Correlated Equilibria for Approximate Variational Inference in MRFs
Almost all of the work in graphical models for game theory has mirrored previous work in probabilistic graphical models. Our work considers the opposite direction: Taking advantage of recent advances in equilibrium computation for probabilistic infer…
Authors: Luis E. Ortiz, Boshen Wang, Ze Gong
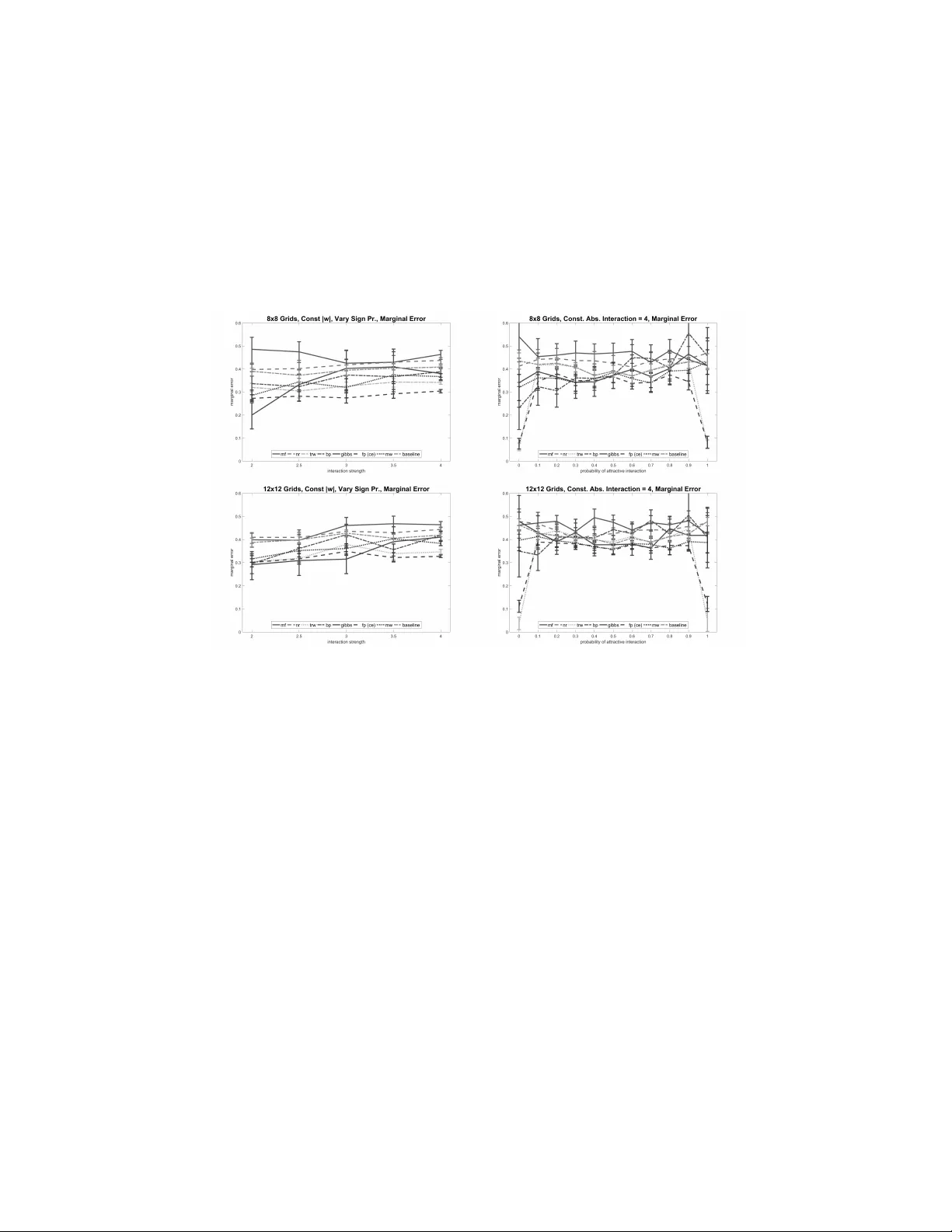
Correlated Equilibria for Appro ximate V ariational Inference in MRFs Luis E. Ortiz, Boshen W ang Departmen t of Computer & Information Science Univ ersity of Mic higan - Dearb orn { leortiz,boshenw } @umich.edu Ze Gong Sc ho ol of Computing, Informatics & Decision Systems Engineering Arizona State Univ ersity Ze.Gong@asu.edu Octob er 10, 2017 Abstract Almost all of the w ork in graphical mo dels for game theory has mir- rored previous w ork in probabilistic graphical models. Our w ork considers the opposite direction: T aking adv antage of recent adv ances in equilib- rium computation for probabilistic inference. In particular, we presen t form ulations of inference problems in Mark ov random fields (MRFs) as computation of equilibria in a certain class of game-theoretic graphical mo dels. While some previous work explores this direction, none of that w ork concretely establishes the precise connection b etw een v ariational probabilistic inference in MRFs and correlated equilibria. There is no w ork that exploits recent theoretical and empirical results from the lit- erature on algorithmic and computational game theory on the tractable, p olynomial-time computation of exact or approximate correlated equilib- ria in graphical games with arbitrary , loopy graph structure. Our work discusses how to design new algorithms with equally tractable guarantees for the computation of approximate v ariational inference in MRFs. In ad- dition, inspired b y a previously stated game-theoretic view of state-of-the- art tree-reweig hed (TR W) message-passing techniques for b elief inference as zero-sum game, we prop ose a differen t, general-sum p oten tial game to design approximate fictitious-play tec hniques. W e perform syn thetic ex- p erimen ts ev aluating our proposed approximation algorithms with stan- dard metho ds and TR W on several classes of classical Ising mo dels (i.e., with binary random v ariables). W e also ev aluate the algorithms using Ising mo dels learned from the MNIST dataset. Our exp eriments sho w that our global approac h is comp etitiv e, particularly shinning in a class of Ising mo dels with constant, “highly attractive” edge-weigh ts, in which 1 it is often b etter than all other alternatives we ev aluated. With a notable exception, our more lo cal approach was not as effective as our global ap- proac h or TR W. Y et, in fairness, almost all of the alternativ es are often no b etter than a simple baseline: estimate the marginal probability to b e 0 . 5. 1 In tro duction Almost all of the work in graphical games has b orrow ed heavily from analogies to probabilistic graphical mo dels. Y et, ov er-reliance on those analogies and previous standard approaches to exact inference migh t ha v e led that approac h to face the same computational roadblo c ks that plagued most exact-inference tec hniques. As an example of w ork that heavily exploits previous w ork in probablistic graphical mo dels (PGMs), Kak ade et al. [2003] designed p olynomial-time algo- rithms based on linear programming for computing c orr elate d e quilibria (CE) in standard graphical games with tree graphs. The approach and p olynomial-time results extend to graphical games with bounded-tree-width graphs and graph- ical p olymatrix games with tree graphs. Exact inference is tractable in PGMs whose graphs ha v e b ounded treewidth, but intractable in general [Coop er, 1990, Shimon y, 1994, Istrail, 2000]. In 2005, Papadimitriou and Roughgarden show ed the intractabilit y of computing the “so cial-welfare” optim um CE in arbitrary graphical games (see also Papadimitriou and Roughgarden [2008]). Everything seemed to point tow ard an ev entual resignation that the approach of Kak ade et al. [2003], along with any other approach to the problem for that matter, had hit the “b ounded-treewidth-threshold wall.” Y et, so on after, Papadimitriou [2005] to ok a radically different approach to the problem, and surprised the communit y with an efficient algorithm for computing CE not only in graphical games, but also in almost all known com- pactly represen table games. Jiang and Leyton-Brown [2015a] built up on Pa- padimitriou’s idea to provide what most p eople would consider an improv ed p olynomial-time algorithm, b ecause of the simplification of the CE that their algorithm outputs (see also Jiang and Leyton-Brown, 2011, for a summary). 1 An immediate question that arises from the algorithmic results just described is, what is so fundamentally different b et ween the problem of exact inference in graphical mo dels and equilibrium computation that made this result p ossible in the context of graphical games? Of course, CE, probabilistic inference, and their v arian ts are different problems, ev en within the same framew ork of graphical mo dels. The question is, ho w different are they? It is w ell-known that pur e str ate gy Nash e quilibrium (PSNE) is inherently a classical/standard discrete c onstr aints satisfaction pr oblem (CSP) . It is also 1 Papadimitriou’s work has an interesting history , which Jiang and Leyton-Brown [2015a] nicely summarize. Some questions arose at the time about the technical soundness in the description of some steps in Papadimitriou’s algorithm. Jiang and Leyton-Brown [2015a] provided clarifications to those steps. 2 w ell-known that an y CSP can b e cast as a most-likely , or equiv alen tly , a max- imum a p osteriori (MAP) assignment estimation problem in Markov r andom fields (MRFs) . 2 Through this connection, it is clear that there exists a MAP form ulation of PSNE. But what ab out other, more general forms of equilibria? W e present here a formulation of the problem of equilibrium computation as a kind of lo cal conditions for different approximations to b elief inference. Simi- larly , we sho w how one can view some sp ecial games, called gr aphic al p otential games [Ortiz, 2015], as defining an e quivalent MRF whose “lo cally optimal” so- lutions corresp ond to arbitr ary equilibria of the game. Hence, P apadimitriou’s result, and later that of Jiang and Leyton-Bro wn, op en up the p ossibilit y that at least new classes of problems in probabilistic graphical models could be solved exactly and efficiently . The question is, which classes? While w e provide sp ecific connections b et ween the tw o fields that yield im- mediate theoretical and computational implications, w e also provide practical alternativ es that result from those connections. That is, the foundation of b oth Papadimitriou’s and Jiang and Leyton-Brown’s algorithms is the el lip- soid metho d , which is one approac h that leads to the p olynomial-time algorithm for linear programming. This approach, while prov ably efficient in theory , is often seen as less practical as other alternatives such as so-called interior-p oint metho ds . This is in contrast to the simple linear programs that are p ossible for certain classes of graphical games [Kak ade et al., 2003]. Are there simpler and practically effectiv e v ariants of Papadimitriou’s or Jiang and Leyton-Bro wn’s algorithms? While the last question is an imp ortant open question, we do not address it directly in this pap er. Instead, W e emplo y ideas from the literature of learning in games [F udenberg and Levine, 1999], particularly no-regret algo- rithms and fictitious play , to propose t wo sp ecific instances of game-theoretic inspired, practical, and effectiv e heuristics for b elief inference in MRFs. One heuristic tak es a lo cal approach, and the other takes a global approac h. W e ev aluate our prop osed algorithms within the context of the most p opular, stan- dard, and state-of-art tec hniques from the literature in probabilistic graphical mo dels. This manuscript describ es our work, which starts to address some of the questions ab ov e, and rep orts on our progress. 1.1 Ov erview of the Paper Section 2 pro vides preliminary material, in tro ducing basic notation, terminol- ogy , and concepts from graphical models and game theory . Section 3 is the main technical section of the pap er. It shows reductions of differen t problems in b elief inference in MRFs as computing equilibria in graph- ical p oten tial games compactly represented as Gibbs p otential games [Ortiz, 2015]. The reductions presen ted here v ary in generality from MAP assignment, mar ginals, and ful l-joint estimation to pur e-str ate gy Nash e quilibria (PSNE), mixe d-str ate gy Nash e quilibria (MSNE), and c orr elate d e quilibria (CE) , resp ec- 2 Assuming a solution exists, of course; otherwise the resulting MRF is not well-defined. 3 tiv ely . W e briefly discuss a connection betw een P apadimitriou’s algorithm, as w ell as Jiang and Leyton-Brown’s, and the w ork of Jaakk ola and Jordan [1997] on v ariational approximations to the problem of probabilistic inference in MRFs via mean-field mixtures. The paper also includes a discussion on the connec- tions to previous work in computer vision on the problem of relaxation lab eling, and w ork on game-theoretic approac hes to (Bay esian) statistical estimation. W e then presen t an alternative approach based on a more global view of the prob- lem, in con trast to the more lo cal approach of the formulations mentioned abov e. More sp ecifically , we formulate the inference problem using a tw o-pla yer p oten- tial game, inspired by the w ork on tr e e r eweighe d (TR W) message-p assing [W ain- wrigh t et al., 2005]. W e prop ose a sp ecial type of sequen tial, “hybrid” standard and sto chastic fictitious play algorithm for b elief inference. Section 4 rep orts on our exp erimen tal ev aluation. W e compare our pro- p osed algorithms to the p opular, most commonly used, standard, and easily implemen table approximation tec hniques in use to day . Section 5 discusses future work and suggests new opp ortunities for other p o- ten tial research directions, beyond those already discussed in the main technical sections of the pap er. Section 6 concludes the pap er with a summary of our contributions. 2 Preliminaries This section introduces basic notation and concepts in graphical mo dels and game theory used throughout the pap er. It also includes brief statemen ts on curren t state-of-the-art mathematical and computational results in the area. Basic Notation. Denote by x ≡ ( x 1 , x 2 , . . . , x n ) an n -dimensional vector and b y x − i ≡ ( x 1 , . . . , x i − 1 , x i +1 , . . . , x n ) the same v ector without comp onen t i . Similarly , for every set S ⊂ [ n ] ≡ { 1 , . . . , n } , denote by x S ≡ ( x i : i ∈ S ) the (sub-)v ector formed from x using only comp onents in S , suc h that, letting S c ≡ [ n ] − S denote the complemen t of S , we can denote x ≡ ( x S , x S c ) ≡ ( x i , x − i ) for every i . If A 1 , . . . , A n are sets, denote by A ≡ × i ∈ [ n ] A i , A − i ≡ × j ∈ [ n ] −{ i } A j and A S ≡ × j ∈ S A j . Graph T erminology and Notation. Let G = ( V , E ) b e an undirected graph, with finite set of n vertic es or no des V = { 1 , . . . , n } and a set of (undi- rected) edges E . F or eac h no de i , let N ( i ) ≡ { j | ( i, j ) ∈ E } b e the set of neigh b ors of i in G , not including i , and N ( i ) ≡ N ( i ) ∪ { i } the set including i . A clique C of G is a set of no des with the prop erty that they are all mutually connected: for all i, j ∈ C , ( i, j ) ∈ E ; in addition, C is maximal if there is no other no de k outside C that is also connected to each no de in C , i.e., for all k ∈ V − C , ( k , i ) / ∈ E for some i ∈ C . Another useful concept in the context of this paper is that of hypergraphs, whic h are generalizations of regular graphs. A hyp er gr aph gr aph G = ( V , E ) is defined b y a set of nodes V and a set of hyp er e dges E ⊂ 2 V . W e can think of 4 the h yp eredges as cliques in a regular graph. Indeed, the primal gr aph of the h yp ergraph is the graph induced b y the no de set V and where there is an edge b et w een tw o no des if they both b elong to the same hyperedge; in other words, the primal graph is the graph induced by taking eac h h yp eredge and forming cliques of no des in a regular graph. 2.1 Probabilistic Graphical Mo dels Probabilistic graphical mo dels are an elegant marriage of probability and graph theory that has had tremendous impact in the theory and practice of modern artificial in telligence, machine learning, and statistics. It has permitted effective mo deling of large, structured high-dimensional complex systems found in the real world. The language of probabilistic graphical mo dels allows us to capture the structure of complex interactions b et ween individual entities in the system within a single mo del. The core comp onen t of the mo del is a graph in which each no de i corresp onds to a random v ariable X i and the edges express conditional indep endence assumptions ab out those random v ariables in the probabilistic system. 2.1.1 Mark ov Random Fields, Gibbs Distributions, and the Hammersley-Clifford Theorem By definition, a join t probability distribution P is a Markov r andom field (MRF) with resp ect to (wrt) an undirected graph G if for all x , for every no de i , P ( X i = x i | X − i = x − i ) = P ( X i = x i | X N ( i ) = x N ( i ) ) . In that case, the neigh b ors/v ariables X N ( i ) form the Markov blanket of no de/v ariable X i . Also by definition, a joint distribution P is a Gibbs distribution wrt an undirected graph G if it can b e expressed as P ( X = x ) = Q C ∈C Φ C ( x C ) for some functions Φ C indexed b y a clique C ∈ C , the set of all (maximal) cliques in G , and mapping every p ossible v alue x C that the random v ariables X c asso ciated with the no des in C can take to a non-negative num b er. W e sa y that a join t probabilit y distribution P is p ositive if it has full supp ort (i.e., P ( x ) > 0 for all x ). 3 Theorem 1. (Hammersley-Clifford [Hammersley and Clifford, 1971]) L et P b e a p ositive joint pr ob ability distribution. Then, P is an MRF with r esp e ct to G if and only if P is a Gibbs distribution with r esp e ct to G . In the con text of the theorem, the functions Φ C are positive, which allo ws us to define MRFs in terms of lo c al p otential functions { φ C } ov er each clique C in the graph. Define the function Ψ( x ) ≡ P C ∈C φ C ( x C ). Let us refer to any function of this form as a Gibbs p otential with resp ect to G . A more familiar expression of an MRF is P ( X = x ) ∝ exp( P C ∈C φ C ( x C )) = exp(Ψ( x )) . 3 The positivity constrain t is only necessary for the “only if ” case pro of of the theorem. 5 2.1.2 Some Inference-Related Problems in MRFs One problem of interest in an MRF is to compute a most likely assignment x ∗ ∈ arg max x P ( X = x ) = arg max x P C ∈C φ C ( x C )); that is, the most lik ely outcome with resp ect to the MRF P . Another problem is to compute the in- dividual mar ginal pr ob abilities P ( X i = x i ) = P x − i P ( X i = x i , X − i = x − i ) ∝ P x − i exp( P C ∈C φ C ( x C ))) for eac h v ariable X i . A related problem is to com- pute the normalizing constant Z = P x exp( P C ∈C φ C ( x C ))) (also known as the p artition function of the MRF). Another set of problems concern so called “b elief up dating.” That is, com- puting information related to the p osterior pr ob ability distribution P 0 ha ving observ ed the outcome of some of the v ariables, also known as the evidenc e . F or MRFs, this problem is computationally equiv alent to that of computing prior marginal probabilities. 2.1.3 Brief Ov erview of Computational Results in Probabilistic Graphical Models Both the exact and appro ximate versions of most inference-related problems in MRFs are in general in tractable (e.g., NP-hard), although polynomial-time algorithms do exists for some sp ecial cases (see, e.g., Dagum and Lub y, 1993, Roth, 1996, Istrail, 2000, W ang et al., 2013, and the references therein). The complexit y of exact algorithms is usually characterized by structural prop erties of the graph, and the typical statemen t is that running times are p olynomial only for graphs with b ounded treewidth (see, e.g., Russell and Norvig, 2003 for more information). Sev eral deterministic and randomized appro ximation approac hes exist (see, e.g., Jordan et al., 1999, Jaakk ola, 2000, Geman and Ge- man, 1984). An approximation approac h of particular in terest in this pap er is variational infer enc e [Jordan et al., 1999, Jaakkola, 2000]. Roughly speak- ing, the general idea is to approximate an in tractable MRF P by a “closest” probabilit y distribution Q ∗ within a “computationally tractable” class Q : for- mally , Q ∗ ∈ arg max Q ∈Q KL( Q k P ), where KL( Q k P ) ≡ P x Q ( x ) ln Q ( x ) P ( x ) is the Kul lb ack-L eibler (KL) diver genc e b et ween probabilit y distributions P and Q wrt Q . The simplest example in the so called me an-field (MF) appr oxi- mation , in whic h Q = { Q | Q ( x ) = Q i Q ( x i ) for all x ∈ Ω } consists of all p ossible pr o duct distributions. Ev en if P is an IM, no closed-form solution exists for its mean-field approximation, and the most common computational sc heme is based on simple axis parallel optimizations, leading to individual lo- cal conditions of optimality and p oten tial lo cal minima: that is, the problem is essen tially reduced to finding Q ∗ ( x ) = Q i Q ∗ i ( x i ) such that for all i , w e ha ve Q ∗ i ∈ arg max Q i P x i Q i ( x i ) P x − i h Q j 6 = i Q ∗ j ( x j ) i Ψ( x i , x − i ) + H Q i ( X i ), where H ( Q i ) ≡ H Q i ( X i ) ≡ − P x i Q i ( x i ) ln Q i ( x i ) is the (Shannon) en tropy of ran- dom v ariable X i ∼ Q i . 6 2.2 Game Theory Game theory [von Neumann and Morgenstern, 1947] provides a mathematical mo del of the stable b eha vior (or outcome) that may result from the in teraction of rational individuals. This pap er concen trates on nonc o op er ative settings: in- dividuals maximize their own utility , act indep endently , and do not ha ve (direct) con trol ov er the b eha vior of others. 4 The concept of e quilibrium is cen tral to game theory . Roughly , an equilib- rium in a nonco op erativ e game is a point of strategic stance, where no individual pla yer can gain by unilater al ly deviating from the equilibrium b eha vior. 2.2.1 Games and their Representation Let V = [ n ] denote a finite set of n play ers in a game. F or eac h play er i ∈ V , let A i denote the set of actions or pur e str ate gies that i can play . Let A ≡ × i ∈ V A i denote the set of joint actions , x ≡ ( x i , . . . , x n ) ∈ A denote a join t action, and x i the individual action of play er i in x . Denote b y x − i ≡ ( x 1 , . . . , x i − 1 , x i +1 , . . . , x n ) the joint action of all the play ers exc ept i , such that x ≡ ( x i , x − i ). Let M i : A → R denote the p ayoff/utility function of play er i . If the A i ’s are finite, then M i is called the p ayoff matrix of play er i . Games represen ted this w ay are called normal- or str ate gic-form games . There are a v ariety of compact represen tations for large games inspired b y probabilistic graphical mo dels in AI and machine learning [La Mura, 2000, Kearns et al., 2001, Koller and Milch, 2003, Leyton-Brown and T ennenholtz, 2003, Jiang and Leyton-Bro wn, 2008]. The results of this paper are presented in the context of the following generalization of gr aphic al games [Kearns et al., 2001], a simple but pow erful model inspired by probabilistic graphical mo dels suc h as MRFs previously defined b y Ortiz [2014]. 5 Definition 1. A gr aphic al multi-hyp ermatrix game (GMhG) is defined by • a dir e cte d graph G = ( V , E ) in which there is a no de i ∈ V in G for eac h of the n play ers in the game (i.e., | V | = n ), and the set of directed edges, or arcs, E defines a set of neighb ors N ( i ) ≡ { j | ( j, i ) ∈ E , i 6 = j } whose action affect the pa y off function of i (i.e., j is a neighbor of i if and only if there is an arc from j to i ); and • for eac h play er i ∈ V , – a set of actions A i , 4 Individual rationality here means that each play er seeks to maximize their own utility . Also note that, while many parlor “win-lose”/zero-sum games in volv e comp etition, in general, nonc o op er ative 6 = c omp etitive : eac h pla yer just wan ts to do the b est for himself, regardless of how useful or harmful his b eha vior is to others. 5 Connections ha ve already b een established b et ween the different kinds of compact repre- sentations [Jiang and Leyton-Brown, 2008], which may facilitate extensions of ideas, frame- works, and results to those alternative mo dels. 7 – a h yp ergraph where the vertex set is its (inclusive) neighb orho o d N ( i ) ≡ N ( i ) ∪ { i } and the hyperedge set is a set of cliques of play ers C i ⊂ 2 N ( i ) , and – a set { M 0 i,C : A C → R | C ∈ C i } of lo c al-clique p ayoff (hyp er)matric es . The interpretation of a GMhG is that, for eac h pla yer i , the lo c al and glob al p ayoff (hyp er)matric es M 0 i : A N ( i ) → R and M i : A → R of i are (implicitly) defined as M 0 i ( x N ( i ) ) ≡ P C ∈C i M 0 i,C ( x C ) and M i ( x ) ≡ M 0 i ( x N ( i ) ), resp ectively . Graphical p oten tial games. Graphical p oten tial games are sp ecial instances of GMhGs. They pla y a key role in establishing a stronger connection b et ween probabilistic inference in MRFs and equilibria in games than previously noted. Ortiz [2015] provides a c haracterization of graphical p oten tial games, and dis- cusses the implication of con vergence of certain kinds of “playing” pro cesses in games based on connections to the Gibbs sampler [Geman and Geman, 1984], via the Hammersley-Clifford Theorem [Hammersley and Clifford, 1971, Besag, 1974]. Y u and Bertho d [1995] (implicitly) used graphical p oten tial games to establish an equiv alence b et w een lo c al maxim um- a-p osteriori (MAP) inference in Mark ov random fields and Nash equilibria of the game, a topic revisited in Section 3.1. 6 2.2.2 Equilibria as Solution Concepts Equilibria are generally considered the solutions of games. V arious notions of equilibria exist. A pur e str ate gy (Nash) e quilibrium (PSNE) of a game is a join t action x ∗ suc h that for all play ers i , and for all actions x i , M i ( x ∗ i , x ∗ − i ) ≥ M i ( x i , x ∗ − i ) . That is, no play er can impro ve its pay off b y unilater al ly deviating from its prescrib ed equilibrium x ∗ i , assuming the others stic k to their actions x ∗ − i . Some games, such as the extensively-studied Prisoner’s Dilemma, hav e PSNE; many others, such as “pla yground” Ro ck-P aper-Scissors, do not. This is problematic b ecause it will not be possible to “solv e” some games using PSNE. A mixe d-str ate gy of play er i is a probability distribution Q i o ver A i suc h that Q ( x i ) is the probabilit y that i chooses to play action x i . 7 A joint mixe d- str ate gy is a joint probabilit y distribution Q capturing the play ers b ehavior, suc h that Q ( x ) is the probabilit y that join t action x is play ed, or in other w ords, each play er i plays action in comp onen t x i of x . Because we are assum- ing that the pla yers play indep endently , Q is a pro duct distribution: Q ( x ) = Q i Q i ( x i ). Denote by Q − i ( x − i ) ≡ Q j 6 = i Q j ( x j ) the joint mixed strategies of all the pla yers except i . The exp e cte d p ayoff of a play er i when some joint mixed- strategy Q is play ed is P x Q ( x ) M i ( x ); abusing notation, denote it by M i ( Q ). 6 In the in terest of brevit y , please see Ortiz [2014] for a thorough discussion of GMhGs, including their compact representation size and connections to other classical classes of games in game theory . 7 Note that the sets of mixed strategies contain pure strategies, as we can alw ays recov er playing a pure strategy exclusively . 8 The c onditional exp e cte d p ayoff of a play er i given that he plays action x i is P x − i Q − i ( x − i ) M i ( x i , x − i ); abusing notation again, denote it by M i ( x i , Q − i ). A mixe d-str ate gy Nash e quilibrium (MSNE) is a joint mixed-strategy Q ∗ that is a pro duct distribution formed by the individual pla y ers mixed s trategies Q ∗ i suc h that, for all play ers i , and an y other alternativ e mixed strategy Q 0 i for his pla y , M i ( Q ∗ i , Q ∗ − i ) ≥ M i ( Q 0 i , Q ∗ − i ) . Every game in normal-form has at least one suc h equilibrium [Nash, 1951]. Thus, ev ery game has an MSNE “solution.” One relaxation of MSNE considers the case where the amount of gain each pla yer can obtain from unilateral deviation is v ery small. This concept is par- ticularly useful to study approximation versions of the computational prob- lem. Given ≥ 0, an (appr oximate) -Nash e quilibrium (MSNE) is defined as ab o ve, except that the exp ected gain condition b ecomes M i ( Q ∗ i , Q ∗ − i ) ≥ M i ( Q 0 i , Q ∗ − i ) − . Sev eral refinements and generalizations of MSNE hav e b een prop osed. One of the most in teresting generalizations is that of a c orr elate d e quilibrium (CE) [Aumann, 1974]. In contrast to MSNE, a CE can b e a full joint distribution, and thus characterize more complex joint-action b eha vior by play ers. F ormally , a c orr elate d e quilibrium (CE) is a join t probability distribution Q ov er A suc h that, for all pla yers i , x i , x 0 i ∈ A i , x i 6 = x 0 i , and Q ( x i ) > 0, X x − i Q ( x − i | x i ) M i ( x i , x − i ) ≥ X x − i Q ( x − i | x i ) M i ( x 0 i , x − i ) , where Q ( x i ) ≡ P x − i Q ( x i , x − i ) is the (marginal) probabilit y that pla y er i will pla y x i according to Q and Q ( x − i | x i ) ≡ Q ( x i , x − i ) / P x 0 i Q ( x 0 i , x − i ) is the con- ditional given x i . An MSNE is CE that is a pro duct distribution. An equiv- alen t expression of the CE condition ab o ve is P x − i Q ( x i , x − i ) M i ( x i , x − i ) ≥ P x − i Q ( x i , x − i ) M i ( x 0 i , x − i ) . As w as the case for MSNE, w e can relax the con- dition of deviation to accoun t for potential gains from small deviation. Given > 0, adding the term “ − ” to the righ t-hand-side of the condition ab o ve defines an (appr oximate) -CE . 8 CE hav e several conceptual and computational adv antages ov er MSNE. F or instance, all play ers ma y achiev e better exp ected pay offs in a CE than those ac hiev able in any MSNE; 9 some “natural” forms of play are guaranteed to con verge to the ( set of ) CE [F oster and V ohra, 1997, 1999, F uden berg and Levine, 1999, Hart and Mas-Colell, 2000, 2003, 2005]; and CE is consistent with a Bay esian framew ork [Aumann, 1987], something not yet p ossible, and apparen tly unlikely for MSNE [Hart and Mansour, 2007]. 2.2.3 Brief Ov erview of Results in Computational Game Theory There has been an explosion of computational results on different equilibrium concepts on a v ariety of game representations and settings since the b eginning 8 Note that approximate CE is usually defined based on this unconditional version of the CE conditions [Hart and Mas-Colell, 2000]. 9 The distinction b et ween installing a traffic light at an intersection and leaving the inter- section without one is a real-world example of this. 9 of this century . The following is a brief summary . W e refer the reader to a b ook b y Nisan et al. [2007] for a (partial) introduction to this research area. The problem for t wo-pla y er zer o-sum games, where the sum of the en tries of b oth matrix is zero, and therefore only one matrix is needed to represent the game, can b e solved in p olynomial time: It is equiv alen t to linear program- ming [von Neumann and Morgenstern, 1947, Sz´ ep and F orgo´ o, 1985, Karlin, 1959]. After b eing op en for o ver 50 y ears, the problems of the complexity of computing MSNE in games w as finally settled recen tly , following a very rapid sequence of results in the last part of 2005 [Goldb erg and P apadimitriou, 2005, Dask alakis et al., 2005, Dask alakis and P apadimitriou, 2005, Dask alakis et al., 2009b, Chen and Deng, 2005b]: Computing MSNE is likely to be hard in the w orst case, i.e., PP AD-complete [P apadimitriou, 1994], even in games with only t wo play ers [Chen and Deng, 2005a, 2006, Chen et al., 2009, Dask alakis et al., 2009a,b]. The result of F abrik ant et al. [2004] suggests that computing PSNE in succinctly representable games is also likely to b e intractable in the worst case, i.e., PLS-complete [Johnson et al., 1988]. A common statement is that computing MSNE, and in some cases ev en PSNE, with “sp ecial prop erties” is hard in the w orst case [Gilb oa and Zemel, 1989, Gottlob et al., 2003, Conitzer and Sandholm, 2008]. Computing approximate MSNE is also thought to b e hard in the worst case [Chen et al., 2006, 2009]. W e refer the reader to Ortiz and Irfan [2017], and the references therein, for recent results along this line and a brief surv ey of the state-of-the-art for this problem. Most current results for computing exact and approximate PSNE or MSNE in graphical games essentially mirror those for MRFs and constraint netw orks: p olynomial time for b ounded treewidth graph; intractable in general [Kearns et al., 2001, Gottlob et al., 2003, Dask alakis and Papadimitriou, 2006, Ortiz, 2014]. This is unsurprising b ecause they were mostly inspired by analogous v ersions in probabilistic graphical mo dels and constrain t net works in AI, and therefore share similar c haracteristics. Several heuristics exist for dealing with general graphs [Vic krey and Koller, 2002, Ortiz and Kearns, 2003, Dask alakis and Papadimitriou, 2006]. In contrast, there exist p olynomial-time algorithms for computing CE, b oth for normal-form games (where the problem reduces to a simple linear feasibility problem) and ev en most succinctly-representable games kno wn today [P apadim- itriou, 2005, Jiang and Leyton-Brown, 2015a], including graphical games. 3 Equilibria and Inference The line of work presen ted in this section is partly motiv ated b y the follo wing question: Can we lever age advanc es in c omputational game the ory for pr oblems in the pr ob abilistic gr aphic al mo dels c ommunity? Establishing a strong bilateral connection b etw een b oth problems may help us answer this question. The literature on computing equilibria in games has skyro ck eted since the b eginning of this century . As w e disco ver techniques dev elop ed early on within the game theory communit y , and as new results are generated from the ex- 10 tremely activ e computational game theory communit y , we ma y b e able to adapt those techniques for solving games to the inference setting. If we can establish a strong bilateral connection betw een inference problems and the computation of equilibria, w e ma y b e able to relate algorithms in b oth areas and exchange previously unknown results in eac h. 3.1 Pure-Strategy Nash Equilibrium and Appro ximate MAP Inference Consider an MRF P with resp ect to graph G and Gibbs potential Ψ defined b y the set of p oten tial functions { φ C } . F or each no de i , denote by C i ⊂ C the subset of cliques in G that include i . Note that the (inclusive) neighborho o d of pla yer i is given by N ( i ) = ∪ C ∈C i C . Define an MRF-induc e d GMhG, and more sp ecifically , a (hyperedge-symmetric) h yp ergraphical game [P apadimitriou, 2005, Ortiz, 2015], with the same graph G , and for eac h play er i , hypergraph with hyperedges C i and lo cal-clique pay off h yp ermatrices M 0 i,C ( x C ) ≡ φ C ( x C ) for all C ∈ C i . A few observ ations about the game are in order. Prop ert y 1. The r epr esentation size of the MRF-induc e d game is th e same as that of the MRF: not exp onential in the lar gest neighb orho o d size, but the size of the lar gest clique in G . Prop ert y 2. The MRF-induc e d game is a gr aphic al p otential game [Ortiz, 2015] with gr aph G and (Gibbs) p otential function Ψ : i.e., for al l i , x and x 0 i , M i ( x i , x − i ) − M i ( x 0 i , x − i ) = M 0 i ( x i , x N ( i ) ) − M 0 i ( x 0 i , x N ( i ) ) = X C ∈C i φ C ( x i , x C −{ i } ) − X C ∈C i φ C ( x 0 i , x C −{ i } ) = X C ∈C i φ C ( x i , x C −{ i } ) + X C 0 ∈C −C i φ C 0 ( x C 0 )+ − X C ∈C i φ C ( x 0 i , x C −{ i } ) − X C 0 ∈C −C i φ C 0 ( x C 0 ) =Ψ( x i , x − i ) − Ψ( x 0 i , x − i ) . R emark 1 . Through the connection established by the last prop ert y , it is easy to see that se quential b est-resp onse dynamics is guaranteed to conv erge to a PSNE of the game in finite time, regardless of the initial play . 10 In fact, we can conclude that a joint-action x ∗ is a PSNE of the game if and only if x ∗ is a 10 Recall that b est-r esp onse dynamics refers to the a process where at each time step, each play er observes the action x − i of others and takes an action that maximizes its pay off given that the others play ed x − i . In this case, those dynamics would essentially b e implementing an axis-parallel co ordinate maximization ov er the space of assignments for the MRF, which is guaran teed to conv erge to a lo cal maxima (or critical p oin ts) of the MRF. 11 lo cal maxima or a critical p oin t of the MRF P . Th us, the MRF-induced game, lik e al l p otential games [Monderer and Shapley, 1996b], alwa ys has PSNE. 11 Similarly , for any potential game, one can define a game-induc e d MRF using the p oten tial function of the game whose set of lo cal maxima (and critical p oin ts) corresp onds exactly to the set of PSNE of the p otential game. Through this connection w e can show that solving the lo cal-MAP problem in MRFs is PLS- complete in general [F abrik ant et al., 2004]. 12 One question that comes to mind is whether one can say an ything ab out the prop erties of the globally optimal assignmen t in the game-induced MRF and the pa yoff it supp orts for the play ers. Or whether it can be characterized by stronger notions of equilibria. F or example, are str ong NE , in whic h no c o alition of play ers could obtain a Pareto dominated set of pa yoffs by unilaterally deviating, joint MAP assignments of the MFR? Or more generally , what characteristics can we assign to the MAP assignments of the game-induced MRF? In short, w e can use algorithms for PSNE as heuristics to compute lo cally optimal MAP assignments of P and vic e versa . 13 R emark 2 . Dask alakis et al. [2007] extended results in game theory characteriz- ing the num b er of PSNE in normal-form games (see Stanford, 1995, Rinott and Scarsini, 2000, and the references therein) to graphical games, but now taking in to consideration the net work structure of the game. Information ab out the n umber of PSNE in games can provide additional insight on the structure of MRFs. F or example, one of the results of Dask alakis et al. [2007] states that for graphs resp ecting certain expansion prop erties as the num b er of nodes/play ers increases, the num b er of PSNE of the graphical game will ha v e a limiting dis- tribution that is a Poisson with exp ected v alue 1. Also according to Dask alakis et al. [2007], a similar b eha vior o ccurs for games with graphs generated ac- cording to the Erd¨ os-R ´ enyi mo del with sufficiently high a verage-degree (i.e., reasonably high connectivity). Th us, either the set of MRF-induced games has significan tly low measure relative to the set of all p ossible randomly generated games (something that seems likely), or the num b er of lo cal maxima (and crit- ical p oin ts) of the MRF will hav e a similar distribution, and th us that num b er 11 This result should not be surprising giv en that other researchers ha ve established a one-to- one relationship b etw een the complexit y class PLS [Johnson et al., 1988], which characterizes local search problems, of which finding lo cal maxima of the MRF is an instance, and (ordinal) potential games [F abrik ant et al., 2004]. 12 A direct pro of of this result follows from Papadimitriou et al. [1990], and in particular, the result for Hopfield neural networks [Hopfield, 1982]. A Hopfield neural net work can b e seen as an MRF, and more sp ecifically , and Ising mo del, when the weigh ts on the edges are symmetric. Similarly , any Hopfield neural netw ork can b e seen as a p olymatrix game [Miller and Zuc ker, 1992]; when the weigh ts are symmetric the network can be seen as a p otential game (in particular, it is an instance of a p arty affiliation game [F abrik ant et al., 2004]). Indeed, a stable configuration in an arbitrary Hopfield neural netw ork is equiv alent to a PSNE of a corresponding p olymatrix game. (See Papadimitriou et al., 1990, and Miller and Zuck er, 1992, for the relev ant references.) 13 Note that algorithms for PSNE can in principle find critical p oin ts of P . In either case, algorithms such as the max-pro duct version of b elief propagation (BP) can only provide such local-optimum/critical-point con vergence guaran tees in general. 12 is expected to be low. The latter w ould suggest that local algorithms suc h as the max-pro duct algorithm may b e less likely to get stuck in lo cal maxima (or critical p oints) of the MRF. In addition, there hav e been several results stating that PSNE are unlik ely to exist in many graphs, and that, when they do exist, they are not that man y [Dask alakis et al., 2007]. 14 MRF-induced games would in that sense represen t a very ric h class of non-r andomly gener ate d graphical games for which the results ab o ve do not hold. 3.2 Mixed-strategy Equilibria and Belief Inference Going b ey ond PSNE and MAP estimation, this subsection b egins to establish a stronger, and p oten tially more useful connection betw een probabilistic inference and more general concepts of equilibria in games. Let S b e a subset of the play ers (i.e., no des in the graph) and denote by Q S ( x S ) ≡ P x V − S Q ( x ) the (marginal) probability distribution of Q ov er p ossi- ble joint actions of play ers in S . Consider the condition for correlated equilibria (CE), which for the MRF-induced game w e can express as, for all i, x i , x 0 i 6 = x i , X x N ( i ) Q N ( i ) ( x i , x N ( i ) ) X C ∈C i φ C ( x i , x C −{ i } ) ≥ X x N ( i ) Q N ( i ) ( x i , x N ( i ) ) X C ∈C i φ C ( x 0 i , x C −{ i } ) . Comm uting the sums and simplifying w e get the following equiv alent condition: X C ∈C i X x C −{ i } Q ( x i , x C −{ i } ) φ C ( x i , x C −{ i } ) ≥ X C ∈C i X x C −{ i } Q ( x i , x C −{ i } ) φ C ( x 0 i , x C −{ i } ) . (1) This simplification is imp ortan t b ecause it highlights that, mo dulo exp ected pa yoff equiv alence, w e only need distributions ov er the original cliques, not the induced neighboho o ds/Mark o v blank ets, to represent CE in this class of games, in contrast to Kak ade et al. [2003]; thus, we are able to maintain the size of the represen tation of the CE to b e the same as that of the game. As an alternative, w e can use the fact that the MRF-induced game is a p oten tial game and, via some definitions and algebraic manipulation, get the follo wing sequence of equiv alent conditions, which hold for all i , x i and x 0 i . P x − i Q ( x i , x − i ) ( M i ( x i , x − i ) − M i ( x 0 i , x − i )) ≥ 0 P x − i Q ( x i , x − i ) (Ψ( x i , x − i ) − Ψ( x 0 i , x − i )) ≥ 0 P x − i Q ( x i , x − i ) (ln P ( x i , x − i ) − ln P ( x 0 i , x − i )) ≥ 0 14 In particular, the n umber of PSNE has a Poisson distribution with parameter 1. 13 Rewriting the last expression, we get the following equiv alent condition: for all i , x i and x 0 i , X x − i Q ( x i , x − i )[ − ln P ( x i , x − i )] ≤ P x − i Q ( x i , x − i )[ − ln P ( x 0 i , x − i )] . (2) The following are some additional remarks on the implications of the last condition. 15 R emark 3 . First, it is useful to in tro duce the following notation. F or an y dis- tribution Q 0 , let H ( Q 0 , P ) ≡ P x Q 0 ( x )[ − log 2 P ( x )] b e the cr oss entr opy b e- t ween probability distributions Q 0 and P , with resp ect to P . 16 Denote by Q − i ( x − i ) ≡ P x i Q ( x i , x − i ) the marginal distribution of play ov er the joint- actions of all play ers exc ept play er i . Denote by Q 0 i Q − i the joint distribution defined as ( Q 0 i Q − i )( x ) ≡ Q 0 i ( x i ) Q − i ( x − i ) for all x . Then, condition 2 implies the follo wing sequence of conditions, which hold for all i . X x Q ( x )[ − ln P ( x )] ≤ X x − i Q − i ( x − i )[ − ln P ( x 0 i , x − i )] for all x 0 i H ( Q, P ) ≤ min x 0 i X x − i Q − i ( x − i )[ − log 2 P ( x 0 i , x − i )] = min Q 0 i X x Q 0 i ( x i ) Q − i ( x − i )[ − log 2 P ( x i , x − i )] = min Q 0 i H ( Q 0 i Q − i , P ) As anon ymous review er pointed out, the condition is actually that of a c o arse CE (CCE) [Hannan, 1957, Moulin and Vial, 1978], whic h is a superset of CE and allows us to apply several simple metho ds for computing such equilibrium concept, as discussed later in this section. Hence, any CE of the MRF-induc e d game is a kind of appr oximate lo c al optimum (or critic al p oint) of an appr oxi- mation of the MRF b ase d on a sp e cial typ e of cr oss entr opy minimization. The following prop ert y summarizes this remark. Prop ert y 3. F or any MRF P , any c orr elate d e quilibria Q of the game induc e d by P satisfies H ( Q, P ) ≤ min i min Q 0 i H ( Q 0 i Q − i , P ) . R emark 4 . Let us in tro duce some additional notation. F or an y joint distribution of pla y Q 0 , let H ( Q 0 ) ≡ P x Q 0 ( x )[ − log 2 Q 0 ( x )] be its entrop y . Similarly , for an y pla yer i , for any marginal/individual distribution of play Q 0 i , let H ( Q 0 i ) ≡ P x i Q 0 i ( x i )[ − log 2 Q 0 i ( x i )] b e its (marginal) entrop y . F or any distribution Q 0 15 In what follows, we refer to concepts from information theory in the discussion, such as (Shannon’s) entrop y , cross entrop y , and relative entrop y (also known as Kullback-Leibler divergence). W e refer the reader to Cov er and Thomas [2006] for a textbo ok introduction to those concepts. 16 That is, (a low er b ound on) the av erage num b er of bits required to transmit ”mes- sages/even ts” generated according to Q but enco ded using a scheme based on P . 14 and P , let KL( Q 0 k P ) ≡ P x Q 0 ( x ) log 2 ( Q 0 ( x ) /P ( x )) = H ( Q 0 , P ) − H ( Q 0 ) be the Kul lb ack-L eibler diver genc e betw een Q 0 and P , with resp ect to Q 0 . Denote b y H ( Q i |− i ) ≡ P x i ,x − i Q ( x i , x − i ) log 2 ( Q ( x i , x − i ) /Q − i ( x i )) = H ( Q − i ) − H ( Q ) the conditional entrop y of the individual play of pla yer i giv en the join t play of all the play ers except i , with respect to Q . Then, w e can express the condition 2 as the following equiv alent conditions, whic h hold for all i . KL( Q k P ) + H ( Q ) ≤ min Q 0 i KL( Q 0 i Q − i k P ) + H ( Q 0 i Q − i ) KL( Q k P ) + H ( Q i |− i ) ≤ min Q 0 i KL( Q 0 i Q − i k P ) + H ( Q 0 i ) Hence, any CE of a MRF-induc e d game is a kind of appr oximate lo c al optimum (or critic al p oint) of a sp e cial kind of variational appr oximation of the MRF. The following prop ert y summarizes this remark. Prop ert y 4. F or any MRF P , any c orr elate d e quilibria Q of the game induc e d by P satisfies KL( Q k P ) ≤ min i min Q 0 i KL( Q 0 i Q − i k P ) + H ( Q 0 i ) − H ( Q i |− i ) . Note that the last prop erty implies that the appro ximation Q satisfies the lo cal condition KL( Q k P ) ≤ min i min Q 0 i KL( Q 0 i Q − i k P ) + log 2 | Ω i | . Before contin uing exploring connections to CE, it is instructive to first con- sider MSNE. 3.2.1 Mixed-strategy Nash Equilibria and Mean-Field Appro ximations In the sp ecial case of MSNE, the join t mixed strategy Q ( x ) = Q i Q i ( x i ) is a pro duct distribution. Denote b y Q × − i ( x − i ) ≡ Q j 6 = i Q j ( x j ) = P x i Q ( x ) the (marginal) joint action of play ov er all the pla yers except i , and denote by ( Q 0 i Q × − i ) the probabilit y distribution defined such that the probabilit y of x is ( Q 0 i Q × − i )( x ) ≡ Q 0 i ( x i ) Q × − i ( x − i ). In this special case, the equilibrium conditions imply the following condi- tions, which hold for all i : for all x i suc h that Q i ( x i ) > 0, X x − i Q i ( x i ) Q × − i ( x − i )[ − ln P ( x i , x − i )] = min x 0 i X x − i Q i ( x i ) Q × − i ( x − i )[ − ln P ( x 0 i , x − i )] . Denoting by X + i ≡ { x i ∈ A i | Q i ( x i ) > 0 } , the last condition implies that X x i ∈X + i X x − i Q i ( x i ) Q × − i ( x − i )[ − ln P ( x i , x − i )] = X x i ∈X + i Q i ( x i ) min x 0 i X x − i Q × − i ( x − i )[ − ln P ( x 0 i , x − i )] . 15 The last condition is equiv alent to X x i X x − i Q i ( x i ) Q × − i ( x − i )[ − ln P ( x i , x − i )] = min x 0 i X x − i Q × − i ( x − i )[ − ln P ( x 0 i , x − i )] , whic h, in turn, we can express as H ( Q, P ) = min Q 0 i H ( Q 0 Q × , P ) . The last expression is also equiv alent to KL( Q k P ) + H ( Q i ) = min Q 0 i KL( Q 0 i Q × − i k P ) + H ( Q 0 i ) . Hence, a NE Q of the game is almost a lo c al ly optimal me an-field appr oximation, exc ept for the extr a entr opic term. In summary , for MSNE we hav e the follo wing tigh ter condition than for arbitrary CE. Prop ert y 5. F or any MRF P , any MSNE Q of the game induc e d by P satisfies KL( Q k P ) = min Q 0 i KL( Q 0 i Q × − i k P ) + H ( Q 0 i ) − H ( Q i ) , for al l i . Note that the last prop ert y implies that the mean-field approximation Q satisfies the lo cal condition KL( Q k P ) ≤ min Q 0 i KL( Q 0 i Q × − i k P ) + log 2 | Ω i | for all i . One p ossible wa y to address the issue of the extra en tropic term is to consider instead the MRF-induc e d infinite game , where each play er i has the (contin uous) utilit y function 17 f M 0 i ( Q i , Q N ( i ) ) ≡ X x i X x N ( i ) Q i ( x i ) Y j ∈N ( i ) Q j ( x j ) M 0 i ( x i , x N ( i ) ) + H ( Q i ) and w ants to maximize o ver its mixed-strategy Q i giv en the other play er mixed- strategies Q j for all j 6 = i . Prop ert y 6. The MRF-induc e d infinite game define d ab ove is an infinite Gibbs p otential game with the same gr aph G and the fol lowing p otential over the set of individual (pr o duct) mixe d str ate gies Ψ( Q ) = X C ∈C X x C Y j ∈ C Q j ( x j ) φ C ( x C ) + H ( Q ) = − K L ( Q k P ) + Z 17 In an infinite game the sets of actions or pure strategies are uncountable. Existence of equilibria holds under reasonable conditions (i.e., each set of actions is a nonempty compact conv ex subset of Euclidean space, and each play er utility is contin uous and quasi-concav e in the play er’s action), all of which are satisfied by the MRF-induced infinite game considered here. (See F udenberg and Tirole, 1991, for more information.) 16 wher e Z is the normalizing c onstant for P . F r om this we c an derive that the individual player mixe d-str ate gies { Q i } ar e a “pur e str ate gy” e quilibrium of the infinite game if and only if KL( Q k P ) = min Q 0 i KL( Q 0 i Q × − i k P ) . Or, in other words, if Q is a PSNE of the infinite game, then Q is also a lo c al optimum (or critic al p oint) of the me an-field appr oximation of P . R emark 5 . The lo cal pay off function defined abov e for the infinite game also has connections to the game theory literature on le arning in games [F udenberg and Levine, 1999]. This area studies prop erties of pro cesses b y which pla yers “learn” ho w to pla y in (usually rep eated) games; especially prop erties related to the existence of con vergence of the learning (or playing) dynamics to equilibria. In particular, the local pa yoff function is similar to that used by lo gistic fictitious play , a sp ecial version of a “learning” pro cess called smo oth fictitious play . The difference is that the last entrop y term inv olving the individual pla yer’s mixed strategy has a regularization-type factor λ > 0 such that play ers play strict b est-response as λ → 0. In addition, logistic fictitious pla y is an instance of a learning pro cess that, if follo wed b y a pla yer, achiev es so called appro ximate universal c onsistency (i.e., roughly , in the limit of infinite pla y , the av erage of the pay offs obtained b y the pla yer will b e close to the b est obtained ov erall during rep eated play , r e gar d less of how the other players b ehave ), also known as Hannan c onsistency [Hannan, 1957], for appropriate v alues of λ depending on the desired approximation level. Indeed, it is not hard to see that in fact the b est-resp onse mixed-strategy Q i of play er i to the mixed strategies Q N ( i ) of their neighbors is Q i ( x i ) ∝ exp P x N ( i ) h Q j ∈N ( i ) Q j ( x j ) i M 0 i ( x i , x N ( i ) ) = exp X C ∈C i ,C 6 = { i } Y j ∈ C −{ i } Q j ( x j ) φ C ( x i , x C −{ i } ) . Hence, running se quential b est-resp onse dynamics in the MRF-induced infinite game is equiv alent to finding a v ariational mean-field approximation via recur- siv e up dating of the first deriv ative conditions. 18 The pro cess will then b e equiv alent to minimizing the function F ( Q ) ≡ KL( Q k P ) by axis-parallel up- dates. The resulting sequence of distributions/mixed-strategies monotonically decreases the v alue of F and is guaran teed to con v erge to a local optim um or a critical p oin t of F . Hence, the corresponding learning process is guaran teed to conv erge to a PSNE of the infinite game, whic h is in turn an appr oximate MSNE of the original game. But this is not surprising in retrosp ect, given the last prop ert y (Prop ert y 6). That prop ert y essentially states a broader prop erty of al l p oten tial games: they are isomorphic to so called games with identic al 18 In particular, the pro cess is called a Cournot adjustment with lo ck-in in the literature on learning in games [F udenberg and Levine, 1999]. 17 inter ests [Monderer and Shapley, 1996b], whic h are games where every pla yer has exactly the same pa yoff function. R emark 6 . The previous discussion suggests that we could use appropriately- mo dified versions of algorithms for MSNE, such as NashProp [Ortiz and Kearns, 2003], as heuristics to obtain a mean-field approximation of the true marginals. Going in the opp osite direction, the discussion ab o v e also suggests that, by treating any (graphical) potential game as an MRF, for any fixed λ > 0, logistic fictitious pla y in any potential game con verges to an appro ximate ( λ/ min i | A i | )- MSNE of the potential game. Indeed, there has b een recen t w ork in this direc- tion, whic h explores the connection betw een learning in games and mean-field appro ximations in mac hine learning [Rezek et al., 2008]. That work prop oses new algorithms based on fictitious play for simple mean-field approximation applied to statistical (Ba yesian) estimation. The game-induced MRF is a λ -temp erature Gibbs measure. As we tak e λ → 0, w e get the limiting 0-temp erature Gibbs measure which is a probability distribution ov er the set of global maxima of the p otential function of the game, and 0 probability ev erywhere (i.e., the supp ort of the limiting distribution is the set of join t-actions that maximize the potential function). The supp ort of the 0-temp erature Gibbs measure is a subset of the “globally optimal” PSNE of the potential game. But there might b e other equilibria corresponding to lo cal optima (or critical p oin ts) of the p oten tial function. Are there other connections b et ween the Nash equilibria of the game and the supp ort of the limiting distribution? 3.2.2 Correlated Equilibria and Higher-order V ariational Appro ximations Kak ade et al. [2003] designed p olynomial-time algorithms based on linear pro- gramming for computing CE in standard graphical games with tree graphs. The approac h and p olynomial-time results extend to graphical games with b ounded- tree-width graphs and graphical polymatrix games with tree graphs. Ortiz et al. [2007] (see also Ortiz et al., 2006) proposed the principle of maxim um en tropy (MaxEn t) for equilibrium selection of CE in graphical games. They studied sev eral prop erties of the MaxEnt CE, designed a monotonically increasing algo- rithm to compute it, and discussed a learning-dynamics view of the algorithm. Kamisett y et al. [2011] employ ed adv ances in approximate inference metho ds to prop ose approximation algorithms to compute CE. In all of those cases, the general approac h is to use ideas from probabilistic graphical models to design algorithms to compute CE. The fo cus of this pap er is the opp osite direction: emplo ying ideas from game theory to design algorithms for b elief inference in probabilistic graphical mo dels. Prop ert y 4 suggests that we can use the CE for the MRF-induced game as a heuristic appro ximation to higher-order v ariational appro ximations. In fact, one w ould argue that in the context of inference, doing so is more desirable b ecause, in principle, it can lead to b etter approximations that can capture more asp ects of the joint distribution than a simple mean-field appro ximation would alone. 18 F or example, mean-field approximations are likely to b e p o or if the MRF is m ulti-mo dal. Motiv ated by this fact, Jaakkola and Jordan [1997] suggest using mixture of product distributions to impro ve the simple v ariational mean-field appro ximation. 3.2.3 Some Computational Implications But, consider the algorithms of P apadimitriou [2005] or Jiang and Leyton-Brown [2015a] (see also P apadimitriou and Roughgarden, 2008, and Jiang and Leyton- Bro wn, 2011), which we can use to compute a CE of the MRF-induced game in p olynomial time. Such CE will b e, by construction, also a (p olynomial ly-size d) mixtur e of pr o duct distributions . (In the case of Jiang and Leyton-Brown’s al- gorithm it will b e a mixture of a subset of the joint-action space, which is equiv alent to a probability mass function ov er a p olynomial ly-size d subset of the join t-action space; said differen tly , a mixture of product of indicator func- tions, each pro duct corresp onding to particular outcomes of the join t-action space.) Hence, the algorithms of Papadimitriou and Jiang and Leyton-Brown b oth provide a means to obtain a heuristic estimate of a lo cal optimum (or critical point) of such a mixture in p olynomial time. The result w ould not be exactly the same as that obtained by Jaakkola and Jordan [1997] in general, b ecause of the extra entropic term men tioned in the discussion earlier. Can we find alternative versions of the p ayoff matric es, and/or alter Pap adimitriou’s algorithm, so that the r esulting c orr elate d e quilibria pr ovides an exact answer to the appr oximate infer enc e pr oblem that uses mixtur es of pr o duct distributions? Regardless, at the very least one could use the resulting CE to initialize the tec hnique of Jaakk ola and Jordan [1997] without sp ecifying an a priori num b er of mixtures. Ha ving said that, both Papadimitriou’s and Jiang and Leyton-Bro wn’s al- gorithms make a p olynomial num b er of calls to the ellipsoid-algorithm, or more sp ecifically , its “oracle,” to obtain each of the pro duct distributions whose mixture will form the output CE. It is known that the ellipsoid algorithm is slo w in practice. P apadimitriou [2005], Papadimitriou and Roughgarden [2008], and Jiang and Leyton-Bro wn [2015a] leav e open the design of more practical algorithms based on in terior-p oin t metho ds. Finally , this connection also suggests that we can (in principle) use an y learning algorithm that guarantees conv ergence to the set of CE (as described in the section on preliminaries on game theory where the concept was in tro- duced) as a heuristic for approximate inference. Several so-called “no-regret” learning algorithms satisfy those conditions. Indeed, w e use tw o simple v ari- an ts of such algorithms in our exp erimen ts. View ed that wa y , suc h learning algorithms w ould b e similar in spirit to sto c hastic simulation algorithms with a kind of “adaptivity” reminiscent of the work on adaptive imp ortance sam- pling (see, e.g., Cheng and Druzdzel, 2000, Ortiz and Kaelbling, 2000, Ortiz, 2002, and the references therein). Establishing a p ossible stronger connection b et w een learning in games, CE, and probabilistic inference seems like a promis- ing direction for future researc h. In fact, as previously mentioned (at the end 19 of Remark 5), there has already b een some recent w ork in this direction, but sp ecifically for MSNE and mean-field appro ximations [Rezek et al., 2008]. Later in this pap er, w e present the results of an exp erimen tal ev aluation of the p erformance of a simple no-regret learning algorithm in computational game theory [F udenberg and Levine, 1999, Blum and Mansour, 2007, Hart and Mas-Colell, 2000] in the con text of probabilistic inference. Those are iterativ e al- gorithms lik e man y other approximate inference metho ds suc h as mean field and other v ariational appro ximations, but closer in spirit to sampling/sim ulation- based methods suc h as the Gibbs sampler and other similar MCMC metho ds. Indeed, the running time per iteration of those algorithms is roughly the same as that of sampling-based metho ds. W e delay the details until the Exp eriments section (Section 4). 3.3 Other Previous and Related W ork Earlier work on the so called “relaxation lab eling” problem in AI and computer vision [Rosenfeld et al., 1976, Miller and Zuc ker, 1991] has established connec- tions to p olymatrix games [Janovsk a ja, 1968] (see also Hummel and Zuck er, 1983, although the connection had y et to b e recognized at that time). That w ork also establishes connections to inference in Hopfield netw orks, dynamical systems, and polymatrix games [Miller and Zuc ker, 1991, Zuck er, 2001]. A re- duction of MAP to PSNE in what w e call here a GMhG w as in tro duced by Y u and Bertho d [1995] in the same context (see also Bertho d et al., 1996); although they concen trate on pairwise potentials, whic h reduce to polymatrix games in this con text. Because, in addition, the ultimate goal in MAP inference is to obtain a glob al optimum configuration, Y u and Bertho d [1995] prop osed a Metrop olis-Hastings-st yle algorithm in an attempt to av oid lo cal minima. Their algorithm is similar to sim ulated annealing algorithms used for solving satisfi- abilit y problems, and other lo cal metho ds such as W alkSA T [Selman et al., 1996] (see, e.g., Russell and Norvig, 2003 for more information). The algorithm can also b e seen as a kind of learning-in-games sc heme [F udenberg and Levine, 1999] based on b est-resp onse with random exploration (or “trembling hand” b est res ponse). That is, at every round, some b est-response is taken with some probabilit y , otherwise the previous resp onse is replay ed. Zuck er [2001] presents a mo dern accoun t of that work. The connection to p oten tial games, and all its w ell-known prop erties (e.g., conv ergence of best-resp onse dynamics) do es not seem to ha ve b een recognized within that literature. Also, none of the work mak es connections to higher-order (i.e., beyond mean-field) inference approxi- mation techniques or the game-theoretic notion of CE. 3.4 Appro ximate Fictitious Play in a Two-pla yer P oten tial Game for Belief Inference in Ising Mo dels This section presents a game-theoretic fictitious-play approach to estimation of no de-marginal probabilities in MRFs. The approach this time is more global in terms of ho w we use the whole join t-distribution for the estimation of individual 20 marginal probabilities. The inspiration for the approach presented here follo ws from the work of W ainwrigh t et al. [2005]. The section concentrates on Ising mo dels, an important, sp ecial MRF instance from statistical physics with its o wn interesting history . Definition 2. An Ising mo del wrt an undirected graph G = ( V , E ) is an MRF wrt G such that P θ ( x ) ∝ exp X i ∈ V b i x i + X ( i,j ) ∈ E w i,j x i x j where θ ≡ (, ¯ W ) is the set of node biases b i ’s and edge-weigh ts w ij ’s, which are the parameters defining the joint distribution P θ o ver {− 1 , +1 } n . It is fair to say that interest on more general classes of MRFs originates from the sp ecial class of Ising mo dels. It is also fair to say that, because of the relativ e s implicit y and imp ortance of Ising mo dels for problems in statistical ph ysics, as w ell as to other ML and AI applications areas such as computer vi- sion and NLP , Ising mo dels hav e b ecome the most common platforms in which to empirically study approximation algorithms for arbitrary MRFs. In short, simplicit y of presen tation and empirical ev aluation guide the fo cus of Ising mod- els in this section: Generalizations to arbitrary MRFs are straightforw ard but cum b ersome to present. Hence, in this manuscript, we omit the details of such generalizations. As an outline, the curren t section b egins with an algorithmic instan tiation of the iterative approach. The exact instantiation dep ends on whether w e are using CE or MSNE as the solution concept. The section then follo ws with an informal discussion of the game-theoretic foundations of the general framework b ehind the approach, and a discussion of immediate implications to computa- tional prop erties and p oten tial conv ergence. Denote b y T G the set of all spanning trees of connected (undirected) graph G = ( V , E ) that are maximal with resp ect to E (i.e., does not con tain any spanning forests). If spanning tree T ∈ T G , we denote by E ( T ) ⊂ E the set of edges of T . T o simplify the presentation of the algorithm, let f M T ( µ, T ) ≡ X ( i,j ) ∈ E 1 [( i, j ) ∈ E ( T )] w ij µ ( i,j ) and Ψ X, T ( x, T ) ≡ X i ∈ V b i x i + X ( i,j ) ∈ E 1 [( i, j ) ∈ E ( T )] w ij x i x j . Initialize x (1) ← Uniform( {− 1 , +1 } n ), and for eac h ( i, j ) ∈ E , b µ (1) ( i,j ) ← x (1) i x (1) j . At each iteration l = 1 , 2 , . . . , m, 1: T ( l ) ← arg max T ∈ T G f M T ( b µ ( l ) ( i,j ) , T ) 2: T ( l ) ← Uniform arg max T ∈ T G T ( l ) 21 3: s l ← Uniform( { 1 , . . . , l } ) 4: X ( l +1) ← arg max x ∈{− 1 , +1 } n Ψ X, T ( x, T ( s l ) ) 5: x ( l +1) ← Uniform X ( l +1) 6: for all ( i, j ) ∈ E do 7: v ( l +1) ( i,j ) ← x ( l +1) i x ( l +1) j × ( 1 , if MSNE, 1 ( i, j ) ∈ E ( T ( s l ) ) , if CE 8: b µ ( l +1) ( i,j ) ← l b µ ( l ) ( i,j ) + v ( l +1) ( i,j ) l +1 9: end for F or each Ising-mo del’s random-v ariable index i = 1 , . . . , n , set p ( m +1) i = 1 m + 1 m +1 X l =1 1 h x ( l ) i = 1 i as the estimate of the exact Ising-mo del’s marginal probabilit y p i ≡ P ( X i = 1). The running time of the algorithm is dominated by the computation of the maxim um spanning tree (Step 1) which is O ( | E | + n log n ). All other steps take O ( | E | ). Within the literature on probabilisitic graphical mo dels, Hamze and de F re- itas [2004] prop ose an MCMC approach based on sampling non-ov erlapping trees. While our approac h has a sampling fla vor, its exact connection to MCMC is unclear at b est. Also, the spanning trees that our algorithm generates ma y o verlap. The follo wing discussion connects the algorithm ab o ve to an approximate v ersion of fictitious play from the literature on learning in games in game theory . F or the most part, w e omit discussions to appro ximate v ariational inference in this man uscript, except to sa y that TR W message-passing [W ain wright et al., 2005] is the inspiration b ehind our prop osed algorithm ab o ve. The game implicit in the heuristic algorithm ab o ve is a tw o-play er p oten tial game b et ween a “joint-assignment” (JA) play er and a “sp anning-tr e e” (ST) pla yer. The p otential function is Ψ X, T ( x, T ) . The pay off functions M X and M T of the JA play er and the ST pla yer, respectively , are iden tical and equal the p oten tial function Ψ X, T ( x, T ): formally , M X ( x, T ) = M T ( x, T ) = Ψ X, T ( x, T ). Note that the pay off function of the ST pla yer is str ate gic al ly e quivalent to the function P ( i,j ) ∈ E 1 [( i, j ) ∈ E ( T )] w ij x i x j . T echnically , this is a game with identical pay offs, whic h are kno wn to hav e what Monderer and Shapley [1996a] called the fictitious play pr op erty : the em- pirical pla y of fictitious pla y is guaran teed to con verge to an MSNE of the game. While determining a b est-response for the ST pla yer is easy (i.e., using an al- gorithm for computing maximal spanning tree such as Krusk al’s, as we do in our implementation for the experiments), unfortunately the same is in general not possible for the JA play er, whose b est-resp onse is as hard as computing a MAP assignment of another Ising mo del with the same graph and (generally non-zero) biasno de parameters, but a sligh tly different set of edge-weigh ts. 19 19 As men tioned earlier, there are some instances for whic h this computation is actually 22 One approach to deal with the problem of obtaining a b est-response from the JA play er is to draw one tree uniformly at random from the empirical dis- tribution and find a b est-resp onse to that tree. Such an approach is equiv alent to a type of smo oth b est-response. If b oth play ers w ere to do the same, si- multane ously , the result is a sto c hastic version of fictitious play or sto chastic fictitious play for short [F udenberg and Levine, 1999]. The empirical distri- bution of play of sto c hastic fictitious play in a game with identical pay offs, or what’s strategically equiv alent, any p oten tial game, also con verges to an MSNE of the game [Hofbauer and Sandholm, 2002]. In our case, how ev er, we really ha ve a t yp e of “h ybrid” sequen tial-version, where the ST pla yer is alw ays be- ha ving as in standard fictitious play , while the JA pla yer is b eha ving according to a sto c hastic fictitious play . In addition, as an alternative to the b est-response computation for pla yer JA, w e might wan t to add an entropic (preference) function of the mixed-strategy to the JA play er as an additional term in JA’s pay off, so that the result is really a “smo oth” b est-response, or more specifically in this case a smo oth sto chastic fictitious play [F udenberg and Levine, 1999]. Such an addition w ould mak e the connection to v ariational inference more evident, and w ould allow us to dev elop more direct b ounds on the quality of the v ariational result. The main problem is that we do not know of an y study of such hybrids within game theory . In addition, most instances of fictitious play assume simultane ous mov es. Numerical instability is another problem w e found in practice when using suc h smo oth b est-resp onse. Even in instances where that was not a problem, the p erformance was indistinguishable, in a formal statistical sense, from the version of the algorithm that we prop ose ab ov e. In the con text of belief inference, w e b eliev e it actually makes more sense to hav e a so called “sequen tial” play , where pla yers trade mo ves: the JA play er starts by choosing some action (i.e., full, joint assignments to the random v ari- ables), the ST play er b est-responds to that action, then the JA pla yer b est- resp onds to the ST play er’s action, contin uing in that wa y , such that at eac h round, eac h pla yer is best-resp onding to the empiric al distribution of play 20 up to the time the play er makes a mo ve (i.e., draws an action). While this t yp e of sequential pro cess often helps to stabilize the dynamics and improv e the lik eliho o d of conv ergence, it seems that such sequen tial pro cesses hav e receiv ed considerably less attention than their simultaneous-mo ve counterpart within the game-theory communit y . W e conjecture, how ever, that the type of fictitious play pro cess defined abov e in fact conv erges. W e b eliev e that the pro of follows from combining results possible in polynomial time. In fact, this would ha ve been p ossible for the type of Ising models with planar tw o-dimensional grid graph, also known as a “square lattices,” w e used in the experiments, if we would ha ve c hosen those mo dels to ha ve zero biases, or the edge-weigh ts had some sp ecial characteristics. Unfortunately , there is no guarantee that the sp ecific Ising models randomly drawn w ould satisfy those conditions in general. As w e discuss shortly , we settle for a simple computation of the b est-response for the JA play er using sto c hastic fictitious pla y [F udenberg and Levine, 1999]. 20 In game theory , this is also known as the belief distribution of play each play er has about the others’ future mixed-strategy based on previously observed play . 23 from standard and sto c hastic fictitious play for games with iden tical pay offs, whic h are (strategically equiv alent) instances of p oten tial games [Monderer and Shapley, 1996a, Hofbauer and Sandholm, 2002]. The deriv ation is complex and not trivial, in volving key mathematical concepts from the literature in stochastic appro ximation. Delving into such level of complexit y not only go es b eyond the scop e of this pap er, but more imp ortan tly , doing so distracts attention from the pap er’s main fo cus: to pro vide a general, broad illustration of ho w ideas and results from game theory may be useful in providing alternativ e, effective, and practical approaches to hard b elief-inference problems in probabilistic graphical mo dels. Th us, we lea ve the formal pro of of our conjecture as future work. As a last p oin t, it is imp ortan t to understand and k eep in mind that, as it is w ell-known, in the context of potential games, while se quential b est-r eply con verges to a PSNE (i.e., a joint assignment), fictitious play can conv erge to an MSNE of the game. 21 Monderer and Shapley [1996a] provide an example in a 2-pla yer 2-action normal-form (co ordination) game with iden tical pa yoffs. Said differen tly , the resulting empirical distribution of play for the JA play er may b e to what Monderer and Shapley [1996a] themselv es call a “purely mixed strat- egy” (i.e, every action is pla yed with p ositiv e probability; or said differently , the corresp onding probabilit y mass function has full sup ort ov er the action set of the pla yer). 22 In the con text of belief inference, the resulting mixed-strategy w ould corresp ond to an (appro ximate) marginal distribution, not a particular join t-assignment. Hence, in the context of b elief inference, the conv ergence of the pro cedure abov e may not ha ve to b e to a single (p ossibly local) optimum of the p otential function Ψ X, T : in principle, con vergence could b e to a (non- deterministic) mixtur e ov er join t-assignments. In fact, this is what w e observ e in our exp eriments, alb eit after only a finite num b er of iterations. A thorough understanding of the con vergence prop erties observ ed in practice requires con- siderably more exp erimental w ork than is reasonable within the con text and purp ose of the work describ ed in this man uscript. 3.5 Sk etc h of algorithm deriv ation and relation to TR W The connection betw een TR W and the algorithm presen ted in this section re- sults from a sto chastic minimization of a precise upp er b ound on a v ariational appro ximation that uses a joint distribution (CE) or a pro duct distributions (MSNE) ov er the spanning trees of the MRF graph G = ( V , E ) and the original MRF’s random v ariables X . Here is a sk etch of the precise mathematical ex- pressions for the CE-based case. (The ones for the MSNE-case are very similar, and omitted for brevity .) While the deriv ation is more general, w e only present it in the con text of Ising mo dels. W e use the following notation for the purp ose of the discussion here. Let 21 Recall that in fictitious play , each play er uses the empiric al distribution of play as an estimate or belief of how the other play er would behav e in the future, not just the other play er’s last action as in sequential best-reply . 22 Other names used in game theory are total ly mixe d strate gy or mixe d str ate gy with ful l supp ort. 24 Q X, T b e the v ariational join t distribution o v er the random v ariables X and T corresp onding to join t v ariable assignments and spanning tree, resp ectiv ely . Let Q X b e the marginal probability of Q X, T o ver X : i.e., Q X ( x ) ≡ P T ∈ T G Q X, T ( x, T ), for all x ∈ {− 1 , +1 } . Let P X ≡ P θ b e the ground-truth join t distribution (defin- ing the Ising mo del) we w ould like to appro ximate. Denote by KL( Q X || P X ) ≡ X x Q X ( x ) ln Q X ( x ) P X ( x ) the KL-divergence of betw een Q X and P X with resp ect to Q X . Let b Q X, T the empiric al joint distribution of ”joint actions” for the b oth pla yers generated during fictitious play: i.e., b Q X, T ( x, T ) ≡ 1 m P m l =1 1 x ( l ) = x, T ( l ) = T . Let v ij ≡ E b Q X, T [ X i X j ] = P x b Q X ( x ) x i x j , where b Q X ( x ) ≡ P T ∈ T G b Q X, T ( x, T ) de- notes the empirical marginal o ver X only; that is, summed o ver all spanning trees T ov er G = ( V , E ) with resp ect to b Q , which is clearly easy to compute: b Q X ( x ) ≡ P T ∈ T G b Q X, T ( x, T ) for all x . Let u ij ≡ E Q ∗ X, T [ 1 [( i, j ) 6∈ T ] X i X j ] = P x,T Q ∗ X, T ( x, T ) 1 [( i, j ) 6∈ T ] x i x j . where Q ∗ X, T ∈ arg max Q X, T P x,T Q X, T ( x, T )Ψ( x, T ). Denote by H ( Q ∗ X ) ≡ − P x Q ∗ X ( x ) ln Q ∗ X ( x ) the standard ”Shannon’s entrop y” of X with resp ect to the marginal of Q ∗ X, T o ver X (i.e., Q ∗ X ( x ) = P T Q ∗ X, T ( x, T )); and similarly for H ( b Q X ). After some algebra, we can obtain the following b ound for the v ariational approximation: min Q X KL( Q X || P X ) ≤ − max Q X, T X x,T Q X, T ( x, T )Ψ( x, T )+ − X ( i,j ) ∈ E w ij u ij − H ( Q ∗ X ) + ln Z . The first term in the b ound, maximizing o ver Q X, T , inspires the application of fictitious play . As an aside, note that we can generate a family of upp er b ounds (details omitted); e,g,, for b Q X , min Q X KL( Q X || P X ) ≤ − X ( i,j ) ∈ E w ij v ij − H ( b Q X ) + ln Z . Note that H ( b Q X ) is easy to compute, and that the last expression leads imme- diately to an easily computable low er bound on ln Z . 4 Exp erimen ts In this section we present the results of synthetic exp erimen ts on the perfor- mance of the game-theoretic-inspired heuristics we prop ose in this pap er for 25 appro ximate b elief inference in MRFs. Our algorithms hav e very simple im- plemen tations. W e also compare them with the most p opular approximation algorithms and heuristics, with equally simple implemen tations, prop osed in the literature on probabilistic graphical mo dels. 4.1 Exp erimen tal Design: Syn thetic Mo dels The exp erimen tal design in terms of the class of Ising mo dels is as in Domke and Liu [2013]. W e consider Ising mo dels with d × d simple grid graphs, which are planar (i.e., no “wrap around” edges, such that eac h of the four corner no des hav e exactly t wo neighboring no des, any other non-in ternal no de has exactly three neigh b ors, while the rest, i.e., all in ternal no des, hav e exactly four neigh b ors). Hence, the n umber of v ariables or nodes is n = d 2 . W e used d ∈ { 8 , 12 } for our exp erimen ts. W e did not consider edge-weigh ts magnitude parameters 1 . 0 or 1 . 5, because it is really hard to b eat a Gibbs sampler for maxim um w eigh t magnitudes smaller than 2 . 0, relativ e to the bias parameters b i ’s b eing in the real-v alued in terv al [ − 1 , 1]. The reason for this might b e that, b ecause, as stated in Domke and Liu [2013], the mixing rate of a Gibbs sampler in suc h mo dels grows roughly exp onen tial with the magnitude, the induced Mark ov c hain mixes prett y fast for suc h cases; thus conv ergence is quic k. F or eac h v alue w ∈ { 2 . 0 , 2 . 5 , 3 . 0 , 3 . 5 , 4 . 0 } , we generated random Ising mo dels with edge-w eights w ij ∼ Uniform([ − w , w ]) or w ij ∼ Uniform([0 , w ]) for the “mixed” or “attractiv e” case, resp ectiv ely , for each ( i, j ) ∈ E , i.i.d., and no de biases b i ∼ Uniform([ − 1 , +1]), also i.i.d. for all i , and independent of the edge-w eights. One exception on the class of Ising mo dels used for ev aluation is a class we use with edge-weigh ts with constant magnitude (i.e., w = max ( i,j ) ∈ E | w ij | ), but in whic h we v ary the probability q of attractive edge-w eights; that is, given a probabilit y q , the sign of the edge-w eight are i.i.d. random v ariables in whic h the sign is p ositiv e with probability q , and negativ e with probabilit y 1 − q . 23 W e prop ose this class of Ising mo dels for future ev aluations of approximate b elief inference techniques. F or ev aluation using this class, w e consider w ∈ { 2 . 0 , 2 . 5 , 3 . 0 , 4 . 0 } . F or each q , we randomly generated 50 Ising mo dels as samples for w = 4, and 5 samples for eac h w 6 = 4. Note that despite the graphs b eing planar, the bias parameter is non-zero in general, so that the known p olynomial-time exact algorithms for planar graphs do not technically apply . Here, we consider simple no-r e gr et algorithms from the literature of learning in games [F udenberg and Levine, 1999, Blum and Mansour, 2007]. The tw o most common notions of regret are external and swap regret, the latter b eing stronger than the former. (Another name often used for external regret is “un- conditional regret,” while other names for swap regret are “internal regret” and “conditional regret.” W e refer the reader to the references to standard literature on learning in games for sp ecific definitions.) There are several such no-regret 23 The weight of each edge ( i, j ) ∈ E is a random v ariable of the form W ij = (2 S ij − 1) w , where the S ij ∼ Bernoulli( q ), i.i.d., and w is a p ositiv e constant. 26 algorithms in the literature with different types of con v ergence guaran tees de- p ending on the exact notion of regret used. Here we consider tw o types of no-regret algorithms, and leav e the ev aluation of other no-regret algorithms for future w ork. One type of algorithm we consider is really a class of algorithms based on the Multiplic ative Weight Up date (MWU) algorithm [Blum and Man- sour, 2007]. In our implementation of the MWU algorithm, for eac h play er i at eac h round t ≥ 1, w e set the probability of pla ying action x i at round t + 1, whic h we denote by x ( t +1) i , to be p t +1 ( x i ) ∝ p t ( x i ) 1 − η t (1 − ¯ M i ( x i , x ( t ) − i )) , where η t is analogous to a learning rate in ML (i.e., the step size when using standard gradien t descent/ascend for optimization), and ¯ M i is the normalized pa yoff function for pla yer i (i.e., the expression x i P ( i,j ) ∈ E w i,j x j + b i nor- malized so that minimum and maximum v alues are 0 and 1, resp ectively). In general, if we set the v alue of η t to a constant η we guaran tee that the em- pirical joint distribution o ver joint actions induced by the play ed sequence of join t actions x ( t ) con verges to the set of approximate CCE, where the level of the approximation dep end on η . If we set η t = q ln(2) t then we guarantee that con vergence to the set of CCE. 24 There is a simple construction that allows us to use the MWU algorithm to construct algorithms for which a play er can hav e either no swap regret, or approximately swap-regret, dep ending on the v alue of η t : if constan t ( η ) the empirical distribution of empirical play conv erges to the set of approximate CE, while if set as ab o ve conv ergence is guaran teed to the set of CE. 25 W e refer to the differen t v ersions of no-regret algorithms based on MWU related to conv ergence to exact or approximate CCE as “mw er” and “m w er cf,” resp ectively; and to those related to exact or approximate CE as “m w sr” and “mw sr cf,” resp ectiv ely . W e set η to 0 . 01 in all of our exp erimen ts. W e also ev aluate a simple (approximate) no-swap-regret algorithm b y Hart and Mas-Colell [2000], whic h we denote as “nr” from no w on. Li ke all (ap- pro ximate) no-swap-regret algorithms, nr guarantees to con verge to (the set of appro ximate) CE. Eac h iteration of nr takes roughly the same amount of time as that for Gibbs sampling. W e set the num b er of iterations of the nr algorithm to 10 5 for the standard experimental setup, and to 10 6 for our prop osed new ev aluation setting. Our exact implementation is a natural adaptation we b e- liev e is more amenable to the b elief-inference setting. In particular, we ev aluate a v ersion in which w e up date the mixed-strategy eac h pla yer uses to dra w an action at every iteration t as follows. F or each play er, (1) we set the probability of switc hing the pla yer’s last action being equal to the empirical regret, or 0 if the empirical regret is negativ e; and (2) we set the pla yer’s probability of pla ying action +1 by “damping” the currently suggested probabilit y of playing 24 The set of CCE is a superset of CE and is related to the concept of external regret. Indeed, conv ergence to the set of CCE implies that each player has no external regret, and we say that the empirical play of the play er is “Hannan consistent” [Hannan, 1957], or equiv alently , “universally consistent” [F udenberg and Levine, 1999]. 25 The set of CE is related to the concept of swap regret. Indeed, convergence to the set of CE implies that eac h play er has no swap regret. 27 +1, p t (1), for the corresp onding play er by the original algorithm: 26 that is, we use the update 0 . 99 × p t (1) + 0 . 01 × (0 . 5). W e also use 10 5 iterations. Also, w e only presen t results for the sequential, “semi-sto c hastic” fictitious pla y we discuss in Section 3.4, for the case of CE only , which we denote as “fp (ce)” from no w on. W e set the n umber of iterations m = 15. 27 Finally , the results for the MSNE-instan tiation of the fictitious play algorithm w e prop ose are quite similar to those for fp (ce), at least for m = 15; th us, w e omit those results in the interest of keeping the plots less “crowded” and thus easier to interpret. W e compare the different mw-t yp e algorithms, the simple nr algorithm, and our prop osed fp (ce) to (1) standard mean-field approximation (mf ), with se- quen tialaxis-parallel up dates; (2) standard b elief propagation (bp), with sim ul- taneous up dates; (3) TR W (trw); and (4) the Gibbs sampler (gs). The running times p er iteration of all metho ds is O ( | E | ), except that of fp (ce) which is O ( | E | + n log n ), and of course that of bl whic h is constant. In the next para- graph, w e pro vide more detail on the sp ecifics of the implemen tations of metho ds (1–4). As baseline (bl), we use the simplest p ossible estimator from the p ersp ectiv e of a verage marginal-error to measure quality: alwa ys use 0.5 as the estimate of the exact marginal distribution of eac h v ariable. Certainly , one w ould ex- p ect that for an algorithm to b e comp etitiv e, its p erformance should b e better than bl. As we so on discuss, our exp erimental results suggest that this is not alw ays the case; that is, several standard metho ds, including some of the ones prop osed here and ev en state-of-the-art such as TR W, do not satisfy that condi- tion for “hard” cases. W e ev aluate mean field (mf ) using sequentialaxis-parallel up dates, stopping if the maxim um absolute difference in probabilit y v alues b e- t ween iterations is ≤ 10 − 5 , and using a maxim um n umber of iterations = 10 6 . F or b elief propagation (bp) we use simultaneous up dates, and “smo oth” the up date based on the av erage of the current v alue and the new v alue in order to “damp en” or at least try to prev ent oscillations and impro ve the lik eliho o d of con vergence, 28 stopping if the maximum absolute difference in probability v al- ues b et ween iterations is ≤ 10 − 7 , and a maxim um n umber of iterations = 10 5 . F or tree rew eighed message-passing (trw), w e use a constan t parameter ρ = 0 . 55 for all corresp onding edge-app earance-probabilit y parameters ρ ij ’s [W ainwrigh t 26 The algorithm determines its suggested probability solely on the p ositiv ely-truncated empirical regret. 27 That num ber of iterations is relatively lo w, but given that our implemen tation is in MA T- LAB, setting m = 15 is roughly the num ber of iterations for which the amoun t is roughly the same as that for our C implementation of TR W, as describ ed in W ainwrigh t et al. [2005], but without optimizing for the parameters ρ ij ’s, which we set to a constant = 0 . 55 for all edges ( i, j ) ∈ E . Clearly this is an unfair comparison for fp (ce). The optimization of ρ ij ’s in volv es performing a maxim um spanning tree computation at each iteration until conv ergence, and this op eration follows each TR W message-passing with fixed ρ ij ’s. While such an optimiza- tion is tractable, and optimizing for the ρ ij ’s does seem to improv e the upp er-bounds on the log-partition function, it is not clear from the experimental results in W ainwrigh t et al. [2005] that the improv ement on the quality of the individual marginal estimates justify the extra work necessary for the optimization. 28 It is well known that bp may not converge in MRFs with lo op y graph, such as the Ising model with grid graph we are using here for our exp erimen ts. 28 et al., 2005], along with a smo oth up date and the same stopping criterion as for bp. F or the Gibbs sampler, w e use 10 6 iterations. 4.2 Exp erimen tal Results: Syn thetic Mo dels Fig. 1 summarizes our results for the most common classes of Ising mo dels con- sidered in the exp erimen tal ev aluation of approximation algorithms and heuris- tic for b elief inference in the literature as describ ed ab ov e. W e p erform hypoth- esis testing for the result in these classes of Ising mo dels using paired z-tests on the individual (i.e., not joint) differences, eac h with p-v alue 0 . 05. Hence, all the statemen ts are statistically significant with resp ect to suc h h yp othesis tests. Note that there is no globally b est appro ximation technique o verall for these classes. Finally , plots for b oth 8x8 and 12x12 mo dels are included to illus- trate ho w the relativ e p erformance of these appro ximation algorithms are not strongly affected b y the grid size d . F or brevity , we will only discuss results for the 12x12 case. W e refer the reader to App endix A for exp erimental results and discussion for the 8x8 case. Among all m w-type algorithms, we only present the results of m w er cf b e- cause it outp erforms all other t yp es almost consistently , as we discuss later in this section and plot in Fig. 5. Hence, w e refer to mw er cf simply as ’mw’ from no w on. “Mixed” 12x12 case (Bottom left plot, Fig. 1). Clearly , gs is b est for all w in this case. Among the other appro ximation algorithms, w e observ e the follo wing. 1. fp (ce) is worse than bp for w < 3 . 5, and indistinguishable from bp for w ≥ 3 . 5. 2. fp (ce) is consistently b etter than trw. 3. trw is consistently worse than bp. 4. mw is w orse than fp (ce) for w < 3 . 0, and indistinguishable from fp (ce) for w ≥ 3 . 0 5. All metho ds, except for mf and nr, are consistently better than bl. mf and nr are consistently worse than bl. 6. mf is b etter than nr for w ≥ 3 . 0, and indistinguishable from eac h other for w < 3 . 0. “A ttractive” 12x12 case (Bottom righ t plot, Fig. 1). In this case, there is no clear o verall b est. W e also observe the follo wing. 1. trw is b est among all methods for w ≥ 3 . 0, indistinguishable from gs for w = 2 . 5, and w orse than gs for w = 2 . 0. 29 2. fp (ce) is w orse than gs for w = 2 . 0, but b etter than gs for w = 4 . 0, and indistinguishable from gs otherwise. 3. mw and fp (ce) are consisten tly indistinguishable. 4. mf, nr, and bp are consistently indistinguishable from each other, except for w = 2 . 0, where bp is b etter than nr. 5. bp and bl are consistently indistinguishable, except for w = 4 . 0, where bp is b etter. Fig. 2 summarizes our exp erimental results for a class of Ising mo dels which app ears to lead to “harder” Ising-model instances. 29 W e p erform h yp othesis testing for the result in these classes of Ising mo dels using t wo approaches de- p ending on w . F or w = 4, where we draw 50 models as samples for each q , w e use appropriately mo dified paired z-tests on the individual (i.e., not join t) differences, each with p-v alue 0 . 05. W e mo dify the calculation of the v ariances resulting from the av erage ov er the samples computed for each q . W e do so b ecause the distributional prop erties of the empirical meanav erage for each q ma y differ. F or w < 4, where w e only dra w 5 mo dels as samples for eac h q , w e use b o otstrapped-based, individual, paired hypothesis-testing ov er each pair of aggregate differences b etw een the metho ds for each of those v alues of w ; we use 100 b o otstrap samples, and p-v alue 0 . 05 All the statements are statistically significan t with resp ect to such hypothesis tests. Aggregate results for 12x12 (Bottom left plot, Fig. 2). The bottom left-hand plot in Fig. 2 shows the aggregate results for this case. There is no clear ov erall b est ov er all q . W e also observ e the follo wing. 1. fp (ce) is b est among all metho ds except for when w = 2 . 0, where gs is b etter. 2. trw is second best among all metho ds, except for when w = 2 . 0, where it is third b est (b ehind fp (ce) and gs). 3. bp is consisten tly b etter than mf and nr except when w = 3 . 5, where it is indistinguishable from nr (but still b etter than mf ). 4. mf is consisten tly worse than bl, except when w = 4 . 0, where they are indistinguishable. nr is also consisten tly worse than bl, except when w = 2 . 5, where they are indistinguishable 5. gs is consisten tly b etter than mf, nr, and bl, except when w = 4 . 0, where gs and bl are indistinguishable. 6. mw is b etter than bl when w < 3 . 5, but indistinguishable from bl when w ≥ 3 . 5. 29 Such class of mo dels follows from our general experience with similar mo dels. W e find that instantiating Ising mo del parameters using densities ov er edge-weigh ts tended to yield to relatively easier mo dels than the ones we obtain b y fixing the magnitude of the edge-weigh ts and v arying the probability of their sign, indep enden tly for each edge. 30 Results for constan t edge-weigh t magnitude w = 4 as a function of probabilit y of attractive in teraction q (Right plots, Fig. 2). The righ t- hand plots in Fig. 2 sho ws finer-grain results for this case, for b oth the 8x8 and 12x12 mo dels. The results suggest that in fact such instances of Ising mo dels tend to b e harder in the sense that even state-of-the-art algorithms such as trw are no b etter than the simple baseline estimation, in whic h b p i = 0 . 5 for all nodes/v ariables i , for about half of the full range of v alues of the sign probabilit y q (i.e., for q ∈ { 0 . 1 , 0 . 4 , 0 . 5 , 0 . 6 , 0 . 8 , 0 . 9 } ). In fact, the performance of trw is almost exactly the same as baseline across the range of non-extreme v alues of q . (Note ho w the plot of the v alues for trw and bl are essen tially on top of each other for v alues of q other than 0 or 1.) On the other hand, note how fp (ce) is consistently better than bl across the whole range of v alues for q . In fact, fp (ce) is alw ays in the set of (statistically) b est p erformers for all q with the exception of q ∈ { 0 . 0 , 1 . 0 } , where trw is b etter. Almost all the metho ds other than fp (ce) are no b etter, and often worse, than bl. Two notable exceptions are that trw and mw b eat bl only when q ∈ { 0 . 0 , 1 . 0 } . Also, mw and fp (ce) are indistinguishable, except for q ∈ { 0 . 0 , 1 . 0 } where fp (ce) is b etter. Fig. 3 plots the prop ortion of non-con vergen t runs of bp (higher curv e) and trw (low er curve). Note the interesting behavior of bp: the likelihoo d of conv er- gence diminishes considerably as q nears 0 . 5. The effect is almost symmetrical. In contrast, the effect on the non-conv ergence of trw is negligible. Note, how ever, that the bp’s non-conv ergence do es not seem to really affect its p erformance in terms of marginal error. This plot provides additional evidence for our claim that the generative mo del of random Ising mo dels used for ev aluation do es lead to harder problem instances. Results for the effect of differen t t yp es of no-regret algorithms. Fig. 5 sho ws the results of v arious types of no-regret algorithms based on the multiplicativ e- w eights algorithm. The v ariants result from the combination of (a) external vs. sw ap regret and (b) exact vs. approximate no-regret guarantees. The tak e-home message is that the version for external regret with approximate no-regret guar- an tees, whic h we refer to b oth as ’m w’ and ’m w er’ throughout this section, is consisten tly b etter or no worse than the others, as we stated at the b eginning of this subsection (second paragraph). This result app ears counter-in tuitive given that such v ariant has the low est guarantees in terms of optimality/equilibrium conditions. Said differen tly , the p ossible set of solutions is largest among all v ari- an ts. An analogy with gradient-descen t based optimizations in other mac hine- learning contexts may provide a p ossible explanation for this b eha vior. F or example, it is well known that reducing the learning rate or step size in in verse prop ortion to the num b er of iterations when learning neural netw orks via back- prop theoretically guarantees conv ergence in parameter (weigh t) space. Y et, it is equally well-kno wn that doing so is often slow in practice, and that using a small contan t as the learning rate tends to lead to faster con vergene to go o d mo dels, despite the lac k of theoretical guarantees. W e refer the reader to the caption in Fig. 5 for further discussion. 31 Results on the effect of the n umber of iterations. Finally , Fig. 4 shows the marginal error of the estimates obtained by fp (ce), for different n umbers of iterations. Increasing the n umber of iterations from m = 15 to m = 50 (and greater) only yields minimal improv ement in marginal error. In addition, eac h run of fp results in pretty consisten t marginal errors at each iteration lev el. Based on this, it appears that fp con v erges to an estimate in a fairly low n umber of iterations, and do es so consistently . Compare this with Fig. 6, which shows t wo similar plots eac h for the trw and gs algorithms. Though trw results in a comparable a verage marginal error, the marginal error of each run v aries more than in fp. Increasing the n umber of iterations for trw do es not decrease this v ariance, either. The same behavior occurs with gs, though its av erage marginal error is a bit higher than trw and fp. 4.3 Exp erimen tal Design: MNIST-based Ising Mo dels W e also ev aluated the v arious algorithms on Ising mo dels for more realistic settings. W e use images of handwritten digits from the p opular MNIST dataset to build Ising mo dels for soft de-noising. Note that the interest here is not classification nor MAP estimation, but b elief inference: using the individual marginal probabilities as confidence measure on the individual pixel v alues of the de-noised image. The images consist of 28x28 pixel images, so our Ising mo dels are 28x28 simple planar grid graphs, as in the synthetic exp erimen ts. The grayscale pixel v alues in the original MNIST images are conv erted to black (+1) and white ( − 1) v alues, using a threshold of 0 . 5. Rather than randomly setting edge weigh ts, w e compute the av erage pro duct b et ween neighboring pixels, tak en across all training images, then use that av erage product as the edge-w eight b et ween those neighboring pixels. That is, denote by I l the matrix represen tation of the l -th image in the MNIST training dataset, and denote b y m the num b er of images in that training dataset. W e set the w eight w ( i,j ) , ( i,j +1) of the edge b et w een no des/pixels ( i, j ) and ( i, j + 1), for example, w ( i,j ) , ( i,j +1) ∝ 1 m m X l =1 I l ( i, j + 1) I l ( i, j ) v alues. and the prior bias b ( i,j ) for no de/pixel ( i, j ), for example, as b ( i,j ) ∝ 1 m m X l =1 I l ( i, j ) , and the normalization factor is suc h that max ( i,j ) | b ( i,j ) | = 1. W e select 100 im- ages uniformly at random from the MNIST test dataset, and apply the thresh- olding describ ed abov e to turn them into a BW images. W e add 5% noise to eac h of the resulting BW images by ”flipping” each pixel v alue indep enden tly with probability p = 0 . 05. Hence, we ha ve a different Ising model for eac h im- age: the edge weigh ts are all the same, but the biases differ dep ending on the sp ecific v alue of the test image. That is, if I denotes the matrix represen tation 32 of the noisy BW test image, then the Gibbs p oten tial of the Ising mo del b ecomes Ψ I ( x ) ≡ P (( i,j ) , ( r ,s )) ∈ E e w ( i,j ) , ( r ,s ) x ( i,j ) x ( r,s ) + P ( i, j ) e b ( i,j ) ( I ( i, j )) x ( i,j ) , where e w ( i,j ) , ( r ,s ) ∝ w ( i,j ) , ( r ,s ) and e b ( i,j ) ( I ( i, j )) ∝ b ( i,j ) + 1 2 I ( i, j ) ln 1 − p p , and the nor- malization factor is such that max ( i,j ) | e b ( i,j ) ( I ( i, j )) | = 1 (for consistency with the no de biases of Ising mo dels in the synthetic exp erimen ts). W e ran the exact same algorithms on the constructed Ising mo dels as in the syn thetic exp erimen ts, though w e used a slightly different num b er of (max) iterations: 100 for fp (all v ariants); 10 4 for bp, nr, and m w (all v ariants); 10 5 for trw and gs; and 10 6 for mf. 4.4 Exp erimen tal Results: MNIST-based Ising Mo dels Fig. 7 sho ws our results of the exp erimen tal ev aluation of the algorithms de- scrib ed in earlier sections (with the exception of gs). Like in the synthetic exp erimen ts, we p erform hypothesis testing using paired z-tests on the individ- ual differences, each with p-v alue 0.05. It is imp ortan t to note that statements in this section comparing algorithm performance are alw ays made with resp ect to gs. That is, the b etter performing algorithms here are actually pro ducing output most similar to gs. The computed edge-weigh ts for the Ising models derived from MNIST images actually consist of all positive v alues, so this experiment can be thought of as analogous to the “attractive” case in the synthetic exp erimen ts. How ev er, as evidenced in Fig. 7, the MNIST-deriv ed mo dels app ear to be m uch “easier” than the synthetic models, since ev ery algorithm p erforms m uch b etter than baseline. F or example, mf has very low marginal error in this case, even though in the synthetic exp erimen ts it was often indistinguishable from bl. In order, the b est p erforming algorithms are 1) bp, 2) trw, 3) mf, 4) mw er, 5) mw er cf, 6) fp, 7) nr, 8) mw sr, 9) mw sr cf, and 10) bl. Fig. 7 shows our results for the case of Ising models for the Handwritten Digit ”1” only . That is, the edge w eights were computed using only images in the MNIST dataset with a training lab el of the ”1” digit. Likewise, the observ ed image samples came only from images in the test data set with a lab el of the ”1” digit. The figure sho ws that while the v arious algorithms hav e the same relativ e order to each other when run on ”1’s” vs ”all” digits, the range of av erage marginal errors they achiev ed tightened. 5 F uture W ork and New Opp ortunities It would b e nice to hav e a b etter understanding of the exact relationship b etw een the true joint distribution of the MRF and the equilibrium points of the induced graphical p oten tial game. F or example, it is kno wn that no-external-regret- based algorithms lik e mw conv erge to PSNE in “generic” p otential games [Klein- b erg et al., 2009], such as the MRF-induced game. In fact, we observ e such consisten t conv ergence to PSNE by mw in our exp erimen ts, which is unlik e the b eha vior we observed for fp (ce). But conv ergence to PSNE means that w e are 33 essen tially approximating the whole distribution with a single join t assignment (i.e., a p oin t mass). Y et, mw can outp erform state-of-the-art algorithms like trw, particularly on “hard” instances, despite yielding such extremely coarse ap- pro ximations. In addition, b est-resp onse dynamics in the MRF-induced game con verges to a PSNE and is equiv alent to the metho d of iter ate d c onditional mo des (ICM) [Besag, 1986] in PGMs, which con verges to a lo cally optimal joint assignmen t of the original MRF. W e did not include ICM in our exp erimen ts b ecause it is generally considered inferior to other metho ds. The results of mw suggests w e migh t wan t to also ev aluate ICM for hard instances and compare its output and p erformance to that of m w. One interesting question is whether m w often finds b etter lo cal minima that ICM, or whether ICM is equally effective, in those hard cases. As another example of how the proposed study would b e useful, it migh t giv e us a b etter idea as to whether one can think of a Gibbs sampler, or other Mon te-Carlo sampling algorithms, as providing solutions to equilibrium problems of certain quality . Here w e establish a connection betw een mf and MSNE. Despite the fact that mf often provides po or appro ximations, even w orst than baseline in many cases, it would still be theoretically interesting to study the relationship b et ween the output of mf and that of algorithms that compute approximate MSNE in lo op y graphical games, such as NashProp [Ortiz and Kearns, 2003]. The focus of the exp erimen tal ev aluation in this pap er was testing our pro- p osed, game-theoretically-inspired algorithms for b elief inference with standard algorithms in the literature of probabilistic graphical mo dels with relativ ely “simple” implementations (e.g., do not require calls to softw are pack ages or the implemen tation of complex optimizations). An empirical study inv olving suc h algorithms with considerably more complex implemen tations must hav e a precise experimental metho dology and design that accounts for not only the complexit y of implemen tation, but also a fair comparison that ac hieves the right balance b et ween measures of solution quality and running times. W e leav e such ev aluations for future work b ecause of the level of complexity required to carry them out correctly . The w ork in this pap er just “scratches the surface” in terms of the synergy b et w een equilibirum computation in game theory and belief inference in prob- abilistic graphical mo dels. W e state and discuss several immediate theoretical, algorithmic, and computational implications, but man y more ma y b e p ossible. An ev en broader and more thorough literature review than the one provided in this manuscript is necessary to fully exploit this connection. Thus, man y opp ortunities for no vel contributions remain av ailable in either direction. 6 Con tributions and Concluding Remarks W e pro vide general formulations of the problem of inference in MRFs as equi- librium computation in graphical p oten tial games. W e provide connections, particularly to v ariational inference approac hes, with immediate algorithmic, computational, and theoretical implications to b elief inference in probabilistic 34 graphical mo dels that follow immediately from the game-theory literature to v arious related problems. W e provide t wo approaches for appro ximate b elief inference: a local and a global approach. W e experimentally ev aluate the ef- fectiv eness of the prop osed algorithms in the context of Ising mo dels with grid graphs, and provide a characterization of their computational effectiv eness based on common measures used to c haracterize classes of Ising mo dels (e.g., mixed and attractiv e models with differen t relative levels of magnitude b et ween the edge weigh ts and no de bias v alues). W e also empirically ev aluate effectiv eness using a slightly different approach in which we keep the edge-weigh t magnitude constan t but v ary the “sign probability .” W e show ho w most metho ds are often not muc h better than a simple baseline (i.e., estimate that the marginal prob- abilities are all equal to 0 . 5) in that class of Ising mo dels. Our results suggest that the prop osed class of Ising mo dels does indeed lead to harder instances than the popular mo dels used for empirical ev aluation in the same con text of Ising mo dels. W e empirically show that our prop osed metho d based on a global approac h is b est, b eating ev en TR W within that class, and shinning in a class of Ising models with constan t, “highly attractive” edge-w eights, in whic h it is often b etter than all other alternatives we ev aluated. Note that TR W is gener- ally considered state-of-the-art. W e prop ose such class of Ising models for future ev aluations b ecause our experimental results suggest that instances from that class are often the hardest. While our more lo cal approach is not as effectiv e as our global approach or TR W, in fairness, almost all of the alternatives were no b etter than a simple baseline: estimate the marginal probabilit y to b e 0 . 5. Some reviewers hav e expressed the view that our general equilibrium-based approac h to approximate inference is “limited to lo c al ly optimal solutions to inference problems.” W e would like to p oin t that almost all approaches to appro ximate inference based on v ariational appro ximation emplo yed in practice, including simple metho ds such as mean field and state-of-the-art metho ds such as TR W, suffer from exactly the same limitations. In closing, our hop e is that the work w e presen t in this manuscript will start a conv ersation on the synergy betw een equilibrium computation and be- lief inference. W e b eliev e our work and results establish sufficient preceden t for researc h in the direction of form ulating probabilistic inference problems as problems of equilibrium computation. W e b eliev e this researc h direction is sci- en tifically intriguing and p oten tially fruitful for mathematical, algorithmic, and computational game-theory , as well as for probabilistic graphical mo dels. References R.J. Aumann. Sub jectivity and correlation in randomized strategies. Journal of Mathematic al Ec onomics , 1, 1974. R.J. Aumann. Correlated equilibrium as an expression of Bay esian rationality . Ec onometric a , 55, 1987. Marc Bertho d, Zoltan Kato, Shan Y u, and Josiane Zerubia. Bay esian image 35 classification using Mark o v random fields. Image and Vision Computing , 14 (4):285–295, 1996. Julian Besag. Spatial interaction and the statistical analysis of lattice systems. Journal of the R oyal Statistic al So ciety. Series B (Metho dolo gic al) , 36(2):192– 236, 1974. ISSN 00359246. URL http://www.jstor.org/stable/2984812 . Julian Besag. On the statistical analysis of dirty pictures. Journal of the R oyal Statistic al So ciety. Series B (Metho dolo gic al) , 48(3):259–302, 1986. ISSN 00359246. URL http://www.jstor.org/stable/2345426 . Avrim Blum and Yishay Mansour. Learning, regret minimization, and equilib- ria. In Noam Nisan, Tim Roughgarden, ´ Ev a T ardos, and Vija y V. V azirani, editors, Algorithmic Game The ory , chapter 4, pages 79–102. Cambridge Uni- v ersity Press, 2007. Xi Chen and Xiaotie Deng. Settling the complexit y of 2-play er Nash- equilibrium. T echnical Rep ort 140, Electronic Collo quium on Computational Complexit y (ECCC), 2005a. http://eccc.hpi- web.de/eccc- reports/ 2005/TR05- 140/index.html . Xi Chen and Xiaotie Deng. 3-NASH is PP AD-complete. T echnical Rep ort 134, Electronic Collo quium on Computational Complexity (ECCC), 2005b. http://eccc.hpi- web.de/eccc- reports/2005/TR05- 134/index.html . Xi Chen and Xiaotie Deng. Settling the complexity of tw o-play er Nash equilib- rium. In Pr o c e e dings of the 47th Annual IEEE Symp osium on F oundations of Computer Scienc e (FOCS’06) , 2006. Xi Chen, Xiaotie Deng, and Shang-Hua T eng. Computing Nash equilibria: Appro ximation and smo othed complexity . In Pr o c e e dings of the 47th Annual IEEE Symp osium on F oundations of Computer Scienc e (F OCS’06) , 2006. Xi Chen, Xiaotie Deng, and Shang-Hua T eng. Settling the complexit y of com- puting tw o-play er Nash equilibria. J. ACM , 56(3):1–57, 2009. Jian Cheng and Marek J. Druzdzel. AIS-BN: An adaptive imp ortance sampling algorithm for eviden tial reasoning in large Bay esian netw orks. Journal of A rtificial Intel ligenc e R ese ar ch , 13:155–188, 2000. Vincen t Conitzer and T uomas Sandholm. New complexity results ab out Nash equilibria. Games and Ec onomic Behavior , 63(2): 621 – 641, 2008. ISSN 0899-8256. doi: DOI:10.1016/j.geb. 2008.02.015. URL http://www.sciencedirect.com/science/article/ B6WFW- 4SDGR4B- 1/2/cf2498492436f6eaa78dd3314a877366 . Second W orld Congress of the Game T heory So ciet y . Gregory F. Co oper. The computational complexity of probabilistic inference using Bay esian b elief netw orks (researc h note). A rtif. Intel l. , 42(2-3):393– 405, 1990. 36 Thomas M. Cov er and Jo y A. Thomas. Elements of Information The ory . Wiley & Sons, New Y ork, second edition, 2006. P aul Dagum and Michael Luby . Appro ximating probabilistic inference in ba yesian b elief netw orks is np-hard. Artificial Intel ligenc e , 60(1):141 – 153, 1993. ISSN 0004-3702. doi: h ttps://doi.org/10.1016/0004- 3702(93) 90036- B. URL http://www.sciencedirect.com/science/article/pii/ 000437029390036B . Constan tinos Dask alakis and Christos H. Papadimitriou. Computing pure Nash equilibria in graphical games via Marko v random fields. In EC ’06: Pr o c e e dings of the 7th ACM c onfer enc e on Ele ctr onic c ommer c e , pages 91– 99, New Y ork, NY, USA, 2006. ACM. ISBN 1-59593-236-4. doi: h ttp: //doi.acm.org/10.1145/1134707.1134718. Constan tinos Dask alakis, Alexandros G. Dimakis, and Elc hanan Mossel. Con- nectivit y and equilibrium in random games, 2007. http://www.citebase. org/abstract?id=oai:arXiv.org:math/0703902 . Constan tinos Dask alakis, Paul W. Goldb erg, and Christos H. Papad imitriou. The complexity of computing a Nash equilibrium. SIAM Journal on Com- puting , 39(1):195–259, 2009a. Constan tinos Dask alakis, Paul W. Goldb erg, and Christos H. Papad imitriou. The complexity of computing a Nash equilibrium. Commun. ACM , 52(2): 89–97, 2009b. Konstan tinos Dask alakis and Christos H. Papadimitriou. Three-pla yer games are hard. T echnical Rep ort 139, Electronic Collo quium on Computational Complexit y (ECCC), 2005. http://eccc.hpi- web.de/eccc- reports/ 2005/TR05- 139/index.html . Konstan tinos Dask alakis, Paul W. Goldb erg, and Christos H. Papadimitriou. The complexity of computing a Nash equilibrium. T echnical Rep ort 115, Electronic Collo quium on Computational Complexity (ECCC), 2005. http: //eccc.hpi- web.de/eccc- reports/2005/TR05- 115/index.html . Justin Domke and Xianghang Liu. Pro jecting Ising mo del parameters for fast mixing. In C.J.C. Burges, L. Bottou, M. W elling, Z. Ghahramani, and K.Q. W einberger, editors, A dvanc es in Neur al Information Pr o c essing Sys- tems 26 , pages 665–673. 2013. URL http://media.nips.cc/nipsbooks/ nipspapers/paper_files/nips26/391.pdf . Alex F abrik ant, Christos Papadimitriou, and Kunal T alwar. The complexity of pure Nash equilibria. In STOC ’04: Pr o c e e dings of the Thirty-Sixth Annual A CM Symp osium on The ory of Computing , pages 604–612, New Y ork, NY, USA, 2004. ACM. D. F oster and R. V ohra. Calibrated learning and correlated equilibrium. Games and Ec onomic Behavior , 1997. 37 D. F oster and R. V ohra. Regret in the on-line decision problem. Games and Ec onomic Behavior , pages 7 – 36, 1999. D. F uden b erg and D. Levine. The The ory of L e arning in Games . MIT Press, 1999. Drew F udenberg and Jean Tirole. Game The ory . The MIT Press, 1991. Stuart Geman and Donald Geman. Sto c hastic relaxation, Gibbs distributions, and the Bay esian restoration of images. Pattern Analysis and Machine Intel- ligenc e, IEEE T r ansactions on , P AMI-6(6):721–741, Nov. 1984. I. Gilb oa and E. Zemel. Nash and correlated equilibria: some complexity con- siderations. Games and Ec onomic Behavior , 1:80–93, 1989. P aul W. Goldb erg and Christos H. Papadimitriou. Reducibilit y among equilibrium problems. T echnical Rep ort 090, Electronic Collo quium on Computational Complexity (ECCC), 2005. http://eccc.hpi- web.de/ eccc- reports/2005/TR05- 090/index.html . Georg Gottlob, Gianluigi Greco, and F rancesco Scarcello. Pure Nash equilibria: Hard and easy games. In T ARK ’03: Pr o c e e dings of the 9th c onfer enc e on The or etic al asp e cts of r ationality and know le dge , pages 215–230, New Y ork, NY, USA, 2003. ACM. ISBN 1-58113-731-1. doi: http://doi.acm.org/10. 1145/846241.846269. J.M. Hammersley and P . Clifford. Marko v fields on finite graphs and lattices. Unpublished, 1971. Firas Hamze and Nando de F reitas. F rom fields to trees. In Pr o c e e dings of the 20th Confer enc e on Unc ertainty in Artificial Intel ligenc e , UAI ’04, pages 243– 250, Arlington, Virginia, United States, 2004. AUAI Press. ISBN 0-9749039- 0-6. URL http://dl.acm.org/citation.cfm?id=1036843.1036873 . James Hannan. Approximation to Ba y es risk in repeated play . In M. Dresher, A. W. T uck er, and P . W olfe, editors, Contributions to the The ory of Games , v olume I II, pages 97–140. Princeton Universit y Press, 1957. Sergiu Hart and Yishay Mansour. The comm unication complex- it y of uncoupled nash equilibrium procedures. In STOC ’07: Pr o c e e dings of the thirty-ninth annual ACM symp osium on The ory of c omputing , pages 345–353, New Y ork, NY, USA, 2007. A CM. ISBN 978-1-59593-631-8. doi: http://doi.acm.org/10.1145/1250790. 1250843. URL http://portal.acm.org/ft_gateway.cfm?id=1250843& type=pdf&coll=Portal&dl=GUIDE&CFID=48027515&CFTOKEN=24230463 . Sergiu Hart and Andreu Mas-Colell. A simple adaptive pro cedure leading to correlated equilibrium. Ec onometric a , 68(5):1127 – 1150, 2000. 38 Sergiu Hart and Andreu Mas-Colell. Uncoupled dynamics do not lead to Nash equilibrium. Americ an Ec onomic R eview , 93(5):1830–1836, 2003. Sergiu Hart and Andreu Mas-Colell. Sto c hastic uncoupled dynamics and Nash equilibrium: Extended abstract. In T ARK , pages 52–61, 2005. Josef Hofbauer and William H. Sandholm. On the global conv ergence of sto c has- tic fictitious play . Ec onometric a , 70(6):2265–2294, 2002. ISSN 00129682, 14680262. URL http://www.jstor.org/stable/3081987 . J J Hopfield. Neural net works and ph ysical systems with emergent collective computational abilities. Pr o c e e dings of the National A c ademy of Scienc es of the Unite d States of A meric a , 79(8):2554–2558, 1982. URL http://www. pnas.org/content/79/8/2554.abstract . Rob ert A. Hummel and Steven W. Zuck er. On the foundations of relaxation lab eling pro cesses. Pattern A nalysis and Machine Intel ligenc e, IEEE T r ans- actions on , P AMI-5(3):267–287, May 1983. Sorin Istrail. Statistical mechanics, three-dimensionalit y and NP- completeness: I. universalit y of intracatabilit y for the partition func- tion of the Ising model across non-planar surfaces (extended abstract). In STOC ’00: Pr o c e e dings of the thirty-se c ond annual ACM symp o- sium on The ory of c omputing , pages 87–96, New Y ork, NY, USA, 2000. A CM. ISBN 1-58113-184-4. doi: http://doi.acm.org/10.1145/335305. 335316. URL http://portal.acm.org/ft_gateway.cfm?id=335316&type= pdf&coll=Portal&dl=GUIDE&CFID=46800608&CFTOKEN=87597059 . T ommi S. Jaakkola. T utorial on v ariational approximation metho ds. In M. Op- p er and D. Saad, editors, A dvanc e d Me an Field Metho ds: The ory and Pr actic e , pages 129–159. MIT Press, Cambridge, MA, 2000. T ommi S. Jaakkola and Michael L. Jordan. Improving the mean field approxi- mation via the use of mixture distributions. In Pr o c e e dings of the NA TO ASI on L e arning in Gr aphic al Mo dels . Klu wer, 1997. http://people.csail.mit. edu/tommi/papers/mix.ps . E. B. Janovsk a ja. Equilibrium situations in multi-matrix games. Litovsk. Mat. Sb. , 8:381–384, 1968. Alb ert Xin Jiang and Kevin Leyton-Brown. Action-graph games. T echnical Rep ort TR-2008-13, Univ ersity of British Colum bia, September 2008. URL http://www.cs.ubc.ca/cgi- bin/tr/2008/TR- 2008- 13 . Alb ert Xin Jiang and Kevin Leyton-Bro wn. Polynomial computation of exact correlated equilibrium in compact games. SIGe c om Exchanges , 10(1):6–8, 2011. 39 Alb ert Xin Jiang and Kevin Leyton-Brown. Polynomial-time computation of exact correlated equilibrium in compact games. Games and Ec onomic Behav- ior , 91:347 – 359, 2015a. ISSN 0899-8256. doi: http://dx.doi.org/10.1016/j. geb.2013.02.002. URL http://www.sciencedirect.com/science/article/ pii/S0899825613000249 . Alb ert Xin Jiang and Kevin Leyton-Brown. Polynomial-time computation of exact correlated equilibrium in compact games. Games and Ec onomic Behav- ior , 91:347 – 359, 2015b. ISSN 0899-8256. doi: http://dx.doi.org/10.1016/j. geb.2013.02.002. URL http://www.sciencedirect.com/science/article/ pii/S0899825613000249 . Da vid S. Johnson, Christos H. Papadimitriou, and Mihalis Y annak akis. Ho w easy is local searc h? Journal of Computer and System Scienc es , 37(1):79 – 100, 1988. Mic hael I. Jordan, Zoubin Ghahramani, T ommi S. Jaakk ola, and La wrence K. Saul. An introduction to v ariational metho ds for graphical mo dels. Mach. L e arn. , 37(2):183–233, 1999. Sham Kak ade, Michael Kearns, John Langford, and Luis Ortiz. Correlated equi- libria in graphical games. In EC ’03: Pr o c e e dings of the 4th ACM Confer enc e on Ele ctr onic Commer c e , pages 42–47, New Y ork, NY, USA, 2003. ACM. Hetunandan Kamisetty , Eric P . Xing, and Christopher J. Langmead. Approx- imating correlated equilibria using relaxations on the marginal p olytope. In Lise Geto or and T obias Sc heffer, editors, Pr o c e e dings of the 28th Interna- tional Confer enc e on Machine L e arning (ICML-11) , pages 1153–1160, New Y ork, NY, USA, 2011. ACM. URL http://www.icml- 2011.org/papers/ 594_icmlpaper.pdf . Sam uel Karlin. Mathematic al Metho ds and The ory in Games, Pr o gr amming, and Ec onomics . Addison W esley Publishing Company , 1959. M. Kearns, M. Littman, and S. Singh. Graphical models for game theory . In Pr o c e e dings of the Confer enc e on Unc ertainty in Artificial Intel ligenc e , pages 253–260, 2001. Rob ert Klein b erg, Georgios Piliouras, and Ev a T ardos. Multiplicative updates outp erform generic no-regret learning in congestion games: Extended ab- stract. In Pr o c e e dings of the F orty-first Annual ACM Symp osium on The- ory of Computing , STOC ’09, pages 533–542, New Y ork, NY, USA, 2009. A CM. ISBN 978-1-60558-506-2. doi: 10.1145/1536414.1536487. URL http://doi.acm.org/10.1145/1536414.1536487 . Daphne Koller and Brian Milc h. Multi-agent influence diagrams for represen ting and solving games. Games and Ec onomic Behavior , 45(1):181–221, 2003. Pierfrancesco La Mura. Game netw orks. In Pr o c e e dings of the 16th Annual Confer enc e on Unc ertainty in A rtificial Intel ligenc e (UAI-00) , 2000. 40 Kevin Leyton-Brown and Moshe T ennenholtz. Local-effect games. In Pr o c e e d- ings of the Eighte enth International Joint Confer enc e on Artificial Intel ligenc e (IJCAI) , pages 772–777, 2003. Douglas A. Miller and Steven W. Zuck er. Copositive-plus Lemke algorithm solv es p olymatrix games. Op er ations R ese ar ch L etters , 10(5):285 – 290, 1991. Douglas A. Miller and Stev en W. Zuck er. Efficient simplex-like metho ds for equi- libria of nonsymmetric analog netw orks. Neur al Computation , 4(2):167–190, 1992. doi: 10.1162/neco.1992.4.2.167. URL http://www.mitpressjournals. org/doi/abs/10.1162/neco.1992.4.2.167 . Do v Monderer and Llo yd S. Shapley . Fictitious pla y prop ert y for games with iden tical in terests. Journal of Ec onomic The ory , 68(1):258 – 265, 1996a. ISSN 0022-0531. doi: h ttp://dx.doi.org/10.1006/jeth.1996.0014. URL http: //www.sciencedirect.com/science/article/pii/S0022053196900149 . Do v Monderer and Lloyd S. Shapley . P otential games. Games and Ec o- nomic Behavior , 14(1):124 – 143, 1996b. ISSN 0899-8256. doi: DOI: 10.1006/game.1996.0044. URL http://www.sciencedirect.com/science/ article/B6WFW- 45MH08H- 2C/2/69a63e2471795b08d937785bb923e9ea . H. Moulin and J. P . Vial. Strategically zero-sum games: The class of games whose completely mixed equilibria cannot b e impro v ed up on. International Journal of Game The ory , 7(3):201–221, 1978. ISSN 1432-1270. doi: 10.1007/ BF01769190. URL http://dx.doi.org/10.1007/BF01769190 . John Nash. Non-co operative games. Annals of Mathematics , 54:286–295, Septem b er 1951. Noam Nisan, Tim Roughgarden, ´ Ev a T ardos, and Vijay V. V azirani, editors. A lgorithmic Game The ory . Cambridge Universit y Press, 2007. Luis E. Ortiz. Sele cting Appr oximately-Optimal A ctions in Complex Structur e d Domains . PhD thesis, Brown Universit y , May 2002. http://www- personal. umd.umich.edu/ ~ leortiz/phd.pdf . Luis E. Ortiz. On sparse discretization for graphical games. CoRR , abs/1411.3320, 2014. URL . Luis E. Ortiz. Graphical p oten tial games. CoRR , abs/1505.01539, 2015. URL http://arxiv.org/abs/1505.01539 . Luis E. Ortiz and Mohammad T. Irfan. T ractable algorithms for approximate Nash equilibria in generalized graphical games with tree structure. In Pr o c e e d- ings of the Thirty-First AAAI Confer enc e on Artificial Intel ligenc e (AAAI- 17) , pages 635–641. AAAI Press, 2017. 41 Luis E. Ortiz and Leslie P ack Kaelbling. Adaptiv e imp ortance sampling for esti- mation in structured domains. In UAI ’00: Pr o c e e dings of the 16th Confer enc e on Unc ertainty in Artificial Intel ligenc e , pages 446–454, San F rancisco, CA, USA, 2000. Morgan Kaufmann Publishers Inc. ISBN 1-55860-709-9. Luis E. Ortiz and Mic hael Kearns. Nash propagation for loopy graphical games. In Suzanna Beck er Bec ker, Sebastian Thrun Thrun, and Klaus Obermay er, editors, A dvanc es in Neur al Information Pr o c essing Systems 15 , pages 817– 824, 2003. Luis E. Ortiz, Rob ert E. Schapire, and Sham M. Kak ade. Maximum entrop y cor- related equilibrium. T echnical Rep ort TR-2006-21, CSAIL MIT, Cam bridge, MA USA, March 2006. Luis E. Ortiz, Rob ert E. Schapire, and Sham M. Kak ade. Maximum entrop y cor- related equilibria. In Marina Meila and Xiaotong Shen, editors, Pr o c e e dings of the Eleventh International Confer enc e on Artificial Intel ligenc e and Statis- tics (AIST A TS-07) , volume 2, pages 347–354. Journal of Machine Learning Researc h - Pro ceedings T rack, 2007. URL http://jmlr.csail.mit.edu/ proceedings/papers/v2/ortiz07a/ortiz07a.pdf . C. H. Papadimitriou, A. A. Sch¨ affer, and M. Y annak akis. On the complexity of lo cal search. In STOC ’90: Pr o c e e dings of the twenty-se c ond annual A CM symp osium on The ory of c omputing , pages 438–445, New Y ork, NY, USA, 1990. A CM. ISBN 0-89791-361-2. doi: http://doi.acm.org/10.1145/100216. 100274. Christos H. P apadimitriou. On the complexit y of the parity argumen t and other inefficien t pro ofs of existence. J. Comput. Syst. Sci. , 48(3):498–532, 1994. ISSN 0022-0000. doi: http://dx.doi.org/10.1016/S0022- 0000(05)80063- 7. Christos H. Papadimitriou. Computing correlated equilibria in multi-pla yer games. In STOC ’05: Pr o c e e dings of the Thirty-Seventh A nnual ACM Sym- p osium on The ory of cComputing , pages 49–56, 2005. Christos H. Papadimitriou and Tim Roughgarden. Computing equilibria in m ulti-play er games. In SOD A ’05: Pr o c e e dings of the Sixte enth Annual ACM- SIAM Symp osium on Discr ete Algorithms , pages 82–91, 2005. Christos H. P apadimitriou and Tim Roughgarden. Computing correlated equilibria in multi-pla yer games. J. ACM , 55(3):1–29, 2008. ISSN 0004-5411. doi: h ttp://doi.acm.org/10.1145/1379759.1379762. URL http://portal.acm.org/ft_gateway.cfm?id=1379762&type=pdf&coll= Portal&dl=GUIDE&CFID=48210635&CFTOKEN=34538586 . Iead Rezek, David S. Leslie, Stev en Reece, Stephen J. Rob erts, Alex Rogers, Ra jdeep K. Dash, and Nic holas R. Jennings. On similarities b et ween inference in game theory and mac hine learning. J. A rtif. Intel l. R es. (JAIR) , 33:259– 283, 2008. URL http://dblp.uni- trier.de/db/journals/jair/jair33. html#RezekLRRRDJ08 . 42 Y osef Rinott and Marco Scarsini. On the n umber of pure strategy Nash equi- libria in random games. Games and Ec onomic Behavior , 33(2):274 – 293, 2000. Azreil Rosenfeld, Rob ert A. Hummel, and Steven W. Zuc ker. Scene lab eling by relaxation op erations. IEEE T r ansactions of Systems, Man, and Cyb ernetics , SMC-6(6), June 1976. Dan Roth. On the hardness of approximate reasoning. A rtificial Intel li- genc e , 82(1):273 – 302, 1996. ISSN 0004-3702. doi: https://doi.org/10.1016/ 0004- 3702(94)00092- 1. URL http://www.sciencedirect.com/science/ article/pii/0004370294000921 . Stuart J. Russell and Peter Norvig. Artificial Intel ligenc e: A Mo dern Appr o ach . P earson Education, 2003. Bart Selman, Henry Kautz, and Bram Cohen. Lo cal search strategies for satis- fiabilit y testing. In David S. Johnson and Michael A. T rick, editors, Cliques, Coloring, and Satisfiability: Se c ond DIMACS Implementation Chal lenge, Oc- tob er 11-13, 1993 , volume 26 of DIMACS Series in Discr ete Mathematics and The or etic al Computer Scienc e . AMS, 1996. Solomon Eyal Shimony . Finding MAPs for b elief netw orks is NP-hard. A rtifi- cial Intel ligenc e , 68(2):399 – 410, 1994. ISSN 0004-3702. doi: DOI:10.1016/ 0004- 3702(94)90072- 8. URL http://www.sciencedirect.com/science/ article/B6TYF- 47YY1PM- 5/2/464fa2711fc166135138f15751a06bd2 . William Stanford. A note on the probability of k pure Nash equilibria in matrix games. Games and Ec onomic Behavior , 9(2):238 – 246, 1995. J. Sz ´ ep and F. F orgo´ o. Intr o duction to the The ory of Games . D. Reidel Pub- lishing Company , 1985. D. Vickrey and D. Koller. Multi-agent algorithms for solving graphical games. In Pr o c e e dings of the Eighte enth National Confer enc e on Artificial Intel ligenc e (AAAI-02) , pages 345–351, 2002. John v on Neumann and Osk ar Morgenstern. The ory of Games and Ec onomic Behavior . Princeton Universit y Press, Princeton, NJ, 1947. Second Edition. M. J. W ainwrigh t, T. S. Jaakk ola, and A. S. Willsky . A new class of upp er b ounds on the log partition function. IEEE T r ansactions on Information The ory , 51(7):2313–2335, July 2005. ISSN 0018-9448. doi: 10.1109/TIT. 2005.850091. Chaoh ui W ang, Nik os Komo dakis, and Nik os Paragios. Mark ov random field mo deling, inference & learning in computer vision & image under- standing: A survey . Computer Vision and Image Understanding , 117 (11):1610 – 1627, 2013. ISSN 1077-3142. doi: http://dx.doi.org/10. 1016/j.cviu.2013.07.004. URL http://www.sciencedirect.com/science/ article/pii/S1077314213001343 . 43 S. Y u and M. Bertho d. A game strategy approach for image labeling. Computer Vision and Image Understanding , 61(1):32 – 37, 1995. Stev en W. Zuck er. Relaxation labeling: 25 years and sill iterating. In L. S. Da vis, editor, F oundations of Image Understanding , chapter 10, pages 289– 322. Kluw er Academic Publishers, Boston, 2001. A Exp erimen tal Results and Discussion for 8x8 Grids Fig. 1 summarizes our results for the most common classes of Ising mo dels con- sidered in the exp erimen tal ev aluation of approximation algorithms and heuris- tic for b elief inference in the literature as describ ed ab ov e. W e p erform hypoth- esis testing for the result in these classes of Ising mo dels using paired z-tests on the individual (i.e., not join t) differences, each with p-v alue 0 . 05. Hence, all the statemen ts are statistically significant with resp ect to such hypotesis tests. Note that there is no globally b est appro ximation tec hnique ov erall for these classes. “Mixed” case (Left plot, Fig. 1). Clearly , gs is b est for all w in this case. Among the other appro ximation algorithms, w e observe the following 1. fp (ce) is b est and b etter than bp for w = 4, indistinguishable from bp for w = 3, and w orst than bp for w = 2 where bp is best. 2. fp (ce) is consistently b etter than trw. 3. trw is worst than bp for w < 4, but b etter than bp for w = 4. 4. All metho ds, except for mf and nr, are consistently b etter than bl; mf and nr are consisten tly worst than bl, except for w = 2 where mf is indistinguishable from bl. 5. mf and nr are indistinguishable, except for w = 4 where nr is b etter than mf. “A ttractive” case (Righ t plot, Fig. 1). In this case, there is no clear o verall b est. W e also observe the following. 1. trw is best among all metho ds except for w = 2 where gs is b est, and trw is second b est. 2. fp (ce) is b etter than all other metho ds, except trw, and gs for w = 2; and bp for w < 4 where fp (ce) is indistinguishable from bp. 3. mf, nr, bp, and gs are consistently indistinguishable from bl, and from eac h other; except for w = 2 where gs is best, of course. 44 Fig. 2 summarizes our exp erimental results for a class of Ising mo dels which app ears to lead to “harder” Ising-model instances. 30 W e p erform h yp othesis testing for the result in these classes of Ising mo dels using t wo approaches de- p ending on w . F or w = 4, where we draw 50 models as samples for each q , w e use appropriately mo dified paired z-tests on the individual (i.e., not join t) differences, each with p-v alue 0 . 05. W e mo dify the calculation of the v ariances resulting from the av erage ov er the samples computed for each q . W e do so b ecause the distributional properties of the empirical mean/a verage for eac h q ma y differ. F or w < 4, where w e only dra w 5 mo dels as samples for eac h q , w e use b o otstrapped-based, individual, paired hypothesis-testing ov er each pair of aggregate differences b etw een the metho ds for each of those v alues of w ; we use 100 b o otstrap samples, and p-v alue 0 . 05 All the statements are statistically significan t with resp ect to such hypotesis tests. Aggregate results (Left plot, Fig. 2). The left-hand plot in Fig. 2 shows the aggregate results for this case. There is no clear o verall b est ov er all q . W e also observe the following. 1. fp (ce) is b est for w = 4 and w = 3, while b eing second b est to gs for w = 2; and, for w = 2 . 5, tied for b est with gs (i.e., indistinguishable from gs). 2. trw is consistently b etter than bp, mf, bl, and nr, except for w = 2 . 5 where trw is indistinguishable from bp; trw is consisten tly worst than fp (ce) 3. Only mf is worst than bl for w ∈ { 2 , 4 } ; mf is indistinguishable from bl for w ∈ { 2 . 5 , 3 } ; also, bp and nr are indistinguishable from bl, except for w = 2 . 5, where bp is b etter than bl. 4. bp is b etter than mf except for w = 2; bp is indistinguishable from nr for w ∈ { 2 , 3 } , but bp is b etter than nr for w ∈ { 2 . 5 , 4 } . 5. gs is consisten tly b etter than mf and nr; indistinguishable from trw, ex- cept, of course, for w = 2 where gs is tied for b est with fp (ce). Results for constant edge-weigh t magnitude w = 4 as a function of probability of attractiv e interaction q (Righ t plot, Fig. 2). The righ t-hand plot in Fig. 2 shows finer-grain results for this case. The results suggest that in fact such instances of Ising mo dels tend to b e harder in the sense that even state-of-the-art algorithms such as TR W are no b etter than the simple baseline estimation, in which b p i = 0 . 5 for all no des/v ariables i , for less than half of the full range of v alues of the sign probabilit y q (i.e., for q ∈ { 0 . 1 , 0 . 4 , 0 . 5 , 0 . 6 , 0 . 8 , 0 . 9 } ). In fact, the performance of TR W is almost ex- actly the same as baseline accros the range of non-extreme v alues of q . (Note 30 Such class of mo dels follows from our general experience with similar mo dels. W e find that instantiating Ising mo del parameters using densities ov er edge-weigh ts tended to yield to relatively easier mo dels than the ones we obtain b y fixing the magnitude of the edge-weigh ts and v arying the probability of their sign, indep enden tly for each edge. 45 ho w the plot of the v alues for trw and bl are essen tially on top of each other for v alues of q other than 0 or 1.) On the other hand, note how fp (ce) is con- sisten tly better than bl across the whole range of v alues for q . In fact, fp (ce) is alwa ys in the set of (statistically) best p erformers for all q : i.e., the single b est for q = 1 . 0, and indistinguishable from trw for q = 0 . 0; gs and bp for q ∈ { 0 . 1 , 0 . 5 , 0 . 6 , 0 . 7 } ; nr, gs, and bp for q = 0 . 2; gs for q ∈ { 0 . 3 , 0 . 4 , 0 . 9 } ; and gs and mf for q = 0 . 8. The prop osed fp (ce) is also b est at b oth extremes, while trw is only best when all weigh ts are negative. Almost all the metho ds other than fp (ce) are no b etter, and often worst, than bl, except for bp and trw for q = 0 . 0; trw for q ∈ { 0 . 2 , 0 . 7 , 1 . 0 } ; trw and gs for q = 0 . 3; and gs for q = 0 . 8. 46 Figure 1: Standard Ev aluation on Ising Mo dels with 8x8 and 12x12 Grids. The left and right plots are for the so-called “mixed” and “attractive” instances of Ising mo dels, respectively . F or all plots, the x-axis is the largest magnitude of the edge-weigh ts: i.e., w = max ( i,j ) ∈ E | w ij | . The y-axis is the a verage, o ver 50 randomly generated Ising mo dels, of the aver age , ov er all of the 144 v ariables, of the absolute difference b et ween the estimate and exact marginal probability for the random v ariable corresp onding to that no de, along with their corresp onding 95% confidence in terv als (CIs). The legend in eac h plot is for differen t appro ximation algorithms: bl = baseline; mf = mean field; bp = b elief propagation; trw = tree reweighed message-passing; nr = simple no-regret algorithm; gs = Gibbs sampler; mw = multiplicativ e weigh ts; and fp (ce) = the CE version of our version of the fictitious play for the 2-play er p oten tial game described in Section 3.4. W e refer the reader to the main b ody for implementation details and a thorough discussion of the results. 47 Figure 2: Ev aluation on Ising Mo dels with 8x8 and 12x12 Grids, Uniform In teraction Magnitude, and V aried Probabilit y of Attractiv e In teractions. ( L eft plots ) The x-axis, y-axis, and legend are as in Fig. 1, except the edge-w eight magnitude w is constant for each interaction strength in the x-axis (i.e., 2, 2 . 5, 3, and 4), and nr uses 10 6 iterations. F or all cases, the result is the a verage ov er all v alues of the probabilit y of attractive interaction q ∈ { 0 . 0 , 0 . 1 , . . . , 0 . 9 , 1 . 0 } , and ov er 5 Ising mo dels for eac h q ; exc ept for the case of constan t edge-w eight magnitude w = 4, in whic h case the av erage for each q is ov er 50 Ising-mo del samples. Said differen tly , the o veral a verage for the cases of w ∈ { 2 . 0 , 2 . 5 , 3 . 0 } is ov er a total of 55 Ising models, while those for the case of w = 4 is ov er a total of 550 mo dels. Note that the standard 95% CIs based on a Gaussian appro ximation resulting from the Cen tral Limit Theorem (CL T) do not directly apply here because the av erages are ov er different q v alues, each of whic h ma y hav e different distributional prop erties (e.g., differen t v ariances). F or w < 4, b ecause w e are computing the av erage marginal-error ov er every q , each based on only 5 samples, w e use the bo otstrap method to compute the 95% CIs ov er the o verall av erage for each metho d and each w , using 100 samples. F or w = 4, b ecause w e hav e 50 samples for each q , we use a properly adapted version of the standard 95% CIs which mo difies the calculation of the ov erall v ariance to account for distributional differences from each q . ( Right plots ) Results for each q v alue with w = 4, with 50 models as samples for each, along with their corresp onding individual 95% CIs computed as usual. W e refer the reader to the main b o dy for a thorough discussion. 48 Figure 3: Ev aluation on Ising Mo dels with 8x8 Grids, Uniform In- teraction Magnitude (w= 4), and V aried Probabilit y of A ttractive In teractions q : Prop ortion of Non-conv ergen t BP and TR W Runs. This plot sho ws prop ortion, along with standard individual 95% CIs, of non- con vergen t runs (y-axis) of bp (higher curv e) and trw (low er curve), as a function of the probability of attractive interaction q (x-axis) for Ising mo dels with con- stan t edge-weigh ts magnitude equal to 4. The setup is as describ ed in the right plot of Fig. 2 for the case of edge-weigh t magnitude w = 4. The proportion is out of 50 runs for eac h q ∈ { 0 , 0 . 1 , 0 . 2 , . . . , 0 . 9 , 1 } . Note how the con vergence of bp degrades when q nears 0 . 5. Note the almost symmetric effect on non- con vergence for bp. Note also that bp non-conv ergence seems uncorrelated with its p erformance, as sho wn in Fig. 2 (Righ t plot). While trw may also show non- con vergence outside non-uniform edge-weigh ts, the effect is less drastic than for bp. 49 Figure 4: Ev aluation on Ising Mo dels with 12x12 Grids, Uniform In- teraction Magnitude (w= 4), and V aried Probabilit y of A ttractive In teractions: Marginal Error of fp (ce) by Num b er of Iterations. This plot shows the marginal error of the estimates obtained by the fp algorithm, for differen t num b ers of iterations used in the algorithm. The x-axis is the n um- b er of iterations m , while the y-axis is the same as in Fig. 1 and Fig. 2. The marginal error of each run is represen ted by a circle on the graph. Each run is the result of av eraging ov er all v alues of the probabilit y of attractive interac- tion q ∈ { 0 . 0 , 0 . 1 , . . . , 0 . 9 , 1 . 0 } . The a verage marginal error is shown as a line, and is obtained from 20 randomly generated Ising mo dels and corresp onding estimates. The num b er of iterations used w ere m ∈ { 15 , 50 , 100 , 200 , 500 } . 50 Figure 5: Ev aluation on Ising Mo dels with 12x12 Grids, Multiplicative W eigh ts Algorithms. The top plots are the same as those in Fig. 1 and the b ottom plots are the same as those in Fig. 2, with the exception that only multi- plicativ e weigh ts algorithms are included in these plots (along with the baseline algorithm). The legend is as follows: m w er = external regret minimization; m w er cf = external regret minimization using a constant η = 0 . 01; mw sr = sw ap regret minimization; mw sr cf = sw ap regret minimization using a con- stan t η = 0 . 01. W e refer the reader to the main b o dy for more details regarding the implementation of these algorithms. 51 Figure 6: Ev aluation on Ising Mo dels with 12x12 Grids, Uniform In- teraction Magnitude (w= 4), and V aried Probabilit y of A ttractive In teractions: Marginal Error of trw and gs b y Num b er of Iterations. This plot shows the marginal error of the estimates obtained by the trw (top plots) and gs (b ottom plots) algorithms, for different n umbers of iterations. The axes are the same as in Fig. 4. Note that the right plots use a logarithmic scale for the num b er of iterations. The num b er of iterations used in the left plots were m ∈ { 15 , 50 , 100 , 200 , 500 } , and m ∈ { 10 2 , 10 3 , 10 4 , 10 5 } for the right plots. The marginal error of each run (circles) and the a v erage marginal error (line) were found using the same pro cedure as in Fig. 4. 52 Figure 7: Ev aluation on Ising Mo dels Deriv ed from MNIST Images, 28x28 Grids. This b o x plot compares the marginal errors of all algorithms with resp ect to gs. Because each algorithm was run on 100 image samples, eac h b o x consists of 100 av erage (o ver 28 2 = 784 v ariables) marginal errors. Data p oin ts that are more than 1.5 times the interquartile range aw ay from the median are considered outliers, and are drawn as short lines. The “whiskers” of the b oxes are drawn as long lines. 53 Figure 8: Ev aluation on Ising Models Deriv ed from MNIST Images of Handwritten Digit ”1” Only , 28x28 Grids. This b o x plot compares the marginal errors of all algorithms with resp ect to gs. Because each algorithm w as run on 100 image samples, each b o x consists of 100 av erage (ov er 28 2 = 784 v ariables) marginal errors. Data p oin ts that are more than 1.5 times the in terquartile range a wa y from the median are considered outliers, and are drawn as short lines. The “whiskers” of the boxes are drawn as long lines. 54
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment