A Comparative Study of Matrix Factorization and Random Walk with Restart in Recommender Systems
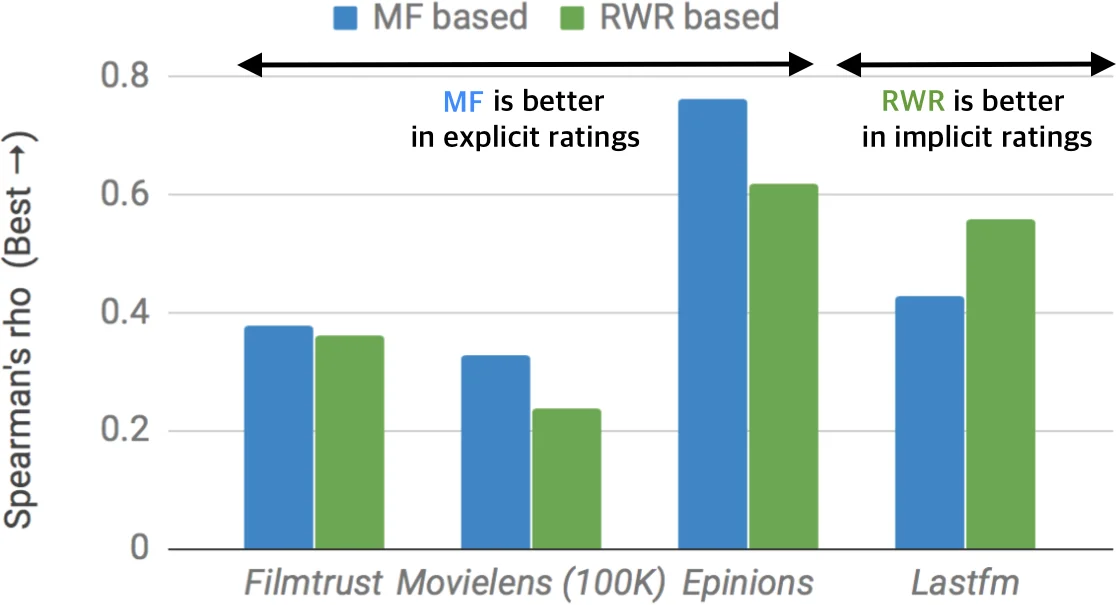
Between matrix factorization or Random Walk with Restart (RWR), which method works better for recommender systems? Which method handles explicit or implicit feedback data better? Does additional information help recommendation? Recommender systems play an important role in many e-commerce services such as Amazon and Netflix to recommend new items to a user. Among various recommendation strategies, collaborative filtering has shown good performance by using rating patterns of users. Matrix factorization and random walk with restart are the most representative collaborative filtering methods. However, it is still unclear which method provides better recommendation performance despite their extensive utility. In this paper, we provide a comparative study of matrix factorization and RWR in recommender systems. We exactly formulate each correspondence of the two methods according to various tasks in recommendation. Especially, we newly devise an RWR method using global bias term which corresponds to a matrix factorization method using biases. We describe details of the two methods in various aspects of recommendation quality such as how those methods handle cold-start problem which typically happens in collaborative filtering. We extensively perform experiments over real-world datasets to evaluate the performance of each method in terms of various measures. We observe that matrix factorization performs better with explicit feedback ratings while RWR is better with implicit ones. We also observe that exploiting global popularities of items is advantageous in the performance and that side information produces positive synergy with explicit feedback but gives negative effects with implicit one.
💡 Research Summary
This paper presents a systematic comparative study of two dominant collaborative‑filtering paradigms: matrix factorization (MF) and random walk with restart (RWR). The authors first formalize the mathematical correspondence between the two families of methods, mapping each MF variant (explicit‑feedback, implicit‑feedback, bias‑augmented, side‑information‑augmented) to an analogous RWR counterpart. A novel contribution is the introduction of a global‑bias version of RWR (RWR‑Bias) that incorporates item popularity and user tendency directly into the graph transition matrix, mirroring the bias terms used in MF‑Bias.
Four recommendation scenarios are examined: (1) explicit rating data, (2) implicit interaction data, (3) inclusion of global bias terms, and (4) exploitation of side information such as user demographics or item categories. For each scenario the paper defines the corresponding loss functions (e.g., squared error for explicit MF, confidence‑weighted loss for implicit MF) and the iterative update rules (gradient descent for MF, power‑iteration for RWR).
Experiments are conducted on three real‑world datasets (MovieLens, Netflix, Last.fm) covering both explicit (star ratings) and implicit (clicks, play counts) feedback. Evaluation metrics include RMSE, MAE, Precision@K, Recall@K, and NDCG. The results show a clear pattern: MF (especially MF‑Bias) outperforms all RWR variants on explicit‑feedback tasks, achieving 5‑10 % lower RMSE and higher precision. Conversely, RWR (particularly RWR‑Bias) dominates on implicit‑feedback tasks, delivering 7‑12 % improvements in top‑K precision and recall. Adding bias terms improves both families, but side information has divergent effects: MF‑Side boosts performance on explicit data (4‑8 % gain) and helps alleviate cold‑start problems, while RWR‑Side degrades performance on implicit data (3‑5 % loss) because noisy side attributes propagate through the random walk.
The analysis also highlights why these differences arise. MF’s linear regression framework naturally integrates global averages and bias, making it well‑suited for dense, rating‑centric datasets. RWR’s graph‑based propagation captures local similarity patterns and excels when interaction signals are binary or sparse, as in implicit logs. However, RWR is more sensitive to noisy side edges, which can dilute the personalized proximity scores.
In conclusion, the paper provides practical guidance: use MF (with bias and side information) for services that collect explicit ratings (e.g., movie or product reviews), and prefer RWR (especially the bias‑enhanced version) for platforms that rely on implicit behavior (e.g., clicks, streams). The authors release code and datasets, and suggest future work on hybrid models that combine latent factor and graph‑based signals, as well as extensions to dynamic, time‑evolving graphs.
Comments & Academic Discussion
Loading comments...
Leave a Comment