Pattern representation and recognition with accelerated analog neuromorphic systems
Despite being originally inspired by the central nervous system, artificial neural networks have diverged from their biological archetypes as they have been remodeled to fit particular tasks. In this paper, we review several possibilites to reverse m…
Authors: Mihai A. Petrovici, Sebastian Schmitt, Johann Kl"ahn
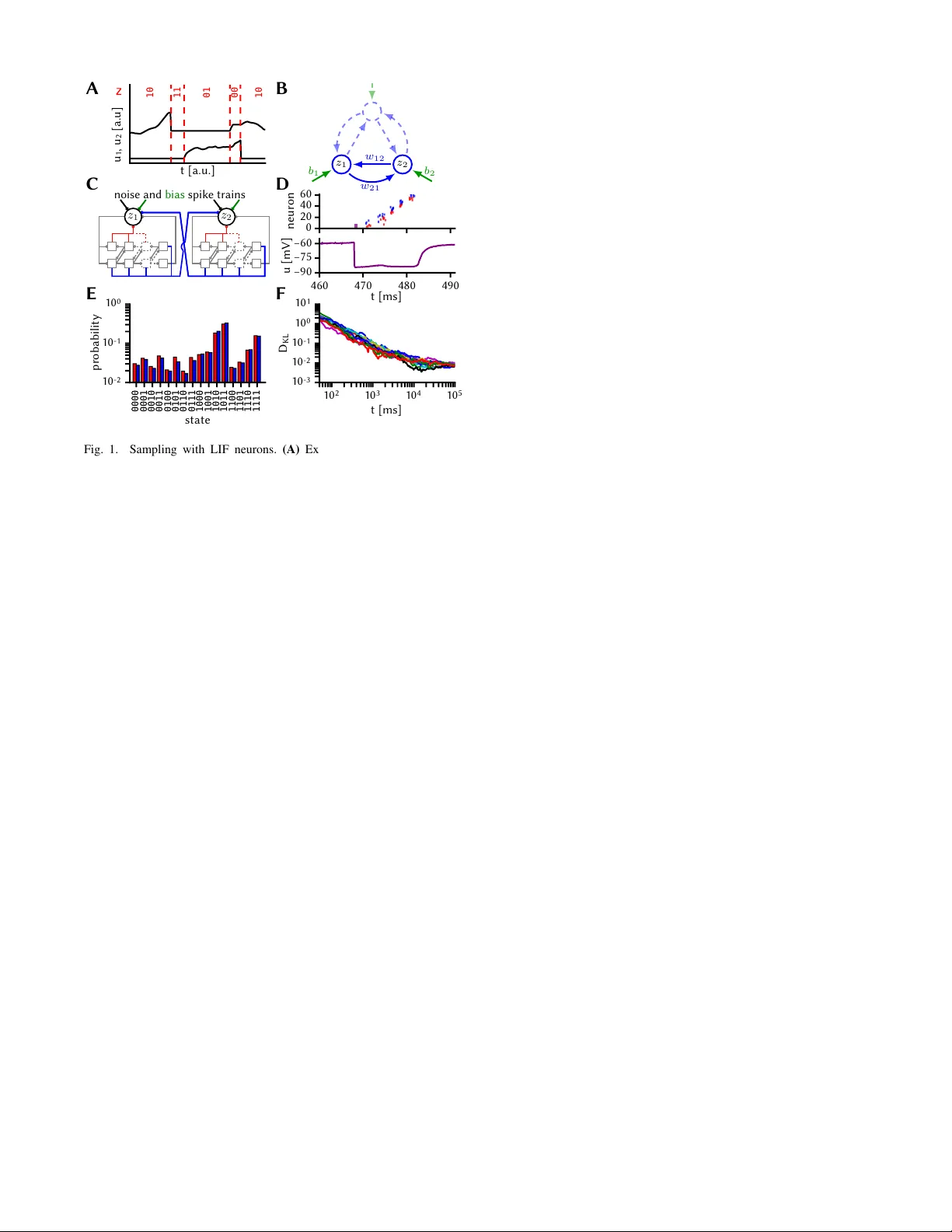
P attern representation and recognition with accelerated analog neuromorphic systems M. A. Petrovici † ‡ S. Schmitt † J. Klähn † D. Stöckel † A. Schroeder † G. Bellec k J. Bill † O. Breitwieser † I. Bytschok † A. Grübl † M. Güttler † A. Hartel † S. Hartmann § D. Husmann † K. Husmann † S. Jeltsch † V . Karasenko † M. Kleider † C. K oke † A. K ononov † C. Mauch † E. Müller † P . Müller † J. Partzsch § T . Pfeil † S. Schiefer § S. Scholze § A. Subramoney k V . Thanasoulis § B. V ogginger § R. Legenstein k W . Maass k R. Schüffn y § C. Mayr § J. Schemmel † K. Meier † † Heidelberg Uni versity , Kirchhoff-Institute for Physics, Im Neuenheimer Feld 227, D-69120 Heidelber g ‡ Univ ersity of Bern, Department of Physiology , Bühlplatz 5, CH-3012 Bern § T echnische Universität Dresden, Chair of Highly-P arallel VLSI-Systems and Neuromorphic Circuits, D-01062 Dresden k Graz Univ ersity of T echnology , Institute for Theoretical Computer Science, A-8010 Graz Abstract —Despite being originally inspired by the central nervous system, artificial neural networks ha ve diverged from their biological archetypes as they have been remodeled to fit particular tasks. In this paper , we review sev eral possibilites to reverse map these architectures to biologically more realistic spiking networks with the aim of emulating them on fast, low- power neur omorphic hardwar e. Since many of these devices em- ploy analog components, which cannot be perfectly controlled, finding ways to compensate for the resulting effects represents a key challenge. Here, we discuss three different strategies to address this problem: the addition of auxiliary network components for stabilizing activity , the utilization of inherently rob ust architectur es and a training method f or hardware- emulated networks that functions without perfect knowledge of the system’ s dynamics and parameters. For all three scenarios, we corroborate our theoretical considerations with experimental results on accelerated analog neuromorphic platforms. I . I N T RO D U C T I O N Artificial neural networks (ANNs) rank among the most successful classes of machine learning models, but are – superficial similarities to sensory processing pathways in cortex notwithstanding – difficult to map to biologically realistic spiking neural networks. Nev ertheless, we argue that such a rev erse mapping is worthwhile for two reasons. First, it could help us understand information processing in the brain – assuming that it follo ws similar computational principles. Second, it enables machine learning applications on fast, low-po wer neuromorphic architectures that are specifically dev eloped to mimic biological neuro-synaptic dynamics. In this manuscript, we discuss sev eral ways to answer what we consider to be a key challenge for neuromorphic archi- tectures with analog components: Is it possible to design spiking architectures and training methods that are amenable to neuromorphic implementation and remain functionally performant despite substrate-inherent imperfections? More specifically , we revie w three different approaches [1]–[3]. The first two are based on recent insights about how networks of spiking neurons can be constructed to sample from predefined joint probability distributions [4], [5]. When these distributions are learned from data, these networks automatically build an internal, generativ e model, which is then straightforward to use for pattern recognition and memory recall [6]. Practical problems arise when the hardware dynamics and parameter ranges are incompatible to the target specifications of the network, as these inevitably distort the sampled distribution. The first approach in volv es the addition of auxiliary network components in order to make it rob ust to hardware-induced distortions (Sec. II). The second one restricts the network topology in a way that endows it with immunity to some of these ef fects (Sec. III). W e demonstrate the effecti veness of both these approaches on the Spikey neuromorphic system [7]. The third strategy maps traditional feedforward architec- tures, trained of fline with a backpropagation algorithm, to a network of spiking neurons on the neuromorphic device (Sec. IV). Here, the key to good performance is an additional learning phase where parameters are trained on hardware in the loop, while using the abstract network description as an approximation for the parameter updates. W e sho w ho w this approach can restore network functionality despite having incomplete knowledge about the gradient along which the pa- rameters need to descend. These experiments are performed on the BrainScaleS neuromorphic system [8]. While our networks are small compared to those used in contemporary machine learning applications, they showcase the potential of using accelerated analog neuromorphic sys- tems for pattern representation and recognition. In particular , the used neuromorphic systems operate 10 4 times faster than their biological archetypes, thereby significantly speeding up both training and practical application. I I . F A S T S A M P L I N G W I T H S P I K E S Follo wing [4], [5], neural network activity can be inter - preted as sampling from an underlying probability distribu- tion over binary random v ariables (R Vs). The mapping from spikes to states z = ( z 1 , . . . , z k ) is defined by z ( t ) k = 1 if t s k < t < t s k + τ ref , 0 otherwise , (1) where t s k are spike times of the k th neuron and τ ref its abso- lute refractory period (Fig. 1 A). When using leaky integrate- and-fire (LIF) neurons, Poisson background noise is used to achiev e a high-conductance state, in which the stochastic B 0000 0001 0010 0011 0100 0101 0110 0111 1000 1001 1010 1011 1100 1101 1110 1111 state 1 0 - 2 1 0 - 1 1 0 0 probability E C 0 20 40 60 neuron D t [a.u.] u 1 , u 2 [ a . u ] z 10 11 01 00 10 A 1 0 2 1 0 3 1 0 4 1 0 5 t [ m s ] 1 0 - 3 1 0 - 2 1 0 - 1 1 0 0 1 0 1 D K L F 460 470 480 490 t [ m s ] −90 −75 −60 u [ m V ] noise and bias spike trains z 1 z 2 z 2 z 1 w 12 w 21 b 2 b 1 Fig. 1. Sampling with LIF neurons. (A) Exemplary membrane potential traces and mapping of refractory/non-refractory neuron states to states 1/0 of binary R Vs. (B) Exemplary structure of a BM. A subset of 2 units ( z 1 , z 2 ) with biases ( b 1 , b 2 ) (green) and connected by weights w 12 = w 21 (blue) is highlighted to exemplify the neuromorphic network structure in subplot C. (C) Sketch of sampling subnetworks representing binary R Vs. Each subnetwork consists of a principal LIF neuron (black circle) and an associated synfire chain that implements refractoriness (red synapses), and coupling between sampling units (blue synapses). (D) Exemplary spike activity of a sampling unit and membrane potential of its PN. (E) T ar get (blue) vs. sampled (red) distribution on the Spikey chip. (F) Evolution of the Kullback-Leibler diver gence between the sampled and the target distribution for multiple experimental runs. T ime giv en in biological units. response of a single neuron is well approximated by a logistic activ ation function p ( z k = 1) = σ [ ¯ u k − ¯ u 0 k ] /α , (2) where σ ( · ) is the logistic function and ¯ u k represents the noise-free membrane potential of the k th neuron. The param- eters ¯ u 0 k (bias parameter determining the inflection point) and α (slope) are controlled by the intensity of the background noise. With appropriate settings of synaptic weights w ij and bias parameters ¯ u 0 k , these networks can be trained to sample from Boltzmann distributions p ( z ) ∝ exp[ − E ( z )] = exp z T W z / 2 + z T b , (3) where the weight matrix W and the bias vector b can be chosen freely . This enables the emulation of Boltzmann machines (BMs) with networks of LIF neurons (Fig. 1 B). A core assumption of the neural sampling framework is that the membrane potential u k of a neuron reflects the state z \ k of all presynaptic neurons at any moment in time: u k ( z \ k ) = P n j 6 = k W kj z j + b k . (4) In particular , this requires that all neurons instantaneously transmit their states (spikes) to all their postsynaptic part- ners. In an y physical system, this assumption is necessarily violated to some degree, since signal transmission can nev er be instantaneous. In the particular case of accelerated neu- romorphic hardware, synaptic transmission delays become ev en more problematic, as they can be in the same order of magnitude as the state-encoding refractory times themselves. Furthermore, the required equiv alence between post-synaptic potential (PSP) durations and refractory states (1,4) can be violated if either of these are unstable. On Spikey , for exam- ple, refractory times hav e relative spike-to-spike variations σ τ ref /τ ref between 2 % and 20 %. These two kinds of timing mismatch pose a fundamental problem to the implementation of spiking BMs in accelerated analog substrates. Here, we alleviate the issue of substrate-induced timing mismatches by using a recurrent network structure that rep- resents each R V with a small subnetwork, called a sampling unit. The subnetw orks are b uilt such that refractory times can be well controlled and, in addition, intra-unit refractory states and inter -unit state communication across the network are inseparably coupled (Fig. 1 C). Sampling units consist of a single principle neuron (PN) and a small synfire chain of excitatory (EPs) and inhibitory populations (IPs). The EPs of each stage project to both pop- ulations in the follo wing stage, thereby relaying an acti vity pulse in the forward direction. The IPs project backwards, ensuring that neurons from previous stages only spike once. Additionally , all IPs and the last EP also project onto the PN with large weights. Therefore, after the PN elicits a spike, the IPs sequentially pull its membrane potential close to the inhibitory rev ersal potential, prohibiting it from firing as long as the synfire chain is active (Fig. 1 D). When the pulse has reached the final synfire stage, its EP pulls the PN’ s membrane potential back to its equilibrium v alue. The total duration of this pseudo-refractory period can then be controlled by the synfire chain length and parameters. In addition to controlling refractoriness, the synfire chains also mediate the interaction between PNs. The connections from a synfire chain to other PNs simply mirror its connec- tions to its own PN. This guarantees a match between effec- tiv e interaction durations and pseudo-refractory periods. The correct synapse parameter settings (weights, time constants) are determined in an iterativ e training procedure [1]. The results of a hardware emulation can be seen in Fig. 1 E, F . A network of four sampling units was trained on Spikey to sample from a target Boltzmann distribution. After training, the network needs about 10 4 ms of biological time to achiev e a good match between the sampled and the target distribution. Considering the hardware acceleration factor of 10 4 , this happens in 1 ms of wall-clock time. I I I . R O B U S T H I E R A R C H I C A L N E T W O R K S As discussed in the previous section, sampling LIF net- works are ostensibly sensiti ve to different types of hardware- induced timing mismatch. In this subsection, we discuss how a sampling network model can be made robust by imposing a hierarchy onto the network structure [2]. This is the equi valent of moving from general BMs to restricted BMs (RBMs). In addition to making their operation more robust, as we discuss belo w , this hierarchization has the distinct advantage of significantly speeding up training. ideal SW sim HW Spikey F 0 40 80 120 160 τ m [ m s ] D 0.0 0.5 1.0 1.5 2.0 0.6 0.7 0.8 0.9 1.0 class. accuracy Δ T d e l a y / τ r e f B 0.0 0.2 0.4 σ τ r e f / τ r e f C 10 8 6 4 n w [ b i t s ] E A visible (144) hidden (50) label (6) Fig. 2. Robustness from structure in hierarchical networks. (A) Hierarchical spiking network emulating an RBM. (B)–(E) Effects of hardware-induced distortions on the classification rate of the network. Each test image was presented for a duration of 1000 ms. Green: training data, blue: test data, bro wn: mean v alue and range of distortions measured on Spikey . Error bars represent trial-to-trial variations. (B) Synaptic transmission delays. (C) Spike-to-spik e variability of refractory times. (D) Membrane time constant. (E) Synaptic weight discretization. (F) Comparison of classification rates in three scenarios: software simulation of the ideal, distortion-free case (black), software simulation of combined hardware-induced distortions as measured on Spikey (purple), hybrid emulation with the hidden layer on Spikey (green). Light colors for training data, dark colors for test data. T o emulate an RBM, we construct a hierarchical LIF network model with 3 layers: a visible layer representing the data, a hidden layer that learns particular motifs in the data and a label layer for classification (Fig. 2 A). The network was trained with a contrasti ve learning rule ∆ W ij ∝ h z i z j i data − h z i z j i model , (5) ∆ b i ∝ h z i i data − h z i i model (6) on a modified subset of the MNIST dataset ( h·i data and h·i model represent expectation values when clamping training data and when the network samples freely , respectiv ely). Due to hardware limitations, we used a small network and dataset (6 digits, 12 × 12 pixels, each with 20 training and 20 test samples) for this proof-of-principle experiment. The specific influence of various hardware-induced dis- tortion mechanisms were first studied in complementary software simulations. These simulations show that the classi- fication accuracy of the network is essentially unaffected by the types of timing mismatch discussed above, even when their amplitudes are much larger than those measured on our neuromorphic substrate (Fig. 2 B, C). In order to facilitate a meaningful comparison with hardware experiments, two further distortion mechanisms were studied. An upper limit to the membrane conductance can prevent neurons from entering a high-conductance state, thereby distorting their activ ation functions away from their ideal logistic shape (2) and consequently modifying the sampled distribution. Howe ver , within the range achie vable on Spikey , the effect on the classification accuracy remains small (Fig. 2 D). The largest effect (about 5.6 % regression in classification accu- racy compared to ideal software simulations) stems from the discretization of synaptic weights, which have a resolution of 4 bits on Spikey (Fig. 2 E). The robustness of this hierarchical architecture to timing mismatches is a consequence of both the training procedure and the information flow within the network. T raining has the effect of creating a steep energy landscape E ( z ) (3), for which deep energy minima, corresponding to particular learned digits, represent strong attractors, in which the system is placed during classification by clamping of the visible layer . Throughout the duration of such an attractor , visible neurons represent pix els of constant intensity encoded in their spiking probability , thereby entering a quasi-rate-based infor- mation representation regime. Therefore, the information the y provide to the hidden layer is unaffected by temporal shifts or zero-mean noise. As they outnumber the hidden neurons 24:1, the y ef fecti vely control the state of the hidden layer . The hidden layer neurons themselves are unaf fected by timing mismatches because they are not interconnected. Second- order (hidden → label → hidden) lateral interactions are indeed distorted, but as they are mediated by only few label neurons, their relativ e strength is too weak to play a critical role. These findings are corroborated by experiments on Spikey (Fig. 2 F). Due to the system’ s limitations, we used a hybrid approach, with the visible and label layers implemented in software and the hidden layer running on Spikey . In the ideal, undistorted case, the LIF network had a classification per- formance of 86.6 ± 1.7 % (93.4 ± 0.9 %) on the test (train- ing) set. This was reduced to 78.1 ± 1.5 % (90.7 ± 1.7 %) when all distorti ve effects were simultaneously present in software simulations. In comparison, the hybrid emulation showed a performance of 80.7 ± 2.3 % (89.8 ± 1.8 %), which closely matched the software results within the trial-to-trial variability . W e stress that this was a result of direct-to- hardware mapping, with no additional training to compensate for hardware-induced distortions (as compared to Sec. IV). I V . I N - T H E - L O O P T R A I N I N G In Sec. II, we used a training procedure based on (5,6) to optimize the hardware-emulated sampling network. Such simple contrasti ve learning rules can yield very good classi- fication performance in networks of spiking neurons [6]. An- other class of highly successful learning algorithms is based on error backpropagation. This, howe ver , requires precise knowledge of the gradient of a cost function with respect to the network parameters, which is difficult to achiev e on ana- log hardware. W e propose a training method for hardware- emulated networks that circumvents this problem by using the cost function gradient with respect to the parameters of an ANN as an approximation of the true gradient with respect to the hardware parameters [3]. A similar method has previously been used for network training on a digital neuromorphic device [9]. Our training schedule consisted of two phases. In the first phase, an ANN was trained in software on a modified subset 0 5 10 15 20 25 30 35 in-the-loop training step 1 0 1 1 0 2 1 0 3 1 0 4 software model training step 0.00 0.25 0.50 0.75 1.00 class. accuracy C A B visible (100) hidden (15) hidden (15) label (5) backpropagation weight updates 4 bit weight discretization BrainScaleS spikes ANN activity MNIST prediction forw ard pass backward pass Fig. 3. In-the-loop training. (A) Structure of the feed-forward, rate-based deep spiking network. (B) Schematic of the training procedure with the hardware in the loop. (C) Classification accurac y ov er training step. Left: software training phase, right: hardware in-the-loop training phase. of the MNIST dataset (5 digits, 10 × 10 pixels, with a total of 30690 training and 5083 test samples) using a simple cost function with regularization C ( W ) = P s ∈ S k ˜ y s − ˆ y s ) k 2 + P kl 1 2 λW 2 kl (7) and backpropagation with momentum [10] ∆ W kl ← η ∇ W kl C ( W ) + γ ∆ W kl , (8) W kl ← W kl − ∆ W kl . (9) Here, ˜ y s and ˆ y s denote the target and network state of the label layer , respectively , and the sum runs over all samples within a minibatch S . The learned parameters were then translated to a feed-forward spiking neural network (Fig. 3 A). Here, the BrainScaleS wafer-scale system [8] was used for network emulation. Due to hardware imperfections, the ANN classification accuracy of 97 % dropped to 72 +12 − 10 % after mapping the network to the hardware substrate. In the second training phase, the hardware-emulated net- work was trained in the loop (Fig. 3 B) for sev eral iterations. Parameter updates were calculated using the same gradient descent rule as in the ANN, but the activ ation of all layers was measured on the hardware. The rationale behind this approach is that the activ ation function of an ANN unit is sufficiently similar to that of an LIF neuron to allow using the computed gradient as an approximation of the true hardware gradient. As seen in Fig. 3 C, this assumption is v alidated by the post-training performance of the hardware-emulated net- work: after 40 training iterations, the classification accuracy increased back to 95 +1 − 2 %. V . D I S C U S S I O N W e have revie wed three strategies for emulating per- formant spiking network models in analog hardware. The proposed methods tackled the problems induced by substrate- inherent imperfections from different (and complementary) angles. The three strategies were implemented and ev aluated with two dif ferent analog hardware systems. An essential advantage of the employed neuromorphic platforms is provided by their accelerated dynamics. De- spite possible losses in performance compared to precisely tunable software solutions, accelerated analog neuromorphic systems have the potential to v astly outperform classical simulations of neural networks in terms of both speed and energy consumption [3] – an inv aluable advantage for on- line learning of complex, real world data sets. The network in Sec. II, for example, is already faster than equiv alent software simulations (NEST 2.2.2 default build, single-threaded, Intel Core i7-2620M) by sev eral orders of magnitude. The studied networks serv e as a proof of principle and are scalable to larger network sizes. Future research will hav e to address whether the results obtained for these small networks still hold as training tasks increase in complexity . Furthermore, the generativ e properties of the described hier- archical LIF networks remain to be studied. Another major step forward will be taken once training can take place entirely on the hardware, thereby rendering sequential re- configurations between individual experiments unnecessary . Future generations of the used systems will feature on- board plasticity processor units, with early-stage experiments already showing promising results [11]. A C K N O W L E D G M E N T S The first fiv e authors contributed equally to this work. This research was supported by EU grants #269921 (BrainScaleS), #604102 and #720270 (Human Brain Project) and the Man- fred Stärk Foundation. R E F E R E N C E S [1] M. A. Petrovici, D. Stöckel, I. Bytschok, J. Bill, T . Pfeil, J. Schemmel, and K. Meier, “Fast sampling with neuromorphic hardware, ” Neural Information Processing Systems, Demonstration, 2015. [2] M. A. Petrovici, A. Schroeder , O. Breitwieser , A. Grübl, J. Schem- mel, and K. Meier, “Rob ustness from structure: Fast inference on a neuromorphic device with hierarchical LIF networks, ” IJCNN, 2017. [3] S. Schmitt, J. Klähn, G. Bellec, A. Grübl, M. Güttler, A. Hartel et al. , “Neuromorphic hardware in the loop: T raining a deep spiking network on the brainscales wafer-scale system, ” IJCNN, 2017. [4] L. Buesing, J. Bill, B. Nessler, and W . Maass, “Neural dynamics as sampling: A model for stochastic computation in recurrent networks of spiking neurons, ” PLoS Computational Biology , vol. 7, no. 11, 2011. [5] M. A. Petrovici, J. Bill, I. Bytschok, J. Schemmel, and K. Meier , “Stochastic inference with spiking neurons in the high-conductance state, ” Physical Review E , vol. 94, no. 4, 2016. [6] L. Leng, M. A. Petrovici, R. Martel, I. Bytschok, O. Breitwieser et al. , “Spiking neural networks as superior generativ e and discriminative models, ” in Cosyne Abstracts, Salt Lake City USA , February 2016. [7] T . Pfeil, A. Grübl, S. Jeltsch, E. Müller, P . Müller , M. A. Petrovici, M. Schmuker et al. , “Six networks on a uni versal neuromorphic computing substrate, ” F r ontiers in Neur oscience , vol. 7, p. 11, 2013. [8] J. Schemmel, D. Brüderle, A. Grübl, M. Hock, K. Meier , and S. Mill- ner , “ A wafer-scale neuromorphic hardware system for large-scale neural modeling, ” in Pr oceedings of the 2010 IEEE ISCAS , 2010, pp. 1947–1950. [9] S. K. Esser, P . A. Merolla, J. V . Arthur, A. S. Cassidy , R. Appuswamy et al. , “Con volutional networks for fast, energy-ef ficient neuromorphic computing, ” PNAS , vol. 113, no. 41, pp. 11 441–11 446, 2016. [10] N. Qian, “On the momentum term in gradient descent learning algo- rithms, ” Neural Networks , vol. 12, no. 1, pp. 145–151, 1999. [11] S. Friedmann, J. Schemmel, A. Grübl, A. Hartel et al. , “Demonstrating hybrid learning in a flexible neuromorphic hardware system, ” IEEE T rans. on Biomed. Circ. and Syst. , no. 99, pp. 1–15, 2016.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment