Hit Song Prediction for Pop Music by Siamese CNN with Ranking Loss
A model for hit song prediction can be used in the pop music industry to identify emerging trends and potential artists or songs before they are marketed to the public. While most previous work formulates hit song prediction as a regression or classification problem, we present in this paper a convolutional neural network (CNN) model that treats it as a ranking problem. Specifically, we use a commercial dataset with daily play-counts to train a multi-objective Siamese CNN model with Euclidean loss and pairwise ranking loss to learn from audio the relative ranking relations among songs. Besides, we devise a number of pair sampling methods according to some empirical observation of the data. Our experiment shows that the proposed model with a sampling method called A/B sampling leads to much higher accuracy in hit song prediction than the baseline regression model. Moreover, we can further improve the accuracy by using a neural attention mechanism to extract the highlights of songs and by using a separate CNN model to offer high-level features of songs.
💡 Research Summary
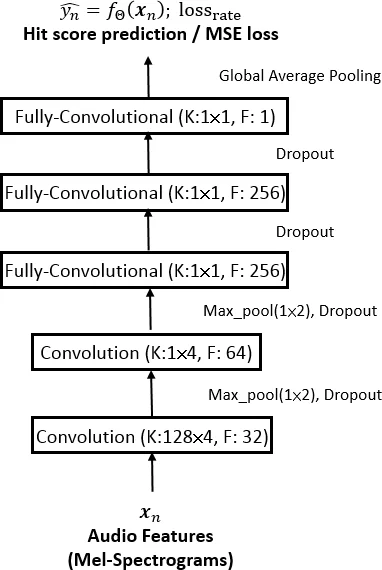
This paper tackles the problem of predicting pop‑music hits by reframing it as a ranking task rather than the more common regression or binary classification approaches. The authors argue that the essential goal of hit prediction is to determine the relative popularity of songs, which can be learned more naturally through pairwise ranking. To this end, they propose a Siamese convolutional neural network (CNN) architecture that processes pairs of songs with shared parameters. The network is trained with a multi‑objective loss that linearly combines a mean‑squared‑error (MSE) term for predicting absolute hit scores and a pairwise ranking loss that enforces a margin between the predicted scores of the two songs in a pair. The weighting between these two objectives (parameter w) is tuned on a validation set, allowing a trade‑off between accurate score estimation and correct ordering.
The dataset comes from KKBOX, a major streaming service in Taiwan and East Asia. Daily play‑count logs spanning January 2016 to June 2017 are used; each song’s “hit score” is defined as its normalized market share on the 60th day after release. This definition mitigates the bias of cumulative counts that favor older releases and captures sustained popularity beyond initial promotional spikes. From the full corpus, the authors sample the 15 000 songs with the highest hit scores and perform 10‑fold cross‑validation with an 8:1:1 split for training, validation, and testing.
Two levels of audio representation are employed. Low‑level features consist of 30‑second log‑mel spectrograms (128 bins, 22 050 Hz, 4 096‑point FFT). The authors compare two segment selection strategies: (a) “Mid‑30”, simply taking the middle 30 seconds of each track, and (b) “HL‑30”, extracting a 30‑second highlight using a state‑of‑the‑art neural attention thumbnailing model. The HL‑30 approach consistently yields higher evaluation scores, indicating that the attention model captures the most informative parts of a song.
To bridge the semantic gap between raw audio and the high‑level concept of “hotness”, the authors augment the audio input with high‑level tag features. They use JYnet, a pre‑trained music‑tagging CNN trained on the MagnaTagATune dataset, to predict activation scores for 50 tags (genres, instruments, moods, etc.). These tag vectors are passed through a three‑layer fully‑connected network and combined with the audio‑based CNN output using a weight µ, also tuned on validation data. Adding tag information improves performance across almost all model variants.
A crucial contribution is the design of pair‑sampling strategies for the Siamese network. Naïve random sampling often yields many pairs of low‑popularity songs due to the long‑tail nature of listening data, which can dilute the learning signal. The authors therefore propose:
-
A/B sampling – Songs are split into “A” (above‑average hit score) and “B” (below‑average). Each training pair must contain at least one A‑song, ensuring that the model focuses on discriminating popular from non‑popular tracks and alleviating class imbalance.
-
Artist sampling – Pairs are formed from songs by the same artist, forcing the model to learn why some tracks from an artist become hits while others do not.
-
Hybrid sampling – A weighted average of the predictions from A/B and artist samplers.
The loss for the Siamese network is the standard hinge‑style ranking loss:
loss_rank = (1/P) Σ max(0, m – δ(y_i, y_j)·(f(x_i) – f(x_j)))
where δ = +1 if y_i ≥ y_j and –1 otherwise, and m is a margin hyper‑parameter.
Evaluation metrics focus on the top‑10 % of songs (the 150 highest‑ranked test tracks) and include normalized discounted cumulative gain (nDCG@10 %), Kendall’s τ, and Spearman’s ρ. These metrics capture both the relevance of the predicted scores (nDCG) and the correctness of the ordering (τ, ρ).
Results show that:
- Using HL‑30 instead of Mid‑30 improves nDCG from 0.0725 to 0.0999 for the simple CNN, confirming the benefit of attention‑based highlights.
- Adding tag features raises nDCG further to 0.1241 and improves ranking correlations.
- The Siamese CNN with A/B sampling outperforms naïve and artist sampling in Kendall’s τ (0.1852 vs. 0.0828) and Spearman’s ρ (0.2713 vs. 0.1222).
- The best overall configuration—Siamese CNN with A/B sampling plus tag features—achieves nDCG = 0.1287, Kendall = 0.2415, and Spearman = 0.3484, surpassing all baselines.
The authors conclude that treating hit prediction as a ranking problem, combined with careful pair sampling to address data imbalance, and enriching audio with semantic tag information and attention‑driven highlights, yields a substantially more effective model for discriminating hits from non‑hits. They suggest future work could integrate richer artist metadata, lyrics, or social‑media signals to further boost predictive power.
Comments & Academic Discussion
Loading comments...
Leave a Comment