A Continuous Relaxation of Beam Search for End-to-end Training of Neural Sequence Models
Beam search is a desirable choice of test-time decoding algorithm for neural sequence models because it potentially avoids search errors made by simpler greedy methods. However, typical cross entropy training procedures for these models do not directly consider the behaviour of the final decoding method. As a result, for cross-entropy trained models, beam decoding can sometimes yield reduced test performance when compared with greedy decoding. In order to train models that can more effectively make use of beam search, we propose a new training procedure that focuses on the final loss metric (e.g. Hamming loss) evaluated on the output of beam search. While well-defined, this “direct loss” objective is itself discontinuous and thus difficult to optimize. Hence, in our approach, we form a sub-differentiable surrogate objective by introducing a novel continuous approximation of the beam search decoding procedure. In experiments, we show that optimizing this new training objective yields substantially better results on two sequence tasks (Named Entity Recognition and CCG Supertagging) when compared with both cross entropy trained greedy decoding and cross entropy trained beam decoding baselines.
💡 Research Summary
The paper addresses a fundamental mismatch between how neural sequence‑to‑sequence models are trained and how they are decoded at test time. Standard training uses a locally normalized cross‑entropy (CE) objective that maximizes the probability of the gold token at each time step, while inference often employs beam search, a global heuristic that keeps the top‑k partial hypotheses and expands them. Because CE does not take the beam’s global search behavior into account, models trained with CE can actually perform worse when decoded with a larger beam than when decoded greedily—a phenomenon reported in several recent studies.
To close this gap, the authors propose to directly optimize the final evaluation loss (e.g., Hamming loss) computed on the output of beam search. This “direct loss” objective is well defined but discontinuous: beam search contains discrete argmax and top‑k selections, and the loss is evaluated on a discrete output sequence. Consequently, gradients are undefined and conventional back‑propagation cannot be applied.
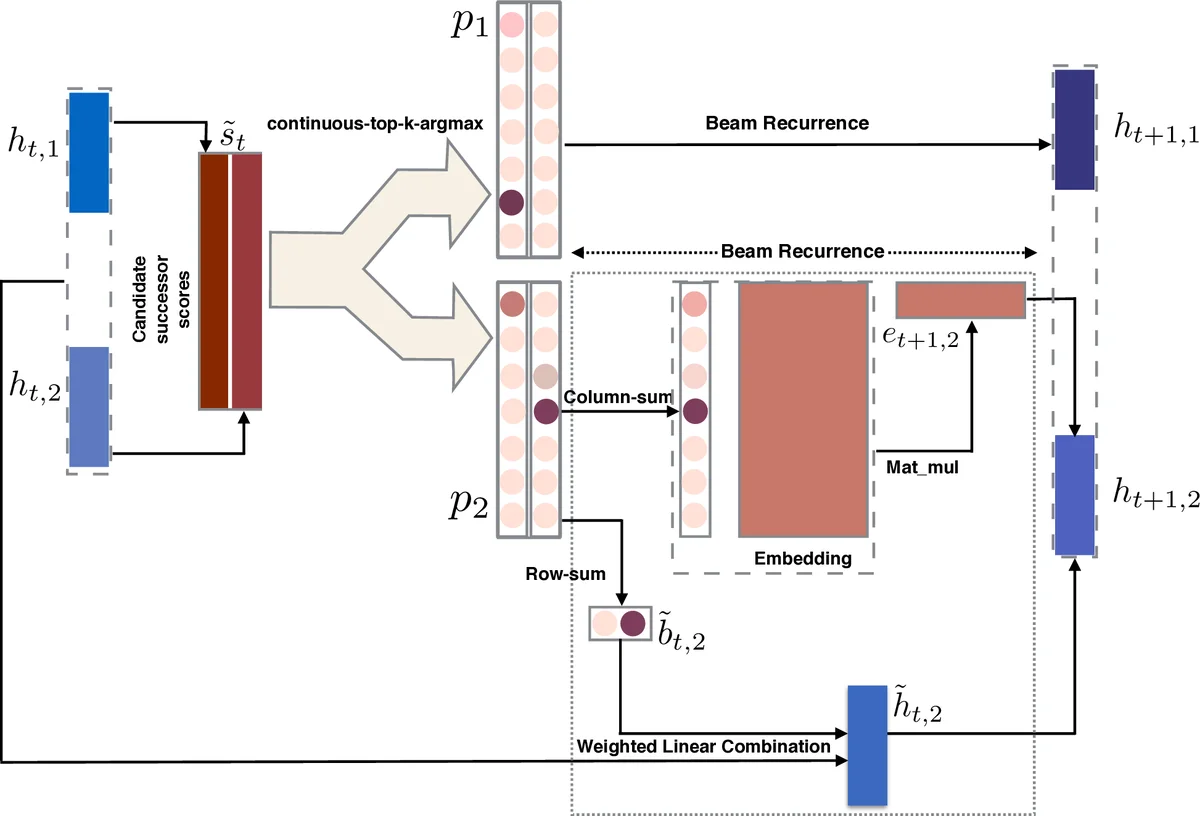
The core technical contribution is a differentiable surrogate that continuously relaxes the entire beam‑search procedure. The relaxation proceeds in two steps. First, the argmax operation is replaced by a temperature‑controlled peaked‑softmax: for a score vector s, the probability of index i becomes exp(α s_i) / Σ_j exp(α s_j). As α → ∞ the distribution collapses to a one‑hot vector, reproducing the true argmax, while for finite α it yields a smooth approximation that permits gradient flow.
Second, the top‑k selection is approximated by iteratively applying the peaked‑softmax to the squared distance from each of the top‑k scores. Concretely, given the k × |V| candidate score matrix \tilde{s}, the algorithm finds the highest score m₁, computes p₁ = peaked‑softmax_α(−( \tilde{s} − m₁ 1)²), then masks out the contribution of the first peak and repeats to obtain p₂,…,p_k. Each p_i is a soft matrix that concentrates mass on the i‑th highest candidate while remaining differentiable. Row‑wise sums of p_i give soft back‑pointers \tilde{b}_{t,i} (probability that a current beam element originates from each previous beam element), and column‑wise sums give soft vocabularies a_i (distribution over next tokens).
Algorithm 3 integrates these components into a full “soft beam” recurrence. At each time step t the model computes local scores \tilde{s}_t
Comments & Academic Discussion
Loading comments...
Leave a Comment