Estimating latent feature-feature interactions in large feature-rich graphs
Real-world complex networks describe connections between objects; in reality, those objects are often endowed with some kind of features. How does the presence or absence of such features interplay with the network link structure? Although the situat…
Authors: Corrado Monti, Paolo Boldi
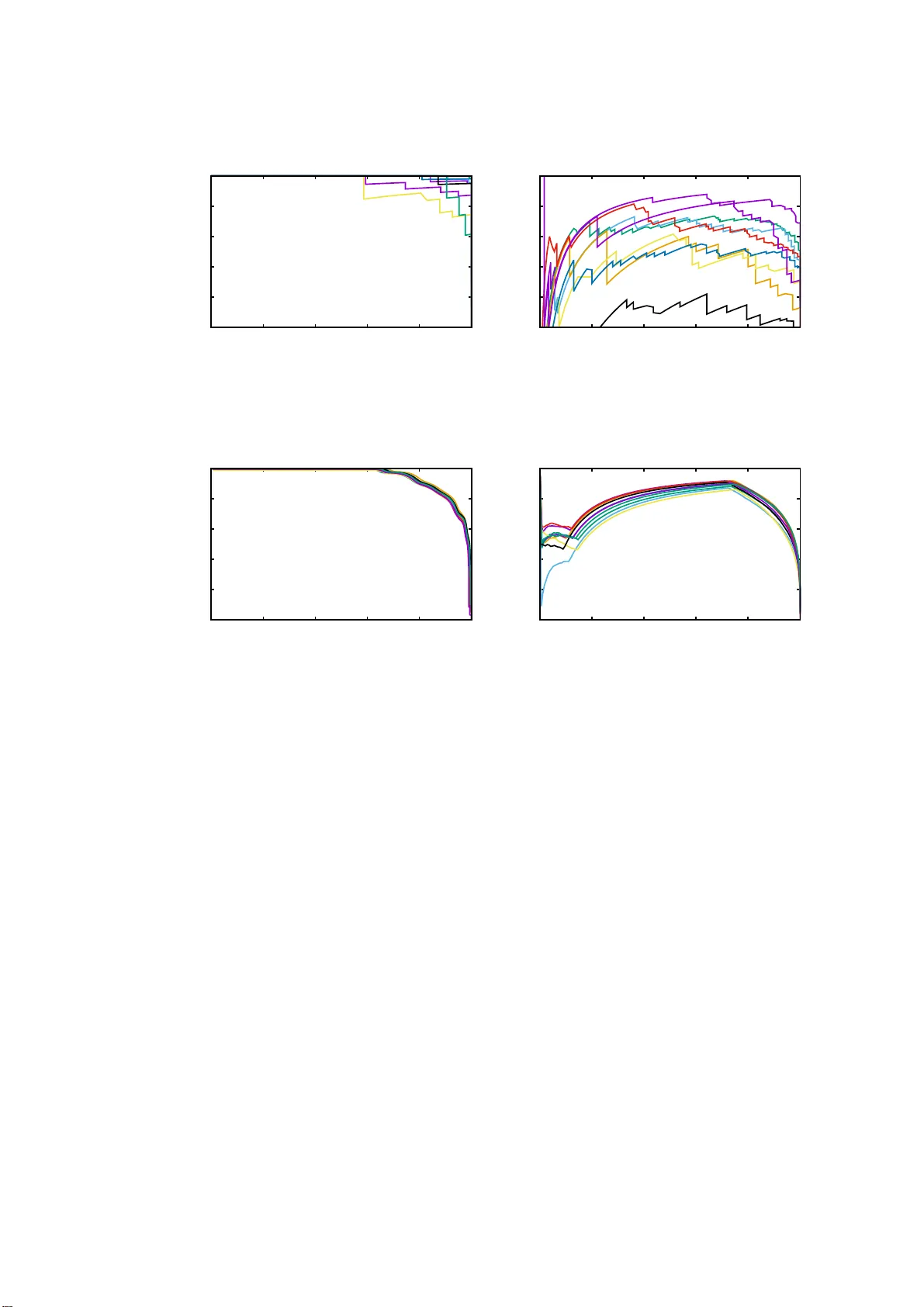
Estimati ng laten t feature-feature in tera ctions in large feature-ric h graphs Corrado Mon ti 1 and P aolo Boldi 1 1 Dipartimen to di Informatica, Univ ersità degli Studi di Milano, Italy , {monti,bo ldi}@di.u nimi.it Abstract Complex netw orks arising in n ature are usually mo deled as (directed or undirected) graphs describing some connection betw een the ob jects that are identified with their nod es. In man y real-w orld sc enarios, though, those ob jects are endo w ed with prop erties and attributes (hereb y cal led features). In this pap er, w e shall confine our in terest to binary features, so that every no de has a precise set of features; w e assume that the presence/absence of a link b etw een t w o giv en nodes d ep end s on the features that the tw o no des exhibit. Although the si tuation descri b ed ab ov e is truly ub iq uitous, there is a limited b o dy of researc h d ealing with large graphs of this kind. Man y previous works considered homophily as the only p ossible t ransmission mec hanism translating no d e f eatures in to links: tw o nodes wil l b e link ed with a probability that dep ends on th e num ber of features they share. Other authors, instead, dev eloped more so phisticated models (often using Ba ye sian Netw orks [30] or Mark o v Chain Monte Carlo [20]), that are indeed able to handle complex feature intera ctions, but are unfit to scale to very large netw orks. W e study a model derived from the works of Mille r et al. [47], where in teractions b etw een p airs of features can foster or discourage link formation. In th is work, we will inv estigate how to estimate the laten t feature-feature interacti ons in this mo del. W e shall prop ose t w o solutions: the first one assumes feature indep end ence and it is essen tially based on a Naive Ba yes approac h; the second one consists in using a learning algorithm, which relaxes the indep enden ce assumption and is based on p erceptron-like tec hniques. In fact, we sho w it is p ossible to cast the mo del eq uation in order to see it as the p rediction rule of a p erceptron. W e analyze ho w classical results for the p erceptrons can b e interpreted in th is con text; then, we define a fast and simple p erceptron-like algorithm for this task. This approach (th at we call Llama , Learning LA ten t fea ture- feature MAtrix) can pro cess hundreds of millions of links in minutes. Our exp eriments sho w that our approac h can b e a pplied even to very large n etw orks. W e t h en compare these tw o techniques in tw o different wa ys. First we produce syn- thetic datasets, obtained by generating random graphs follo wing the mo del w e adopted . These exp eriments sho w how w ell the Llama algorithm can reconstruct laten t v ariables in this model. These exp eriments also provide evidence that t h e Naive indep endence assumptions made b y the first app roac h are detrimental in practice. Then we consider a real, large-sca le citation netw ork where each node (i.e., paper) can be describ ed by differ- ent types of c haracteristics. This second set of exp eriments confirm that our a lgorithm can find meaningful latent feature-feature interactions. F urthermore, our framew ork can b e used to assess how well each set of features can explain the links in the graph. 1 In tro duction The pr o blem o f finding a mo del that descr ibe s how complex net works shape their structure is well studied but still elusive in its full g e nerality . In many scena r ios, though, it is rea sonable 1 to assume that the netw o r k arises in some wa y from a co mplex in terwea ving of some features of the no des. F or example, in a co-a uthorship net work, a link stems mor e easily b etw een authors with similar interests; similarly , in a genetic regulatory netw ork, links are affected b y the differen t bio logical functions of the regulators. Many mo dels hav e been prop osed for descr ibing complex netw ork where ar cs are influ- enced b y some features of the no des. F or example, Lattanzi and Siv akumar [3 8] desc r ibe d a mo del where arcs form at ra ndom, or as a co nsequence of share d common features; Cal- darelli et al. in [7] pr op osed a mo del where a rcs are determined by an arbitrar y function of the “fitness” of the no des (i.e., a r eal-v alued prop erty p oss essed by ea ch no de). More mo dels prop osed alo ng this line of research will be describ ed in Section 2 . Although in s ome cases the r elation b etw een fea tur e s a nd links is homophily (a link stems more easily b et ween nodes that shar e a lar g e p ortion of the same features), we w ould like to design a mo del that is a ble to capture also more c o mplex behaviors. F or example, feature h co uld foster links to feature k also when h 6 = k : e.g., in the cas e of s e ma n tic relations, a concept tagged as b elonging to the catego ry “Mo vies” will often link to a concept tagged as belo nging to “ Dir e c to rs”. If we consider directed netw o rks, we would like this relations hip betw een features to b e directed: feature h could foster links to w ards feature k but no t the other wa y around. F o r example, in a c ita tion netw or k, we could easily exp ect a pap er within the so ciolo g y realm to cite a statistics pa p er , but a link in the opp osite direction will b e m uch har der to find. Finally , some pairs of features could not fo ster but rather inhi bit link formation: as “R ome o and Juliet” nar rates, b elonging to riv a l families could discourage the creation of a link in a long-term r omantic relations hip graph. The theoretical mo del w e a re going to describ e (based o n the work b y Miller, Griffiths and J ordan [4 7]) is able to represent all the afor ement ioned kinds of b ehavior within a unified framework, while at the same time b eing simple e nough to b e co mputationally useful and scalable, as we will s how in the second pa rt of this work. In this work, we will see how the estimation of the latent para meters of the mo del is fundament ally related to p erceptron- like prediction rules, and we will turn this insight in to a sca lable algo rithm able to extr act information also fro m very lar ge gra phs. In our mo del a specia l role is pla yed by the feature-feature matrix W . This matrix can express the v ar ious kinds of interpla y b etw een features a nd links, as described above; it is a latent , unobserv able element of the mo del, that ca n compactly expla in the observ able links. The question is basically the following: assuming to know the links of a netw o rk and the features every no de b ear s, how can we estimate ho w fea tures interact with eac h other – i.e., estimating the matrix W ? This ques tion has a lo t of practical implicatio ns. Consider for example a semantic graph [12], where no des are concepts, arcs are semantic re lations, and each concept ca n belo ng to different categories. Here, the matrix element W h,k describ es how t wo catego ries h and k re la te to each other: it summarizes if they in teract p ositively , negatively and how m uch; it can therefore b e used for measuring the sema n tic con nection b et ween the tw o ca te- gories. In a linguistic g raph (ma ybe obtained from a large corpus o f text), where a link ex ists betw een w ords used a s sub jects and thos e used a s ob jects for a certain v erb, W descr ibes the s emanti c ar eas a giv en verb can connect. In a citation netw o r k where features a r e area s of scientific research, the set S k = { h | W h,k > 0 } contains the fields fo r whic h the field k is useful, a nd so forth. Many o ther examples are po ssible; it is howev er imp or tant to no te how ma n y of these applications require to deal with graphs ha ving a h ug e n um ber o f nodes and links. W e will present concrete examples dealing with tens of millions o f no des. Op er a ting a t this sca le demands new techn iques; a s we will see in Section 2, many of the existing techniques are not able to scale to this size. A first idea, that we will descr ibe in Section 4.1, is to just e stimate the pro ba bilit y of a link from the ca teg ory pairs we see in the data. W e will derive formally this a pproach, 2 showing that it can b e ascr ibed to the family of Naive Bay es lear ning. In particular, we will see that this estimation requires independence assumptions that are particular ly unre- alistic in most practical cases. F or example, c o nsider the semantic link b et ween the en tit y “R onald R e agan ” and the 1954 W estern film “Cattle Que en of Montana” ; such an approach will incr emen t, becaus e of the presence of this link, the element of W corresp onding to ( f il ms, U.S. pr esidents ) , r egardless o f the fact that this link could alrea dy b e well explained b y ( f il ms , actors ) . Based on the latter observ ation, we will need to streamline the mo del: we will make it deterministic, by fixing its activ a tio n function φ . As we will des crib e in Section 4.2, this fact will allow us to see our mo del equa tion as the prediction rule of a p erceptron and in the end to develop a more so phisticated approa ch based on online machine learning. What w e will do is to see A (the links in the gr aph) a s par tially unknown, muc h like in the link prediction problem; we will show that, while lear ning A , the in ter nal state of the p erce ptr on will tend to W . This approa ch, that we will call Llama – Learning LAten t MAtrix – will ov ercome the na ive a ssumptions of the previo us mo del. In Section 5 we will test this a pproach on our model, by sim ula ting graphs ob eying the mo del a nd then observing how this w ay o f reco nstructing W b ehav es . Mor e precisely , we will show ho w Llama is able to reco nstruct the W matrix, and how instead the indep endence assumptions mak e the Naive a lgorithm very far from the goal. Finally , in Section 6 we will consider a real, la r ge-scale citation net work, where no des ar e pap ers a nd links r epresent c ita tions. Here, each no de can be describ ed b y diff erent types of characteristics; w e will consider institutions of the authors, and fields of research the pap er belo ngs to. W e will define a notion of explai nability , a w a y to measure how a certain set of features can explain links in a graph a ccording to our framew ork. Then, we will pro v e how real-data exp eriments confirm that our algor ithm can find mea ningful, latent feature-feature in teractions fro m a real netw ork. 2 Related w o rks The in terplay b etw een features a nd links in a net w ork w as investigated separa tely in differ- ent fields. Indeed, interpreting links as a re s ult of features of each node has in fact a solid empirical background. F or ex a mple, the dualism b etw een “p ers o ns a nd gr o ups” a s a n under- lying mechanism for so cial connections was first in vestigated by Br eiger [6] in 1974. Within so ciology , the simple phenomenon of homophily – “simila rity breeds connection” – received a great deal o f atten tion: McPherson et al. [42] present ed evidence and inv estigated o n the r ole of homophily in socia l ties; considered features included race and ethnicit y , s o cial status, and geogr a phical lo cation. Bisgin et al. [3] studied instead the ro le of interests in o nline so cia l media (sp ecifically , Last.fm, L iveJournal, and Blo gCatalog ), finding how ever that the role of in terests as features is w eak on those online net w orks—at lea st when cons idering ho mophily only . In some fields, b ehaviors more complex than homophily w ere co nsidered as well. T en- dencies o f such kind, where no des with certain features tend to connect to other t yp e s of no des, are called mixing p atterns in so ciolog y a nd are often described by a matrix, wher e the element ( i, j ) describ es the rela tionship betw een a feature i and a feature j . In epidemiolo gy , mixing patterns hav e pro ven to be greatly beneficial in analyzing the spre ad of contagions. F or example, they app eared to be a crucial factor in tra cking the spread of sexual diseases [2] as well as in mo deling the transmissio n of respira tory infections [49]. F or this reason, such matrices are also called “Who Acquires Infection F r om Whom” (W AIF W) matrices, and ha ve bee n empirically assessed in the field [27, 3 1]. In biology and bioinformatics, a seminal s tudy b y Menche et al. [45] highlighted the connections betw een the int eractome (the net work of the physical and metab olical interactions within a cell) and the diseases each comp onent w as asso ciated with, observing a clustering o f disease-as so ciated pro teins. 3 The empirical evidence prese nted in v arious fields, combined with the existence of large datasets av ailable in the web, and the increa se o f computational r esources, fos ter ed some in vestigation o f mo dels of gra ph endow ed with fea tur e s . Class mo del s. A po pular framework has b een that o f latent class mo dels : in these mo dels, every no de belong s to exactly one class , and this clas s influences the links it may be inv olv ed int o. The b est-known example is the sto chastic blo ck mo del [5 0, 58]: in this mo del, it is assumed that e a ch pair of clas ses has a cer tain proba bilit y of determining a link, and Snijders and Nowic ki [5 8] study how to infer those probab ilities; they also inv estigate how to determine the class assignments, leading to a so rt of communit y detection algor ithm. Hofman and Wiggins [30] devised a v a riant of this sch eme, by sp ecifying o nly within-class probabilities a nd b et ween-class probabilities. Another useful adaptation involv e s s ha ring only the b etw ee n- class pro babilit y and sp ecifying instead the w ithin-cla ss proba bilities separately for eac h class , a llowing to c haracterize each with a certain degree o f ho mophily . Both these approaches exemplify the need to r e duce the n um be r of para meters of the or iginal blo ck mo del, in order to fa c ilita te the estimation of its pa rameters. Kemp et al. [33], and Xu et al. [62], s tudied and applied a non-para metric generaliza tio n of the mo del whic h allows for an infinite num b er of clas ses (therefore ca lled infinite re lational mo del ). It p e rmits a pplica tion on data where the information ab out class is not provided directly . They use a Gibbs sa mpling tech nique to infer mo del parameters. A well-kno wn sho rtcoming of the c la ss-based mo dels is the prolifera tion of cla sses [47], since dividing a class according to a new feature le a ds to tw o differen t classes: if w e hav e a class for “students” and then we wish to account fo r the g ender to o, we will hav e to split that cla ss in “female s tudents” and “ ma le students”. This ap proach is impractical a nd in many cases it leads to ov erlo o k significant dynamics. In or der to ov er come this limitation, some author s [1] e x tended class ical class-bas e d mo dels to allow mixed member s hip. Her e, the mo del of classes remains, but with a fuzzy appro a ch: each no de can b e “split” a mo ng m ultiple classes, a nd in pra ctice class assignments b ecome represented by a probabilit y distribution. F eature mo dels . Contrary to class-based mo dels, fe atur e-b ase d mo dels pro p os e a more natural appro ach for no des with multiple attributes: in those mo dels, ea ch no de is endow e d with a whole vector of features. Ther efore, feature- ba sed mo dels can b e seen as a genera liza - tion of class-based models: in fact, when all the vectors have exactly one non-zero comp onent, the mo del has the same expressive p ow er of class-based ones. F ea tures ca n b e real-v a lued – as in [29] – or binar y , wher e the set of no des exhibiting a feature is crisp, and not fuzzy , like in [44]. Many works in this dir ection pro po sed mo dels that only allow for homophily , forbidding any other in teraction among features. A seminal example is that of affiliatio n net works [38] b y Lattanzi a nd Siv ak umar; in that work, a so cial graph is pro duced by a latent bipartite net work o f actors a nd so cieties ; links among actors are fo s tered by a connection to the same so ciety . Gong et al [21] analyze d a rea l feature-rich socia l net w ork – Goog le+ – thro ugh a generative, fea ture-based netw ork mo del based on homophily . Our attenti on will fo cus instea d on mo dels able to gr asp more complex b ehavior than ho - mophily , following the aforementioned empirical ev idence fro m so c ia l netw o rks, epidemiology and bioinfor matics. MA G m o del family . Within this stream o f resear ch, an imp ortant line of work has bee n explored b y Kim, Lesko v ec and others [36], under the name of multiplic ative attribute gr aphs . Ther e, every feature is descr ib ed by a t wo-b y-t w o matrix, w ith r eal-v alued element s. Those elements describ e the probabilities of the cr eation o f a link in all the p ossible cases of that feature appea ring or no t app ear ing on a given pair of no des. As a conseq uence, it can be thought as a feature-rich sp ecial case of their previous Kr oneck e r mo del [40]. This 4 mo del has be e n fu rther extended to include many other factors ; notably , they hav e mo dified it to b e dynamic [3 7]: features can b e b orn and die, a nd only alive featur e s b e a r effects. How ever, the co mplexit y of this model preven ts it from be ing use d on larg e-scale netw orks. The same a uthors hav e pr op osed [35] a n exp ectation-maximiz a tion a lg orithm to es timate the parameters of their base mo del; nonetheless , rep orted exp eriments are o n graphs with thousands of no des at most. In the dynamic version, they rep o rt examples o n hundreds of no des (e.g., they find that by fitting the interactions of characters in a Lord of the Ring movie, their features effectively mo del the different subplots). In this work, instea d, w e wish to ha ndle net w orks o f mu ch larg er size: in the exp erimental part, we will show examples with many millions of no des, for which we a r e able to estimate model parameters very efficiently . MGJ mode l family . In 2009 , Miller, Griffiths and Jorda n [47] pro po sed a feature- based mo del to describe the link pro bability b etw een tw o nodes b y considering in teractions b etw een all the pairs o f features of the tw o no des. They show ho w by inferring features and their in teractions on small graphs (h undr eds of no des ), they are able to predict links with a very high accura cy (measured through the ar ea under the ROC curve). The estimation tech nique they prop os e is not exact (since this would b e in tr a ctable [23]), but it is based o n a Marko v Chain Monte Carlo (MCMC) metho d [20]. Their mo del can b e interpreted as a ge nerative mo del; they chose, how ev er, not to in- vestigate its str uctural prop erties in terms of the resulting netw o rk structure. Subsequen t work [51] fo cused on this go a l, being able to genera te feature-rich g raphs with realistic fea- tures, but they did not try to es timate the latent v ariables o f the mo del necessary to pr edict links. In this work, we will build on the e v idence gained in our previous work [5], that shows how the Miller-Griffiths-Jor dan mo del (further extended to exhibit comp etition dyna mics in feature generation) can b e a p ow erful to ol to generate netw orks with realistic, global pro p- erties (e.g . distance distr ibution, degree distribution, fraction of reachable pairs, etc.). As explained in previous work [5], th is mo del can a t the s ame time be used to s ynt hesize r ealis- tic graphs by itself, or as a way to generate, g iven a real gr aph, a different one with similar characteristics. Despite the capabilities of the MGJ mo del [47], how ever, the choice of using a MCMC tech nique in the orig ina l w ork [20] re vealed itself inadequate to work on datasets la r ger than some hu ndreds of no des. As noted by Griffiths et al. in 2010 [23], there is a need for computationally efficien t mo dels a s well a s reliable inference schemes for mo deling mult iple mem ber ships. Menon and Elk an [46] noted how the inadequacy in handling large gr a phs underpinned this work, and many similar ones, and ascrib ed this flaw to the MCMC metho d. There has b een, since, a certain amount of studies on how to apply the MGJ mo del o n larger gr aphs. The tw o aforementioned works, for example, tried to so lve this problem in different wa ys. Griffiths and Ghahramani [23] describe d a simpler mo del: they remov ed from the original model [4 7] the possibility of having negative interaction betw een features; also, they fixed the activ atio n function of the mo del (a comp onent which w e will ca refully explain in the next section); in this wa y , they o btained a framework that is more computationally efficient , and c a n b e applied to graphs of up to ten thousand nod e s . Menon a nd Elk an [46], instea d, slightly enriched the mo del, b y introducing a bias ter m for each no de; then, they prop osed a new estimation tec hnique, based o n sto chastic gra dient descent. A main fo cus there was to av oid undersampling non-links to ov e r come class im- balance, since des pite it b eing “the sta ndard strateg y to ov ercome im balance in sup ervised learning” it has the “disadv a nt age of necessarily throw[ing] out information in the training set”. T o overcome this problem (that we so lve instead in the standard wa y of undersampling, see s e c tion 4), they design a s ophisticated a pproach cen tered o n the direct optimization o f the ar e a under the ROC curve. 1 With this technique, they can ha ndle gr a phs with thou- 1 Recen t w orks [63] hav e i ndi cated empirically as w ell as theoretically how employing this measure in link prediction leads to sev erely misleading results. 5 sands of no des. A different appro ach, that obtained s imilar results on gr a phs of the same size, is [17], where the author s prop ose an SVM-based estimation of parameters, and r epo rt it being able to run on gr aphs as larg e as tw o thousa nds no des i n 42 minutes. Our appro ach runs in around 15 min utes o n gr aphs three orders of magnitude bigger . The task we are defining ultimately falls into the r ealm o f latent v aria ble mo dels [1 8], since we ar e trying to explain a set of manifest v ariables – links a nd features – throug h a set of latent v ariables – the feature-feature int eraction weigh ts, i.e., the elements W h,k of the matrix W . If, like in o ur c a se, manifest v a riables a re categ orical, w e usually talk about latent structur e mo dels , that hav e b een studied as such by statisticians and so cial scientist since the 1950’s . Laza rsfeld s ta rted studying th e statistics b ehind these models in an effo r t to explain peo ple answers to ps y ch ologica l questions (sp ecifically , in [59], answers from W orld W ar I I soldiers) thro ug h quantifiable, latent traits [39]. These techniques w ere improv ed by later studies [2 2, 26]; howev er , these techniques—conceived for tr aditional so c ia l studies—were designed for s ma ll groups; the use cases described there do n ot usually in volve mo re than a h undred of nodes. W e require our tec hniques to work with millions of no des, and hundreds of millions of links. Previous literatur e has also treated linked do cument corp ora , wher e features are the words contained in each do cument (e.g., [41] and [11]). In these works, a uthors build a link prediction mo del obtained fro m LDA, that considers b oth links a nd features of each no de. Ho wev er , the la rgest gr aphs consider ed in these works have a bo ut 10 3 no des (with ∼ 10 4 po ssible features), and they do not provide the time req uir ed to train the mo del. [25] developed an LDA approach explicitly tailored for “ large g raphs” — but without any external feature informatio n for no des: they ra ther reconstruct this externa l infor mation from scra tc h; the lar gest graph they considered has a bo ut 10 4 no des a nd 10 5 links, for which they report a running time of 4 5 − 60 minut es. In this work, we too will emplo y a mo del of the Miller -Griffiths-Jorda n family , that we will thoroughly describ e in Section 3. As mentioned ab ov e, a wa y to genera te realistic gra phs with this mo del was s tudied in [5]. Here, we will prop os e some further consideratio ns on that model that will lead (in section 4) to v arious tec hniques aimed at estimating the main parameter of the mo del, i.e., the feature-feature matrix. W e will tes t those metho ds on synthet ic data ge ner ated b y our mo del in section 5. In sec tion 6 we will try our metho ds empirically on real netw orks whose size is unmatc hed by prev io us literature. 3 Our framew o rk Let us briefly pr esent the main a ctors in our theoretica l framework. In this work, we will treat the following ob jects as (at least par tially) obser v able: • The (p ossibly directed) gra ph G = ( N , A ) , where N is the se t of n no des, wherea s A ⊆ N × N is the set of links; for the sake of simplicity , in this w ork w e assume that self-lo ops (i.e., links o f the form ( i, i ) ) are allow ed. • A set F of m features. • A no de-feature associa tion Z ⊆ N × F . W e will denote these o b jects through their matrix-equiv alent represen tation. More pre- cisely , G = ( N , A ) will b e represented as a matrix A ∈ { 0 , 1 } n × n (fixing some a rbitrary ordering o n the no des); Z will b e repres en ted as a matrix Z ∈ { 0 , 1 } n × m (again fixing some arbitrary order ing on the feature s ). In the following, A i,j will refer to the element in the i -th row and j -th co lumn o f the matrix A . The – typically unobser v able – o b jects that will define our netw ork mo del will b e the following: 6 - 3 - 2 - 1 0 1 2 3 0.2 0.4 0.6 0.8 1.0 K = 1 - 3 - 2 - 1 0 1 2 3 0.2 0.4 0.6 0.8 1.0 K = 5 - 3 - 2 - 1 0 1 2 3 0.2 0.4 0.6 0.8 1.0 K = 25 Figure 1: A sigmo id activ a tion function φ , with different choices for K . K regulates its smo othness, a nd for K → ∞ it appro aches a step function. • A matrix W ∈ R m × m , that represent how features interact with eac h other. The idea is that a high v alue for W h,k means that the presence of feature h in a no de i and of feature k in no de j will foster the creation of a link from i to j . Conv er sely , a negative v alue will indica te tha t s uc h a link will be inhibited b y h and k . Naturally , the ma gnitude of W h,k will determine the force o f these effects. W e will re fer to W as the latent fe atur e-fe atu r e matrix . • A monoto nically increas ing function φ : R → [0 , 1] that will ass ig n a probability to a link ( i, j ) , given the re a l n umber res ulting from applying W to the features o f i and j ; w e will call such a fu nction our activation function , in analogy with neural net works [28]. The relationship be t w een those actors is des crib ed forma lly by the fo llowing equation, that f ully defines o ur mo del: P ( i, j ) ∈ A = φ X h X k Z i,h W h,k Z j,k (1) In other w o r ds, the pro babilit y o f a link is higher when the sum of W h,k is higher, where h, k are all the (ordered) pairs o f features app earing in the consider e d pair of no des . W e will now ca refully detail this equation in the following sections. 3.1 Mo del parameters Analysis of the l aten t feature-feature m atrix. Let us p oint out how different c hoices for W can lea d to man y differen t kinds of in terplay b etw een links a n d features. The simplest case is W = I (the identit y matrix). Since its only non-zer o elements ar e those of the form ( k , k ) , the only non-zero elements in the summation are those with Z i,k = Z j,k = 1 . Therefore, the b ehavior of the mo del in this case is that o f pur e homophily : the more features in common, the hig her the probabilit y of a link (remem ber that φ is mo no tonic). More generally , as we said, a p ositive entry W h,k > 0 will indicate a p ositive influence on the formation of a link from no des with feature h to no des with feature k . In the sp ecial case of an undirected graph, we will ha v e a symmetric matrix – that is, W h,k = W k,h for a ll h and k . W ca n be use d to e xpress also other behaviors. If P k W h,k is large, this fact will indicate that nodes with feature h will be highly connected – sp ecifically , they will have a large n um ber of out-links. A la r ge s um for a column of W , that is a large v alue for P k W k,h , will imply , in tu rn, that no des with feature h to hav e many in-links . Choice of the activ ation function. The activ a tion fun ction φ will deter mine ho w the real n um ber s r esulting from P h P k Z i,h W h,k Z j,k will b e translated in to a probability for the even t ( i, j ) ∈ A . Since we require φ to b e monotonically increasing , its r ole is just to shap e the r esulting distribution. 7 Throughout this work, and following previous literature [47], w e will fo c us on activ ation functions th at ca n b e expressed as a sig moid: φ ( x ) = e K ( ϑ − x ) + 1 − 1 (2) The pa rameter ϑ ∈ R is the cent er of the sigmoid, whereas K ∈ (0 , ∞ ) regulates its smo othness. Figure 1 depicts how K influences the re sulting probabilities (when ϑ = 0 ). W e will loo k at both these quantities as a priori par ameters of the mo del. W e will also extend the do ma in of K to the sp ecial v a lue K = ∞ , for which φ is the step function 2 χ ( ϑ, ∞ ) . Letting K = ∞ will mak e o ur mo del fully deterministic—all the probabilities bec o me either 1 or 0 . W e will see how this simplification can turn our mo del in to an imp ortant framework for mining information from a c o mplex netw ork. 3.2 An algebraic p oin t of view F or some applications, it will b e useful to consider the mode l expres sed b y (1) as a matr ix op eration. As introduced in the prev io us section, Z is the n × m no de-fea tur e indicator matrix. With this notation, w e can expre s s (1) as P = φ ZWZ T (3) where φ here denotes the natural elemen t-wise gener alization o f our activ ation function — i.e., it simply applies it to all the elements of the ma trix. The resulting matr ix P is a matrix that descr ib es the proba bilities o f A : that is, its e lemen t P i,j defines the probability that L i,j = 1 or equiv alently that ( i, j ) ∈ A . Y ou can think of P a s an uncertain gra ph [34, 52], of which A is a realization (sometimes called a world [1 5]). Uncertain graphs ar e a con v enien t representation of graph distributions, in the same spirit as the cla ssical E rdős-Rényi mo del: in an uncertain g raph the node set is fixed and each arc ha s a certain pro ba bilit y of being present (arcs are indep endent from one another). Many useful statistical prop e rties o f the graph distribution ass o ciated to an uncertain g raph (e.g., the exp ected num ber of connected comp onents) can b e connected to pro pe r ties of the uncertain graph itself, seen as a simple weigh ted graph; it is this connection tha t made uncer tain graphs pa rticularly po pular in some co nt exts. While this view is simple and concise, it may b e of little use from a computationa l per sp ective. In concrete applicatio ns n will b e very large; also, algor ithms that c o uld b e of use in dea ling di r e ctly with this representation do not run in linear time—the most no table example b eing matrix f actorizatio n (e.g., computing the SVD [60]). It is useful, howev er , to view (3) separately for ea ch row of the matrix. In practice, this means co mputing the set o f out-links of a single node. This op era tio n allows us to treat a single no de at a time, permitting the design of online algorithms, r equiring a single pa ss o n all the no des . Moreov er, this interpretation renders W a (p ossibly asymmetric) similar it y function: if we r epresent no des i and j through their corr esp onding rows in Z (indicating them a s z i and z j ) then our feature- feature matr ix can b e seen as a function th a t giv en these tw o vectors computes a real n um ber representing a weight for the pair ( i, j ) . In the sp ecial case o f W = I this is the sta ndard inner pro duct h z i , z j i ; in this case the similarity o f thos e t w o v ectors is just the n um ber o f features they share, thus implementing ho mophily . Instead, for a general W this similarity is h z i , z j i W (although W is not necessarily symmetric or po sitive definite). 2 W e wi ll use the notation χ I ( x ) = ( 1 if x ∈ I 0 if x / ∈ I . 8 In this sense W can be see n as a function W : 2 F × 2 F → R , that a cts as a kernel for sets of features . 3.3 In trinsic dimens ionalit y and explainabilit y Ev ery fixed g r aph G has a probability that depends on the feature-feature matrix and, of course, on Z , that is, on the c hoice o f the features that we asso ciate with every no de, and ultimately o n the set of features we choose . Some sets of features will mak e the graph more probable than others; we might then sa y that the explainability is a pr op erty of the c ho sen set of features for a certain graph G . W e will measure it in pr actice in some s cenarios in the third, exper imen tal, par t of this work. F or the moment, let us point o ut that the nu mber of features can b e seen as an intrinsic dimensionali ty of the graph G : if the graph co uld be explained b y our mo del without any error at all, then the sa me inf ormation of G is in fact con tained in Z and W . In that case, we might sa y th at the out-links of node i (describ ed in the graph b y ℓ i , the i -th row of the adjacency matrix A ) could be equally repre s en ted b y z i , th us with a m uc h smaller dimension: sp e cifically , with a v ector of m elements. In fact, n is a natural upp er bound for m . Let us use the no des themselv es as features (i.e., F = V ), a sso ciating with every no de i the only feature i (i.e, setting Z = I ). If W = A then the gr a ph will b e a lways p erfectly expla ined: it would be enough to choose φ a s the step fu nction χ (0 , ∞ ) to mak e the results o f o ur mo del iden tical to the gr aph, since P ( i, j ) ∈ A = P i,j = φ ZWZ T i,j = φ ( W i,j ) = ( 1 if ( i, j ) ∈ A 0 otherwise. Naturally , this c hoice of features do es not tell us m uc h; in practice, we ob viously w ant m ≪ n . F or this, we allow for the introduction of s ome degr ee of a pproximation; some links will be wr ongly pr e dicted b y o ur mo del, b ecause it will expec t their c a tegories to link to each other. W e shall call this effect gener alization err or . W e will see in exp eriments ho w it can be measured and how it is intimately connected with the ex plainability of a set of features in a graph. 3.4 In tro ducing normalization Let us now pr esent some interesting v ariants of the prop ose d mo del. In many real- world scenarios, we can sp eculate tha t not all features a r e created equal. F or exa mple, in the formation of a friendship link betw een t wo p eople, disco vering that they b oth ha ve watc hed a very p o pular mo vie ma y not giv e us muc h insight; k nowing instead that they both have seen an undergro und movie that few pe o ple ha ve a ppreciated could give to their friendship link a more solid background. In other words, in some cas e s rarest feature s matter mor e . Column norm alization. T o implemen t this effect, we can normalize Z by column (recall that columns corresp ond to features) in our equa tion, defining ← − Z i,h = Z i,h || Z − ,h || p where Z − ,h denotes the h -th co lumn of Z and || − || p represents the ℓ p norm, for some chosen p . The notation ← − Z is used to emphasize the fact that, if p = 1 , this normalization yields a left-sto ch astic (i.e., c olumn-sto chastic) matrix. Each c olumn can b e seen in this case as a probability distribution a mong no des , uniform on no des ha v ing that feature and null on the 9 others. If we plug ← − Z in place of Z in (1), we obta in P ( i, j ) ∈ A = φ X h X k ← − Z i,h W h,k ← − Z j,k = φ X h X k Z i,h W h,k Z j,k || Z − ,h || p · || Z − ,k || p (4) th us r e a ching the effect we wanted: inside the summation, rare feature s will b ear more weigh t, and co mmon features will b e of lesser imp orta nce . This can also be seen as an adaptatio n of a tf-idf-like schema [61] to our con text. Ro w normali zation. In o ther contexts, row normalizations migh t b e desira ble instead. The fact that tw o peo ple x and y are friends o f the same individual z in F aceb o ok may be a sign indicating that they hav e so me common int erest, and that they ma y b ecome friends in the future; howev er , if x is a public figure then the fact that he is friend with z is no t really significant, and does not tell us muc h ab out p ossible future friendship with y . In other words, no des with few features may matter more. F orma lly , ro w normalizatio n is defined as − → Z i,h = Z i,h || Z i, − || p . where Z i, − is the i -th row of Z . Again, we used the no ta tion − → Z b ecause when p = 1 we obtain a right-stochastic ma trix. 4 Inferring feature-feature in teractio n The fundamen tal agen t in shaping the gra ph in our framework is, a s stated in the previous section, the feature-feature matrix W . In many a pplications, howev e r, the information r ep- resented by W is no t directly av ailable: in a so cial net work, we can observe friendship links and c ha racteristics o f e ach p ers on, but the relationship betw een the characteristics is latent and not observ able. This is the ca se for ma n y other sc e na rios: in a linked document cor- po ra where documents a re describ ed b y a set of topics, we do not kno w how different topics foster or discourage links . Knowing (at leas t pa rtially) links a nd features of ea ch no de, but ignoring how features interact with each other, is also a commo n trait of all the exa mples we men tioned b efore. As discuss e d in Section 1, knowing the latent feature-feature matrix has a lo t of pr actical implications: it can summar ize effectiv ely how features interact with ea ch o ther – in the case of a semantic netw ork tagged with catego ries, it means getting a hold of which categories are semantically connected, for a cita tio n netw ork it means b eing able to identify which fields of research are being useful for a certain field, and so on. More generally , as we dis c ussed in Section 3, knowing W means be ing able to represent all the information expressed by the graph in a mor e succinct w ay . The pro blem we wish to solve is therefor e the following: a ssuming to know A and Z , how can we r e c o nstruct a plausible W ? In other words: if we know the arcs in a graph, and each no de is characterized by a se t of (binary) features, how can w e estimate how features int eract with ea ch o ther ? 4.1 A naiv e approach Let us first describ e a naive approach to construe the latent fe ature-feature matr ix W ; remember that we ar e assuming (1), where Z , A and φ are fixe d (the ro le of φ will be discussed b elow) and w e aim at choo sing W as t o maximize the probabilit y of A . More precisely , we shall use a naive Bay es tec hnique [4], estimating the probability of existence o f a link through maximum likelihoo d and assuming independence b etw een features; 10 that is, we are going to assume that the even ts { Z i,h = 1 } and { Z i,k = 1 } ar e indep endent for h and k . Let us introduce the following no tation: • let N k ⊆ N b e the set of no des with the feature k , i.e. N k = { i ∈ N | Z i,k = 1 } ; • co nv er s ely , let us write F i for the set of fea tures sp or ted by a node i , tha t is F i = { k ∈ F | Z i,k = 1 } ; • let us also use Z i,k to denote the even t { Z i,k = 1 } . Now, fixing t w o features h and k , let us consider the probabilit y p h,k that there is a link betw een tw o ar bitrary no des with those features, such as i ∈ N h and j ∈ N k : p h,k := P ( i, j ) ∈ A Z i,h ∩ Z j,k . Said o therwise, p h,k represents the proba bilit y that tw o no des ( i, j ) happ en to be connected, if we as sume that i has feature h and j has feature k . This quantit y c a n be es timated as the fraction o f pairs ( i, j ) such that b oth Z i,h and Z j,k are true, that happen to b e links. In other words, p h,k = | ( N h × N k ) ∩ A | | N h | · | N k | Here, and in the following, we are a ssuming that self-lo ops a r e allow ed. F o r a sp ecific pair of nodes ( i, j ) , the probabilit y of the presence of a link under the full knowledge of Z is given b y P ( i, j ) ∈ A \ h ∈ F i Z i,h ∩ \ h ∈ F j Z j,h . This is the probability that ( i, j ) ar e connected, g iven that we know their commo n f eatures. Let us naively assume that Z i,h and Z j,k are independent for all i , j, h, k with i 6 = j and h 6 = k ; we also assume that they are indepe ndent ev en under the knowledge that ( i, j ) ∈ A . Then, under these naive indep endence a ssumptions, the la st proba bilit y can b e ex pr essed as Y h ∈ F i Y k ∈ F j P ( i, j ) ∈ A Z i,h ∩ Z j,k = Y h ∈ F i Y k ∈ F j p h,k Let us define W a s: W h,k = log | ( N h × N k ) ∩ A | | N h | · | N k | (5) W e will no w chec k that suc h a matrix is correct. Consider ing aga in the definition o f our mo del (1 ) a nd plug g ing in the matrix W just defined, w e obtain: P ( i, j ) ∈ A = φ X h ∈ F i X k ∈ F j W h,k = φ log Y h ∈ F i Y k ∈ F j | ( N h × N k ) ∩ A | | N h | · | N k | = = φ log Y h ∈ F i Y k ∈ F j p h,k = φ log P ( i, j ) ∈ A \ h ∈ F i Z i,h ∩ \ h ∈ F j Z j,h = = φ log P ( i, j ) ∈ A Z (6) 11 This fact co nfirms that, fo r a cer tain c hoice o f φ (namely 3 , φ ( x ) = min(1 , e x ) ) and under the previously mentioned independence assumptions, this estimate of W is correct for o ur mo del. 4.2 A p erceptron-based approac h The indep endence as sumptions behind the naive approa ch (hereby r e ferred to a s Naive ) are not realistic. One of the p otentially undesirable cons e q uences of such a ssumptions is that the resp onsibility for the existence of a link ar e shar ed amo ng a ll the features of the tw o in volv ed entities. T o understand how misleading this a pproach ca n be, consider a seman tic link betw een the entit y for “ Ronald Reagan” a nd the one for “Cattle Que en of Montana” (a 1954 W es tern film starr ing Rona ld Reaga n). Naive will co un t that link a s a member of the set { ( N presidents × N mov ies ) ∩ A } , a nd it will consequently incr ease the corresp o nding ent ry ( W presidents, mov ies ) in the feature-fea ture matrix. W e would like instead to desig n an algorithm that is able to rec o gnize tha t this link is already well explained by the matrix element W actor s, movies and that do es not enforce a false asso cia tion betw een p oliticia ns a nd W estern movies. In other words, we wan t an algo rithm that p erce ives if some feature is already explaining a link, a nd upda tes its estimate of W o nly if it is not. In this per sp ective, we want to proper ly cas t our pro blem in the setting of machine learning. A deterministic mo del. In o rder to obtain this result, let us simplify our framework b y letting φ be the step function χ (0 , ∞ ) , that is φ ( x ) = ( 1 if x > 0 , 0 otherwise. This ca n b e also seen a s a sigmoid (2 ) whose parameters are ϑ = 0 and K → ∞ . In previous work [5], we found that, even if s uc h an activ a tion function pro duces a mo r e disco nnected net work, the net w ork degr ee distribution will conv erge even more sharply to a p ow er la w. It is important to no te that this c ho ice will make o ur model full y deterministic. In o ther words, g iven the complete k nowledge of Z and W , the mo del will not allow for an y missing or wrong link. F o r this reason, with this mo del we can not measure the likel iho o d of a real net work; instead, we will j ust sepa rate its links in to explaine d and unexplaine d b y the mo del with r esp ect to a cer tain set of feature F . A decision rule. By using this deterministic activ a tion function, the equa tion of o ur mo del (1 ) b ecomes : ( i, j ) ∈ A ⇐ ⇒ X h X k Z i,h Z j,k W h,k > 0 (7) Let us indica te the i - th r ow of Z with z i (as a co lumn vector), the outer pro duct with ⊗ and the Hadamar d product with ◦ . Then, w e can alternatively wr ite the ab ov e rule in one of these t wo eq uiv alent for ms: ( i, j ) ∈ A ⇐ ⇒ z T i Wz j > 0 or ( i, j ) ∈ A ⇐ ⇒ X h,k h z i ⊗ z j ◦ W i h,k > 0 (8) 3 W e need the min in this form ula to respect our assumption that φ only has v alues i n [0 , 1] . H o w ev er, it do es not c hange anyth ing in practice, since i n (6) the argumen t of the logarithm is a probability , and therefor e it is forced to be in [0 , 1] . 12 z i and z j z i ⊗ z j min min min min min P sgn ( i, j ) ∈ A min min min min z i, 1 z i, 2 z i, 3 z j, 1 z j, 2 z j, 3 Figure 2: A neural-netw ork view of the p erceptron-like algorithm, fo r the ca se of m = 3 features. W e indicate fixed weigh ts with double lines, with min those no des activ ating o nly if a nd only if b oth input no des ar e active (that is, the min of their inputs), and with sgn the sign function. The only non-fixed weight s (lea rned by the p er ceptron up date rule) are th ose from the z i ⊗ z j lay er to the P neuron: they corresp ond to the ma tr ix W app earing in our mo del. 4.2.1 A p erceptron. Equation (8) is in fact a spe c ial case o f the de cision rule o f a p erceptron [53], the simplest neural net w ork cla ssifier. The idea here is that by lear ning how to s e parate links from non- links (in fact a form of link pr ediction), the classifier infers W as its in ter nal state. Let us br iefly recall the s ta ndard definition: a p e rceptron is a binary classifier who s e in ternal state is represented b y a vector 4 w ∈ R p , and it classifies an instance x ∈ R p as po sitive if and only if s gn( w · x ) > 0 . The internal state w is t ypically initialized at rando m; then, during the lear ning phas e , for ea ch i ∈ { 0 , 1 , . . . , t − 1 } : 1. the per ceptron o bserves a n example x i ∈ R p ; 2. it emits a pr e diction ˆ y i = sgn( w · x i ) ; 3. it receives the true lab el y i ∈ {− 1 , 1 } ; 4. if y i 6 = ˆ y i , it upda tes its internal state with w = w + y i λ x i , where λ ∈ (0 , 1] is a parameter ca lled le arning r ate . 4 F or the purposes of this pap er, we l imit ourselv es to describing perceptrons with n ull bias. 13 The key p oint here is that the decision rule for e mitting a pr ediction ca n be ca s t to b e fundamen tally the same a s in our mo del. Specifica lly , if w e view the laten t feature-fea ture matrix W a s a v ector of length m 2 , and we do the sa me for z i ⊗ z j , then we can se e that the decision rule sg n( w · x i ) = 1 corresp onds to (8), if we set W as the v ector w and z i ⊗ z j as the example x . Note that in o ur case an ex ample for the per ceptron will be a pair of no des ( i, j ) , r ep- resented no t b y a vector but by the m × m matrix z i ⊗ z j : this is a matrix whose element [ z i ⊗ z j ] h,k is 1 if and only if the first no de exhibits the feature h and the second exhibits the feature k . This trick is sometimes called the outer pr o duct kernel : we are embedding a pair of vect ors o f dimension 2 m into a hig her-dimensional r epresentation of dimension m 2 . This m × m -matrix in fac t can b e a lternatively thought of a s a vector of size m 2 , allowing us to use suc h v ectors a s training examples for the perceptro n, where the label is y = 1 if a nd only if ( i, j ) ∈ A , and y = − 1 otherwise. The learned v ector w will b e, if seen as a matrix, the des ired W app earing in (7), as we are going to analyze next. T o recap, the p erceptro n w e are going to use op erates like this: giv en a T s equence of pairs of no des (elements of N × N ): 1. the per ceptron obser ves the next pair ( i, j ) ∈ T , through their bina ry feature vectors ( z i , z j ) ; 2. it co mputes a prediction on whether they form a link, acco rding to (8); more precisely , the pr ediction will b e ˆ y i,j = sgn( z T i Wz j ) 3. it receives the ground-truth: y i,j = 1 if ( i, j ) ∈ A , a nd y i,j = − 1 otherwis e; 4. if the prediction w as wrong, the updates its in ternal sta te b y adding to W the quantit y y i,j λ ( z i ⊗ z j ) . In doing this, we a r e us ing m 2 features, in fact a kernel pro jection of a space of dimension 2 m in to the larger s pace of size m 2 . Similarly , the w eight vector to b e lear ned has size m 2 . P ositive examples are those that corr esp ond to existing links. W e can v ie w this a s a sha llow, simple neural netw ork, as depicted in Figur e 2. In terpretation of the error b ound. One adv a ntage of casting our approach to the per ceptron alg orithm is that the latter is a well studied and its p er fo rmance was analyzed in all deta ils. In particular, man y b ounds on its accuracy a re kno wn: let us consider the b ounds discussed 5 in [10, Theorem 12.1]. Casting it to our case, some easy manipulations get the following b ound for the n um ber of miscla ssifications M = |{ ( i, j ) ∈ T s.t. ˆ y i,j 6 = y i,j }| : M ≤ inf U ∈ R m × m H ( U ) + R k U k 2 + R k U k p H ( U ) (9) where k − k denotes the F rob enius no rm and • H ( U ) = P ( i,j ) ∈ T max 0 , 1 − z T i U z j is the sum o f the so-called hinge losses and • R = max ( i,j ) ∈ T k z i ⊗ z j k is called the r adius o f th e examples. Let us try to give a n interpretation of this b ound, by lo oking a t all factors affecting the n um be r M of error s o f the algorithm. In the following, w e wan t to use the bound ab ov e to compute the num ber of misclassifica tion whic h we undergo using (8). F or this purp ose, let us set U = W as in (8). Suppo se also, for the sake of simplicit y , that T = A (that is, that we a r e using all and only the links as examples). W e can define tw o subsets of T : E U = ( i, j ) ∈ A z T i U z j ≤ 0 B U = ( i, j ) ∈ A 0 < z T i U z j < 1 . 5 In fact, for the sak e of simplicity we are considering only Euclidean norm and standa rd hinge l oss . 14 The set E U contains the exa mples that a re inc orr e ctly classifie d (i.e., those which are not classified a s links ac c o rding to (8)); the s et B U contains the exa mples that are corr ectly classified but with a very small margin. W e have that H ( U ) = X ( i,j ) ∈ A max 0 , 1 − z T i U z j = X ( i,j ) ∈ E U ∪ B U 1 − z T i U z j ≤ (1 + a ) | E U | + b | B U | , (10) for s o me a, b > 0 with b < 1 . In other words, the ter m H ( U ) in the rig h t-hand-side of (9) is connected with the amount of misclassifications and b or derline-cor rect cla ssifications: each misclassification has a cost that is lar ger than one, w her eas b order line-correc t class ifications are paid les s than o ne each. In a way , H ( U ) is a measure of how well o ur mo del c o uld fit in the b est c ase this pa rticular feature- r ich g r aph. One w a y to reduce the num ber of border line-corre c t class ific ations would b e to m ultiply U by a constan t lar ger than one: note that this opera tion do es not change the c la ssification of (8), but at the sa me time it increa ses the cos t of miscla s sifications (the co efficient a of (10)) and the norm of || U || , that also app ears on the right-hand-side of (9). The pr esence of || U || in the bound is explained by the fact that a mo del with a larg e no rm is (apart from scaling) more complex: e.g ., a very spars e U (one where only a few pair s o f features in teract) will ha ve a v er y low norm. The last term appearing in (9) is R 2 , that can be rewritten as R 2 = max ( i,j ) ∈ T X h X k z i,h z j,k = max ( i,j ) ∈ T | F i | · | F j | . In other words, it mea sures how m any p airs of fe atu r es we need to consider in o ur set of examples. Mo re precisely , this is the num ber of po ssible pairs among the features of the source and the target o f each arc. Of course R 2 ≤ m 2 : this fact mea ns that the b ound is smaller if w e nee d less features to explain the graph. It is also small if there is little ov erlap of features (i.e., if max i ∈ N | F i | is s mall). In the cas e of a feature-rich gr aph that can be p erfectly expla ined by a latent feature - feature matr ix W (according to our deterministic mo del), w e hav e H ( W ) = 0 . In this case, in fac t, all the elements of the sum (that is, the lo s ses suffer ed by the a lgorithm) would be null. This can b e seen using for example the inequality given in (10): the set | E W | would b e empty , a nd the same can be said for | B W | , p ossibly scaling W by a constant. In this sp ecial case, the b ound simplifies to M < R k W k 2 . This is the p erceptron conv ergence theorem [54], whic h in our case tells us that if a pe rfect W exists, the algorithm will conv erge to it. 4.2.2 A passiv e-aggressive algorithm Online learning. In general, what we did w as to recast our goa l in the framework of o nline binary classification. Binary clas s ification, in fact, is a well-known problem in supe r vised ma chi ne lear ning; online classification simplifies this problem b y assuming that examples are presented in a sequential fashion and that the classifier op erates by re p ea ting the fo llowing cycle: 1. it observes an exa mple; 2. it tries to predict its lab el; 3. it receives the true label; 4. it updates its in ter nal state consequent ially , and mov es on to the next e xample. 15 Algorithm 1 Llama , th e passiv e-aggr essive algor ithm to build the laten t feature-feature matr ix W . Input : The graph G = ( N , A ) , with A ⊆ N × N F eatures F i ⊆ F for each no de i ∈ N A pa rameter κ > 0 Output : The feature-feature latent matrix W 1. W ← 0 2. Let ( i 1 , j 1 ) , . . . , ( i T , j T ) b e a s e q uence of elemen ts of N × N . 3. F or t = 1 , . . . , T (a) ρ ← 1 / ( | F i t | · | F j t | ) (b) µ ← P h ∈ F i t P k ∈ F j t W h,k (c) If ( i t , j t ) ∈ A δ ← min( κ, max(0 , ρ (1 − µ ))) else δ ← − min( κ, max(0 , ρ (1 + µ ))) (d) F or eac h h ∈ F i t , k ∈ F j t : W h,k ← W h,k + δ An online le a rning algorithm, generally , needs a constant amount of memory with resp ect to the n um ber o f examples, whic h allows one to employ online algo rithms in situations where a very larg e set of voluminous input da ta is av a ilable. A surv ey is a v ailable in [9]. A well-known type o f online lea r ning algo rithms are the so- c alled per ceptron-like alg o- rithms. They a ll share the s ame traits o f the p erceptron: eac h example must be a vector x i ∈ R p ; the internal sta te o f the class ifier is als o represented by a v ector w ∈ R p ; the predicted lab el is y i = sig n ( w · x i ) . The a lgorithms differ o n how w is built. How ev er, since their decision r ule is always the s ame, they all lead back to the decision rule of our mo del (8). This obse rv ation a llow us to employ any p erceptro n- like algor ithm fo r our pur po ses. P erceptron-like algo r ithms (for e xample, ALMA [19] and Passive-Aggressive [13]) are usually simple to implement, provide tight theoretical b ounds, and have b een proved to b e fast and accurate in practice. A P assiv e-Aggressive algorithm . Among the existing p erceptron- like online classifica - tion frameworks, we will heavily employ the well-kno wn P assive-Aggressive classifier , c harac- terized by being extremely fast, simple to implemen t, and shown by many experiments [8, 4 8] to p erfor m well on real data. Le us now describ e the well-kno wn P assive-Aggressive algor ithm [13], while showing how to ca s t this algorithm for our case. T o do this let us consider a sequence of pairs of no des ( i 1 , j 1 ) , . . . , ( i T , j T ) ∈ N × N (to b e defined later ). Define a sequence of matrice s W 0 , . . . , W T and of slack v ariables ξ 1 , . . . , ξ T ≥ 0 as follo ws: • W 0 = 0 16 • W t +1 is a matrix minim izing k W t +1 − W t k + κξ t +1 sub ject to the constraint that y i t ,j t · X h ∈ F i t X k ∈ F j t W t +1 h,k ≥ 1 − ξ t +1 , (11) where, a s b efore y i t ,j t = ( − 1 if ( i, j ) 6∈ A 1 if ( i , j ) ∈ A , k − k denotes a gain the F r ob enius norm and κ is an optimization parameter determining the a mount of aggres siveness. The in tuition behind the ab ov e-describ ed optimization problem, as discussed in [13], is the fo llowing: • the left-hand-side of the inequality (11) is p ositive if and only if W t +1 correctly predicts the presence/ absence of the link ( i t , j t ) ; its a bs olute v a lue can b e thought of as the confidence of the prediction; • we w ould lik e the confidence to b e a t least 1 , but allow for some err or (embo died in the s lack v ariable ξ t +1 ); • the cost function o f the optimization problem tries to keep as mu ch memory of the previous optimization steps as p os s ible (minimizing the difference with the previo us iterate), and at the same time to minim ize the erro r con tained in th e slac k v a riable. By merging the Passive-Aggressive solution to this pr o blem with our aforementioned framework, we obtain the algor ithm describ ed in Algorithm 1 . W e will refer to this algor ithm as L lama : L e arning LAtent MA t rix . Normalization. F o r per ceptron-like alg orithms, no rmalizing ex ample vectors (in our case, the matrix z i ⊗ z j ) often gives b etter res ults in practice [1 4]. This is equiv alent to using the ℓ 2 -row-normalized version of our model, as discussed in Section 3.4 (setting p = 2 ). The assumption b ehind that mo del is in fact that no des with fewer features provide a s tronger signal for the sma ll set of features they hav e; no des with ma ny features b ear less information ab out those feature. It is immediate to see that Algorithm 1 can be ada pted to use the ℓ 2 -row-normalization b y changing step (c) to: (c) If ( i t , j t ) ∈ A : δ ← √ ρ min( κ, ma x(0 , 1 − √ ρµ )) else : (12) δ ← − √ ρ min( κ, ma x(0 , 1 + √ ρµ )) Similar a daptations would allow one to implemen t any row normaliza tio n. Sequence of pairs. Finally , let us discuss how to build the s equence o f examples . W e wan t W to b e built throug h a single-pass online learning pro cess, where we hav e all p os itiv e examples at our disp osal (and they are in fac t a ll included in the training sequence), but where negative exa mples cannot b e all includ ed, because they are to o man y and they would pro duce overfitting. Both the Passiv e-Aggressive construction des crib ed ab ov e a nd the P e r ceptron algorithm depend crucially o n the sequence of p ositive a nd negative examples ( i 1 , j 1 ) , . . . , ( i T , j T ) that is taken as input. In par ticular, as discussed in [32], it is c ritical that the num ber of neg a tive 17 and po s itiv e ex a mples in the sequence is balance d. T aking this suggestion in to account – and also considering [63] suggestio ns ab out uniform sampling – w e build the s equence a s follows: we draw uniformly at rando m | A | no de pairs ( i, j ) s.t. ( i, j ) / ∈ A ; then, no des ar e enumerated (in a rbitrary or der), and for each node i ∈ N , all a rcs of the form ( i , • ) ∈ A a re added to the sequence, follow ed by all non-links no de pairs of the form ( i, • ) . Of cour se, in the end the sequence co nt ain T = 2 · | A | node pa irs – that is, | A | links along with | A | non-links. Obviously , ther e are other p ossible ways to define th e sequence of examples and to select the subset of negative examples. How ever, we c hose to ado pt this technique (single pass on a ba la nced ra ndom sub-sa mple of pairs) in order to define and test o ur metho dology with a single, na tural and co mputationa lly efficien t appro ach. How ever, when exp erimenting with real data in Section 6, w e will also test whether the ordering of nodes affects the results, b y comparing na tural (i.e. chronologica l) and random order . Error b ound for P assiv e-Aggressive. The analysis of the error b ound for misclassifi- cations of the pe rceptron (9) can be made more precise for the case of the Passiv e-Aggressive algorithm: using Theorem 4 of [1 3], the b ound beco mes: M ≤ inf U ∈ R m × m max R 2 , 1 /κ 2 κH ( U ) + k U k 2 . (13) If κ = 1 /R 2 , the b ound reduces to M ≤ inf U ∈ R m × m 2 H ( U ) + ( R k U k ) 2 , and our disc us sion of (9) is essentially confirmed. W e encounter R 2 = max ( i,j ) ∈ T | F i | · | F j | , that is the maximum num ber of pairs o f features we obse r ve at the same time; H ( U ) , the total loss of the “best” (in terms of the infimum in the equa tion) pos sible feature-feature matrix; and k U k , the norm of suc h a matrix, which is fundamentally a measure of its complexity . Also for Passiv e-Aggress ive, these fa c to rs define the p erforma n ce of the algo rithm on a sp ecific instance o f feature -rich gra ph. A truly on-line a ppr oach with unnormalized samples will r equire a constant κ (in our exp eriments we set 1 . 5 ), which yields M ≤ inf U ∈ R m × m cR 2 H ( U ) + ( R k U k ) 2 , for s o me cons tan t c . 5 Exp erimen ts on syn thetic data In this section, we will test how the metho ds describ ed in this pap er p er fo r m on synthetic graphs g enerated within o ur fra mework using the techniques descr ib ed in previous work [5]; in th e next s ection we will see how they behav e on real-world data. W e are in fact building up o n previous metho ds [5] to g e ner ate a realistic no de- feature asso ciation Z that, when used as input to the mo del o f (1), is a ble to s ynt hesize feature-rich net works with the same traits (e.g., distance distribution, degree distribution, fraction o f reachable pairs, etc) a s typical real complex netw o rks. In par ticular, in [5] we discuss how to generate a syn thetic feature-r ich gr aph with the same prop erties as a given real o ne. These exp eriments allow us to emplo y gra phs g e nerated through this appro a ch as a test b ed for the algorithms pr esented in the Section 4. 18 A vg. features p er no de S χ exp B 5 . 8 4 ± 1 . 6 3 5 . 17 ± 1 . 6 3 5 . 22 ± 1 . 51 N 5 . 76 ± 1 . 43 5 . 30 ± 1 . 56 5 . 51 ± 1 . 31 A vg. degree S χ exp B 10 9 . 4 ± 325 163 . 2 ± 329 15 . 6 ± 217 N 10 . 9 ± 145 11 . 8 ± 138 2 6 . 3 ± 29 9 Mean harmonic distance S χ exp B 2 . 1 6 ± 92 2 . 43 ± 1 339 2 . 02 ± 3 290 N 2 . 31 ± 3 034 11 . 0 ± 2 472 2 . 01 ± 1 606 T able 1: Prop erties of the synthetic feature-rich graphs. The 6 gener a ted graph families ar e indicated according to the φ function used ( S is the sigmoid, χ is th e step function, and exp is the exponential) and to the distribution o f the v alues of W (Bernoullian or normal). The listed properties represents the median, inside each graph family , of: the a verage num ber of features p er node, the a v erage degree a nd and the mea n harmo nic distance. 5.1 Exp erimen tal setup T o gener ate eac h net work, w e first pro duced its node-featur e a sso ciation Z with the Indian Buffet Mo del metho d [5], using the sa me parameter v alues adopted in previous work: α = 3 , β = 0 . 5 , c = 0 . Then, we fed these matrices Z to our mo del equa tion (1) to gener ate a n um be r of graphs. F or the gr aph mo del, w e employ ed the follo wing parameters : • W e used n = 10 0 00 no des. • W e applied three differen t t ype s of activ a tion function φ , to compare their results: 1. The classic sig moid function S ( x ) = e K ( ϑ − x ) + 1 − 1 , cited in Section 3.1 as w ell as in [5] as the standar d approach; we set ϑ = 0 a nd K = 5 . Please no te that this function do es not resp ect the assumptions for which we derived Llama , nor those o f Naive . 2. The step function χ (0 , ∞ ) , c ha r acterizing the model behind Llama . 3. The exp function, whic h c ha r acterizes the model behind Naive . • The latent matr ix W was genera ted assuming that its en tries ar e i.i.d., with the fol- lowing t wo v alue distributions: 1. A generalized Be r noulli distribution W h,k ∼ B ( p ) that assumes the v alue 10 with probability p = 10 m and − 1 with probability 1 − p . This choice was determined through exp eriments, with the pur p os e of obtaining gra phs with a realistic dens ity independently fro m the n um ber of features m . 2. A normal distribution W h,k ∼ N ( µ, σ ) with mea n and v ariance identical to the previous Ber noulli distribution. 19 3. W e had to slightly mo dify these distributions for the ca se φ = exp , in or der to obtain r ealistic gra phs also in that case: in par ticula r , when φ = exp we used a Bernoulli distribution with v a lue 1 with proba bilit y p = 1 m and − 1 with probability 1 − p , and a nor ma l distribution that had the same mean and v ariance as the just- describ ed Bernoulli distribution. In the following, when w e say that φ = e xp we imply tha t we used one of these tw o mo dified distributions to generate W . With these three c hoices for φ and t wo choices for the g eneration of W , w e obta ined six different families of feature-rich gra phs. F or each graph family , we genera ted 1 00 differen t graphs. The proper ties of these net w orks are summed up in T able 1. They repr esent a wide range o f r ealistic traits w e could actually obser ve in co mplex netw orks. 5.2 Ev aluation First o f all, even if the a im of both Llama a nd N aive is to recons truct the matrix W , we are not interested in the a ctual v alues of the elements of W . O ur goa l is to find a feature-featur e matrix for which our mo del w orks: it is no t important if the v alues a re s caled up o r s hifted as lo ng a s the predictions of our mo del for the links remain correct. F or this reas on, we will measure directly how ac c ur ate our methods are in ter ms of predicting if a no de pair ( i, j ) forms a link, g iven their featur e s . T o keep this ev aluation meaningful, our algorithms will no t b e allowed to see the whole gr a ph: we will use the standard appro ach of 10 -fold cross- v alidation; i.e., we divide the set of no des N in to ten subsets (folds) of eq ual size, a nd we used nine folds to train the a lgorithm and the tenth remaining fold to test the results (for each p ossible choice o f the latter). Our ev aluation closely re s em bles the approach follow ed fo r link pr e diction . There ar e of course s o me differences: fir st of all, we are using an external so urce of information (the no de features) that is not av ailable to link-prediction metho ds; s e cond, our aim is to ev a luate our mo del and o ur a lgorithms to find W t hr ough link prediction. That is, we a re not in terested in finding the b est existing link predictor , but in measuring if our algorithms can corr e ctly fit o ur mo del on a spe c ific instance of feature -rich graph ( G, Z ) . Ho w ever, w e follow ed the ev aluation guidelines for link prediction recen tly stated b y Y ang et al. [63]. • W e ev aluated how accurate our alg orithms are in prediction by sho wing precision/r ecall curves: Y ang et al. [63], in fact, obser ve that other alter natives, such as the ROC curve, are heavily biased after undersampling negative examples and can yield misleading results; s ince tied sco res do affect res ults (esp e c ially for Naive ), we employed the tech niques described in [43] to compute precision and recall v alues for tied scores. • Using precision/re c all curves a llow us to av o id using a fixed thresho ld b et ween “link”/“ not link”; it is imp or ta n t, in fact, to ev aluate the sc or es themselves; on the co n trary , by choosing a thr e s hold ϑ and then conv erting each scor e x to a binary event x > ϑ would make the compariso n unfair; we instead used directly the s c o re computed b y o ur model (the ar g umen t of φ in (1)) since the larg er this score, the more probable that link should be. • W e used the same test set for all the tes ted algor ithms. • Althoug h in our ca se it was necessary to under s ample negatives (th e total num b er o f no de pairs would b e unmanagea ble), we to ok care of sampling uniformly the edges missing from the test netw o rk: w e draw no de pair s ( i, j ) such that ( i, j ) / ∈ A uniformly from the set N × N , un til we had a num ber of non-arc s equal to the num b er of arc s . Since o ur metho ds are not influenced b y the distances of the pair s of no des in volv ed (contrarily to standar d link prediction a pproaches), we av oided to g ather our results by geo desic distance. 20 A UPR Time (s) Naive 0 . 824 ± 0 . 0 28 0 . 034 ± 0 . 0 34 Llama 0 . 89 3 ± 0 . 020 0 . 097 ± 0 . 097 SVM 0 . 915 ± 0 . 014 6439 . 303 ± 6439 . 30 3 T able 2: Area under the precision-recall curve (o n av erage across 10 folds and 4 exp eriments) and the required training time in seconds. F or each v a lue we rep ort the mean and the standard deviatio n. With the ab ov e considerations in mind, w e pro ceeded to e v aluate our approach using precision-rec all cur ves. F or ea ch of the netw orks and for each fold, we gave the training graph as input to the algorithm ( Llama or Naive ) and obtained an estimated matr ix W . This ma tr ix is defined by 6 (5) for N aive and b y 7 Algorithm 1 for Llama . Each metho d then assigned its sc ore (i.e., the a rgument of φ in (1)) to each node pair in the test set, a ccording to our model. 5.3 T raining time Before discussing the results, let us present a measure of the training times of the a lgorithms we prop ose, in comparison with SVM, a baseline previously employ ed in the litera ture for feature-rich g raphs [17]. F or this alg orithm, we are using an efficient implementation (the one from WEKA [24]), written in the same langua g e as o ur own alg orithms, a nd using ther e fo re the s ame metho ds for I/ O. W e employ ed a linear k ernel (the fastest) for the SVM. The results we show are ab out a single gra ph family of the o nes discussed ab ov e (sp ecifi- cally , the case where W h,k ∼ N ( µ, σ ) and the sigmoid function S ( x ) is used a s a n activ a tion function). These are the most common cas e s treated in the literature. Also , w e needed to set a low e r n um ber of no des n = 100 0 in order for the SVM to terminate. Our results (T able 2 ) show a training time for the SVM tha t is four or ders of mag nitude longer than Naive or Llama , i.e., taking on the scale of hours for gr aphs of thousands o f no des. These results are consisten t with the previo us literature. Perceptron-like a lgorithms are known to b e muc h less c o mputationally exp e ns ive than traditiona l SVMs [56]. How ever, despite them to b e un usable a t the sca le we wan t to oper ate (tens millions of nodes ), it is worth noting that their performance is (slightly) be tter than Llama in th is par ticular case. 5.4 Results W e repo rt detailed p erforma nce results for Naive and Llama in T able 3. There, we sho w the av erage AUPR (Area Under Precision-Reca ll curve) obtained acros s a ll the graphs inside each graph family consider ed. T o co mpute the AUPR we us e d the technique describ ed b y Davis a nd Goadr ich [16]. F ollowing the previous sugg estions [63], we use this area as an ov erall mea sure of the go o dness of our approach. W e can see how the results of Lla ma ar e on av e r age ab ov e 9 5% for b oth the step function and the sigmoid a ctiv ation function. The exp cas e , in fact, is the 6 In the case ( N h × N k ) ∩ A = ∅ , the Naive approac h as describ ed b y (5) w ould set W h,k = log 0 . W e tried t w o alternativ e strategies to solve this i ssue: (i) setting W h,k equal to a large negativ e nu mber for those pairs ( de facto putting a lo w er bound to W h,k ); (ii) employing an add-one smoothing [55], i.e., using log( x + 1) in place of log( x ) . The experimental results are essentially the same in the t wo cases. The figures presente d in this section are the ones obtained b y (i). 7 W e tried also th e normalized ve rsion of Lla ma expressed in (12), for differe n t v alues of p , l ea ving the model unc hanged. Again, the experimental results obtained are the same on our datase t, so we are here presen ting the v alues obtained b y the unnor malized version of the algorithm. 21 S, B S, N χ, B χ, N ex p , B exp , N Naive . 843 ± . 060 . 95 1 ± . 14 8 . 599 ± . 28 8 . 798 ± . 2 58 . 931 ± . 232 . 972 ± . 084 Llama . 974 ± . 0 16 . 951 ± . 151 . 973 ± . 018 . 967 ± . 117 . 529 ± . 279 . 880 ± . 155 T able 3: Area under the pr ecision-reca ll curve of Naive and o f Ll ama . F or each o f the considered gr a ph families, w e rep ort the mean and the standard deviation a c ross all the graphs. one wher e Naive works better – as it was expected from the theo ry . In the norma l case, the per formance of Llama is still go o d; a Bernoulli distribution with an exponential activ ation function is instead the only case when Llama performance is inadmissible. As w e shall se e in Section 6 , though, the e xp cas e does not c o rresp ond to a realis tic setting. Let us discuss in deta ils the r esults obtained, g athering them b y the activ ation fun ction employ ed to generate the graph. T o b e able to gra s p what happe ns across different folds in a sing le gr aph, and to av oid ov ercrowding the plots, we will rep ort the precision-r e c all plots for a single g raph inside each family . Step activ ation (Fig ure 3 and 4). Let us first consider the case of the net w orks generated with a step ac tiv ation function. Note that b y using χ (0 , ∞ ) as the activ ation function we are making our mo del deterministic — a pair forms a link if and only if its score is p ositive. F urthermore , this is precisely the activ ation function fo r which we hav e forma l guarantees on the Llama p erfo r mances. In fact, its results ar e remar k ably go o d, as testified b y a n area under curve b eyond 9 6% in both the Berno ullia n and the Gaussian case. Naive is able to take adv antage of this clean a ctiv ation function only with a normal distribution on the v alues of W (where its p erfor ma nce is aro und 80% ); in the ber no ullian case, it degrades tow ard a random class ifier. Exp onent ial activ ation (Figure 5 and 6). Let us now loo k a t the e x po nen tial ac ti- v ation fun ction, for which we hav e formally der ived Naive . The results obtained b y Naive are in fact very go o d at all recall levels. Llama , on the other hand, obtains its w orst p erfor ma nce on this simulation, due to the fact that the expo nen tial function is mostly dissimilar from Lla ma ’s natural one (the step function). In the b ernoullian ca se its p erformance is chaotic, and dep ends very m uch on the training set; instead, in the normally- dis tr ibuted ca se, the are a under the precision-r ecall curve is definitely b etter, around 80 % on a v erage. Sigmoid activ ation (Figure 7 and 8 ). Finally , let us lo ok at the results obtained when the activ a tion function is a sigmoid (2) with K = 5 . W e emphasize that this a ctiv ation func- tion is one for whic h w e hav e no theoretica l guarantees, neither for Llama ( which assumes a step function) no r for Naive (which assumes an e x po nen tial); also, it is the function of choice in previo us literature (e.g. [47]). W e rep ort in Figure 7 the precisio n-recall curves for the case of the B ernoulli distribution and in Fig ure 8 the precisio n-recall curves for the case of the normal distribution. W e can see how N aive p erforma nce s display a high v ariance and are w ay b ehind the Llama per formances, espe c ially in the Bernoulli-distributed case. Llama perfor ma nces in fact are almost as go o d as in its na tur a l step function ca se, with a n area under curve consistently beyond 9 5% . The unambiguous prev a lence of L lama in this “natural” case could explain the results we a r e showing in the next section. 22 0.5 0.6 0.7 0.8 0.9 1 0 0.2 0.4 0.6 0.8 1 precision recall 0.5 0.6 0.7 0.8 0.9 1 0 0.2 0.4 0.6 0.8 1 precision recall Naive Llama Figure 3: Precision-rec a ll curves in the netw ork χ, B . Different color s represe nt different folds used in cross-v alidation. 0.5 0.6 0.7 0.8 0.9 1 0 0.2 0.4 0.6 0.8 1 precision recall 0.5 0.6 0.7 0.8 0.9 1 0 0.2 0.4 0.6 0.8 1 precision recall Naive Llama Figure 4: Precisio n-recall curves in the net work χ, N . Different co lors represent differe nt folds used in cross-v alidation. 6 Exp erimen ts on real data In this section, we will fo cus on (1 ) how our a lgorithms b ehave on real- world feature-r ich net works and (2) how our framework can b e used to ev alua te the r elationship b et ween a net work and a particular set of features for its no des. In particular, we will c o nsider the fitness of our mo del as a measure of how muc h a ce r tain set o f features ca n explain the links in suc h a gra ph. Explainability . Given a g r aph G = ( N , A ) a nd a particular set of features ˆ F that can be asso ciated to its nodes (with ˆ Z ⊆ N × ˆ F ), we can define the explainabi lity of ˆ F for G to be the area under the precision-r ecall curv e obtained by the scor es pro vided by our model; with “sco re” we mean, a s b efore, the ar gument of φ in (1), wher e the matrix W is the o ne found b y Alg o rithm 1 when it is given G and ˆ Z as input. W e ag ain use the AUP R (Area Under Precisio n-Recall curve) as a measure of fitness, as we did in Section 5.3. 6.1 Exp erimen tal setup W e are going to consider a scientific netw ork r ecent ly re le a sed by Micro soft Resea rch, and known as the Micros oft Academic Graph [57]. It r epresents a very large (tens of millions), heterogeneous corpus of scien tific works; each scientific work has some metadata associa ted 23 0.5 0.6 0.7 0.8 0.9 1 0 0.2 0.4 0.6 0.8 1 precision recall 0.5 0.6 0.7 0.8 0.9 1 0 0.2 0.4 0.6 0.8 1 precision recall Naive Llama Figure 5: Precis ion-recall curves in the netw ork exp , B . Different colors represent different folds used in cross-v alidation. 0.5 0.6 0.7 0.8 0.9 1 0 0.2 0.4 0.6 0.8 1 precision recall 0.5 0.6 0.7 0.8 0.9 1 0 0.2 0.4 0.6 0.8 1 precision recall Naive Llama Figure 6 : Precision- recall curves in the net work exp , N . Different color s r epresent different folds used in cross-v alidation. with it. W e will co nsider the c ita tion net w ork formed by these pap ers: this is a directed graph whose no des ar e the pap ers, and with an arc ( i, j ) ∈ A if and only if pa p er i contains a citation to pa per j . As for the features , we will cons ider the following a lter native se ts o f no de features: • a uthors’ affiliatio ns : for each pap er, a ll the institutions that each author o f the pa- per claims to be ass o ciated to. “Univ ersity of Milan” and “Go ogle” are examples o f affiliations. • the set of fields of stu dy : the field of study as so ciated by the dataset c ur ators [57] to the keyw o r ds of the paper . “Complex net w ork” and “V er tebrate paleont ology” a re examples of fields o f s tudy . These features fully resp ect all the assumptions we made: they ar e a ttributes of the nodes, they ar e binary (a no de can have a feature or not, without any middle ground), they a re po ssibly overlapping (a paper can have more than one affiliation/field asso cia ted with it). Our g oal now is to compare the explainability (as defined ab ove) of these tw o sets of features for the citation netw or k. Since we wan t to compare them fairly , we reduced the dataset to those no des for which the dataset specifies b oth fe a tures: tha t is, pa per s for whic h bo th the affiliations and the fields of study are re p or ted. In this way we obtained: 24 0.5 0.6 0.7 0.8 0.9 1 0 0.2 0.4 0.6 0.8 1 precision recall 0.5 0.6 0.7 0.8 0.9 1 0 0.2 0.4 0.6 0.8 1 precision recall Naive Llama Figure 7: Precision-rec a ll curves in the netw ork S, B . Differen t co lors r e present differen t folds used in cross-v alidation. 0.5 0.6 0.7 0.8 0.9 1 0 0.2 0.4 0.6 0.8 1 precision recall 0.5 0.6 0.7 0.8 0.9 1 0 0.2 0.4 0.6 0.8 1 precision recall Naive Llama Figure 8: Precisio n-recall curves in the net work S, N . Differen t colors repres e n t differe n t folds used in cross-v alidation. • A gra ph G = ( N , A ) wher e N is a set of 1 8 93 9 15 5 papers, and A co ntains the 189 465 540 citations betw een those paper s. • A s et F a of 19 834 affiliations, and the as so ciation Z a betw een paper s and affiliations. Each paper has b et ween 1 and 182 a ffilia tions; o n av erage, we hav e 1 . 3 6 affiliations p e r pap er. • A set F f of 47 26 9 fields, and the ass o ciation Z f betw een pap ers and those fields o f study . Each paper involv es b etw een 1 and 200 fields; on av erage, we hav e 3 . 88 fields per pap er. • As a further type o f test, we p erfor med the experiments also on the union F a ∪ F f . W e pro ceeded then to ev aluate the explainability o f F a and F f for G with the same approach prese nted in Section 5.3: 1. W e divide the set N in ten folds N 0 , . . . , N 9 . 2. F or eac h fold N i : (a) W e a pply Algor ithm 1 to the part o f A a nd Z r elated to th e training s et ∪ j 6 = i N j . (b) W e obtain a matr ix W . 25 0.5 0.6 0.7 0.8 0.9 1 0 0.2 0.4 0.6 0.8 1 precision recall 0.5 0.6 0.7 0.8 0.9 1 0 0.2 0.4 0.6 0.8 1 precision recall Naive Llama Figure 9 : Prec ision-recall cur ves of the Naive baseline and of Llama , when explaining the citation netw ork using the affiliation of author s as features. Differen t colors re pr esent different folds used in cross-v a lidation. 0.5 0.6 0.7 0.8 0.9 1 0 0.2 0.4 0.6 0.8 1 precision recall 0.5 0.6 0.7 0.8 0.9 1 0 0.2 0.4 0.6 0.8 1 precision recall Naive Llama Figure 10: Precision-reca ll curves of the Naive baseline and of Llama , when explaining the citation net w ork using the fields of study of eac h paper as features . Differen t colors represent different folds used in cross-v a lidation. (c) W e compute the scores o f our mo del with W on th e test set N i . (d) W e measure the precision-rec all curve for these scores. In or der to v alidate on real data the re s ults we o btained in Section 5.3 for s ynt hetic data, we also car ried o ut the same pro ce dur e also with the W matrix found by N aive . As a result, we obtained t wo ten-folded precis ion-recall curves fo r ea ch o f the thre e set o f features considered: F a , F f and F a ∪ F f . F urthermor e, w e a re compar ing tw o different order ings for node sequences in Llama : one is purely random (the one we s uggested in Section 4.2.2), while the other is the natural order of no des in this case, i.e., the chronological o rder of pap er publication. Please no te, how ever, that the 10 -fold cros s-v alidation is still op erated a random (each train-test split is p erformed randomly , r egardless of ordering). 6.2 Results In T able 4 w e rep or t the explainability we o btained (measur ed a s the area under the precisio n- recall curves shown). W e rep ort in Figure 9, 1 0 a nd 11 the precision-r ecall curves for Na ive and for Llama co ncerning the feature set F a , F f and F a ∪ F f , respectively . 26 Affiliations Fields of study B o th Llama . 5551 ± . 0028 . 9162 ± . 0003 . 9210 ± . 0 012 Llama (natural order) . 5446 ± . 0013 . 906 3 ± . 0004 . 9176 ± . 0 002 Naive . 5237 ± . 0005 . 600 7 ± . 0 004 . 6345 ± . 0 002 T able 4: Area under the precision-rec all curve o f the Na ive ba s eline and o f Llama . F or each of the feature sets considered, w e rep o rt the mea n and the standard deviation across the ten folds. W e highlighted the explainability for the citatio n net work of the affiliations and of the fields of s tudy , respectively . 0.5 0.6 0.7 0.8 0.9 1 0 0.2 0.4 0.6 0.8 1 precision recall 0.5 0.6 0.7 0.8 0.9 1 0 0.2 0.4 0.6 0.8 1 precision recall Naive Llama Figure 11: Precision-reca ll curves of the Naive baseline and of Llama , when explaining the citation netw ork using b oth the a ffilia tions a nd the fields, tog ether, as features. Differen t colors r epresent different folds used in cross-v alidation. F rom the table, we can see that the explainability of the fields o f study for the citation net work is muc h larg er than that of the authors a ffilia tions: the firs t is ab ov e 92% , while the second is 56% . In this se ns e, our model allows us to say that the fields of study of a pap er explain very w ell its citations, while the affiliations of its a uthors do not. This might not come as a surprise (the relationship betw een the fields a pap er b elongs to a nd its citatio ns is quite natural) but our contribut ion here is the formal framework which allows us to bac k this a ssertion with solid num bers, through (1) and Algor ithm 1. W e can further v alidate this statement by loo king at the explainabilit y for F a ∪ F f : its v alue o f 92 . 1% is just faintly over the v alue of 91 . 6% obtained for fields alone, implying that the gain obtained by including the who le new set F a of 19 83 4 feature s is pr actically negligible. Finally , it is worth noting that the order ing of the no de does not affect muc h the r e s ults, that go fro m 9 1% of the usual random or der to 90% for the natural order. W e c an grasp more details by lo oking a t the sp ecific prec ision-reca ll curves. By com- paring the Ll ama curve for affiliations in Fig ur e 9 and the one for fields in Fig ur e 10, we can see immediately tha t the latter depicts a v alid classification instrumen t; ther e, the pre- cision/reca ll break-even point is around 8 3% . Also, we can see some specific characteristic of the affiliation feature set: it is in fact able to r each a la rge precis io n, but o nly in the v ery low rang e of reca ll. Her e, a precision of 83% is p ossible only with a reca ll low er than 7% : the rea son behind this is that an a uthor’s affiliation is e ffective in encoura ging a citation in a very limited se t of circumstances; we can conjecture that homophily within small institutions could b e an example. Finally , let us remark how the res ults we obtained on syn thetic data in Section 5 .3 a r e 27 fully confirmed by the r e a l data we presented here: Llama , in a ll the three cases, b ehav es m uch b etter than Naive . T his is esp ecially true for the feature set tha t actually explains the net work: for the fields of study , Llama is a ble to get a 91% v alue for A UPR, while the W matrix found b y Na ive appr oach can barely g et a 6 3% . In particular, precision-r ecall c ur ves lo ok similar to the one shown in Figure 7, co rresp onding to the simulation obtained with φ set to a sig moid and W having a Bernoulli dis tr ibution; real data is actually les s shaky , due to the fact tha t we ha ve 18 millions of nodes instead of the 10 000 used in the simulation. Besides confir ming the v alidity of Ll ama , this o bserv ation also co nfirms the go o dness o f our mo del in expla ining a real gr aph. 7 Conclusions and future w o rk In this work, we inv estigated la r ge, feature-rich co mplex netw orks (netw orks where each no de is characterized b y set of features). Sp ecifically , w e wan ted to analyze a mo del where no de features induce the formation of the links we observe. This hypo thesis is reasonable in many sc e narios (the citation netw orks used in o ur exp e r iments a r e just one example). As discussed in Sec tio n 2, w e employed the Miller- Griffiths-Jorda n mo del as our starting p oint. The pro blem we dealt with was how to infer the laten t feature-fea ture matrix: this ma trix is the main unknown o f the model; it deter mines how features int eract b etw e en each other to give ra ise to the obser ved links. Specifica lly , we fo cused on the following scenario: as s ume to hav e complete knowledge of a no de-feature asso ciation matrix – i.e., to know for every no de, the features it exhibits (em bo died in the binary matrix Z ); also, assume to hav e an (at leas t partial) kno wledge of the links b etw een these no des (the g r aph G ). Our goal was, given these element s, to find the laten t interaction betw een features that gov erns link formation in the gra ph G ; i.e., to discov er the latent matrix W o f our mo del (1). This estimate alone allows us to use our mo del as a p ossible wa y to pr edict which pair of no des form a link. Other p ossible applications include dimensionality reduction o f the features, mea s uring sema ntic distance, discovering hidden r elationships, and so o n. While ma n y p oss ible metho ds a r e av ailable in liter ature to attack these problems, they generally only ca n handle small/medium sized netw orks, while w e are interested in large-scale net works. This ruled out many well-kno wn techn iques, lik e MCMC. Our first a pproach was guided b y a Naiv e Ba y es scheme: we demonstra ted that a very simple equation to estimate the matrix can b e derived by assuming (na ively) independenc e b etw een features, and by making a few ass umptions to restrict our mo del. How ev er, we p ointed out how its naive assumptions can cause problems in pr actical applications, a nd for this reason we described a mo r e so phisticated appro ach, based o n perceptrons. T o link it formally with our mo del o f c hoice, we a ssumed it to be deterministic b y c ho o sing a step activ ation function φ in (1). This assumption allow ed us to align o ur mo del equation to a p erceptro n decision rule, by applying an outer pro duct kernel to the bina ry vectors z i and z j representing the fea tur e s in no des i and j , and to make the p erceptron predictions represent whether they form a link or not. In this w a y , the in ternal state of the p erceptron conv e r ges to the latent feature- feature matrix W . W e descr ibed this le a rning-based approach, and analyzed w ha t a classica l bound on the num ber of errors of a p erceptro n means in this case. Then, s ince any p erceptron-like algorithm can be adapted for this purpo se, we chose the simple and fa s t Passiv e-Aggres s ive algorithm [1 3] to concr etely implement this appr oach (Algorithm 1). In the exp erimental section, we tested how this a lgorithm b ehaves on synthet ic data. W e generated gra phs and node-featur e asso ciations accor ding to the mo del presen ted in [5], under different assumptions. In measuring the outcomes , we a do pted the same techniques as suggested in [6 3]: s p ecifica lly we measured the link prediction capa bilit y of the estimated W through a ten-fold cross-v a lidation. Results sho w ed how our learning approach outp erfor ms 28 the Na ive bas eline in all the analyzed cases, except for the exp activ ation function. Finally , we conducted an exper imen t on a real da taset, a citation net w ork compo s ed b y 18 9 39 155 no des and 189 4 65 5 40 link; running the algo rithm require d ab out 20 min utes. In fact, we used the too ls we dev elop ed for estimating the featu r e-feature matrix in or der to v alidate their per formance on real data, and to s how ho w they can be used to assess whic h feature se t can b e more useful in explaining the links of a net w ork. In this work, o ur ma in contribution consisted in laying out a bridge b etw een perceptron- like learning algor ithms and feature-r ich graph models; we forma lly present ed the c o nnection betw een them, and we show ed how they can b e v aluable fro m a practical po int of view when analyzing g raphs that ha ve tens of millions of no des or mor e. W e hop e that the intersection of machi ne learning and complex netw ork mo dels will attract more research in the future; man y questions ar e left open on these topics. Giv en a sp e cific graph (pos sibly with features) how c a n we under s tand what is the bes t mo del that can expla in its links? Can th is model also offer a lea r ning algo rithm that allows us to make predictions ab out unknown no des? A full answer to this ques t ion would lo ok , from o ne side, like a net w ork “family tree”: it would en umerate po ssible mo dels of net works b y describing the formation of their links, ea ch b eing mor e or less reasona ble depending on the sp ecific net work at hand. F ro m the other side, suc h a “family tre e ” would lo ok lik e a too lbox in the hands o f the net work scient ist: ea ch mo del should offer algor ithms for link prediction that could b e more o r less accurate or computationally efficient. Regarding the efficiency o f algorithms for our mo dels, there ar e some alternatives that are left unexplor ed: for example other online a lgorithms, like PEGA SOS; also, we would like to inv estigate be tter formal connections betw een neural netw o rks and complex netw orks; for example, ca n deep er neural netw o rks also be read as a sensibl e feature-rich graph mo del? Other future directions stem, o n the contrary , from mo difying our mo del. The latent matrix W , as recons tr ucted b y the algo rithms describ e d in this pap er, will b e dense; what happ e ns if w e reduce its dens it y (e.g., by thresholding the abso lute v a lue of its en tries)? How m uch w ould that impact on our ability to reconstruct A ? This density/precision tradeoff can b e taken into c onsideration fro m start: we may wan t to try to co nstruct a laten t ma trix that satisfies so me constr aints (e.g ., on its density , or o n its no r m). This constrained version of the problem may shed new ligh t on the relation b etw een features and links, and can b e a fruitful res earch directio n. Finally , w e re ma rk how it would b e definitely imp orta nt to test the propos e d tec hniques on o ther real feature-r ich complex netw or ks, in order to see in which concrete case s they ca n improv e over the current techniques for link prediction and, mor e g e ner ally , for understanding hidden pa tterns in net w ork data. W e consider these questions of pr ima ry imp ortance, in order to b e able to av oid viewing graph mining algorithms as blac k boxes, but considering instead what they could say ab out the s tructure and the evolution of specific complex netw orks. References [1] Edoardo M. Airoldi, David M . Blei, Stephen E . Fienberg, and Eric P . Xing, Mixe d memb ership sto c hastic blo ckmo dels , J. Mach. Learn . Res. 9 ( June 2008), 1981–20 14. [2] S. O Aral, J.P . Hughes, B. Stoner, W. Whittington, H .H. Handsfield, R.M. Anderson, and K.K. Holmes, Sexual mixing p att erns in the spr e ad of gono c o c c al and chlamydial infe ct i ons. , American Journal of Public Health 89 (1999) , no. 6, 825–83 3. [3] Halil Bisgin, Nitin Agarwal, and Xiaow ei Xu, A stud y of homophily on so cial me dia , W orld Wide W eb 15 (2012), no. 2, 213–232. [4] C.M. Bishop, Pattern r e c o gnition a nd machine le arning (informa tion scie nce and statistics) , Springer- V erlag New Y ork, Inc., 2006. 29 [5] Paolo Boldi, Ir ene Crimaldi, and Corrado M on ti, A network mo del char acterize d b y a latent att ribute structur e with c omp etition , Information Sciences (2016), –. [6] Ronald L. Breiger, The Duality of Persons and Gr oups , Social F orces 53 (1974) , no. 2, 181–190. [7] Guido Caldarelli, Andrea Cap occi, P aolo De Los Ri os, and Miguel A Munoz, Sc ale-fr ee networks fr om varying v e rtex intrinsic fitness , Physical review l etter s 8 9 (2002) , no. 25, 258702. [8] V.R. Carv alho and W.W. Cohen, Single-p ass online le arning: Performanc e, voting schemes and online fe atur e sele cti on , Pro c. of the 12th acm sigkdd, 2006, pp. 548–553. [9] Nicolo Cesa-Bianc hi, Alex C onconi, and Claudio Gen tile, On the g ener alization ability of on-line le arning algorithms , IEEE T ransactions on Information Theory 50 (2004), no. 9, 2050–2057. [10] Nicolo Cesa-Bianc hi and Gábor Lugosi, Pr e diction, le arning, and games , Cambridge universit y press, 2006. [11] J. Chang an d D.M. Bl ei, R elational topic mo dels for do cument networks , In tern ational conference on artificial in telligence and statistics, 2009, pp. 81–88. [12] Michel Chein and Marie-Laure Mugnier, Gr aph-b ase d know le dge r epr esentation: c omputationa l founda- tions of c onc eptual gr aphs , Springer Science & Business Media, 2008. [13] K. Crammer, O. Dekel, J. Keshet, S. Shalev-Shw artz, and Y. Singer, Online p assive-aggr essive algo- rithms , J. Mac h. Learn. Res. 7 (2006), 551–585. [14] Nello Cristianini and John Shaw e-T aylor, An intr o duction to supp ort ve ctor machines and other kernel- b ase d le arning metho ds , Cam bridge unive rsit y press, 2000. [15] Nilesh Dalvi and Dan Suciu, Efficient query evaluation on pr ob abilistic data b ases , The V LD B Journal 16 (2007), no. 4, 523–544. [16] Jesse Da vis and Mark Goadric h, The r elationship b etwe en pr e cision-r e ca l l and r o c curves , Pro ceedings of the 23rd in ternat ional conference on mac hine learning, 2006, pp. 233–240. [17] Janardhan Rao Doppa, Jun Y u, Prasad T adepalli, and Lise Getoor, L ea rning algorithms for link pr e- diction b ase d on chanc e c onstr aints , Joint european conference on mac hine l earning and knowledge disco v ery in databases, 2010, pp. 344–360. [18] B Ev erett , An intr o duction to latent variable mo dels , Springer Science & Business Media, 2013. [19] C. Gen tile, A new appr oximate maximal mar gin classific ati on algorithm , J. M ac h. Learn. Res. 2 (2002) , 213–242. [20] Charles J. Geyer and Minnesota Uni v. (Minneapoli s Sch ool Of Statistics), Markov Chain Monte Carlo Maximum Li keliho o d. , Defense T ec hnical Information Cen ter, 1992. [21] Neil Zhenqiang Gong, W enchang Xu, Ling Huang, Prateek Mittal, Emil Stefano v, V yas Sek ar, and Da wn Song, Evolution of so cial-a ttribute net works: me asur ements, mo deling, and imp lic ations using go o gle+ , Proceedings of the 2012 acm conferenc e on int ernet measuremen t conference, 2012, pp. 131–144. [22] Leo A Goo dman, Explor atory latent structur e analysis using b oth identifiable and unidentifiable mo dels , Biometrik a 61 (1974), no. 2, 215–231. [23] Thomas L. Griffiths and Zoubin Ghahramani, Infinite latent fe atur e mo dels and the indian buffet pr o c ess , Adv ances in neural information processing systems, 2005, pp. 475–482. [24] Mark H al l , Eib e F rank, Ge offrey Holmes, Bernhard Pf ahringer, Peter Reutemann, and Ian H Witten, The weka data mining softwar e: an up date , ACM SI GKDD explorat ions newsletter 11 (2009), no. 1, 10–18. [25] K. Henderson and T. Eliassi- Rad, Applying latent dirichlet al lo ca tion to g ro up disc overy in lar ge gr aphs , Proc. 2009 acm symposi um on applied computing, 2009 , pp. 1456–1461. [26] Neil W Henry, L atent structur e analysis , Encyclopedia of statistical sciences (1983) . [27] N. Hens, N. Goeyv aerts, M . A erts, Z. Shk edy, P . V an Damme, and P . Beute ls, Mining so cial mixing p atterns for infectious dise ase mo dels b ase d on a two-day p opulation survey in b elgium , BMC Infectious Diseases 9 (2009 ), no. 1, 5. [28] John Hertz, Anders Krogh, and Richar d G Palmer , Intr o duction to the the ory of neur al c omputation , V ol. 1, Basic Books, 1991. [29] P .D. H off, Multiplic ative latent factor mo dels for description and pr e diction of so cial networks. , Com- putational and Mathematical Organization Theory 15 (2009), no. 4, 261–272. [30] Jak e M Hofman and Chris H Wiggins, Bayesian appr o ach t o network mo dularity , Physical review letters 100 (2008) , no. 25, 258701. [31] Lorenzo Isella, Mariateresa Romano, Alain Barrat, Ciro Cattuto, Vi ttoria Colizza, W outer V an den Broeck, et al., Close enc ounters in a p e diatric war d: me asuring fac e-to-fac e pr oximity an d mixi ng p at- terns with we ar able sensors , Pl oS one 6 (2011 ), no. 2, e17144. 30 [32] N. Japk owicz and S. Stephen, The class imb alanc e pr oblem: A systematic st udy , Intelligen t data analysis 6 (2002) , no. 5, 429–449 . [33] Charles Kemp, Joshua B T enenbaum, Thomas L Griffiths, T akeshi Y amada, and Naonori Ueda, Le arning systems of c onc epts with an infinite r elational mo del , Aaai, 2006, pp. 5. [34] Arijit K han and Lei Chen, On unc ertain gr aphs mo deling and queries , Pro ceedings of the VLDB En- do wmen t 8 (2015), no. 12, 2042–2043 . [35] Myungh w an Kim and Jure Lesk o v ec, Mo deling so cial networks with no de attrib utes using the multiplic a- tive attribute gr aph mo del , arXiv preprin t arXiv:1106.5053 (2011). [36] , Multiplic ative att ri b ute gr aph mo del of r e al-wor ld networks , In ternet Mathematics 8 (2012), no. 1-2, 113–160. [37] , Nonp ar ametric multi-gr oup memb ership mo del f or dynamic ne tworks , Adv ances in neur al in- formation processing systems, 2013, pp. 1385– 1393. [38] Silvio Lattanzi and D. Siv akumar, Affiliation netwo rks , Proc. of the forty-first ann ual acm s ymposium on theory of computing, 2009, pp. 427–434. [39] Pau l F Lazarsfeld, L ate nt structur e analysis , Psych ology: A study of a science 3 (1959), 476–543. [40] Jure Lesk o v ec, Deepay an Chakrabarti, Jon Kleinberg, Christos F aloutsos, and Zoubin Ghahramani, Kr one cker gra phs: A n appr o ach to mo deling net works , Journa l of Machine Learning Researc h 11 (2010) , no. F eb, 985–1042. [41] Y. Liu, A. Niculescu-Mizil , and W. Gryc, T opic-link lda: joint mo dels o f topic and author c ommunity , Proc. 26th annual int ernationa l conference on machine learning, 2009, pp. 665–672. [42] Miller McPherson, Lynn Smith-Lovin, and James M Co ok, Bir ds of a fe ather: Homophily in so cial networks , Ann ual Review of Sociology 27 (2001), no. 1, 415–444. [43] F rank McSherry and Marc Na jork, Computing information r etriev al p erformanc e me asur es effic iently in the pr esenc e of t ie d sc or es , European conference on information retriev al, 2008, pp. 414–421. [44] Edwa rd Meeds, Zoubin Ghahramani, Radford M Neal, and Sam T Row eis, Mo deling dyad ic data with binary latent f actors , A dv ances in neural information processing systems, 2006, pp. 977–984. [45] Jörg Menche , A mitabh Sharma, M aksim Kitsak, Susan Di na Ghiassian, Marc Vidal, Joseph Loscalzo, and Alb ert-László Barabási, Unc overing dise ase-dise ase r elationships thr ough the inc omplete inter actome , Science 347 (2015) , no. 6224, 1257601 . [46] Adit ya Krishna Menon and Charles Elk an, Link pr e diction vi a matrix factorization , Joint european conferenc e on mac hine learning and kno wledge discov ery i n databa ses, 2011, pp. 437–452. [47] K.T. Mill er, T. L. Griffiths, and M. I. Jordan, Nonp ar ametric latent fe atur e mo dels for link pr e diction. , In nips, 2009, pp. 1276–1284 . [48] Corrado Monti, A. Roz za, G. Zapp ella, M . Zi gnani, A. Arvidsson, an d E. Colleoni, Mo del ling p olitic al disaffe ction fr om twitt er data , Pro c. of the 2nd int. wisdom, 2013, pp. 3. [49] J. Mossong, N . Hens, M. Jit, et al., So cial c ontacts and mixing p atterns r elevant to the spr e ad of infe ctious dise ases , PLoS Med 5 ( 2008), no. 3, e74. [50] Krzysztof Nowic ki and T om A B Snijders, Estimation and pr e diction for sto chastic blo ckstructur es , Journal of the American Statistical Association 96 ( 2001), no. 455, 1077–1087. [51] Joseph J Pfeiffer II I, Sebastian More no, Timothy La F ond, Jen nifer Neville, an d Brian Gallagher , At- tribute d gr aph mo dels: Mo deling network structur e with c orr elate d attributes , Pro ceedings of the 23rd int ernational conferenc e on world wide web , 2014, pp. 831–842. [52] Michalis Potamias, F rancesc o Bonc hi, Aristides Gionis, and George Kollios, K-ne ar est nei ghb ors in un - c ertain gr aphs , Proceedings of the VLDB Endo wmen t 3 (2010), no. 1-2, 997–1008. [53] F rank Rosen blatt, The p er c eptr on: a pr ob abilistic mo del for information stor age and or ganization in the br ain. , Psychological review 65 (1958), no. 6, 386. [54] , Principles of neur o dynamics. p er ceptr ons and the the ory of br ain me chanisms , DTIC Do cumen t, 1961. [55] Stuart Russell and P eter Norvig, Artificial intel ligenc e: A mo dern appr o ach. 2010 , Prent ice Hall, 2010. [56] D Sculley, Online active lea rning metho ds for fast lab el-efficie nt sp am filtering. , Ceas, 2007, pp. 143. [57] Arnab Sinha, Zhihong Shen, Y ang Song, H ao Ma, Darrin Eide, Bo-june P aul Hsu, and Kuansan W ang, An overvie w of micr osoft ac ademic servic e (mas) and applic ati ons , Pro ceedings of the 24th i nternat ional conferenc e on wo rld wide web, 2015, pp. 243–246. [58] T om A.B. Snijders and K rzysztof No wick i, Estimation and pr ed iction for sto chastic blo ckmo dels for gr aphs with latent blo ck structur e , Journal of Classification 14 (1997), no. 1, 75–100. 31 [59] Samu el A Stouffe r, Louis Guttman, Edward A Suchman , P aul F Lazarsfeld, Shirley A Star, and John A Clausen, Me asur ement and pr ed iction. (1950). [60] Lloyd N T refethen and David Bau II I, Numeric al line ar algebr a , V ol. 50, Siam, 1997. [61] Ho Chung W u, Robert Wing P ong Luk, Kam F ai W ong, and Kui Lam K wo k, Interpr eting tf-idf te rm weights a s making r elevanc e de c isions , ACM T ransactions on Information Syste ms (TOIS) 2 6 (2008 ), no. 3, 13. [62] Zhao Xu, V olk er T resp, K ai Y u, and Hans-Peter Kriegel, L e arning infinite hidden r elational mo dels , Uncertainit y in Artificial Intelligence (UAI200 6) (2006). [63] Y ang Y ang, Ryan N Lich tenw alter, and Nitesh V Chawla, Evaluating link pr e diction metho ds , Knowledge and Information Systems 45 (2015) , no. 3, 751–782 . 32
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment