Parametrizing filters of a CNN with a GAN
It is commonly agreed that the use of relevant invariances as a good statistical bias is important in machine-learning. However, most approaches that explicitly incorporate invariances into a model architecture only make use of very simple transformations, such as translations and rotations. Hence, there is a need for methods to model and extract richer transformations that capture much higher-level invariances. To that end, we introduce a tool allowing to parametrize the set of filters of a trained convolutional neural network with the latent space of a generative adversarial network. We then show that the method can capture highly non-linear invariances of the data by visualizing their effect in the data space.
💡 Research Summary
The paper addresses the problem of uncovering and parameterizing the invariances that a trained convolutional neural network (CNN) has implicitly learned. While many prior works incorporate simple geometric invariances (e.g., translation, rotation) into network architectures, they struggle to capture richer, non‑linear transformations that are specific to a given dataset. The authors propose a novel framework that uses a Generative Adversarial Network (GAN) to model the set of filters of a particular CNN layer, but with two crucial twists.
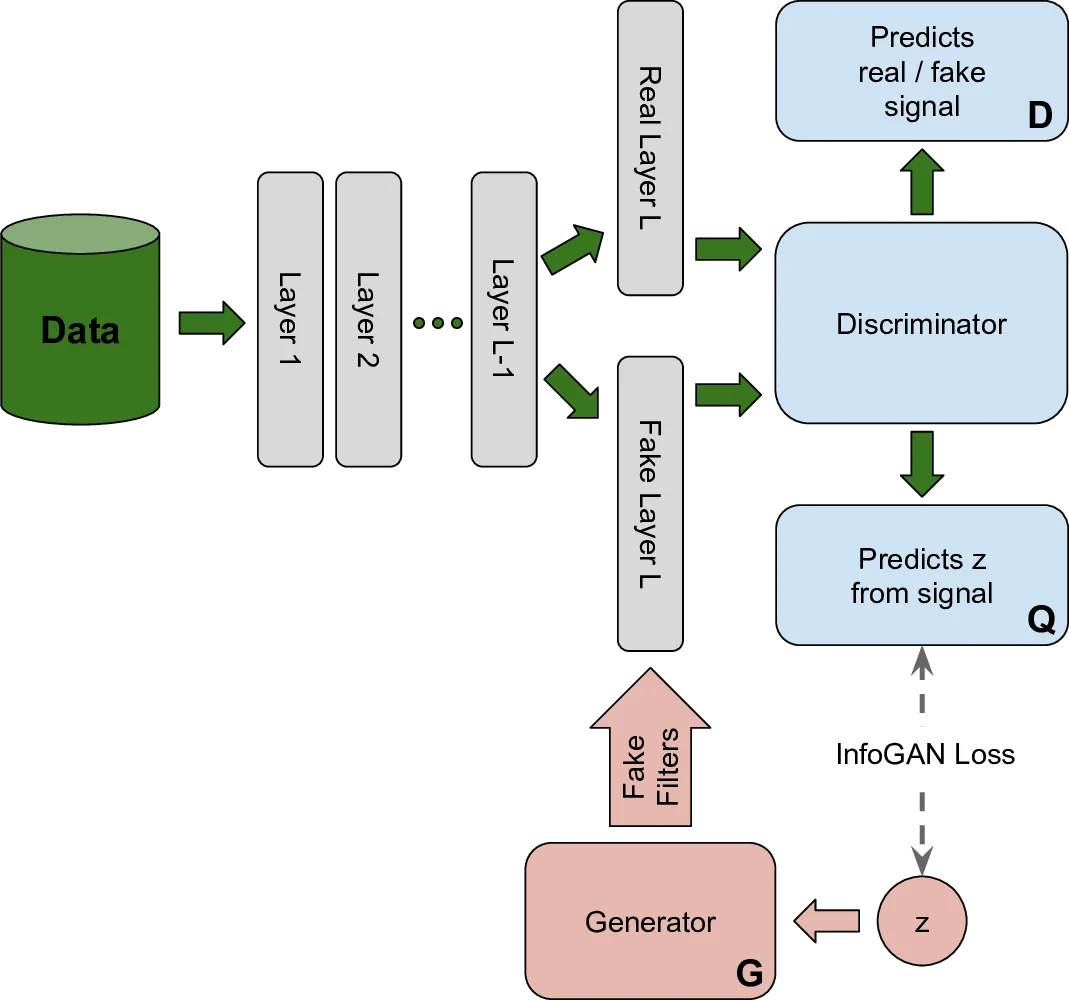
First, instead of feeding the discriminator raw filters (which are few and lead to over‑fitting), the discriminator receives the activations produced when those filters are applied to real images. For a real filter set the activation is CNN⁽ˡ⁾(I); for a generated filter set it is Conv(CNN⁽ˡ⁻¹⁾(I), G(z)). The GAN therefore learns to generate filters whose downstream activations are indistinguishable from those of the original network. This sidesteps the data‑scarcity problem and forces the generator to capture the functional effect of the filters rather than their exact weight values.
Second, to avoid the trivial solution where the generator always outputs the same filter, the authors embed an InfoGAN objective. The latent code z (the GAN’s input noise) is treated as the InfoGAN code c, and an auxiliary network Q is trained to recover z from the fake activation. Maximizing the mutual information I(z, G(z)) forces a smooth, diverse mapping from latent space to filter space, giving a continuous parametrization of the learned invariances. The overall loss combines the standard GAN minimax term with a weighted InfoGAN mutual‑information regularizer (λ L_I).
Training proceeds by jointly updating the generator G, the discriminator D, and the auxiliary Q using minibatch stochastic gradient descent (RMSprop in the experiments). After training, the generator can produce a filter for any latent vector z. To visualize the corresponding invariance in image space, the authors fix an input image x and compute its activation profile a(x|z) using the generated filters. They then vary two dimensions of z on a small grid, and for each perturbed z_k they solve an inverse problem: find an image x′_k that yields the same activation profile a(x′_k|z_k) ≈ a(x|z). This is done by gradient descent on a loss consisting of the squared difference of activation profiles plus a natural‑image prior (Mahendran & Vedaldi, 2015). The resulting grid of images shows how continuous changes in the latent space translate into smooth transformations of the original image—effectively visualizing the invariances encoded by the CNN.
The method is evaluated on MNIST using a 5‑layer CNN (ReLU, max‑pool, batch‑norm). The authors apply the technique to the 4th (deep) layer and the 2nd (shallow) layer. For the deep layer, the generated transformations involve high‑level shape changes, stroke thickness, and slant—non‑linear deformations that preserve class identity. For the shallow layer, the transformations are low‑level, such as brightness shifts and minor stroke width adjustments. To assess whether the generated filters preserve classification performance, they replace the original 4th‑layer filters with an average of ten generated filter sets and retrain the remaining layers; test accuracy improves from 0.971 to 0.982, indicating that the generated variations are indeed irrelevant to the task. A Multi‑Dimensional Scaling (MDS) plot shows that different latent vectors produce a diverse set of filters, confirming that the generator does not simply memorize the original filter bank.
In summary, the contributions are: (1) a GAN framework that learns a smooth, data‑dependent parametrization of CNN filters via activation‑based discrimination, (2) integration of an InfoGAN objective to enforce diversity and interpretability of the latent space, and (3) a practical visualization pipeline that maps latent perturbations to image‑space transformations, revealing the learned invariances. Limitations include experiments confined to grayscale MNIST and a relatively shallow network; scalability to high‑resolution, color images and practical use for data augmentation remain open questions. Future work could extend the approach to more complex datasets, explore transfer‑learning benefits, and investigate new pooling or regularization schemes based on the learned transformation manifold.
Comments & Academic Discussion
Loading comments...
Leave a Comment