Embedding-Based Speaker Adaptive Training of Deep Neural Networks
An embedding-based speaker adaptive training (SAT) approach is proposed and investigated in this paper for deep neural network acoustic modeling. In this approach, speaker embedding vectors, which are a constant given a particular speaker, are mapped through a control network to layer-dependent element-wise affine transformations to canonicalize the internal feature representations at the output of hidden layers of a main network. The control network for generating the speaker-dependent mappings is jointly estimated with the main network for the overall speaker adaptive acoustic modeling. Experiments on large vocabulary continuous speech recognition (LVCSR) tasks show that the proposed SAT scheme can yield superior performance over the widely-used speaker-aware training using i-vectors with speaker-adapted input features.
💡 Research Summary
The paper introduces a novel speaker adaptive training (SAT) framework for deep neural network (DNN) acoustic models that directly canonicalizes internal feature representations using speaker embeddings. Traditional speaker‑aware approaches typically concatenate i‑vectors to the acoustic input or adapt a limited set of model parameters (e.g., input/output layers). While effective for shallow models, these methods struggle with the massive parameter space of modern deep architectures and with data sparsity during adaptation.
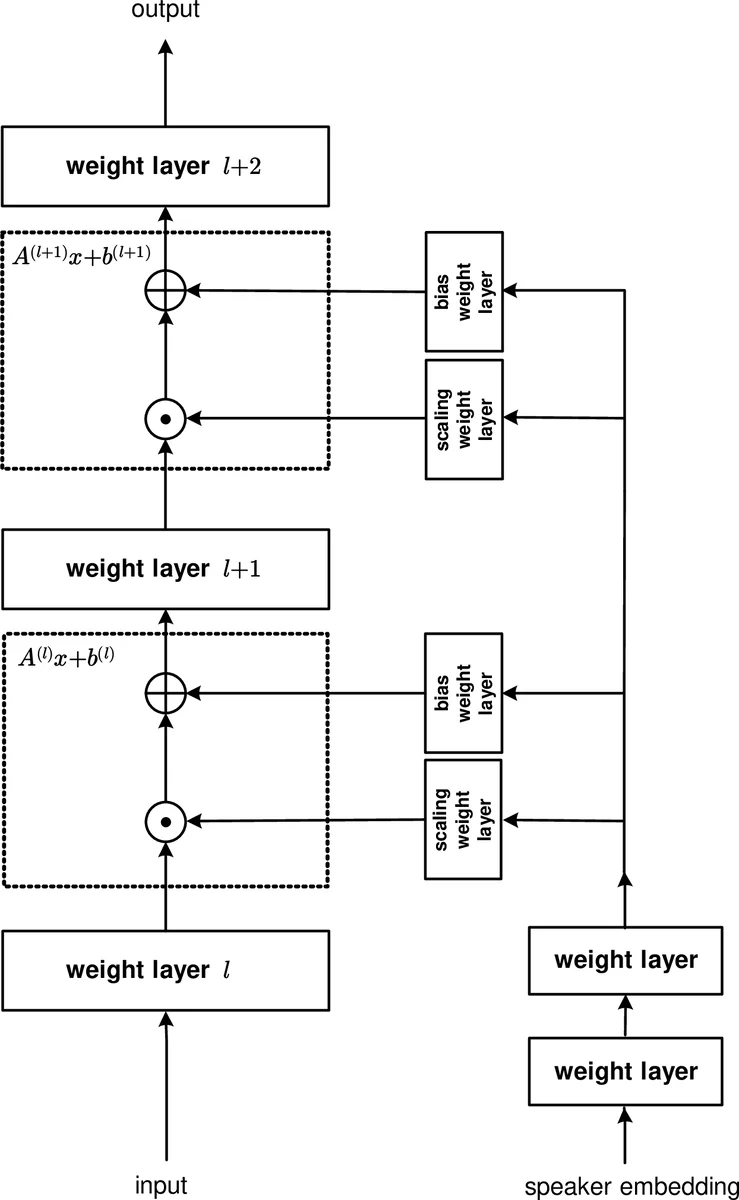
To address this, the authors propose a two‑network architecture: a main network (which can be a feed‑forward DNN, CNN, or recurrent network such as LSTM) that performs the usual acoustic modeling, and a control network that receives a fixed‑dimensional speaker embedding (in the experiments a 100‑dimensional i‑vector) and generates layer‑specific, element‑wise affine transformations. For each selected hidden layer ℓ, the transformation is defined as
(\hat{x}^{(ℓ)}(s) = a^{(ℓ)}(s) \odot x^{(ℓ)}(s) \oplus b^{(ℓ)}(s))
where (a^{(ℓ)}) (scaling) and (b^{(ℓ)}) (bias) are vectors of the same dimensionality as the hidden activations. The scaling vector is produced by a sigmoid‑activated output (ensuring positivity), while the bias vector uses a tanh activation (allowing both signs). The control network shares several lower layers (e.g., dimensions 100 → 256 → 512 → 1024) before branching into separate scaling and bias heads for each SAT layer. This shared‑layer design keeps the total parameter count modest while allowing the low‑dimensional embedding to be mapped into high‑dimensional transformation parameters.
Training is performed jointly: the main and control networks are treated as a single computational graph and optimized with cross‑entropy (CE) loss using mini‑batch stochastic gradient descent (SGD). No separate adaptation stage is required; the speaker‑dependent transformations are learned simultaneously with the acoustic model parameters.
The approach is evaluated on three corpora: (1) Babel Swahili and Georgian (≈40 h per language, ~500 speakers each), (2) Switchboard 300‑hour (SWB) and CallHome (CH) data, and (3) a large 2000‑hour Switchboard‑Fisher‑CallHome set.
Babel results – A 5‑layer DNN (1024 units per layer) with four SAT layers (one after each hidden layer) was compared against a baseline DNN using speaker‑adapted FMLLR features and a baseline that also concatenates a 100‑dimensional i‑vector (fmllr+ivec). Adding SAT on top of fmllr+ivec reduced word error rate (WER) from 50.4 % to 49.9 % for Swahili and from 53.8 % to 52.7 % for Georgian. A “gating” variant that only learns scaling (bias set to zero) gave smaller gains, confirming that full affine transformations are beneficial.
Switchboard 300 h results – Bidirectional LSTM acoustic models with 1–5 layers (each 1024 cells, 512 per direction) were tested. Adding i‑vectors to the FMLLR input already yielded substantial improvements (e.g., 11.4 % → 10.7 % WER on SWB for a 4‑layer LSTM). Incorporating SAT on top of this further reduced WER: a 5‑layer LSTM with two SAT layers achieved 10.3 % (SWB) and 18.4 % (CH) versus 10.7 %/18.8 % for the i‑vector‑only system.
Sequence training – After CE training, models were fine‑tuned with state‑level Minimum Bayes Risk (sMBR). The baseline LSTM (fmllr+ivec) improved from 10.7 % to 10.3 % (SWB) and 18.8 % to 18.5 % (CH). Adding SAT gave an additional 0.1 % absolute gain on SWB and 0.5 % on CH, reaching 10.2 % and 18.0 % respectively.
2000 h results – The same SAT architecture applied to a 5‑layer LSTM trained on 1975 h of data confirmed scalability; SAT continued to provide consistent WER reductions over the strong i‑vector baseline.
Key insights
- Embedding‑driven internal adaptation – By mapping a fixed speaker embedding to layer‑wise affine parameters, the model directly normalizes hidden representations, achieving speaker invariance beyond what input‑concatenation can provide.
- Full affine vs. gating – Including both scaling and bias yields larger gains than scaling alone, indicating that bias compensation is important for aligning internal feature distributions across speakers.
- Parameter efficiency – The shared lower layers of the control network allow a compact mapping from low‑dimensional i‑vectors to high‑dimensional transformation vectors, mitigating over‑parameterization despite the added SAT layers.
- Flexibility across architectures – The method works with feed‑forward DNNs and deep bidirectional LSTMs, and can be applied to any subset of layers (typically the lower layers where speaker variability is most pronounced).
- Compatibility with sequence training – SAT improvements persist after sMBR fine‑tuning, demonstrating that the canonicalized internal space remains beneficial for discriminative training objectives.
Overall, the paper demonstrates that embedding‑based SAT is a practical and effective way to enhance speaker robustness in modern large‑scale LVCSR systems, offering consistent WER reductions over conventional i‑vector speaker‑aware training while requiring only modest additional computation and parameters.
Comments & Academic Discussion
Loading comments...
Leave a Comment