Significance-based community detection in weighted networks
Community detection is the process of grouping strongly connected nodes in a network. Many community detection methods for un-weighted networks have a theoretical basis in a null model. Communities discovered by these methods therefore have interpret…
Authors: John Palowitch, Shankar Bhamidi, Andrew B. Nobel
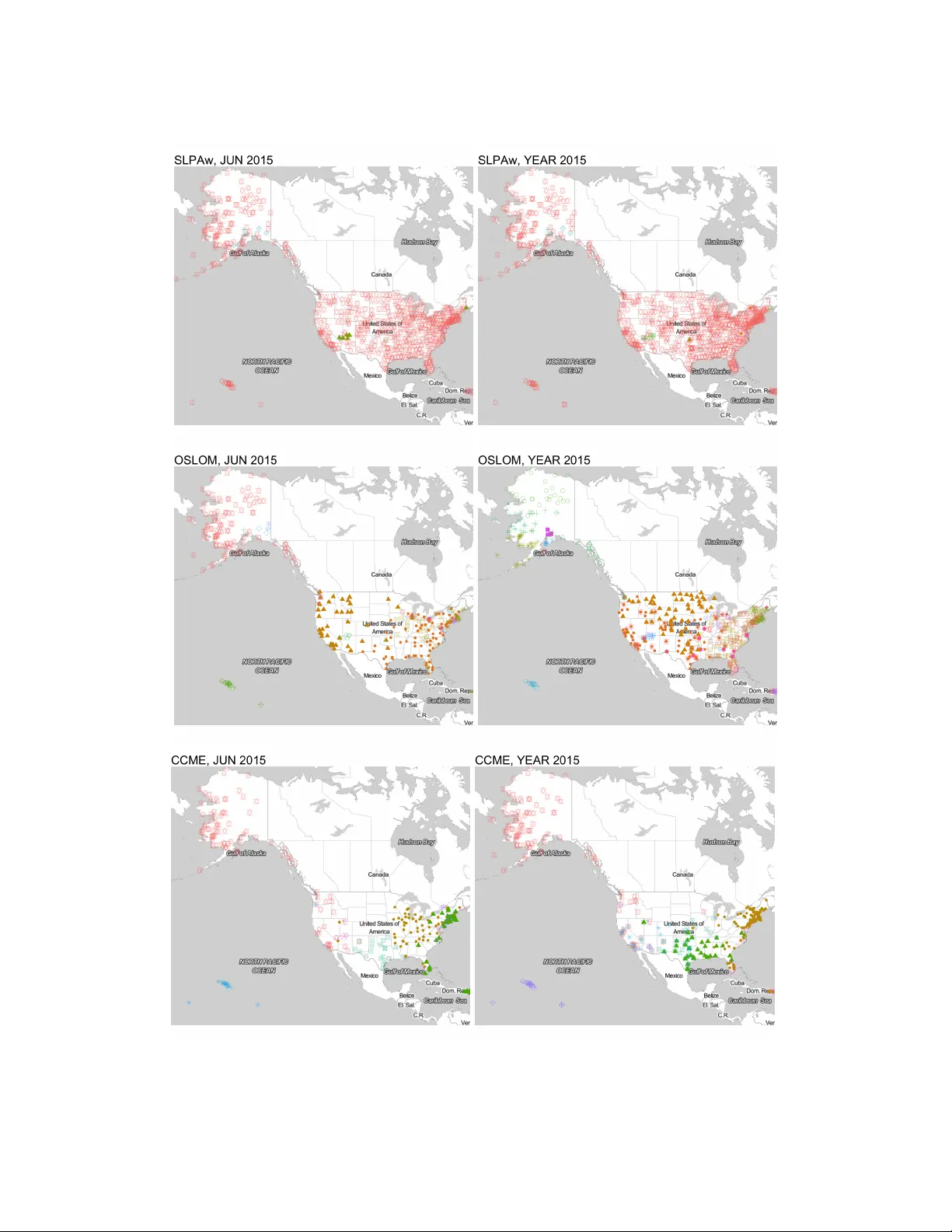
Journal of Machine Learning Research 1 (2017) ** Submitted 7/5; Published */* Significance-based comm unit y detection in w eigh ted net w orks John P alow itch p alojj@email.unc.edu Shank ar Bhamidi bhamidi@email.unc.edu Andrew B. Nob el nobel@email.unc.edu Dep artment of Statistics and Op er ations R ese ar ch University of North Car olina at Chap el Hil l Chap el Hil l, NC 27599 Editor: Abstract Comm unity detection is the pro cess of grouping strongly connected nodes in a net work. Man y comm unity detection metho ds for un -w eighted netw orks ha ve a theoretical basis in a null model. Comm unities disco vered b y these methods therefore hav e in terpretations in terms of statistical significance. In this pap er, we introduce a null for weigh ted net works called the contin uous configuration model. W e use the mo del b oth as a to ol for commu- nit y detection and for simulating w eighted net works with n ull no des. First, we prop ose a communit y extraction algorithm for w eighted netw orks whic h incorporates iterativ e h y- p othesis testing under the n ull. W e prov e a central limit theorem for edge-w eigh t sums and asymptotic consistency of the algorithm under a w eighted sto chastic blo ck mo del. W e then incorp orate the algorithm in a comm unity detection metho d called CCME. T o b enc hmark the method, w e pro vide a simulation framework incorp orating the n ull to plant “bac kground” no des in weigh ted netw orks with communities. W e show that the empirical p erformance of CCME on these simulations is comp etitive with existing metho ds, particu- larly when o verlapping comm unities and bac kground no des are presen t. T o further v alidate the metho d, w e present tw o real-world netw orks with p otential bac kground no des and an- alyze them with CCME, yielding results that reveal macro-features of the corresp onding systems. Keyw ords: Comm unity detection; Multiple testing; Net work models; W eigh ted netw orks; Unsup ervised Learning 1. In tro duction F or decades, the developmen t of graph theory and netw ork science has pro duced a wide arra y of quantitativ e to ols for the study of complex systems. Net work-based data analysis metho ds ha ve driven adv ances in areas as diverse as so cial science, systems biology , life sciences, marketing, and computer science (cf. Palla et al., 2007; Barabasi and Oltv ai, 2004; Lusseau and Newman, 2004; Guimera and Amaral, 2005; Reichardt and Bornholdt, 2007; Andersen et al., 2012). Thorough surv eys of the net work science and metho dology literature ha ve b een pro vided b y Newman (2003) and Jacobs and Clauset (2014), among others. Comm unity detection is a common exploratory tec hnique for netw orks in which the goal is to find subsets of no des that are b oth strongly intraconnected and w eakly intercon- c 2017 John Palo witch ∗ , Shank ar Bhamidi and Andrew B. Nob el. P alo witch, Bhamidi and Nobel nected (Newman, 2004b). There are many p ossible definitions of a communit y , and a broad selection of comm unity detection metho ds. Nonetheless, communit y detection can b e an imp ortan t starting point for further inquiry (Danon et al., 2005). F or instance, comm unity detection has b een used to facilitate recommender systems in online so cial net works (e.g. Sahebi and Cohen, 2011; Xin et al., 2014), and has b een used to “hone in” on regions of genomes (human and otherwise) for a v ariet y of do wnstream analyses (e.g. Cabreros et al., 2016; Platig et al., 2015; F an et al., 2012). Myriad examples of comm unity detection ap- plications can b e found in P orter et al. (2009) and F ortunato (2010), and the references therein. Man y communit y detection metho ds are based on a null mo del, which in this context means a random netw ork mo del without explicit comm unity structure. F or un-weigh ted net works the most common n ull is the configuration model (Bollob´ as, 1980; Bender, 1974) or a related mo del like that of Chung and Lu (2002a,b). Historically , the most common approac h inv olving a null model is the use of a node partition score that is large when no des within the cells of the partition are highly interconnected, relative to what is expected under the n ull (F ortunato, 2010; Newman, 2006). Arguably the most famous example of suc h a criterion is mo dularit y , in tro duced by Newman and Girv an (2004). V arious algorithms ha ve b een created to search directly for partitions of a netw ork with large mo dularity (see Clauset et al., 2004; Blondel et al., 2008), while other approaches use modularity as an auxiliary criterion (see Langone et al., 2011). More recent approaches incorp orate comm unity-specific criteria which are large when the communit y exhibits high connectivity , allo wing for communit y extr action algorithms (e.g. Zhao et al., 2011; Lancic hinetti et al., 2011; Wilson et al., 2014). Generally sp eaking, communities found b y null-based comm unity detection metho ds can b e said to hav e exhibited b ehavior strongly departing from the null. The results of these metho ds therefore carry a statistical testing interpretation unav ailable to alternate approac hes to communit y detection, lik e spectral clustering (White and Smyth, 2005; Zhang et al., 2007) or lik eliho od-based approaches (No wic ki and Snijders, 2001; Karrer and New- man, 2011). In particular, recent metho ds put forth by Lancichinetti et al. (2011) and Wilson et al. (2014) for binary net works exploit the theoretical prop erties of the config- uration mo del to detect “bac kground” no des that are not significantly connected to an y comm unity . These metho ds incorp orate tail b eha vior of v arious graph statistics under the configuration model in a wa y that mo dularity-based metho ds do not. A significan t dra wback of null-based comm unit y detection metho dology is that no ex- plicit n ull mo del exists for edge-w eighted netw orks. Edge w eigh ts are commonplace in net work data, and can pro vide information that impro v es communit y detection p o wer and sp ecificit y (Newman, 2004a). While man y existing comm unity detection methods ha ve b een established for weigh ted and un-w eigh ted netw orks alike, due to the absence of an appro- priate weigh ted-netw ork null mo del, these metho ds do not provide rigorous significance assessmen ts of w eighted-net w ork comm unities. F or instance, the aforementioned metho d from Lancichinetti et al. (2011), called OSLOM, can incorporate edge weigh ts, but uses an exp onen tial function to calculate nominal tail probabilities for edge weigh t sums, a testing approac h which is not based on an explicit null. As a consequence, comm unities in weighte d net works identified by OSLOM ma y in some cases b e spurious or unreliable, especially when no “true” communities exist. 2 Community detection in weighted networks The key metho dological con tributions in this article are as follows: (i) w e provide an explicit null mo del for net w orks with w eighted edges, (ii) we presen t a comm unity extraction metho d based on h yp othesis tests under the n ull, and (iii) we analyze the consistency prop erties of the metho d’s core algorithm with respect to a w eighted sto chastic blo c k model. These contributions provide the b eginnings of a rigorous statistical framework with whic h to study communities in w eighted netw orks. Through extensiv e sim ulations, we sho w that the accuracy of our prop osed extraction metho d is highly comp etitive with other comm unity detection approaches on w eigh ted net works with b oth disjoint and o verlapping comm unities, and on w eighted netw orks with bac kground no des. Importantly , the weigh ted sto chastic blo c k mo del emplo yed (in b oth the theoretical and empirical studies) allows for arbitrary exp ected degree and w eighted-degree distributions, reflecting degree heterogeneit y observ ed in real-w orld netw orks. T o further v alidate the metho d, we apply it to tw o real data sets with (arguably) p oten tial o verlapping communities and bac kground nodes. W e show that the prop osed metho d reco vers sensible features of the real data, in contrast to other metho ds. 1.1 Paper organization The rest of the paper is organized as follows. W e start b y in tro ducing general notation in Section 1.2. In Section 2 we motiv ate and state the con tinuous configuration mo del. In Section 3, we introduce a core algorithm to searc h for comm unities using multiple hypoth- esis testing under the mo del. In Section 4, w e prov e b oth a cen tral limit theorem and a consistency result for the primary test statistic in the core algorithm. W e describe the im- plemen tation and application of the core algorithm in Section 5, and ev aluate its empirical efficacy on sim ulations and real data in Section 6 and 7 (resp ectively). W e close with a discussion in Section 8. 1.2 Notation and terminology W e denote an undirected weigh ted net work on n no des b y a triple G := ( N , A, W ), where N := { 1 , . . . , n } is the no de set with u, v as general elemen ts, A is the adjacency matrix with A uv = 1 if and only if there is an edge b et w een u and v , and W is the w eight matrix with non-negativ e entries W uv con taining edge weigh ts b et ween no des u and v . Note that A uv = 0 implies W uv = 0, but W uv ma y b e zero even when A uv = 1. This allo ws for netw orks with p oten tially zero edge weigh ts; for instance, an online so cial net work from whic h friendship links are edges and message coun ts are edge w eights. The degree of a no de u is defined b y d ( u ) := P v ∈ N A uv , and w e denote the vector of no de degrees b y d = ( d 1 , . . . , d n ). In an analogous fashion, we define the str ength of a no de b y s ( u ) := P v ∈ N W uv , and the strength v ector of the net work by s = ( s (1) , . . . , s ( n )). The total degree and strength of G are giv en b y d T := P v ∈ N d ( v ) and s T := P v ∈ N s ( v ), respectively . 2. The con tin uous configuration mo del T o motiv ate the n ull mo del, w e first explain the in tuition b ehind the binary configuration mo del for unw eighted net works. The binary configuration model for an n -no de net work is based on a given degree vector d corresp onding to the no des. Studied originally in Bollob´ as (1980) and Bender (1974), the mo del is equiv alen t to a pro cess in whic h eac h node u receives 3 P alowitch, Bhamidi and Nobel d ( u ) half-edges, whic h are paired uniformly-at-random without replacemen t un til no half- edges remain (Molloy and Reed, 1995). In other words, the mo del guarantees a graph with degrees d but otherwise uniformly distributed edges. Therefore, giv en an observ ed netw ork with degrees d , a typical draw from the configuration model under d represen ts that net- w ork without an y comm unity structure. As a result, man y comm unity detection methods pro ceed b y iden tifying no de sets having intra-connectivit y significan tly b ey ond what is ex- p ected under the model. F or instance, the mo dularity measure, introduced by Newman and Girv an (2004), scores no de partitions of binary netw orks according to the observed v ersus configuration mo del-exp ected edge densities of the communities. The metho ds OSLOM (Lancic hinetti et al., 2011) and ESSC (Wilson et al., 2014) use the configuration mo del to assess the statistical significance of the deviations graph statistics from their configuration mo del-exp ected v alues. The degrees d of the configuration mo del can be thought of as the no des’ relative prop en- sities to form ties. Chung and Lu made this notion explicit by defining a Bernoulli-based mo del for a n -no de un weigh ted netw ork with a given exp ected degree sequence (Chung and Lu, 2002b). Under this model, the probability of no des u and v sharing an edge is exactly d ( u ) d ( v ) /d T . As null mo dels for communit y detection, the Chung-Lu and configuration are often in terchangeable (Durak et al., 2013). Indeed, for sparse graphs it can b e shown that the probability of an edge b etw een u and v under the configuration mo del is approximately the Chung-Lu probability . The c ontinuous configuration mo del, introduced below, extends the spirit of the configuration and Chung-Lu mo dels b y taking b oth observed degrees d and strengths s as node prop ensities for (resp ectively) edge connection and edge w eight. W e use the following notation to concisely express the mo del. Giv en a v ector x of dimension n , we define for an y indices u, v ∈ N the ratio r uv ( x ) := x ( u ) x ( v ) P w ∈ N x ( w ) (1) Define ˜ r uv ( x ) := min { 1 , r uv ( x ) } . Note that when x is a degree sequence d , r uv ( d ) is the Ch ung-Lu probabilit y of an edge b et ween no des u and v . Finally , for a v ector y of dimension n , define f uv ( x , y ) := r uv ( y ) / ˜ r uv ( x ). 2.1 Mo del statement The con tinuous configuration mo del on n no des has the parameter triple θ := ( d , s , κ ), where d ∈ { 1 , 2 , 3 , . . . } n is a degree vector, s ∈ [0 , ∞ ) n is a strength vector, and κ > 0 is a v ariance parameter. Let F be a distribution on the non-negative real line with mean one and v ariance κ . The mo del sp ecifies a random weigh ted graph G := ( N , A, W ) on n no des as follo ws: 1. P ( A uv = 1) = ˜ r uv ( d ) independently for all node pairs u, v ∈ N 2. F or each no de pair u, v with A uv = 1, generate an independent random v ariable ξ uv according to F , and assign edge w eights b y: W uv = ( f uv ( d , s ) ξ uv , A uv = 1 0 , A uv = 0 4 Community detection in weighted networks The edge generation defined b y step 1 is equiv alen t to the Chung-Lu model: edge indicators are Bernoulli, with probabilities adjusted b y the propensities d . The weigh t generation in step 2 mirrors this pro cess. Edge weigh ts follow the distribution F , with means adjusted by the prop ensities s , through f ( d , s ). If r uv ( d ) 6 1 for all u, v ∈ N (that is, all probabilities are proper), it is easily derived from the mo del that P ( A uv = 1) = d ( u ) d ( v ) d T and E ( W uv ) = s ( u ) s ( v ) s T , (2) equations which extend the binary-netw ork notion of null b eha vior to edge weigh ts. The equations in (2) imply that E ( D ( u )) = d ( u ) and E ( S ( u )) = s ( u ) for all u ∈ N . (3) where D ( u ) and S ( u ) are the (random) degree and strength of u under the mo del. Th us, the con tin uous configuration mo del can b e though t of as null weigh ted net work with giv en exp ected degrees and giv en exp ected strengths. 2.2 Use of the null model When the binary configuration model is used for communit y detection, the degree pa- rameter of the mo del is set to the observ ed degree distribution of the net work. In a sense, this is an estimation of the no des’ connection prop ensities under the null. Similarly , to use the contin uous configuration mo del in practice, w e deriv e the parameter θ from the data at hand. Giv en an observ ed net work G , w e straigh tforw ardly use the observed degrees and strengths d and s as the first tw o parameters of the mo del. The third parameter of the con tinuous configuration mo del, κ , is also computed from the G , and meant to capture its observ ed av erage edge-weigh t v ariance. W e use the following metho d-of-momen ts estimator to specify κ : ˆ κ ( d , s ) := X u,v : A uv =1 ( W uv − f uv ( d , s )) 2 / X u,v : A uv =1 f uv ( d , s ) 2 (4) This estimator is deriv ed as follows. Under the contin uous configuration mo del with d and s , V ar W uv A uv = 1 = f uv ( d , s ) 2 V ar ( ξ uv ) = f uv ( d , s ) 2 κ. (5) Therefore E X u,v : A uv =1 ( W uv − f uv ( d , s )) 2 A = X u,v : A uv =1 V ar W uv A uv = 1 = κ X u,v : A uv =1 f uv ( d , s ) 2 , Dividing through by P u,v : A uv =1 f uv ( d , s ) motiv ates equation 4. Strictly sp eaking, the distribution F is also a parameter of the mo del. Ho wev er, for testing purp oses w e do not require a null sp ecification of F . As w e discuss in the next 5 P alowitch, Bhamidi and Nobel section, p-v alues from the mo del will b e based on a central limit theorem that requires only a third-moment assumption on F . While estimating F could impro ve the mo del’s efficacy as a n ull, in general this would require potentially costly computational procedures, and ad- ditional theoretical assumptions that migh t b e difficult to support or verify in practice. The sp ecification of F will b e most useful for applications of the model that inv olve simulations or lik eliho o d-based analyses. 3. T est statistic and up date algorithm In this section we introduce a core testing-based communit y detection algorithm based on the contin uous configuration mo del. The algorithm allows for a communit y detection approac h whic h employs iterative no de-set up dating, follo wing some recently-in tro duced metho ds (e.g. Lancichinetti et al., 2011; Wilson et al., 2014). First, we define a set up date as a map U α ( · , G ) : 2 N 7→ 2 N , indexed by a parameter α ∈ (0 , 1). Giv en a weigh ted net work G and candidate set B ⊆ N , the up date U α ( B , G ) outputs a new set B 0 formed b y the no des from N that hav e statistically significan t association to B at level α , after a m ultiple-testing correction. W e now describ e U α in detail. The connectivit y of a single no de u ∈ N to a candidate set B is computed via the simple test statistic S ( u, B , G ) := X v ∈ B W uv , (6) whic h is the sum of all w eights on edges inciden t with u and B . When the observed v alue of S ( u, B , G ) is muc h larger than its exp ectation under the con tinuous configuration mo del, there is evidence to supp ort an asso ciation betw een u and B resulting from some form of “ground-truth” comm unity structure in the net w ork. W e assess the strength of evidence, that is, the significance of S ( u, B , G ), with the p-v alue p ( u, B , G ) := P S ( u, B , e G ) > S ( u, B , G ) , (7) where e G is random with resp ect to P , the distribution of the con tinuous configuration model with parameters d , s , and ˆ κ ( d , s ) (see Section 2.2). The update U α is then: Core up date U α 1. Given: graph G with no des N and input set B ⊆ N 2. Calculate p-v alues p := { p ( u, B , G ) : u ∈ N } 3. Obtain threshold τ ( p ) from a multiple-testing pro cedure 4. Output set B 0 = { u : p ( u, B , G ) 6 τ ( p ) } Man y metho ds to compute a m ultiple-testing threshold τ ( p ) are av ailable, the most stringen t b eing the well-kno wn Bonferroni correction. The correction we emplo y is the false disco very rate (FDR) control pro cedure of Benjamini and Hoch b erg (1995). Giv en a set of p-v alues p := { p u } u ∈ N corresp onding to n hypothesis tests and a target FDR α ∈ (0 , 1), eac h p-v alue p u ∈ p is asso ciated with an adjusted p-v alue p ∗ u := n p u / j ( u ) where j ( u ) is 6 Community detection in weighted networks the rank of p u in p , and τ ( p ) := max { p u : p ∗ u 6 α } . Benjamini and Hoch b erg sho w that, if the p-v alues corresp onding to true null h yp otheses are independent, the threshold τ ( p ) b ounds the exp ected n umber of false discov eries at α . The up date U α is an exploratory to ol for moving an input set B closer to a “target” comm unity . Consider that, if the initial set B has a ma jorit y group of no des from some strongly-connected communit y C , the statistic S ( u, B , G ) will b e large for u ∈ C , and small otherwise. In this case, U α applied to B will often return man y nodes in C , and few nodes in C c . Indeed, ideally , we should exp ect U α ( C, D ) to return C , giv en strong enough signal in the data. This reasoning motiv ates an algorithm that searches for “stable comm unities” C satisfying U α ( C, D ) = C . By definition, all in terior nodes of a stable communit y C are significan tly connected to C , and exterior no des are not. W e define a stable communit y searc h pro cedure, which iteratively applies U α un til con vergence: Stable comm unity search (SCS) algorithm 1. Given w eighted graph G with no des N and initial set B 1 ⊆ N ; set B 0 := φ , t = 1 2. If B t = B t 0 for some t 0 < t , terminate. 3. Set B t +1 ← U α ( B t , G ) and t ← t + 1. Return to step 2. Since the num b er of possible no de subsets B t is finite, SCS is guaran teed to terminate. There are some technicalities regarding use of this algorithm, lik e how to obtain B 1 , and when in rare cases t 0 < t − 1. W e relegate resolution of these issues to Section 5. F or no w, the update U α and SCS raise t wo theoretical questions: 1. Is the p-v alue p ( u, B , G ) analytically tractable? If not, is there a useful distributional appro ximation based on the con tinuous configuration mo del? 2. Consistency: with what pow er can SCS detect ground-truth comm unit y structure? These questions are the focus of the next section. 4. Theoretical Results W e now address the theoretical questions raised at the end of the previous section b y analyzing the distribution of the test statistic S ( u, B , G ) under the contin uous configuration mo del (for question 1) and an appropriate alternativ e mo del with plan ted comm unity struc- ture (for question 2). Both analyses ha ve an asymptotic setting consisting of a sequence of random weigh ted net works. Denote this sequence by {G n } n> 1 . If G n is a contin uous configuration mo del with parameters θ := ( s , d , κ ), the following proposition giv es general expressions for the mean and standard deviation of S ( u, B , G n ): Prop osition 1 L et G = ( N , A, W ) b e a r andom network gener ate d by the c ontinuous c on- figur ation mo del with p ar ameters θ = ( s , d , κ ) . F or any ( u, B ) ∈ N × 2 N , let µ ( u, B | θ ) and σ ( u, B | θ ) b e, r esp e ctively, the me an and standar d deviation of S ( u, B , G ) under G . Then µ ( u, B | θ ) ≡ µ ( u, B | s ) = X v ∈ B r uv ( s ) (8) 7 P alowitch, Bhamidi and Nobel and σ ( u, B | θ ) 2 = X v ∈ B r uv ( s ) f uv ( d , s ) (1 − ˜ r uv ( d ) + κ ) (9) The pro of, given in App endix A, follo ws from easy calculations with the mo del’s generating pro cedure (see Section 2.1). All theoretical results will mak e use of the expressions defined in equations 8 and 9. 4.1 Asymptotic Normality of S ( u, B , G ) A cen tral limit theorem under the null mo del is now established for S ( u, B , G ), yielding a closed-form appro ximation for the p-v alue in equation (7). This result is motiv ated by the fact that, under most non-trivial n ull parameter sp ecifications, the distribution of S ( u, B , G ) is not analytically tractable. In the setting of the theorem, for an y n > 1, a random netw ork G n is generated b y a contin uous configuration mo del with parameter θ n := ( d n , s n , κ n ) and common weigh t distribution F . The follo wing regularity conditions are required on the sequence { θ n } n> 1 . Let λ n denote the av erage entry of d n , (whic h is the av erage exp ected degree of G n ). F or eac h r > 0 let L n,r := n − 1 P u ∈ N ( d n ( u ) /λ n ) r b e the normalized r th -momen t of d n . Note that L n, 1 = 1. The regularit y conditions are then as follo ws: Assumption 1 Define e n ( u | β ) := s n ( u ) /d n ( u ) 1+ β . Ther e exists β > 0 such that 0 < lim inf n →∞ min u ∈ N e n ( u | β ) and lim sup n →∞ max u ∈ N e n ( u | β ) < ∞ . Assumption 2 L et β b e as in Assumption 1. Ther e exists ε > 0 such that, for b oth r = 4 β + 2 and r = 4 β + 2 + ε , 0 < lim inf n →∞ L n,r and lim sup n →∞ L n,r < ∞ Assumption 3 lim sup n →∞ sup u,v ∈ N r uv ( d n ) < ∞ . Assumption 4 The se quenc e { κ n } n > 1 is b ounde d away fr om zer o and infinity, and F has finite thir d moment. Assumption 1 reflects the common relationship b et w een strengths and degrees in real- w orld w eighted net works (Barrat et al., 2004; Clauset et al., 2009). Assumptions 2-3 are needed to con trol the extremal b ehavior of the degree distribution. They exclude, for instance, cases with a few no des ha ving d n ( u ) n and the remaining no des having d n ( u ) = O (1). W e note that the Assumption 2 b ecomes more stringen t as β increases, since as β increases the strength-degree p o wer law b ecomes more severe. 8 Community detection in weighted networks Theorem 2 F or e ach n > 1 , let G n b e gener ate d by the c ontinuous c onfigur ation mo del with p ar ameter θ n and weight distribution F . Supp ose { θ n } n > 1 and F satisfy Assumptions 1-4. Fix a no de se quenc e { u n } n > 1 with u n ∈ N and a p ositive inte ger se quenc e { b n } n > 1 with b n 6 n . Supp ose d n ( u n ) b n /n → ∞ as n → ∞ . L et B n ⊆ N b e a no de set chosen indep endently of G n ac c or ding to the uniform distribution on al l sets of size b n . Then S ( u n , B n , G n ) − µ n ( u n , B n | θ n ) σ n ( u n , B n | θ n ) ⇒ N (0 , 1) as n → ∞ (10) The pro of is giv en in App endix B. Essentially , Theorem 2 says that S ( u, B , G ) is asymp- totically Normal provided that B is “typical” and that d ( u ) and B are sufficiently large. The theorem justifies the follo wing appro ximation of the p-v alue in (7): p ( u, B ) ≈ 1 − Φ S ( u, B , G ) − µ ( u, B | θ ) σ ( u, B | θ ) (11) Ab o ve, θ = ( d , s , ˆ κ ( d , s )) is specified from G , as describ ed in Section 2.2. 4.2 Consistency of SCS In this section, we ev aluate the ability of the SCS algorithm to identify true com- m unities in a plan ted-communit y mo del. Explicitly , we consider a sequence of net works {G n } n> 1 where each net work in the sequence is generated by a weigh ted sto c hastic blo c k mo del (WSBM). The WSBM w e emplo y is similar to that presen ted in Aicher et al. (2014), but is generalized to include no de-sp ecific weigh t parameters. In other w ords, it is “strength-corrected” as well as degree-corrected, in a manner analogous to the origi- nal degree-corrected SBM (Co ja-Oghlan and Lank a, 2009). The pro ofs of Theorem 4 and Theorem 5 are giv en in Appendix C. 4.2.1 The weighted stochastic block model F or fixed K > 1, w e define a K -block WSBM on n > 1 no des as follo ws. Let c n b e a comm unity partition vector with c n ( u ) ∈ { 1 , . . . , K } giving the comm unity index of u . De- note communit y i b y C i,n := { u : c n ( u ) = i } . Define π i,n := n − 1 | C i,n | with π n the asso ciated v ector. Let P and M b e fixed K × K matrices with non-negativ e en tries enco ding in tra- and in ter-communit y baseline edge probabilities and edge weigh t exp ectations, resp ectively . Let φ n and ψ n b e arbitrary n -v ectors with p ositiv e entries, whic h are parameters giving no des individual prop ensities to form edges and assign weigh t (separately from P and M ). T o ensure prop er edge probabilities, we assume that max( φ n ) 2 max( P ) 6 1. F or identifiabilit y , w e assume the v ectors φ n and ψ n sum to n . Finally , let F b e a distribution on the p ositive real line with mean 1 and v ariance σ 2 > 0. The WSBM can then be sp ecified as follows: 1. Place an edge b et ween no des u and v with probability P n ( A uv = 1) = r uv ( φ n ) P c n ( u ) c n ( v ) , indep enden tly across no de pairs. 2. F or no de pair u, v with A uv = 1, generate an indep endent random v ariable ξ uv ac- cording to F . Determine edge weigh t W uv b y: W uv = ( f uv ( ψ n , φ n ) M c n ( u ) c n ( v ) ξ uv , A uv = 1 0 , A uv = 0 9 P alowitch, Bhamidi and Nobel The many parameters in volv ed with this mo del allo w for node heterogeneit y and com- m unity structure. When P and M are prop ortional to a K × K matrix of ones, the WSBM reduces to the con tin uous configuration mo del with parameters d ∝ φ , s ∝ ψ , and κ = σ 2 . Comm unity structure is introduced in the net work by allo wing the diagonal en tries of P and M to be arbitrarily larger than the off-diagonals. 4.2.2 Consistency theorem The consistency analysis of SCS in volv es a sequence of random netw orks {G n } n> 1 , where G n is generated by a K -communit y WSBM. In this setting, we incorp orate an additional parameter ρ n , and let P n := ρ n P replace P for each n > 1. This lets us distinguish the role of the asymptotic order of the av erage exp ected degree, defined λ n := nρ n , from the profile of edge densities within and b et ween communities ( P ). Imp ortantly , our results require only that λ n / log n → ∞ , reflecting the sparsity of real-w orld netw orks. Throughout this section, w e denote the v ector of (random) strengths from G n b y S n . W e no w define an explicit notion of consistency in terms of the SCS algorithm. Recall from Section 3 that for fixed FDR α ∈ (0 , 1), a stable communit y in a net work G n is defined as a no de set C ⊆ N satisfying U α ( C, G n ) = C . Definition 3 We say that SCS is c onsistent for a se quenc e of WSBM r andom networks {G n } n> 1 if for any FDR level α ∈ (0 , 1) , the pr ob ability that the true c ommunities C 1 ,n , . . . , C K,n ar e stable appr o aches 1 as n → ∞ . T o assess the conditions that allow a target set C to b e a stable communit y , w e seek more general conditions under which the up date U α ( · , G ) outputs C given any initial set B . If U α ( B , G n ) = C , all no des u ∈ C must hav e significant connectivity to B , as judged b y the p-v alue appro ximation defined in 11. It is clear from that p-v alue expression that, for the up date to return C , the test statistic S ( u, B , G n ) must b e significan tly larger than µ ( u, B | S n ), its exp ected v alue under the contin uous configuration mo del. Therefore, our first result hinges on asymptotic analysis of that deviation, which w e denote b y A ( u, B , G n ) := S ( u, B , G n ) − µ n ( u, B | S n ) . (12) The asymptotics of A ( u, B , G n ) dep end on its p opulation v ersion, in which all random quan tities are replaced with their expected v alues under the WSBM. Let s n b e the expected v alue of S n under G n . W e define the (normalized) p opulation v ersion of A ( u, B , G n ) b y ˜ a n ( u, B ) := λ − 1 n ( E S ( u, B , G n ) − µ n ( u, B | ¯ s n )) , (13) where λ n is the order of the a verage exp ected degree. The v alue ˜ a n ( u, B ) is crucial to the primary condition of Theorem 4. Given a sequence of initial sets { B n } n> 1 and target sets { C n } n> 1 , Theorem 4 establishes that U α ( B n , G n ) = C n with probability approac hing 1 if ˜ a n ( u, B ) is b ounded aw ay from zero, and is p ositive if and only if u ∈ C n . The theorem requires the following tw o assumptions: Assumption 5 Ther e exist c onstants m + > m − > 0 such that, for al l n > 1 , the entries of φ n , ψ n , P , M , and π n ar e al l b ounde d in the interval [ m − , m + ] . 10 Community detection in weighted networks Assumption 6 F is indep endent of n and has supp ort (0 , η ) with η < ∞ . Assumption 5 is standard in consistency analyses inv olving blo ck mo dels (e.g. Zhao et al., 2012; Bic k el and Chen, 2009). Assumption 6 allows the use of Bernstein’s inequalit y throughout the pro of, but ma y b e relaxed if there are constraints on the momen ts of F allo wing the use of a similar inequality . W e no w state Theorem 4, the pro of of whic h is giv en in Appendix C. Theorem 4 Fix K > 1 . F or e ach n > 1 , let G n b e a n -no de r andom network gener ate d by a K -c ommunity WSBM with p ar ameters satisfying Assumptions 5 - 6. Supp ose λ n / log n → ∞ . L et { B n } n> 1 , { C n } n> 1 b e se quenc es of no de sets satisfying the fol lowing: ther e exist c onstants q ∈ (0 , 1] and ∆ > 0 such that for al l n sufficiently lar ge, | B n | , | C n | > q n , and ˜ a n ( u, B n ) > ∆ , u ∈ C n , and ˜ a n ( u, B n ) 6 − ∆ , u / ∈ C n . (14) Then if the up date U α uses the p-value appr oximation given in Equation (11) , P n U α ( B n , G n ) = C n → 1 as n → ∞ . T o prov e the consistency of SCS, w e show that condition 14, when it inv olves the com- m unity sequence, is guaran teed by a concise condition on the mo del parameters. Let ˜ π i,n := P v ∈ C i,n ψ n ( v ), and let ˜ π n b e the vector of ˜ π i,n ’s. The consistency theorem re- quires the follo wing additional assumption, an analog to which can b e found in Zhao et al. (2012) for consistency of modularity under the degree-corrected SBM: Assumption 7 ˜ π n ≡ ˜ π do es not dep end on n . Assumption 7 is made mainly for clarit y . Without it, the condition in (15) of Theorem 5 (b elo w) m ust hold for sufficien tly large n , something which is inconsequen tial to the proof. Define H := P · M , the entry-wise product. Note that when φ and ψ are prop ortional to 1-v ectors, E ( W uv ) = H c ( u ) c ( v ) for all u, v ∈ N . Thus, the in terpretation of H is as the baseline inter/in tra-communit y weigh t exp ectations after integrating out edge presence. Defining ˜ Π := ˜ π ˜ π t , w e state the consistency theorem: Theorem 5 Fix K > 0 . L et {G n } n> 1 b e a se quenc e of networks gener ate d by a K - c ommunity WSBM satisfying Assumptions 5-7. Supp ose that the matrix M := H − H ˜ ΠH ˜ π t H ˜ π (15) has p ositive diagonal entries and ne gative off-diagonal entries. If λ n / log n → ∞ , SCS is c onsistent for {G n } n> 1 . The pro of of Theorem 5 is giv en in App endix C. Understanding of condition 15 b e- gins with the consideration of the case K = 2, when it reduces to the requiremen t that H 11 H 22 > H 2 12 . More generally , and broadly sp eaking, the matrix M reveals whether or not appropriate signal exists in the mo del, with resp ect to the contin uous configuration n ull. Notice that this signal need not b e present in b oth P and M . F or instance, the condition can b e satisfied ev en if H is a scalar m ultiple of M , that is, if P is prop ortional to the 1 -matrix. This entails that SCS is consistent even when the edge structure of G n is Erd˝ os-Ren yi, as long as the edge weigh t signal (enco ded in M ) is prop erly assortative. Of course, the opp osite also holds, namely that SCS is consistent ev en when assortative comm unity signal is only present in P . 11 P alowitch, Bhamidi and Nobel 4.2.3 Connection to weighted modularity and rela ted work The conditions of Theorem 4 and Theorem 5 hav e a deep relationship to the mo dularity measure, discussed in Section 2. Explicitly , let the weighte d mo dularit y (WM) b e the mo dularit y metric with degrees replaced by strengths, as introduced in (Newman, 2004a). F or fixed n > 1, let c be any partition of N . Define K := max { c } and C u := { v : c ( v ) = c ( u ) } . Then the (random) WM of c on G n can be written Q w ( c , G n ) := 1 S n,T X uv ∈ N { W uv − r uv ( S n ) } 1 { c ( u ) = c ( v ) } = 1 S n,T K X i =1 X c ( u )= c ( v ) W uv − r uv ( S n ) = 1 S n,T X u ∈ N X v ∈ C u W uv − r uv ( S n ) = 1 S n,T X u ∈ N S ( u, C u , G n ) − µ n ( u, C u | S n ) = 1 S n,T X u ∈ N A ( u, C u , G n ) Th us, the contri bution of u to WM with its assignment C u is precisely the random asso ci- ation from u to C u . W riting the p opulation WM as ¯ q w n ( C ) := n − 1 P u ˜ a n ( u, C u ), it is easily sho wn that condition (15) implies q w n is maximized by C n , the true comm unity partition. The consistency analysis of the (binary) mo dularit y metric under the degree-corrected SBM, provided by Zhao et al. (2012), similarly hinges on maximization of p opulation mo d- ularit y . It is unsurprising, then, that the parameter condition for their result can b e (anal- ogously) expressed as a fixed K × K matrix ha ving p ositive diagonals and negative off- diagonals. In fact, if the WSBM parameter M is prop ortional to a matrix of 1s, and the parameter ψ is a scalar m ultiple of φ , condition 15 in Theorem 5 is equiv alent to the pa- rameter assumptions on mo dularity consistency in Zhao et al. (2012). F urthermore, their analysis also requires that λ n / log n → ∞ . How ever, b oth the definition of consistency and pro of approach for the theorems in this section are entirely nov el. 5. The Con tin uous Configuration Mo del Extraction metho d In the previous section, w e established an asymptotic result showing that ground-truth comm unities are, with high probability , fixed p oints of the SCS algorithm. This result demonstrates the in-principle sensibilit y of the algorithm. In practice, we must rely on lo cal, heuristic algorithms for initialization and termination, as with other exploratory metho ds. F or instance, k -means is often used to initialize the EM algorithm, and mo dularity can b e lo cally maximized through agglomerative pairing (Clauset et al., 2004). W e incorp orate SCS in a general comm unity detection metho d for weigh ted netw orks en titled Con tinuous Configuration Model Extraction (CCME), written in lo ose detail as follo ws: The CCME Comm unity Detection Metho d for W eigh ted Netw orks 1. Given an observ ed w eighted net work G , obtain initial no de sets B 1 ⊆ 2 N . 2. Apply SCS to each no de set in B 0 , resulting in fixed points C . 3. Remov e sets from C that are empty or redundan t. 12 Community detection in weighted networks These steps are describ ed in more detail b elo w. Imp ortan tly , the metho d has no connection to an y graph-partition criteria. It pro ceeds solely by the SCS algorithm, which assesses comm unities indep enden tly . This allo ws CCME to adaptiv ely return communities that share no des (“o verlap”), and, through the m ultiple testing pro cedure, ignore no des not significan tly connected to any stable comm unities (“bac kground”). 5.1 Step 1: Initialization Just as principled mixture-mo dels can b e initialized with heuristic methods like k -means, it is p ossible to initialize CCME with partition-based communit y detection metho d. Ho w- ev er, w e ha ve observ ed this approach to p erform somewhat p oorly in practice. Instead, w e initialize with a nov el searc h procedure based on the contin uous configuration mo del. F or fixed nodes u, v ∈ N , we define z u ( v ) := max W uv − f uv ( s , d ) √ θ f uv ( s , d ) , 0 The measure z u ( v ) acts like a truncated z -statistic, quan tifying the extremity of the weigh t W uv . The initial no de set corresp onding to u is formed b y sampling d ( u ) no des with replacemen t from N with probabilit y prop ortional to z u ( v ). The intuition b ehind this pro cedure is that if u is part of a highly-connected node set C , then z u ( v ) for no des v ∈ C will be larger (on av erage) than for other no des. 5.2 Step 2: Application of SCS Recall that, given an initial set B 1 , SCS pro ceeds (via the up date U α ) along a sequence of sets B 2 , B 3 , . . . , B t , . . . un til B t = B t 0 for some t 0 < t . Since the num b er of p ossible no de subsets is finite, SCS is guaranteed to terminate in one of t wo states: 1. A stable communit y C , satisfying U α ( C, G ) = C . 2. A stable sequence of comm unities C 1 , . . . , C J satisfying U α ( C 1 , G ) = U α ( C 2 , G ) = . . . = U α ( C J , G ) = U α ( C 1 , G ) . In practice, on empirical and sim ulated data, case 1 is the ma jority . In case 2, SCS do es not result in a clear-cut communit y . How ever, a stable sequence may still be of practical in terest if the constituent sets hav e high ov erlap. In App endix D, we giv e a routine to re-initialize or terminate SCS when it encounters a stable sequence. 5.3 Step 3: Filtering of C The CCME comm unity detection metho d returns a final collection of communities C , con taining the results of the SCS algorithm for each initial set in B 0 . By default, we remo ve an y empty or duplicate sets from C . In some applications, pairs of sets in C will hav e high Jaccard similarity . In Appendix E, w e detail a metho d of pruning thes e near-duplicates from C . Additionally , in App endix E, w e describ e routines to suppress the application of SCS to initial sets that are “weakly” intra-connected, or with high o verlap to already-extracted 13 P alowitch, Bhamidi and Nobel comm unities. These routines greatly reduce the runtime of CCME, and, on some simulated net works, improv e accuracy . Remark: W e note that the parameter α , used in the set up date op eration U α , must b e sp ecified b y the user of CCME. Having a natural interpretation as the false-disco very rate for each up date, α w as set to 0 . 05 for all sim ulations and real data analyses introduced in this pap er. W e found that α = 0 . 05 was a universally effective default setting, and that CCME’s results change negligibly for other v alues of α within a reasonable windo w. 6. Sim ulations This section con tains a performance analysis of CCME and existing methods on a b enc hmarking simulation framework. Sim ulated net works are generated from the W eigh ted Sto c hastic Blo ck Mo del (see Section 4.2.1), with sligh t mo difications to include ov erlapping comm unities and background nodes, when necessary . The p erformance measures, comp et- ing methods, simulation settings, and results are described b elow. 6.1 Performance measures and comp eting metho ds T o assess the p erformance of a communit y detection method the v arious metho ds, we use three measures: 1. Ov erlapping Normalized Mutual Information (oNMI): Introduced b y Lanci- c hinetti et al. (2009), oNMI is an information-based measure b et ween 0 and 1 that approac hes 1 as tw o cov ers of the same no de set b ecome similar and equals 1 when they are the same. F rom a metho d’s results, we calculate oNMI with resp ect to the true comm unities only for the no des the method placed in to comm unities. 2. Comm unity no des in background (%C.I.B.): The p ercentage of true comm unity no des incorrectly assigned to background. 3. Bac kground nodes in comm unities (%B.I.C.): The p ercen tage of true back- ground nodes (if presen t) incorrectly placed into communities. In addition to CCME, tw o other w eigh ted-netw ork metho ds capable of iden tifying ov erlap- ping no des are assessed. One of these is OSLOM (Lancic hinetti et al., 2011), describ ed in Section 1. The other is SLP Aw, a w eigh ted-netw ork version of an o verlapping lab el propaga- tion algorithm (Xie et al., 2011). Also included are four commonly used score-based meth- o ds implemen ted in the R pack age igraph (Cs´ ardi and Nepusz, 2006): F ast-Greedy , whic h p erforms appro ximate mo dularit y optimization via a hierarchical agglomeration (Clauset et al., 2004); Louv ain, an approximate mo dularit y optimizer that pro ceeds through no de mem b ership swaps (Blondel et al., 2008); W alktrap, an agglomerativ e algorithm that lo- cally maximizes a score based on random w alk theory (P ons and Latap y , 2006); Infomap, an information-flo w mapping algorithm that uses random walk transition probabilities (Rosv all and Bergstrom, 2008). Remark. Being extraction metho ds, only CCME and OSLOM naturally sp ecify bac k- ground no des, via testing. As suc h, we will often make direct comparativ e commen ts b e- t ween OSLOM and CCME with respect to background no de handling. F or other methods, 14 Community detection in weighted networks w e tak e as bac kground an y nodes in singleton comm unities. How ever, these methods almost nev er returned singleton comm unities, even when the sim ulation had w eak or non-existen t signal. 6.2 Simulation settings and results W e now give an o v erview of the simulation pro cedure for the b enchmarking framework. A complete account is given in App endix F. W e first describ e “default” parameter settings of the WSBM; in the simulation settings b elow, individual parameters are toggled around their default v alues, to reveal the dependence of the metho ds to those parameters. At each unique parameter setting, 20 random netw orks were simulated. The points in eac h plot from Figure 1 show the a verage p erformance measure of the metho ds ov er the 20 rep etitions. The default WSBM setting has the num b er of no des at n = 5 , 000. The comm unity mem b erships were set by obtaining comm unity sizes from a pow er law, then assigning no des uniformly at random. This process pro duced approximately 3 to 7 comm unities p er net work. F ull details are pro vided in App endix F. Recall the parameters P and M , whic h induce baseline intra- and in ter-com m unit y edge and w eigh t signal. In the default setting, these matrices hav e off-diagonals equal to 1 and diagonals equal to constan ts s e = 3 and s w = 3 (resp ectiv ely). In some sim ulation settings, o verlapping and bac kground no des are added (as described later in this section), but the default setting includes neither o verlap nor bac kground. Common parameter settings. F or all simulated net w orks (regardless of the setting), the no de-wise edge parameters φ were drawn from a p o wer law to induce degree hetero- geneit y . The parameter φ is scaled so that the exp ected a verage degree of eac h netw ork w as equal to √ n , which induces sparsity in the netw ork. The parameter ψ is set by the for- m ula ψ = φ 1 . 5 to ensure a non-trivial relationship b et ween expected degrees and exp ected strengths (see App endix F). 6.2.1 Networks with v ar ying signal levels The first simulation setting tested the metho ds’ dep endence on s e and s w . These v alues w ere mo ved along an even grid on the range [1 , 3]. Plots A-1 and B-1 in Figure 1 show the p erformance measure results when s w is fixed at 3, plots A-2 and B-2 show results when s e = 3, and plots A-3 and B-3 sho w results when s e and s w are mo ved along [1 , 3] together. Man y metho ds had large oNMI scores in this simulation setting. W e transformed the oNMI scores using the function t-oNMI a ( x ) := ( 1 1 − x + a − 1 1+ a ) / ( 1 a − 1 1+ a ) with a = 0 . 05. This is a monotonic, one-to-one transformation from [0 , 1] to itself, which stretc hes the region close to 1, allo wing a clearer comparison b et ween the metho ds’ perfor- mances. CCME consistently out-performed all comp eting metho ds, esp ecially when either the edge or w eight signal w as completely absen t. The plots in ro w B show that when either s e or s w w ere near 1, OSLOM and CCME assigned man y background no des. This is consisten t with these metho ds’ unique abilities to leav e no des unassigned when they are not significan tly connected to comm unities. That said, %C.I.B. can be seen as a measure of sensitivity , since ideally no no des w ould be 15 P alowitch, Bhamidi and Nobel assigned to background when any signal is present. In this regard, CCME outp erformed OSLOM across the range of mo del parameters. 6.2.2 Networks with o verlapping communities The second setting in volv ed net works with o verlapping no des. T o add o verlapping no des to the default netw ork, tw o parameters were in tro duced: o n , the num b er of o verlapping no des, and o m , the num b er of memberships for eac h ov erlapping no de. The particular o verlapping no des and comm unity memberships w ere chosen uniformly-at-random. This closely follows a sim ulation approach tak en by Lancic hinetti et al. (2011). Plots C-1 and C-2 sho w p erformance results from the setting with o n mo ving aw ay from 0 and o m = 2. Plot C-3 shows results from the setting with o n = 500 and o m ∈ { 1 , . . . , 4 } . W e find that CCME consisten tly outp erforms all methods in terms of accuracy (oNMI), and outperforms OSLOM in terms of sensitivit y (%C.I.B.). 6.2.3 Networks with o verlapping communities and ba ckgr ound nodes The final sim ulation setting in volv e d net works with b oth o verlap and background nodes. The n umber of background no des was fixed at 1,000, and num b er of communit y no des v aried from n = 500 to n = 5 , 000. F or eac h netw ork, o n = n/ 4 no des w ere randomly c hosen to o verlap o m = 2 comm unities (also chosen at random). Bac kground no des w ere created b y first sim ulating the n -no de communit y sub-netw ork, and then generating the 1,000-no de bac kground sub-net work according to the con tinuous configuration model, using empirical degrees and strengths from the communit y sub-net work. The complete details of this procedure are giv en in App endix F. The results of this sim ulation setting are shown in row D from Figure 1. F rom plot D-1, w e see that OSLOM and CCME had the highest oNMI scores, fav oring OSLOM when the n umber of comm unity no des decreased. Because this sim ulation setting in volv ed background no des, the %B.I.C. metric is relev an t, and can b e taken as a measure of sp ecificit y: ide- ally , no des from the background sub-netw ork should b e excluded from comm unities. F rom plot D-2, w e see that methods incapable of assigning background had %B.I.C. equal to 1. W e found that CCME correctly ignored background no des as the netw ork size increased, whereas OSLOM became increasingly anti -conserv ative for larger net works. F urthermore, CCME again had lo wer %C.I.B. than OSLOM. 7. Applications In this section, we discuss applications of CCME, OSLOM, and SLP Aw (the metho ds capable of returning o verlapping communities) to t wo real data sets. 7.1 U.S. airp ort netw ork data The first application inv olves commercial airline flight data, obtained from the Bureau of T ransp ortation Statistics (www.transtats.bts.go v). F or each month from Jan uary to July of 2015, w e created a weigh ted net work with U.S. airp orts as no des, edges connecting airp orts that exchanged fligh ts, and edges weigh ted by aggregate passenger coun t. W e also constructed a y ear-aggregated netw ork, formed simply b y taking the union of the mon th- 16 Community detection in weighted networks Figure 1: Simulation results describ ed in Sections 6.2.1-6.2.3. Legends refer to all plots. 17 P alowitch, Bhamidi and Nobel wise edge sets, and adding the month-wise weigh ts. In Figure 2, we display the metho ds’ results when applied to the June and year-aggregated data sets from 2015. Each disco vered comm unity (within-metho d) has a unique color and shap e. Eac h o verlapping no de is plotted m ultiple times, one for each communit y in which it was placed. F or a clearer visualization of comm unities, bac kground nodes are not sho wn. Ov erall, the CCME results, in contrast to results from OSLOM and SLP Aw, suggest that man y airp orts in the U.S. airp ort system ma y not participate in meaningful comm unity b eha vior. The fact that CCME p erforms m ultiple testing against an explicit null mo del giv es this result some v alidity . F urthermore, airp orts in significant communities tend to b e lo cated near large hubs or in geographically isolated areas. W e also see that, with the monthly data, OSLOM and CCME tended to find communities consisten t with geograph y , whereas SLP Aw placed most of the net work into one communit y . With the year-aggregated data, OSLOM also agglomerated most airp orts, whereas CCME contin ued to resp ect the geography . Since the aggregated data is m uch more edge-dense, this suggests the p erformance of OSLOM and SLP A may suffer on weigh ted graphs with high or homogeneous edge-density , whereas CCME is able to detect prop er comm unity structure from the w eights alone. This aligns with the simulation results describ ed in Section 6.2.1. 7.2 ENRON emai l net work An email corpus from the compan y ENRON was made av ailable in 2009. The un- w eighted netw ork formed by linking communicating email addresses is well-studied; see www.cs.cm u.edu/ ~ ./enron for references and Lesko vec et al. (2010) for the data. F or the purp oses of this pap er, we derived a weighte d netw ork from the original corpus, using message coun t b et ween addresses as edge weigh ts. Though the corpus was formed from email folders of 150 ENRON executives, we made the net work from addresses found in any message. This full netw ork has 80,702 no des, comprised of a ma jorit y of non-ENR ON addresses, and lik ely man y spam or irrelev an t senders. Th us, the net work has man y p oten tial “true” background no des. W e applied CCME, OSLOM, and SLP Aw to the netw ork to see whic h metho ds b est fo cused on company-specific areas of the data. T ables 1 and 2 give basic summaries of the results, which show noticeable differences b et ween the outputs of the metho ds. CCME placed far fewer into no des into communities, but detected larger communities with more ov erlapping no des. Notably , CCME had the highest percentage of ENRON addresses among nodes it placed in to communities (see T able 3). These results suggest that CCME was more sensitiv e to critical relationships in the net work. T able 1: Metrics from metho ds’ results on ENRON net work: num b er of communities, min- im um communit y size, median communit y size, maximum comm unit y size, count of nodes in an y comm unity Num.Comms Min.size Med.size Max.size Num.Nodes CCME 185 2 687 5416 14552 OSLOM 405 2 19 770 17635 SLP Aw 2138 2 4 4793 79316 18 Community detection in weighted networks Figure 2: SLP Aw, OSLOM, and CCME results from June 2015 and 2015-y ear-aggregated U.S. airport netw orks. Maps created with ggmap (Kahle and Wic kham, 2013). 19 P alowitch, Bhamidi and Nobel T able 2: Metrics from metho ds’ results on ENRON net work: num b er of ov erlapping no des, minim um # of memberships, median # of mem’ships, max. # of mem’ships Num.OL.Nodes Min.mships Med.mships Max.mships CCME 8104 2 9 78 OSLOM 462 2 2 8 SLP Aw 3860 2 2 4 T able 3: T op domains asso ciated with communit y no des from each metho d, b y proportion CCME.Domains Prop. enron.com 0.784 aol.com 0.008 cpuc.ca.gov 0.006 pge.com 0.004 socalgas.com 0.003 dynegy .com 0.003 OSLOM.Domains Prop. enron.com 0.529 aol.com 0.029 haas.berkeley .edu 0.016 hotmail.com 0.015 yahoo.com 0.009 jmbm.com 0.005 SLP Aw.Domains Prop. enron.com 0.423 aol.com 0.039 hotmail.com 0.023 yahoo.com 0.016 haas.berkeley .edu 0.007 msn.com 0.006 8. Discussion In this paper, w e in tro duced the con tinuous configuration model, whic h is, to the best of our kno wledge, the first n ull model for communit y detection on weigh ted netw orks. The explicit generative form of the null mo del allow ed the sp ecification of CCME, a comm unity extraction metho d based on sequential significance testing. W e show ed that a standardized statistic for the tests is asymptotically normal, a result whic h enables an analytic approx- imation to p-v alues used in the metho d. W e also pro ved asymptotic consistency under a w eighted sto chastic blo c k mo del for the core algorithm of the me thod. On simulated netw orks the prop osed method CCME is competitive with commonly-used comm unity detection metho ds. CCME was the dominan t metho d for sim ulated netw orks with large num b ers of o verlapping nodes. F urthermore, on net works with bac kground no des, CCME was the only metho d to correctly lab el true background no des while maintaining high detection p ow er and accuracy for no des b elonging to comm unities. On real data, CCME gav e results that w ere b oth interpretable and revelatory with resp ect to the natural system under study . W e exp ect that the con tinuous configuration mo del will hav e applications outside the setting of this pap er, just as the binary configuration mo del has b een studied in diverse con texts. One ma y inv estigate the distributional prop erties of many differen t graph-based statistics under the model, as a means of assessing statistical significance in practice. F or instance, an appropriate theoretical analysis could yield an approach to the assessmen t of statistical significance of weigh ted mo dularity . Theorem 2 may b e precedent for this endea vor. Another b enefit of an explicit null for weigh ted netw orks is the p oten tial for sim ulation. Using the contin uous configuration mo del, and parts of the framew ork presen ted in this pap er, one can generate weigh ted net works having true bac kground no des with arbitrary expected degree and strength distributions. 20 Community detection in weighted networks 8.1 Ackno wledgements and Remarks The authors thank Dr. Peter J. Muc ha for helpful suggestions ab out the presentation and con textualization of this pap er’s con tributions. The R co de for the CCME metho d is a v ailable in the gith ub rep ository ‘jpalowitc h/CCME’. The co de for reproducing the analyses in Sections 6 and 7 is av ailable at the gith ub repository ‘jpalowitc h/CCME analyses’. App endix A. Pro of of Prop osition 1 Equation 8 follows immediately from the observ ation in equation 3 and the definition of r uv ( s ). Next, note that E ( W uv | A uv ) = f uv ( d , s ) A uv , and V ar( W uv | A uv ) = κf uv ( d , s ) 2 A uv . Th us, using the law of total v ariance, V ar( W uv ) = f uv ( d , s ) 2 V ar( A uv ) + κf uv ( d , s ) 2 E ( A uv ) = f uv ( d , s ) 2 ˜ r uv ( d )(1 − ˜ r uv ( d )) + κf uv ( d , s ) 2 ˜ r uv ( d ) = r uv ( s ) f uv ( d , s ) (1 − ˜ r uv ( d ) + κ ) Summing o v er v ∈ B giv es equation 9. App endix B. Pro of of Theorem 2 and supp orting lemmas. Here we give the pro of of Theorem 2 in Section 4.1. W e start with supp orting lemmas. Recall the definition of the av erage degree parameter λ n , the normalized r th -momen t L n,r , and other asso ciated definitions from Section 4.1. F or the purp oses of the results b elow, we define the following generalization of L n,r , giv en a no de set B n ⊆ N with b n := | B n | : L n,r ( B n ) := b − 1 n X u ∈ B n { d n ( u ) /λ n } r Note that L n,r ( N ) = L n,r . Recall that in the setting of Theorem 2, the no de set B n is c hosen uniformly from the no de set N . The first result inv olves a deterministic sequence { B n } n > 1 : Lemma 6 F or e ach n > 1 , let G n b e gener ate d by the c ontinuous c onfigur ation mo del with p ar ameters θ n = ( d n , s n , κ n ) and c ommon weight distribution F . Fix a no de se quenc e { u n } n> 1 with u n ∈ N and a p ositive inte ger se quenc e { b n } n> 1 with b n 6 n . Supp ose the p ar ameter se quenc e { d n ( u n ) } n > 1 satisfies d n ( u n ) b n n → ∞ as n → ∞ Fix ε > 0 as in Assumption 2 , and cho ose δ ∈ (0 , 1) such that 2 β δ < ε . Fix a se quenc e of sets { B n } n> 1 with | B n | = b n for al l n , and supp ose that for r = 2 β + 1 and r = β (2 + δ ) + 1 , the se quenc e { L n,r ( B n ) } n> 1 is b ounde d away fr om zer o and infinity. Then S ( u n , B n , G n ) − µ n ( u n , B n | θ n ) σ n ( u n , B n | θ n ) ⇒ N (0 , 1) as n → ∞ 21 P alowitch, Bhamidi and Nobel Pro of In what follows, the functions r uv and ˜ r uv from Section 1.2 will b e used extensively . Note that for an y no des u, v , E W uv = r uv ( s ). Thus by the classical Lyapuno v cen tral limit theorem it suffices to sho w that P v ∈ B n E | W u n ,v − r u n v ( s n ) | 2+ δ r P v ∈ B n E { ( W u n ,v − r u n v ( s n )) 2 } ! 2+ δ → 0 (16) as n tends to infinity . The follo wing deriv ations hold for any fixed n > 1, so w e suppress dep endence on n from u n , and B n , and similar expressions. F or the numerator of (16), we ha ve E | W u,v − r uv ( s ) | 2+ δ = r uv ( s ) ˜ r uv ( d ) 2+ δ E | ξ uv A uv − ˜ r uv ( d ) | 2+ δ = f uv ( d , s ) 2+ δ · E | ξ uv A uv − ˜ r uv ( d ) | 2+ δ , (17) b y definition of the mo del in Section 2 . 1. Moreov er, by the la w of total v ariance, E ( | ξ uv A uv − ˜ r uv ( d ) | 2+ δ ) = (1 − ˜ r uv ( d )) ˜ r uv ( d ) 2+ δ + ˜ r uv ( d ) E | ξ uv − ˜ r uv ( d ) | 2+ δ = n (1 − ˜ r uv ( d )) ˜ r uv ( d ) 1+ δ + E | ξ uv − ˜ r uv ( d ) | 2+ δ o · ˜ r uv ( d ) 6 C · ˜ r uv ( d ) (18) for some p ositive constan t C , b y Assumption 4. Next, we note that b y Assumption 1, there exist positive constants a < c such that for all v ∈ N , a · d n ( v ) β 6 s n ( v ) d n ( v ) 6 c · d n ( v ) β , for n sufficiently large. Thus, if r uv ( d ) 6 1, ˜ r uv ( d ) = r uv ( d ), and f uv ( d , s ) = r uv ( s ) ˜ r uv ( d ) = d T s T s ( u ) s ( v ) d ( u ) d ( v ) 6 c · d T s T { d ( u ) d ( v ) } β . (19) If r uv ( d ) > 1, ˜ r uv ( d ) = 1, and by Assumption 3 there exists c 0 suc h that f uv ( d , s ) = s ( u ) s ( v ) s T 6 c · d ( u ) d ( v ) s T { d ( u ) d ( v ) } β = c · d T s T r uv ( d ) { d ( u ) d ( v ) } β 6 c 0 · d T s T { d ( u ) d ( v ) } β . (20) Therefore, com bining (18)-(20) with (17), there exists C > 0 suc h that E | W u,v − r uv ( s ) | 2+ δ 6 C d T s T 2+ δ · { d ( u ) d ( v ) } β (2+ δ ) ˜ r uv ( d ) = C d T s T 2+ δ · { d ( u ) d ( v ) } β (2+ δ ) d ( u ) d ( v ) d T 6 C · d 1+ δ T s − (2+ δ ) T · { d ( u ) d ( v ) } β (2+ δ )+1 (21) 22 Community detection in weighted networks A similar analysis of the summands in the denominator of (16) giv es E ( W u,v − r uv ( s )) 2 > C 0 · d T s − 2 T · { d ( u ) d ( v ) } 2 β +1 (22) for appropriately chosen C 0 . Let b = | B | . Combining (21) and (22), with some algebra, w e find that the left side of (16) is (up to a constan t) less than d ( u ) d T − δ / 2 · P v ∈ B d ( v ) β (2+ δ )+1 P v ∈ B d ( v ) 2 β +1 1+ δ / 2 = d ( u ) d T bλ − δ / 2 · b − 1 P v ∈ B ( d ( u ) /λ ) β (2+ δ )+1 b − 1 P v ∈ B ( d ( u ) /λ ) 2 β +1 1+ δ / 2 = d ( u ) d T bλ − δ / 2 · L n,β (2+ δ )+1 ( B ) ( L n, 2 β +1 ( B )) 1+ δ / 2 = O ( d ( u ) d T bλ − δ / 2 ) (23) where the final term follows from our assumptions on L n,β (2+ δ )+1 ( B n ) and L n, 2 β +1 ( B n ). By definition, d n,T = nλ n , so the final expression ab o v e is O n ( d n ( u n ) b n /n ) − δ / 2 o = o (1) by assumption. Thus (16) holds and the result follows. W e now pro ceed with the pro of of Theorem 2. Prop osition 6 yields the CL T for S ( u n , B n , G n ) for a deterministic sequence of vertex sets { B n } n > 1 satisfying regularity prop erties. The remainder of th e argument shows that if B n is selected uniformly at random then, under the assumptions of Theorem 2, these regularity prop erties are satisfied with high probability . W e b egin with a few preliminary definitions and results. Definition 7 A se quenc e of r andom variables { X n } n > 1 is said to b e asymptotically uni- formly in tegrable if lim M →∞ lim sup n →∞ E {| X n | 1 ( | X n | > M ) } = 0 Theorem 8 L et f : R k 7→ R k b e me asur able and c ontinuous at every p oint in a set C . Supp ose X n w − → X wher e X takes its values in an interval C . Then E f ( X n ) → E f ( X ) if and only if the se quenc e of r andom variables f ( X n ) is asymptotic al ly uniformly inte gr able. Pro of See Asymptotic Statistics (V an der V aart 2000), page 17. W e now give a tec hnical lemma (needed for a subsequent result) which uses Theorem 8: Lemma 9 L et X 1 , X 2 , . . . b e non-ne gative r andom variables and let s, ε > 0 . If the se- quenc es { E X s n } n > 1 and { E X s + ε n } n > 1 ar e b ounde d away fr om zer o and infinity, then { E X r n } n > 1 is b ounde d away fr om zer o and infinity for every r ∈ (0 , s + ε ) . 23 P alowitch, Bhamidi and Nobel Pro of Supp ose b y w ay of con tradiction that there exists t ∈ (0 , s + ε ) such that lim inf n E X t n = 0. Then lim k E X t n k = 0 along a subsequence { n k } . As the random v ariables X t n k are non- negativ e, X t n k d − → 0, and it follows from the contin uous mapping theorem that X n k w − → 0. As M ε/s X s n 1 ( X s n > M ) 6 X s + ε n , w e find that lim M →∞ lim sup k →∞ E { X s n k 1 ( X s n k > M ) } 6 lim M →∞ M − ε/s lim sup k →∞ E ( X s + ε n k ) = 0 as E ( X s + ε n ) is b ounded b y assumption. It then follo ws from Theorem 8 and the fact that X s n k w − → 0 that E X s n k → 0 as k → ∞ , violating our assumption that E X s n is b ounded aw ay from zero. W e conclude that E X r n is b ounded aw ay from zero for r ∈ (0 , s + ε ). On the other hand, if r ∈ (0 , s + ε ) then for each n > 1 E { X r n 1 ( X n > 1) } 6 E { X s + ε n 1 ( X n > 1) } 6 sup n E { X s + ε n } As the last term is finite b y assumption and E { X r n 1 ( X n 6 1) } is at most one, it follo ws that E ( X r n ) is b ounded. Lemma 10 Supp ose a de gr e e p ar ameter se quenc e { d n } n > 1 satisfies Assumption 2 fr om Se ction 4.1. F or e ach n , let B n b e a r andomly chosen subset of N of size b n , wher e b n → ∞ . Fix ε > 0 as in Assumption 2 , and cho ose δ so that 2 β δ < ε . Then for every r ∈ (0 , β (2 + δ ) + 1] , ther e exists an interval I r = ( a r , b r ) with 0 < a r < b r < ∞ such that P { L n,r ( B n ) ∈ I r } → 1 as n → ∞ . Remark: Note that the function L n,r ( · ) is non-random. The probability app earing in the conclusion of Lemma 10 depends only on the random c hoice of the vertex set B n . Pro of Let D n and D 0 n b e dra wn uniformly-at-random from d n without replacemen t, and fix r ∈ (0 , β (2 + δ )]. A routine calculation giv es V ar { L n,r ( B n ) } = b − 1 n λ − 2 r n V ar { D r n } + { b n − 1 } Cov { D r n , ( D 0 n ) r } . Note that E ( D r n ) = λ r n L n,r and E ( D 2 r n ) = λ 2 r n L n, 2 r , so V ar( D r n ) = λ 2 r n ( L n, 2 r − L n,r ). F urther- more, a simple calculation shows that Co v { D r n , ( D 0 n ) r } is negativ e for every r , and therefore V ar { L n,r ( B n ) } 6 b − 1 n ( L n, 2 r − L n,r ). Our choice of δ ensures that 2 r < 4 β + 2 + ε , and it then follo ws from Lemma 9 and Assumption 2 that L n, 2 r and L n,r are b ounded. Thus V ar { L n,r ( B n ) } = O ( b − 1 n ). Define ∆ := lim inf n L n,r / 2, whic h is p ositiv e by Assumption 2, and let I r := lim inf n →∞ L n,r − ∆ , lim sup n →∞ L n,r + ∆ (24) As E { L n,r ( B n ) } = L n,r , an application of Cheb yshev’s inequalit y yields the b ound P { L n,r ( B n ) / ∈ I r } 6 P {| L n,r ( B n ) − E [ L n,r ( B n )] | > ∆ / 2 } 6 4V ar { L n,r ( B n ) } ∆ 2 = O ( b − 1 n ) . As b n tends to infinity with n , the result follo ws. 24 Community detection in weighted networks B.1 Completing the pro of of Theorem 2. Let ε and δ b e as in Prop osition 6 and Lemma 10. Note that since d n ( u n ) 6 n for all n , our assumption that b n d n ( u n ) /n → ∞ implies | B n | = b n → ∞ . Hence by lemma 10, w e hav e that for b oth r = β (2 + δ ) + 1 and r = 2 β + 1, there exists a p ositive, finite interv al I r suc h that P { L n,r ( B n ) ∈ I r } → 1 as n → ∞ . Th us giv en any subsequence { n k } k > 1 w e can find a further subsequence { n 0 k } k > 1 suc h that L n 0 k ,r ( B n 0 k ) ∈ I r almost surely as k → ∞ , whic h means this sequence is bounded aw ay from zero and infinity in k . No w using Proposition 6, for almost ev ery ω w e ha ve S n 0 k ( u n 0 k , B n 0 k , G n 0 k ) − µ n 0 k ( u n 0 k , B n 0 k | θ n 0 k ) σ n 0 k ( u n 0 k , B n 0 k | θ n 0 k ) ⇒ N (0 , 1) as k → ∞ Applying the subsequence principle completes the pro of. App endix C. Pro of of Theorems 4-5 and supp orting lemmas. Throughout this section, notation and con ven tions from Section 4.2.1 will b e used, though w e suppress dep endence on n for conv enience. F urther recall functions r and f from Section 1.2. The following additional notation will b e used throughout this section: • Define φ T := P v ∈ N φ ( v ) and ψ T := P v ∈ N ψ ( v ). F or eac h K > j > 1, define ˜ π 0 j := P v ∈C j φ ( v ) /φ T and ˜ π j := P v ∈C j ψ ( v ) /ψ T . Let ˜ π 0 and ˜ π be the associated vectors. • Let h· , ·i denote the vector dot-pro duct. F or a general symmetric matrix A , let A ij b e the i, j -th entry , and A i the i -th column. Define H := P · M , the entry-wise pro duct. • Let D ( u ) , S ( u ) b e the random degree, strength of node u ∈ N , let ˜ d ( u ), ˜ s ( u ) b e the corresp onding exp ectations, and let D , S , ¯ d , ¯ s b e the asso ciated n -v ectors. Define ¯ s T := P v ∈ N ¯ s ( v ) and ¯ d T := P v ∈ N ¯ d ( v ). W e now define a empiric al p opulation v ersion of the v ariance estimate: Definition 11 Fix n > 1 and let A and W b e the e dge and weight matric es fr om G n , the n -th r andom weighte d network fr om the se quenc e in the setting of The or em 4. L et x , y b e arbitr ary n -ve ctors with p ositive entries. F or no des u, v ∈ N , define V uv ( x , y ) := ( W uv − f uv ( x , y )) 2 , v uv ( x , y ) := E V uv ( x , y ) A uv = 1 . Define the empirical p opulation varianc e estimator as fol lows: κ ∗ ( x , y ) := P u,v : A uv =1 v uv ( x , y ) P u,v : A uv =1 f uv ( x , y ) 2 The estimator κ ∗ ( x , y ) is called “empirical” b ecause it dep ends on the random edge set E . Despite this, it has a deterministic b ound, a fact which is part of Lemma 12. Throughout the remaining results, denote Θ := ( D , S , ˆ κ ( D , S )) and θ ∗ := ( ¯ d , ¯ s , κ ∗ ( ¯ d , ¯ s )), where the estimator ˆ κ is the estimator from Section 2.2. Recall the definition of the asymptotic order of the av erage degree λ n := nρ n , from Section 4.2.2 in the main text. With this and the conv entions ab ov e, Lemma 12 establishes basic facts ab out the WSBM: 25 P alowitch, Bhamidi and Nobel Lemma 12 Fix n > 1 , and let G n b e a r andom network gener ate d by a WSBM. F or al l no des u, v ∈ N , under Assumptions 5 and 6, (1) ¯ d ( u ) = λ n φ ( u ) h ˜ π 0 , P [ c ( u )] i and ¯ s ( u ) = λ n ψ ( u ) h ˜ π , H [ c ( u )] i (2) m 2 − 6 ¯ d ( u ) /λ n 6 m 2 + and m 3 − 6 ¯ s ( u ) /λ n 6 m 3 + (3) m − 6 ¯ d T /nλ n 6 m + and m 2 − 6 ¯ s T /nλ n 6 m 2 + (4) m 4 − /m 1 + 6 r uv ( ¯ d ) /ρ n 6 m 4 + /m 1 − and m 6 − /m 2 + 6 r uv ( ¯ s ) /ρ n 6 m 6 + /m 2 − (5) m 2 − /m 2 + 6 f uv ( φ, ψ ) 6 m 2 + /m 2 − and m 10 − /m 3 + 6 f uv ( ¯ d , ¯ s ) 6 m 10 + /m 3 − (6) 0 6 V uv ( ¯ d , ¯ s ) 6 ( η m 2 + /m 2 − + m 10 + /m 3 − ) 2 (7) 0 6 κ ∗ ( ¯ d , ¯ s ) 6 g ( η , m − , m + ) wher e g is a deterministic function. (8) Ther e exist glob al c onstants 0 < m 1 < m 2 < ∞ indep endent of n such that for any no de set B ⊆ N , m 1 | B | ρ n 6 µ ( u, B | ¯ s ) , σ ( u, B | θ ∗ ) 2 6 m 2 | B | ρ n Pro of F or (1), we hav e ¯ s ( u ) := E S ( u ) = K X j =1 X v ∈C j E W uv = K X j =1 X v ∈C j ρ n r uv ( φ ) H c ( u ) j = ρ n K X j =1 φ ( u ) n ˜ π j H c ( u ) j = λ n φ ( u ) h ˜ π , H c ( u ) i An identical calculation yields the expression for ¯ d ( u ). The inequalities in (2) then follo w from Assumption 5. F or (3), we again apply Assumption 5 to the equation ¯ s T = K X i =1 X v ∈C i ¯ s ( u ) = K X i =1 nλ n φ ( u ) h ˜ π , H i i = nλ n ˜ π T H ˜ π An identical equation yields the inequality for ¯ d T . (2) and (3) directly yield the inequalities in (4). Note that Assumption 5 implies m 2 − 6 nr uv ( φ ) , nr uv ( ψ ) 6 m 2 + , which yields the first inequalit y of (5). The second inequalit y of (5) follo ws from (4). F or part (6), note that by Assumption 6 and the first inequality in (5), w e ha ve W uv := f uv ( φ, ψ ) ξ uv 6 ( m 2 + /m 2 − ) η (25) The second inequality in (5) then yields (6). F or part (7), recalling the definition of κ ∗ ( ¯ d , ¯ s ) from Definition 11, note first that, b y (6), 0 6 v uv ( ¯ d , ¯ s ) 6 ( η m 2 + /m 2 − + m 10 + /m 3 − ) 2 . Thus, b y the second inequality (5), 0 6 κ ∗ ( ¯ d , ¯ s ) := P u,v : A uv =1 v uv ( ¯ d , ¯ s ) P u,v : A uv =1 f uv ( ¯ d , ¯ s ) 6 ( η m 2 + /m 2 − + m 10 + /m 3 − ) 2 m 10 − /m 3 + 26 Community detection in weighted networks F or part (8), recall that µ ( u, B | ¯ s ) := X v ∈ B r uv ( ¯ s ) The first inequality in (8) follo ws from applying the second inequality in (4). Similarly , σ ( u, B | θ ∗ ) 2 := X v ∈ B r uv ( ¯ s ) f uv ( ¯ d , ¯ s )(1 − ˜ r uv ( ¯ d ) + κ ∗ ( ¯ d , ¯ s )) The second inequality in part (8) follows from parts (4), (5), and (7). The next lemma shows that, if the degrees and strengths of G n are bounded around their exp ected v alues, the empirical estimate of v ariance is b ounded around the conditional p opulation estimate, and the co efficien t of v ariation of S n ( u, B ) is b ounded around its p opulation v alue. Define D T := P u ∈ N D ( u ) as the (random) total degree. Recall that λ n is the asymptotic order the av erage of the exp e cte d degrees ¯ d T . Lemma 13 Fix n > 1 . Supp ose Assumption 5 holds. Define M ( D , S ) := max u ∈ N | S ( u ) − ¯ s ( u ) | , | D ( u ) − ¯ d ( u ) | . (26) Then the fol lowing statements hold: (1) Ther e exists smal l enough t > 0 such that if M ( D , S ) 6 λ n t , ˆ κ ( D , S ) − κ ∗ ( ¯ d , ¯ s ) = P u,v : A uv =1 V uv ( ¯ d , ¯ s ) − v uv ( ¯ d , ¯ s ) P u,v : A uv =1 f uv ( ¯ d , ¯ s ) 2 + D T ρ n O ( t ) + ρ n O ( t ) (2) Fix a c onstant ε > 0 indep endent of n . Assume | ˆ κ ( D , S ) − κ ∗ ( ¯ d , ¯ s ) | 6 ε . Then then ther e exists smal l enough t > 0 (not dep ending on ε ) such that if M ( D , S ) 6 t , for al l B ⊆ N , we have µ ( u, B | Θ) σ ( u, B | Θ) − µ ( u, B | θ ∗ ) σ ( u, B | θ ∗ ) = p | B | ρ n O ( t ) Pro of M ( D , S ) 6 λ n t implies there exists a n -vector a t with comp onents in the in terv al [ − 1 , 1] suc h that S ( u ) = ¯ s ( u ) + λ n ta t ( u ). Therefore, defining ¯ a t := n − 1 P v a t ( v ), r uv ( S ) − r uv ( ¯ s ) = { ¯ s ( u ) + λ n a t ( u ) t }{ ¯ s ( v ) + λ n a t ( v ) t } ¯ s T + nλ n ¯ a t t − ¯ s ( u ) ¯ s ( v ) ¯ s T = ¯ s T { ¯ s ( u ) a t ( v ) + ¯ s ( v ) a t ( u ) + λ n a t ( u ) a t ( v ) t } λ n t − ¯ s ( u ) ¯ s ( v ) nλ n ¯ a t t ¯ s T { ¯ s T + nλ n ¯ a t t } = ¯ s ( u ) a t ( v ) + ¯ s ( v ) a t ( u ) + λ n a t ( u ) a t ( v ) t − r uv ( ¯ s ) n ¯ a t ¯ s T + nλ n ¯ a t t λ n t Using parts (2)-(4) of Lemma 12, for sufficien tly small t we hav e r uv ( S ) − r uv ( ¯ s ) 6 2 λ n m 3 + + λ n t + ρ n ( m 6 + /m 2 − ) n nλ n m 2 − − nλ n t λ n t = 2 m 3 + + t + ( m 6 + /m 2 − ) m 2 − − t ρ n t 27 P alowitch, Bhamidi and Nobel Therefore, | r uv ( S ) − r uv ( ¯ s ) | = ρ n O ( t ) (27) as t → 0. By a similar argument, | r uv ( D ) − r uv ( ¯ d ) | = ρ n O ( t ). It follo ws that | f uv ( D , S ) − f uv ( ¯ d , ¯ s ) | = ρ n O ( t ) . (28) Therefore, using Equations 27-28 and part (7) of Lemma 12, V uv ( D , S ) := ( W uv − f uv ( D , S )) 2 = ( W uv − f uv ( ¯ d , ¯ s )) 2 + 2( W uv − f uv ( ¯ d , ¯ s ))( f uv ( ¯ d , ¯ s ) − f uv ( D , S )) + ( f uv ( ¯ d , ¯ s ) − f uv ( D , S )) 2 = V uv ( ¯ d , ¯ s ) 2 + 2 V uv ( ¯ d , ¯ s )( f uv ( ¯ d , ¯ s ) − f uv ( D , S )) + ( f uv ( ¯ d , ¯ s ) − f uv ( D , S )) 2 6 V uv ( ¯ d , ¯ s ) 2 + ρ n O ( t ) + ρ 2 n O ( t 2 ) = V uv ( ¯ d , ¯ s ) 2 + ρ n O ( t ) Define the following: V T := X u,v : A uv =1 V uv ( D , S ) , ¯ V T := X u,v : A uv =1 V uv ( ¯ d , ¯ s ) . Since D T := P u ∈ N D ( u ) = P u,v : A uv =1 1, the ab ov e inequalit y implies that V T = ¯ V T + D T ρ n O ( t ). Define similarly: g T := X u,v : A uv =1 f uv ( D , S ) 2 , ¯ g T := X u,v : A uv =1 f uv ( ¯ d , ¯ s ) 2 . Similar logic gives g T = ¯ g T + D T ρ n O ( t ). Finally , define ¯ v T := P u,v : A uv =1 v uv ( ¯ s , ¯ d ). Then ˆ κ ( D , S ) − κ ∗ ( ¯ d , ¯ s ) = V T g T − ¯ v T ¯ g T = ¯ V T + D T ρ n O ( t ) ¯ g T + D T ρ n O ( t ) − ¯ v T ¯ g T = ¯ V T + D T ρ n O ( t ) − ¯ v T ¯ g T { ¯ g T + D T ρ n O ( t ) } ¯ g T + D T ρ n O ( t ) 6 ¯ V T − ¯ v T ¯ g T + D T ρ n O ( t ) + D T ρ n O ( t ) − ¯ v T ¯ g T D T ρ n O ( t ) ¯ g T + D T ρ n O ( t ) Note that ¯ v T /D T and ¯ g T /D T are, each, by parts (5) and (6) of Lemma 12, bounded ab o ve and below by constants indep enden t of A , t , and n . Therefore, dividing through by D T , D T ρ n O ( t ) − ¯ v T ¯ g T D T ρ n O ( t ) ¯ g T + D T ρ n O ( t ) 6 ρ n O ( t ) ¯ g T /D T + ρ n O ( t ) = ρ n O ( t ) This prov es part 1. F or part 2, first recall that µ ( u, B | Θ) ≡ µ ( u, B | S ) := P v ∈ B r uv ( S ). Therefore b y Equation 27, w e hav e | µ ( u, B | Θ) − µ ( u, B | θ ∗ ) | = X v ∈ B r uv ( S ) − r uv ( ¯ s ) = | B | ρ n O ( t ) (29) 28 Community detection in weighted networks Recall further that σ ( u, B | Θ) 2 := X v ∈ B r uv ( S ) f uv ( D , S ) (1 − r uv ( D ) + ˆ κ ( D , S )) Using some straightforw ard algebra and applying Equations 27-28, w e ha ve σ ( u, B | Θ) 2 − σ ( u, B | θ ∗ ) 2 = | B | 1 + ˆ κ ( D , S ) − κ ∗ ( ¯ d , ¯ s ) ρ n O ( t ) = | B | ρ n O ( t ) (30) where the second line follo ws from the assumption that | ˆ κ ( D , S ) − κ ∗ ( ¯ d , ¯ s ) | 6 ε . W e will no w b ound σ ( u, B | Θ) close to σ ( u, B | θ ∗ ) using Equation 30 and a T aylor expansion. Define the function h ( x, σ ) := √ σ 2 + x . F or fixed σ , a T aylor expansion around x = 0 gives h ( x, σ ) = σ + P ∞ k =1 ( − 1) k x k k ! σ 2 k − 1 . Setting x = σ ( u, B | Θ) 2 − σ ( u, B | θ ∗ ) 2 and σ = σ ( u, B | θ ∗ ) and applying Equation 30, w e obtain σ ( u, B | Θ) = h ( x, σ ( u, B | θ ∗ )) = σ ( u, B | θ ∗ ) + ∞ X k =1 ( − 1) k | B | k ρ k n O ( t k ) k ! σ ( u, B | θ ∗ ) 2 k − 1 (31) P art (8) of Lemma 12 implies that σ ( u, B | θ ∗ ) p | B | ρ n . Equation 31 therefore gives σ ( u, B | Θ) = σ ( u, B | θ ∗ ) + p | B | ρ n O ( t ) (32) using Equations 29 and 32, we write µ ( u, B | Θ) σ ( u, B | Θ) − µ ( u, B | θ ∗ ) σ ( u, B | θ ∗ ) = µ ( u, B | θ ∗ ) + | B | ρ n O ( t ) σ ( u, B | θ ∗ ) + p | B | ρ n O ( t ) − µ ( u, B | θ ∗ ) σ ( u, B | θ ∗ ) (33) As shorthands, define ¯ µ n := µ ( u, B | θ ∗ ) / | B | ρ n and ¯ σ n := σ ( u, B | θ ∗ ) / p | B | ρ n . P art (8) of Lemma 12 implies that ¯ µ n , ¯ σ n 1. Th us, using Equation 33 and dividing through by the appropriate factors, µ ( u, B | Θ) σ ( u, B | Θ) − µ ( u, B | θ ∗ ) σ ( u, B | θ ∗ ) = p | B | ρ n ¯ µ n + O ( t ) ¯ σ n + O ( t ) − ¯ µ n ¯ σ n = p | B | ρ n O ( t ) This completes part 2. The pro of of Lemma 4 from the main text (below) makes use of Lemma 13 by sho wing that its assumption holds with high probability , for appropriate t . C.1 Pro of of Theorem 4 Throughout, we will sometimes suppress dep endence on n for notational con venience. Recall that A ( u, B , G ) := S ( u, B , G ) − µ ( u, B | S ), the deviation of the CCME test statistic 29 P alowitch, Bhamidi and Nobel from its exp ected v alue under the con tinuous configuration mo del. Recalling that Θ := ( D , S , ˆ κ ( D , S )), define also the random Z -statistic Z ( u, B , G | Θ) := A ( u, B , G ) σ ( u, B | Θ) . (34) Define the random p-v alue P ( u, B , G | Θ) := 1 − Φ( Z ( u, B , G | Θ)) . (35) The random v ariable P ( u, B , G | Θ) is the random version of the p-v alue p ( u, B n | θ ) obtained from the appro ximation in Equation (11). As a consequence of the Benjamini-Ho ch b erg pro cedure, the even t { U α ( B n , G ) = C n } will o ccur if P ( u, B n , G n | Θ) 6 q α , for all u ∈ C n , and P ( u, B n , G n | Θ) > q α , for all u / ∈ C n , (36) since b y assumption | C n | > q n . Let h b e the densit y function of a standard-Normal. By a w ell-known inequality for the CDF of a standard-Normal, if Z ( u, B n , G n | Θ) > 0, P ( u, B n , G n | Θ) 6 1 Z ( u, B n , G n | Θ) h ( Z ( u, B n , G n | Θ)) . (37) By symmetry , if Z ( u, B n , G n | Θ) < 0, then P ( u, B n , G n | Θ) > 1 + 1 Z ( u, B n , G n | Θ) h ( Z ( u, B n , G n | Θ)) . (38) W e therefore analyze the concentration prop erties of Z ( u, B n , G n | Θ) and apply Inequalities 37 and 38 to sho w that for sufficiently large n , the ev en t in Equation 36 o ccurs with high probabilit y . W e will fo cus on the first line of 36 first; the second is sho wn similarly . Recall that θ ∗ is the empirical p opulation null parameters of G n , defined after Definition 11. F or the deriv ation below w e use the follo wing shorthands: Y ≡ S ( u, B n , G n ), µ ≡ µ ( u, B n | S n ), σ := σ ( u, B n | Θ), ¯ y ≡ E Y , ¯ µ ≡ µ ( u, B n | θ ∗ ), and ¯ σ := σ ( u, B n | θ ∗ ). Note Z ( u, B n , G n | Θ) := Y − µ σ = Y − ¯ µ ¯ σ − µ σ − ¯ µ ¯ σ = ¯ y − ¯ µ ¯ σ + Y − ¯ y ¯ σ − µ σ − ¯ µ ¯ σ > ¯ y − ¯ µ ¯ σ − Y − ¯ y ¯ σ − µ σ − ¯ µ ¯ σ (39) Define ¯ z ( u, B n | θ ∗ ) := ¯ y − ¯ µ ¯ σ = λ n ˜ a ( u, B n | ¯ s ) σ ( u, B n | θ ∗ ) where ˜ a ( u, B n | ¯ s ) is the normalized p opulation v ersion of A ( u, B n | S ), as defined in Equa- tion 13 from the main text. The definition ab ov e w orks with Equation 39 to pro duce the illustrativ e inequalit y Z ( u, B n , G n | Θ) > ¯ z ( u, B n | θ ∗ ) − Y − ¯ y ¯ σ − µ σ − ¯ µ ¯ σ . (40) 30 Community detection in weighted networks Inequalit y 40 exemplifies that, if the righ t-hand terms v anish, Z ( u, B n , G n | Θ) can be appro x- imated by a p opulation version. Our analysis therefore reduces to b ounding the right-hand order terms in probabilit y . Explicitly , consider that b y part (8) of Lemma 12, there exists m 2 > 0 such that σ ( u, B n | θ ∗ ) 2 6 m 2 nρ n = m 2 λ n . Combining this with the crucial assumption on ˜ a ( u, B n ) from line 14 from the main text, w e ha ve that for all u ∈ C n , ¯ z ( u, B n | θ ∗ ) = λ n ˜ a ( u, B n | ¯ s ) σ ( u, B n | θ ∗ ) > p λ n ∆ √ m 2 (41) Therefore, the rest of the pro of is mainly dedicated to sho wing that the final tw o terms in line (40) are o P ( √ λ n ). This will imply that Z ( u, B n , G n | Θ) = Ω P ( √ λ n ) and, using Inequal- it y 37, that { P ( u, B n , G n | Θ) 6 q α , ∀ u ∈ C n } has probability approaching 1. Step 1: | µ σ − ¯ µ ¯ σ | = O P ( √ log n ) F or t > 0, define the ev en t E 1 ( t ) := max u ∈ N | S ( u ) − ¯ s ( u ) | , max u ∈ N D ( u ) − ¯ d ( u ) 6 λ n t (42) Fix arbitrary b > 0 indep endent of all other quan tities and define t n ( b ) := q b log n λ n . Note that t n ( b ) → 0 for an y b , b y the assumptions of the Theorem. Recall that D T := P u ∈ N D ( u ), the (random) total degree. F or notational conv enience, let E := { pairs u, v : A uv = 1 } . By part 1 of Lemma 13, the even t E 1 ( t n ( b )) implies ˆ κ ( D , S ) − κ ∗ ( ¯ d , ¯ s ) = P E V uv ( ¯ d , ¯ s ) − v uv ( ¯ d , ¯ s ) P E f uv ( ¯ d , ¯ s ) 2 + D T ρ n O ( t n ( b )) + ρ n O ( t n ( b )) (43) By Lemma 12 part (5), 0 6 V uv ( ¯ d , ¯ s ) 6 ( η m 2 + /m 2 − + m 10 + /m 3 − ) 2 . Recall that v uv ( ¯ d , ¯ s ) := E V uv ( ¯ d , ¯ s ), and that the edge weigh ts that comprise the (upp er- triangle of the) weigh t matrix W are independent. F or a fixed adjacency matrix A , Bern- stein’s Inequalit y therefore gives P X E V uv ( ¯ d , ¯ s ) − v uv ( ¯ d , ¯ s ) > p b log n A ! 6 2 exp ( − 2 b log n 2 a 1 + 2 3 a 2 √ b log n ) (44) No w b y Lemma 12 part (6), P E f uv ( ¯ d , ¯ s ) 2 > D T m 10 − m 3 + . Thus X E f uv ( ¯ d , ¯ s ) 2 + D T ρ n O ( t n ( b )) > D T m 10 − m 3 + / 2 31 P alowitch, Bhamidi and Nobel for large enough n , since ρ n t n ( b ) → 0. Therefore there exist constants a 1 , a 2 > 0 dep ending only on m + , m − , and η suc h that P P E V uv ( ¯ d , ¯ s ) − v uv ( ¯ d , ¯ s ) P E f uv ( ¯ s , ¯ d ) 2 + D T ρ n O ( t n ( b )) > q b log n D T A ! 6 2 exp − 2 b log n 2 a 1 + 2 3 a 2 q b log n D T (45) The ab o ve expression is conditional on a fixed adjacency matrix A . W e now b ound in probabilit y the functionals of A on which the expression depends. It is easily deriv able from the statement of the WSBM and Assumption 5 that there exist constants a 3 , a 4 dep ending on m + and m − suc h that E ( D T ) = a 3 nλ n and V ar( D T ) = a 4 nλ n . Therefore, by another application of Bernstein’s Inequalit y , P | D T − a 3 nλ n | > p nλ n b log n 6 2 exp − 2 b log n 2 a 4 + 2 3 q b log n nλ n (46) Applying this to inequalit y (45), the la w of total probability gives P P E V uv ( ¯ d , ¯ s ) − v uv ( ¯ d , ¯ s ) P E f uv ( ¯ s , ¯ d ) 2 + D T ρ n O ( t n ( b )) > s b log n a 3 nλ n − √ nλ n b log n ! 6 2 exp − 2 b log n 2 a 1 + 2 3 a 2 q b log n a 3 nλ n − √ nλ n b log n + 2 exp − 2 b log n 2 a 4 + 2 3 q b log n nλ n = O ( n − b ) (47) for sufficien tly large n . Along with Equation (43), this implies there exists a constant A 0 dep ending on parameter constrain ts suc h that P ( ˆ κ ( D , S ) − κ ∗ ( ¯ d , ¯ s ) 6 A 0 r b log n nλ n + ρ n t n ( b ) !) > P ( E 1 ( t n ( b ))) − O ( n − b ) (48) for sufficiently large n . W e now assess P ( E 1 ( t n ( b ))). Note that for all u ∈ N , V ar( S ( u )) = O ( λ n ). F urthermore, recall from Inequalit y 25 (in the pro of of Lemma 12) that W uv 6 m 2 + η /m 2 − for all u, v ∈ N . F or fixed b > 0, Bernstein’s Inequality therefore giv es, for any u ∈ N , P | S ( u ) − ¯ s ( u ) | > p b log nλ n 6 2 exp − 2 a 0 b log n 2 + 2 3 q b log n λ n , (49) where a 0 is a constant indep endent of n . The constant a 0 ma y b e chosen so that, similarly , P D ( u ) − ¯ d ( u ) > p b log nλ n 6 2 exp − 2 a 0 b log n 2 + 2 3 q b log n λ n (50) Applying a union b ound, equations (49) and (50) give P ( E 1 ( t n ( b ))) > 1 − 2 n exp − 2 a 0 b log n 2 + 2 3 q b log n λ n − 2 n exp − 2 a 0 b log n 2 + 2 3 q b log n λ n = 1 − O ( n − b +1 ) (51) 32 Community detection in weighted networks for sufficien tly large n . Returning to the inequalit y in (48), we therefore ha ve P ˆ κ ( D , S ) − κ ∗ ( ¯ d , ¯ s ) 6 A 0 q b log n nλ n + ρ n t n ( b ) > P ( E 1 ( t n ( b ))) − O ( n − b ) > 1 − O ( n − b +1 ) (52) for sufficien tly large n . Recall that by assumption, λ n / log n → ∞ . Thus t n ( b ) → 0, and q b log n nλ n + ρ n t n ( b ) = t n ( b ) / √ n + ρ n t n ( b ) 6 1 / √ n = o (1) . Th us, Inequalit y 52 implies that P ˆ κ ( D , S ) − κ ∗ ( ¯ d , ¯ s ) 6 ε > 1 − O ( n − b +1 ) , (53) for sufficiently large n . F or ε > 0, define the ev ent E 2 ( ε ) := ˆ κ ( D , S ) − κ ( ¯ d , ¯ s ) 6 ε . By part 2 of Lemma 3, the even t E 1 ( t n ( b )) ∩ E 2 ( ε ) implies µ σ − ¯ µ ¯ σ := µ ( u, B n | S ) σ ( u, B n | Θ) − µ ( u, B n | ¯ s ) σ ( u, B n | θ ∗ ) = p | B n | ρ n O ( t n ( b )) 6 p λ n O ( t n ( b )) . = O ( p b log n ) (54) Therefore, there exists a constan t A 2 > 0 such that, b y Inequalities 51 and 53, P µ σ − ¯ µ ¯ σ 6 A 2 p b log n = 1 − O ( n − b +1 ) (55) for sufficien tly large n . This completes Step 1. Step 2: | Y − ¯ y ¯ σ | = O P ( √ log n ) . Note that, as for Inequalit y 49, Bernstein’s Inequality giv es P | S ( u, B n , G n ) − E S ( u, B n , G n ) | > p b log nλ n 6 2 exp − 2 a 0 b log n 2 + 2 3 q b log n λ n (56) By Lemma 12 part (8), there exists m 2 > 0 such that σ ( u, B n | θ ∗ ) 2 6 m 2 λ n . Thus, Y − ¯ y ¯ σ := S ( u, B n , G n ) − E S ( u, B n , G n ) σ ( u, B n | θ ∗ ) > S ( u, B n , G n ) − E S ( u, B n , G n ) m 2 √ λ n , so b y Inequalit y 56, we hav e for sufficiently large n that P Y − ¯ y ¯ σ 6 r b log n m 2 ! > 1 − O ( n − b ) . (57) This completes Step 2. 33 P alowitch, Bhamidi and Nobel W e now recall inequalit y 40: Z ( u, B n , G n | Θ) > ¯ z ( u, B n | θ ∗ ) − Y − ¯ y ¯ σ − µ σ − ¯ µ ¯ σ . In step 1, we show ed that there exists a constan t A 2 dep ending only on the fixed WSBM mo del parameters such that for any fixed b > 1, for large enough n , µ σ − ¯ µ ¯ σ 6 A 2 √ b log n with probabilit y 1 − O ( n − b +1 ). In step 2, w e show ed that there exists a constant m 2 dep ending only on the fixed WSBM mo del parameters suc h that for any fixed b > 1, for large enough n , | Y − ¯ y ¯ σ | 6 p b log n/m 2 with probability 1 − O ( n − b ). Recall furthermore from inequalit y 41 that ¯ z ( u, B n | θ ∗ ) > ∆ p λ n /m 2 , where ∆ is from condition 14 in the statement of the Theorem. W e can therefore write that for any fixed b > 1, for large enough n , Z ( u, B n , G n | Θ) > ∆ p λ n /m 2 − p b log n/m 2 − A 2 p b log n = A 3 p λ n − A 4 p b log n with probability at least 1 − O ( n − b +1 ). No w, b y assumption, | C n | > q n . Therefore, using Inequalit y 37 and a union b ound, we can write that for any fixed b > 1, for large enough n , max u ∈ C n P ( u, B n , G n | Θ) 6 exp {− ( A 3 p λ n − A 4 p b log n ) 2 } (58) with probability at least 1 − O ( n − b +2 ). Note that for an y fixed b , the right-hand-side of inequality 58 v anishes, due to the assumption that λ n / log n → ∞ . Thus, for b > 2, inequalit y 58 implies that for large enough n (no w dep ending on choice of b ), the ev ent { P ( u, B n , G n | Θ) 6 q α , ∀ u ∈ C n } has probability 1 − O ( n − b +2 ) → 1. It can b e similarly shown that the second half of the ev ent in (36) has probabilit y approac hing 1. Instead of Inequalit y 40 we (similarly) deriv e Z ( u, B n , G n | Θ) 6 ¯ z ( u, B n | θ ∗ ) + Y − ¯ y ¯ σ + µ σ − ¯ µ ¯ σ (59) This is useful b ecause if u / ∈ C n , assumption (14) ensures that ˜ a n ( u, B n ) ¯ s < − ∆, and hence ¯ z ( u, B n | θ ∗ ) := ¯ y − ¯ µ ¯ σ = λ n ˜ a ( u, B n | ¯ s ) σ ( u, B n | θ ∗ ) 6 λ n − ∆ σ ( u, B n | θ ∗ ) 6 p λ n − ∆ √ m 1 where the last inequalit y follo ws from part (8) of Lemma 12. Steps 1 and 2 therefore work to sho w that for an y fixed b > 1, for large enough n , Z ( u, B n , G n | Θ) 6 − ∆ p λ n /m 2 + p b log n/m 2 + A 2 p b log n = A 3 p λ n − A 4 p b log n With probabilit y 1 − O ( n − b +1 ). Inequality 38 then implies that P max u / ∈ C n P ( u, B n , G n | Θ) > 1 − exp {− ( A 3 p λ n − A 4 p b log n ) 2 } > 1 − O ( n − b +2 ) (60) With reasoning identical to the result for u ∈ C n , this implies that for any b > 2, for large enough n ( b ), the ev ent { P ( u, B n , G n | Θ) > q α, ∀ u / ∈ C n } has probabilit y at least 1 − O ( n − b +2 ) → 1. Applying a union b ound to the ev ent in (36) completes the pro of. 34 Community detection in weighted networks C.2 Pro of of Theorem 5 W e will show that if the condition in (15) holds, then the condition in (14) from Theorem 4 holds when B n = C n = C j,n sim ultaneously across all j ∈ { 1 , 2 , . . . , K } . This in volv es rep- resen ting (14) in terms of the model parameters when B n = C n = C j,n . Sp ecifically , w e de- riv e the normalized p opulation deviation ˜ a ( u, C j,n | ¯ s ) := ( E S ( u, C j,n , G n ) − µ ( u, C j,n | ¯ s )) /λ n . First, note that for an y fixed j 6 K , part (1) of Lemma 12 gives X v ∈ C j,n ¯ s ( v ) = λ n h ˜ π , H j i · X v ∈ C j,n ψ ( u ) = nλ n h ˜ π , H j i ˜ π j and th us ¯ s T := X v ∈ N ¯ s ( v ) = K X j =1 X v ∈ C j,n ¯ s ( v ) = nλ n K X j =1 h ˜ π , H j i ˜ π j = nλ n ˜ π t H π . Therefore, again applying part (1) of Lemma 12, µ ( u, C j,n | ¯ s ) := X v ∈ C j,n r uv ( ¯ s ) = ¯ s ( u ) X v ∈ C j,n ¯ s ( v ) ¯ s T = ¯ s ( u ) h ˜ π , H j i ˜ π j ˜ π t H ˜ π = λ n ψ ( u ) h ˜ π , H c ( u ) ih ˜ π , H j i ˜ π j ˜ π t H ˜ π . Secondly , E S ( u, C j,n , G n ) = X v ∈ C j,n E W uv = X v ∈ C j,n ρ n r uv ( ψ ) H c ( u ) j = λ n ψ ( u ) H c ( u ) j ˜ π j . Th us, ˜ a ( u, C j,n | ¯ s ) := E S ( u, C j,n , G n ) − µ ( u, C j,n | ¯ s ) λ n = ψ ( u ) ˜ π j H c ( u ) j − h ˜ π , H c ( u ) ih ˜ π , H j i ˜ π t H ˜ π . (61) If u ∈ C i,n , the expression in the paren theses from the righ t-hand-side of (61) is the i, j -th elemen t of the matrix H − H ˜ ΠH / ˜ π t H ˜ π , with ˜ Π := ˜ π ˜ π t . By Assumption 5, ψ ( u ) > m − for all u ∈ N and i 6 K , and ˜ π j is fixed. Th us, (15) ensures that (14) holds when C n = C j,n , sim ultaneously for j 6 K . Assumption 5 also ensures that there exists q > 0 such that for all j 6 K and n > 1, | C j,n | > q n . This allows us to apply Theorem 4 to the sequences B n = C n = C j,n , for each j 6 K . A union b ound pro ves the result. App endix D. Cycles in Fixed Poin t Search As remark ed in Section 5.2, it is p ossible for the SCS algorithm to reach a stable sequence C 1 , . . . , C J that is trav ersed by the up date U α ( · , G ). If this happ ens, we apply the follo wing routine to re-start the algorithm, or return the union of the sequence: 35 P alowitch, Bhamidi and Nobel 1. If C i ∩ C i +1 = φ for an y i 6 J , or if C J ∩ C 1 = φ , terminate the iterations and do not extract a communit y . 2. Otherwise, define C ∗ = ∪ J i =1 C i , and: (a) If C ∗ has been visited previously by SCS, extract C ∗ in to C . (b) Otherwise, re-initialize with C ∗ . App endix E. Filtering of B 0 and C T o filter through B 0 and C , we use an inference pro cedure based on a set-wise z -statistic, analogous to the no de-set z -statistic presented in Section 4. Define S ( B ) := P v ∈ B S ( v , B ). Note that S ( B ) has an easily deriv able expectation and standard deviation under the con- tin uous configuration mo del, which w e denote (resp ectiv ely) b y µ ( B | θ ) and σ ( B | θ ). W e define the corresp onding z -statistic and an approximate p-v alue b y z ( B | θ ) := S ( B ) − µ ( B | θ ) σ ( B | θ ) , p ( B | θ ) := 1 − Φ( z ( B | θ )) Before initializing the SCS algorithm on sets in B 0 , we compute the p-v alue abov e for eac h mem b er set, and remo ve any that are not significant at FDR lev el α = 0 . 05. This greatly reduces the num b er of extractions CCME must p erform, and reduces the probability of con vergence on small, spurious communities. W e also use z ( B | θ ) to filter near-matches in C , once all SCS extractions hav e terminated and empt y sets remo ved. T o do so, we require an o verlap “tolerance” parameter τ ∈ [0 , 1]. First, we create a (non-symmetric) |C | × |C | matrix O with general element O ij := | C i ∩ C j | / | C i | , which measures the proportional o v erlap of C i in to C j . After setting the diagonal of O to zero, the filtering pro ceeds as follows: 1. Find indices i 6 = j corresp onding to the maximum entry of O . 2. If O ij < τ , terminate filtering. 3. Remov e either C i or C j from C , whic hever has the smaller z ( B | θ ). 4. Re-compute O , set its diagonal to zero, and return to step 1. F or all sim ulations and real-data analyses in this pap er, we employ ed this algorithm with τ = 0 . 9. T o further decrease the computation time of CCME, as w e pro ceed through B 0 , w e skip sets that w ere formed from no des that hav e already b een extracted into C . W e find that, in practice, none of these adjustmen ts harm CCME’s ability to find statistically significan t ov erlapping communities. Indeed, the sim ulation results mentioned in Section 6.2.2 sho w that CCME outp erforms competing metho ds with ov erlap capabilities. App endix F. Sim ulation framework Here w e describe the benchmarking simulation framework used in Section 6. In T able 4, w e list and name parameters controlling the net work mo del: 36 Community detection in weighted networks T able 4: Simulation mo del parameters n : Number of nodes in communities n b : Number of nodes in background m max : Max communit y size m min : Min communit y size τ 1 : Po wer-law for degree parameters τ 2 : Po wer-law for community sizes k : Mean of degree parameter p ow er-law k max : Maximum degree parameter s e : Within-communit y edge signal s w : Within-communit y weight signal o n : Number of nodes in multiple communities o m : Number of memberships for ov erlap no des F : Distributions of edge weigh ts σ 2 : V ariance parameter for F β : Po wer-la w for strength parameters F.1 Simulation of comm unity nodes The framework is capable of sim ulating net w orks with or without bac kground nodes. W e first describ e the sim ulation pro cedure without bac kground no des, i.e. with n b = 0. Later, w e describ e how to simulate a netw ork with background no des, which inv olv es a slight mo dification to the pro cedure in this subsection. Regardless of the presence of bac kground no des, the first step is to determine comm unit y sizes and no de mem b erships. F.1.1 Community structure and node degree/strength p arameters Here w e describ e how to obtain a cov er C := { C 1 , . . . C K } of n no des. The following steps to obtain C are almost exactly as those from the LFR b enchmark in Lancic hinetti and F ortunato (2009), used extensively in Lancichinetti et al. (2011) and Xie et al. (2013): 1. Each of the o n o verlapping no des will ha ve o m mem b erships. Let n m := n + o n ( o m − 1) b e the num b er of node memb erships presen t in the netw ork. 2. Draw communit y sizes from a pow er law with maxim um v alue m max , minimum v alue m min , and exp onen t − τ 2 , until the sum of communit y sizes is greater than or equal to n m . If the sum is greater than n m , we reduce the sizes of the communities prop or- tionally un til the sum is equal to n m . 3. F orm a bipartite graph of comm unity markers on one side and node mark ers on the other. Eac h communit y marker has num b er of empt y no de slots given b y step (b), and eac h no de has a n umber of mem b erships giv en by step (a). Sequen tially pair no de mem b erships and comm unity no de slots uniformly at random, without replacemen t, un til ev ery no de mem b ership is paired with a communit y . With the communit y assignments in hand, simulation of the netw ork pro ceeds according to the W eighted Sto c hastic Block Mo del as outlined in Section 6. W e describ e choices for particular components of this model in the following subsection. F.1.2 Simula tion of edges and weights As describ ed in Section 6, we set the P and M matrices to ha ve diagonals equal to s e and s w (resp ectiv ely , see T able 4), and off-diagonals equal to 1. W e note that this homogeneit y facilitates creating netw orks with ov erlapping comm unities. With v ariance in the diagonal of P , for example, it would not b e ob vious with what probabilit y to connect o verlapping no des that ov erlap to tw o of the same communities, simultaneously . It remains 37 P alowitch, Bhamidi and Nobel to obtain the strength and degree prop ensity parameters ψ and φ ; w e do so analogously to the sim ulation framew ork in Lancic hinetti et al. (2011). W e first draw φ from a p ow er law with exp onent τ 1 , mean k , and maximum k max (see T able 4). Next we set ψ by the formula ψ ( u ) = φ ( u ) β +1 . It is w orth noting here that, under the mo del given b elow, the exp ected degree of no de u is appr oximately φ ( u ) and the exp ected strength appr oximately ψ ( u ). Therefore, hetero- geneit y/skewness in φ and ψ induce heterogeneity/sk ewness in the degrees and strengths of the sim ulated net works. How ever, b y scaling φ and ψ , w e can force the total expected degree and total exp ected strength of the simulated netw orks to exactly match φ T and ψ T , resp ectiv ely . The scaling constan ts dep end on P and M and are easily deriv able from the mo del’s generative algorithm (describ ed in Section 4.2.1). F.1.3 P arameter settings Here we list the “default” settings of the simulation model, mentioned in Section 6. The follo wing c hoices for parameters were made regardless of the sim ulation setting: τ 2 = − 2, k = √ n , k max = 3 k (three settings whic h make the degree/strength distributions skew ed and the netw ork sparse), β = 0 . 5 (to induce a non-trivial pow er law b etw een strengths and degrees), τ 1 = − 1, m min = n/ 5, m max = 3 m max / 2 (settings whic h pro duce b etw een ab out 3 and 7 communities p er netw ork with skew ed size distribution), and σ 2 = 1 / 2. Other parameter c hoices are sp ecific to the simulation settings describ ed in Section 6. F.2 Background no de simulation If n b > 0, we generate a netw ork with n comm unity no des, and then add n b bac kground no des, generating all remaining edges and w eigh ts according to the con tin uous configuration n ull model in tro duced in the main text. First, we obtain no de-wise parameters for all n + n b no des, yielding vectors φ and ψ as in subsection F.1. In a sim ulated netw ork without bac kground, φ ( u ) and ψ ( u ) are approximately E [ d ( u )] and E [ s ( u )], respectively . T o ensure that this remains the case in a net work for which background no des are added after the sim ulation of comm unity no des, w e m ust split up each φ ( u ) and ψ ( u ) into communit y and bac kground p ortions. A few other adjustmen ts m ust also b e made after the simulation of comm unity no des. T o this end, define • N C := { 1 , . . . , n } ; N B := { n + 1 , . . . , n + n b } (comm unity and background no de sets) • φ C,T := P N C φ ( u ); φ B ,T := P N B φ ( u ) (target total degrees of comm unity and bac k- ground nodes) • φ C ( u ) := φ C,T φ T φ ( u ); φ B ( u ) := φ B ,T φ T φ ( u ) (target edge-coun ts betw een u and the com- m unity and bac kground no des) • φ 1 ,T := P N C φ C ( u ); φ 2 ,T := P N B φ B ( u ) (target total degrees of comm unit y and bac kground subnetworks ) • d o C ( u ) := P v ∈ N C A uv ; d o B ( u ) := P v ∈ N B A uv (observ ed edge-counts b etw een u and the comm unity and bac kground no des) 38 Community detection in weighted networks The ab o ve definitions exist analogously for the strength parameters ψ (replacing “ d ” with “ s ” where appropriate). The w ord “target” abov e indicates that we will set up the bac k- ground sim ulation mo del so that these v alues are the appro ximate exp ected v alues of the graph statistics they represen t. F.2.1 Adjusted community-node simula tion model The only adjustmen t to b e made to the simulation of communit y no des, describ ed in subsection F.1.2, is that the degree and strength parameters are set to a certain fr action of their original v alues. This accoun ts for the ev entual addition of bac kground no des, where the remaining (random) part of eac h nodes degree and strength is to b e sim ulated. So, the communit y-no de simulation (if background no des are to b e added later) follo ws the pro cess describ ed in subsection F.1 with degree parameters { φ C (1) , . . . , φ C ( n ) } and strength parameters { ψ C (1) . . . ψ C ( n ) } . F.2.2 Edges and weights for back ground F or the simulation of the bac kground no des (follo wing the comm unity nodes) our goal is to specify adjusted degree/strength parameters φ 0 and ψ 0 giv en the observ ed edge-sums { d o C (1) , . . . , d o C ( n ) } and w eight-sums { s o C (1) , . . . , s o C ( n ) } from the comm unity no des. In what follows we describ e this sp ecification for φ 0 only; the specification for ψ 0 is exactly analogous. W e first represen t φ 0 T , which we hav e y et to determine, in to comm unity and bac kground totals: φ 0 T = φ 0 C,T + φ 0 B ,T Since the background subnetw ork has not yet b een generated, we make the sp ecification φ 0 ( u ) := φ ( u ) for all u ∈ N B , and hence φ 0 B ,T = φ B ,T is kno wn. T o address φ 0 C,T , note that for eac h comm unit y no de u ∈ N C , φ 0 ( u ) ma y be represented similarly: φ 0 ( u ) = φ 0 C ( u ) + φ 0 B ( u ) This reduces the problem of sp ecifying φ 0 ( u ) to sp ecifying φ 0 C ( u ) and φ 0 B ( u ). Since the comm unity no de subnet work has already b een generated, we set φ 0 C ( u ) ← d o C ( u ). Next, recalling that φ B ( u ) := φ B ,T φ T φ ( u ), w e mak e the sp ecification φ 0 B ( u ) := φ B ,T φ 0 T φ ( u ) (which m ust b e solved for via φ 0 T , in the follo wing). So, in total, w e ha ve φ 0 ( u ) = ( d o C ( u ) + φ B ,T φ 0 T φ ( u ) , u ∈ N C φ ( u ) , u ∈ N B Therefore w e can solve for φ 0 T with the equation φ 0 T := X u ∈ N C ∪ N B φ 0 ( u ) = X u ∈ N C d o C ( u ) + φ B ,T φ 0 T φ ( u ) + X u ∈ N B φ ( u ) = d o C,T + φ B ,T φ 0 T φ C,T + φ B ,T 39 P alowitch, Bhamidi and Nobel Where d o C,T := P u ∈ N C d o C ( u ). The solution for φ 0 T from this quadratic is φ 0 T = φ B ,T + d o C,T 2 + s ( φ B ,T + d o C,T ) 2 4 + φ C,T φ B ,T (62) whic h then immediately giv es the full v ector φ 0 . W e can no w simulate the remaining edges in the netw ork. Sp ecifically , for eac h u ∈ N B and eac h v ∈ N C ∪ N B , we simulate an edge according to P ( A uv = 1) = φ 0 ( u ) φ 0 ( v ) φ 0 T indep enden t across no de pairs (63) W e solv e for ψ 0 analogously . Then for each u ∈ N B and each v ∈ N , w e simulate an edge w eight according to W uv = ( f uv ( φ 0 , ψ 0 ) ξ uv , A uv = 1 0 , A uv = 1 where ξ ∼ F , is as it w as for the generation of the communit y no de subnetw ork. The ab ov e simulation steps corresp ond precisely to the contin uous configuration mo del with parameters ( φ 0 , ψ 0 , F , σ ). Some basic computational trials ha ve shown that, for large net works, the solution for φ 0 T is quite close to φ T . Therefore, for each u ∈ N B , E ( d ( u )) is almost exactly φ ( u ), i.e. what it w ould b e under the model in F.1.2, without bac kground no des. The same holds for the strengths and expected strengths. T ogether with equation 63, this implies the bac kground no des are behaving according to the con tinuous configuration mo del, even as they are a sub-netw ork within a larger netw ork with comm unities. T o illustrate these points, w e simulated a sample net w ork from the default framework with parameters n = 5 , 000, n b = 1 , 000, s e = s w = 3, disjoint communities, and other parameters specified by F.1.3. These settings are akin to what w as used in subsection 6 of the main text. First we plotted φ 0 and ψ 0 against the empirical strengths and degrees with lo wess curves to chec k the matc h. Figure 3 sho ws the fit is essentially linear. Second, for Figure 3: Empirical degrees/strengths vs. adjusted parameters for the example net work eac h no de u ∈ N and for each no de blo ck B (either a true comm unity or the background 40 Community detection in weighted networks no de set) we may calculate an empirical z -score for S ( u, B , G ), as describ ed in subsection 4.1 of the main text. The z -score for S ( u, B , G ) is a measure of connection significance, with resp ect to the contin uous configuration mo del (and also mo dularit y , see Section 4.2.3) b et ween u and B . Let K b e the num b er of true communities in the netw ork. F or each i, j = 1 , . . . , K + 1, where K + 1 is the index of the bac kground no de blo ck, w e computed the empirical av erage of z -statistics betw een no des u from no de blo ck i the no de blo c k B corresp onding to index j . Theses empirical av erages can b e arranged in a ( K + 1) × ( K + 1) matrix sho wing the a verage inter-block connectivities of the netw ork. In Figure 4 we display a visualization of this matrix, which sho ws preferential connection within communities, and roughly n ull connection b etw een the bac kground no des and all blo c ks. Figure 4: Average empirical z -statistics b et ween no des and no de blo c ks References Christopher Aic her, Abigail Z Jacobs, and Aaron Clauset. Learning latent blo ck structure in w eigh ted net works. Journal of Complex Networks , page cnu026, 2014. Reid Andersen, David F Gleich, and V ahab Mirrokni. Overlapping clusters for distributed computation. In Pr o c e e dings of the Fifth A CM International Confer enc e on Web Se ar ch and Data Mining , pages 273–282. A CM, 2012. Alb ert-Laszlo Barabasi and Zoltan N Oltv ai. Netw ork biology: understanding the cell’s functional organization. Natur e R eviews Genetics , 5(2):101–113, 2004. 41 P alowitch, Bhamidi and Nobel Alain Barrat, Marc Barthelem y , Romualdo Pastor-Satorras, and Alessandro V espignani. The architecture of complex weigh ted net works. Pr o c e e dings of the National A c ademy of Scienc es of the Unite d States of Americ a , 101(11):3747–3752, 2004. Edw ard A Bender. The asymptotic n umber of non-negative in teger matrices with given ro w and column sums. Discr ete Mathematics , 10(2):217–223, 1974. Y oav Benjamini and Y osef Ho c hberg. Controlling the false discov ery rate: a practical and p o werful approach to multiple testing. Journal of the R oyal Statistic al So ciety, Series B (Metho dolo gic al) , pages 289–300, 1995. P eter J Bic kel and Aiy ou Chen. A nonparametric view of netw ork mo dels and newman– girv an and other mo dularities. Pr o c e e dings of the National A c ademy of Scienc es , 106(50): 21068–21073, 2009. Vincen t D Blondel, Jean-Loup Guillaume, Renaud Lambiotte, and Etienne Lefebvre. F ast unfolding of communities in large net works. Journal of Statistic al Me chanics: The ory and Exp eriment , 2008(10):P10008, 2008. B ´ ela Bollob´ as. A probabilistic pro of of an asymptotic form ula for the num b er of lab elled regular graphs. Eur op e an Journal of Combinatorics , 1(4):311–316, 1980. Irineo Cabreros, Emmanuel Abb e, and Aristotelis Tsirigos. Detecting comm unity struc- tures in hi-c genomic data. In Information Scienc e and Systems (CISS), 2016 Annual Confer enc e on , pages 584–589. IEEE, 2016. F an Chung and Lin yuan Lu. The av erage distances in random graphs with giv en exp ected degrees. Pr o c e e dings of the National A c ademy of Scienc es , 99(25):15879–15882, 2002a. F an Ch ung and Lin yuan Lu. Connected comp onents in random graphs with given exp ected degree sequences. A nnals of Combinatorics , 6(2):125–145, 2002b. Aaron Clauset, Mark EJ Newman, and Cristopher Mo ore. Finding comm unity structure in v ery large net w orks. Physic al R eview E , 70(6):066111, 2004. Aaron Clauset, Cosma Rohilla Shalizi, and Mark EJ Newman. P o wer-la w distributions in empirical data. SIAM R eview , 51(4):661–703, 2009. Amin Co ja-Oghlan and Andr´ e Lank a. Finding planted partitions in random graphs with general degree distributions. SIAM Journal on Discr ete Mathematics , 23(4):1682–1714, 2009. Gab or Cs´ ardi and T amas Nepusz. The igraph s oft w are pack age for complex netw ork re- searc h. InterJournal , Complex Systems:1695, 2006. Leon Danon, Alb ert Diaz -Guilera, Jordi Duch, and Alex Arenas. Comparing communit y structure identification. Journal of Statistic al Me chanics: The ory and Exp eriment , 2005 (09):P09008, 2005. 42 Community detection in weighted networks Nurcan Durak, T amara G Kolda, Ali Pinar, and C Seshadhri. A scalable n ull mo del for directed graphs matching all degree distributions: In, out, and recipro cal. In Network Scienc e Workshop (NSW), 2013 IEEE 2nd , pages 23–30. IEEE, 2013. Ming F an, Ka-Ch un W ong, T aewoo Ryu, Timothy Rav asi, and Xin Gao. Secom: A nov el hash seed and comm unity detection based-approach for genome-scale protein domain iden tification. PL oS ONE , 7:e39475, 06 2012. San to F ortunato. Commun ity detection in graphs. Physics R ep orts , 486(3):75–174, 2010. Roger Guimera and Luis A Nunes Amaral. F unctional cartograph y of complex metabolic net works. Natur e , 433(7028):895–900, 2005. Abigail Z Jacobs and Aaron Clauset. A unified view of generativ e mo dels for net works: mo dels, metho ds, opp ortunities, and challenges. , 2014. Da vid Kahle and Hadley Wic kham. ggmap: Spatial visualization with ggplot2. The R Journal , 5(1):144–161, 2013. URL http://journal.r- project.org/archive/2013- 1/ kahle- wickham.pdf . Brian Karrer and Mark EJ Newman. Stochastic blo c kmo dels and communit y structure in net works. Physic al R eview E , 83(1):016107, 2011. Andrea Lancic hinetti and Santo F ortunato. Benc hmarks for testing communit y detection algorithms on directed and w eighted graphs with o verlapping communities. Physic al R eview E , 80(1):016118, 2009. Andrea Lancic hinetti, San to F ortunato, and J´ anos Kert ´ esz. Detecting the ov erlapping and hierarc hical communit y structure in complex netw orks. New Journal of Physics , 11(3): 033015, 2009. Andrea Lancic hinetti, Filipp o Radicc hi, Jos ´ e J Ramasco, Santo F ortunato, et al. Finding statistically significan t comm unities in netw orks. PloS One , 6(4):e18961, 2011. Ro cco Langone, Carlos Alzate, and Johan AK Suyk ens. Mo dularit y-based mo del selection for k ernel sp ectral clustering. In The 2011 International Joint Confer enc e on Neur al Networks , pages 1849–1856. IEEE, 2011. Jure Lesko vec et al. Stanford netw ork analysis pro ject. 2010. URL http://snap.stanford. edu . Da vid Lusseau and Mark EJ Newman. Identifying the role that animals play in their so cial net works. Pr o c e e dings of the R oyal So ciety of L ondon B: Biolo gic al Scienc es , 271(Suppl 6):S477–S481, 2004. Mic hael Molloy and Bruce Reed. A critical p oint for random graphs with a given degree sequence. R andom structur es & algorithms , 6(2-3):161–180, 1995. Mark EJ Newman. The structure and function of complex netw orks. SIAM r eview , 45(2): 167–256, 2003. 43 P alowitch, Bhamidi and Nobel Mark EJ Newman. Analysis of weigh ted netw orks. Physic al R eview E , 70(5):056131, 2004a. Mark EJ Newman. Detecting communit y structure in net works. The Eur op e an Physic al Journal B-Condense d Matter and Complex Systems , 38(2):321–330, 2004b. Mark EJ Newman. Mo dularit y and comm unity structure in net works. Pr o c e e dings of the National A c ademy of Scienc es , 103(23):8577–8582, 2006. Mark EJ Newman and Michelle Girv an. Finding and ev aluating communit y structure in net works. Physic al r eview E , 69(2):026113, 2004. Krzysztof No wicki and T om A B Snijders. Estimation and prediction for sto c hastic blo ck- structures. Journal of the Americ an Statistic al Asso ciation , 96(455):1077–1087, 2001. Gergely Palla, Alb ert-L´ aszl´ o Barab´ asi, and T am´ as Vicsek. Quantifying so cial group evolu- tion. Natur e , 446(7136):664–667, 2007. John Platig, Peter Castaldi, Dawn DeMeo, and John Quack en bush. Bipartite comm unity structure of eqtls. , 2015. P ascal P ons and Matthieu Latap y . Computing comm unities in large net w orks using random w alks. Journal of Gr aph A lgorithms Applic ations , 10(2):191–218, 2006. Mason A P orter, Jukk a-P ekk a Onnela, and Peter J Mucha. Comm unities in net w orks. Notic es of the AMS , 56(9):1082–1097, 2009. J¨ org Reic hardt and Stefan Bornholdt. Clustering of sparse data via netw ork comm unitiesa protot yp e study of a large online market. Journal of Statistic al Me chanics: The ory and Exp eriment , 2007(06):P06016, 2007. Martin Rosv all and Carl T Bergstrom. Maps of random walks on complex netw orks rev eal comm unity structure. Pr o c e e dings of the National A c ademy of Scienc es , 105(4):1118– 1123, 2008. Shagha yegh Sahebi and William W Cohen. Communit y-based recommendations: a solution to the cold start problem. In Workshop on R e c ommender Systems and the So cial Web, RSWEB , 2011. Scott White and Padhraic Smyth. A spectral clustering approac h to finding communities in graph. In SDM , volume 5, pages 76–84. SIAM, 2005. James D Wilson, Simi W ang, P eter J Mucha, Shank ar Bhamidi, Andrew B Nob el, et al. A testing based extraction algorithm for iden tifying significant communities in netw orks. The Annals of Applie d Statistics , 8(3):1853–1891, 2014. Jierui Xie, Bolesla w K Szymanski, and Xiaoming Liu. Slpa: Unco vering o v erlapping com- m unities in social net works via a sp eak er-listener interaction dynamic pro cess. In IEEE 11th International Confer enc e on Data Mining , pages 344–349. IEEE, 2011. 44 Community detection in weighted networks Jierui Xie, Stephen Kelley , and Bolesla w K Szymanski. Ov erlapping communit y detection in netw orks: The state-of-the-art and comparative study . A CM Computing Surveys , 45 (4):43, 2013. Liu Xin, E Haihong, Junde Song, Meina Song, and Junjie T ong. Bo ok recommendation based on communit y detection. In Pervasive Computing and the Networke d World , pages 364–373. Springer, 2014. Shih ua Zhang, Rui-Sheng W ang, and Xiang-Sun Zhang. Iden tification of ov erlapping com- m unity structure in complex netw orks using fuzzy c-means clustering. Physic a A: Statis- tic al Me chanics and its Applic ations , 374(1):483–490, 2007. Y unp eng Zhao, Elizav eta Levina, and Ji Zh u. Communit y extraction for so cial net works. Pr o c e e dings of the National A c ademy of Scienc es , 108(18):7321–7326, 2011. Y unp eng Zhao, Eliza veta Levina, and Ji Zhu. Consistency of communit y detection in net works under degree-corrected sto chastic block mo dels. The A nnals of Statistics , pages 2266–2292, 2012. 45
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment