Clustering Stream Data by Exploring the Evolution of Density Mountain
Stream clustering is a fundamental problem in many streaming data analysis applications. Comparing to classical batch-mode clustering, there are two key challenges in stream clustering: (i) Given that input data are changing continuously, how to incrementally update clustering results efficiently? (ii) Given that clusters continuously evolve with the evolution of data, how to capture the cluster evolution activities? Unfortunately, most of existing stream clustering algorithms can neither update the cluster result in real time nor track the evolution of clusters. In this paper, we propose an stream clustering algorithm EDMStream by exploring the Evolution of Density Mountain. The density mountain is used to abstract the data distribution, the changes of which indicate data distribution evolution. We track the evolution of clusters by monitoring the changes of density mountains. We further provide efficient data structures and filtering schemes to ensure the update of density mountains in real time, which makes online clustering possible. The experimental results on synthetic and real datasets show that, comparing to the state-of-the-art stream clustering algorithms, e.g., D-Stream, DenStream, DBSTREAM and MR-Stream, our algorithm can response to a cluster update much faster (say 7-15x faster than the best of the competitors) and at the same time achieve comparable cluster quality. Furthermore, EDMStream can successfully capture the cluster evolution activities.
💡 Research Summary
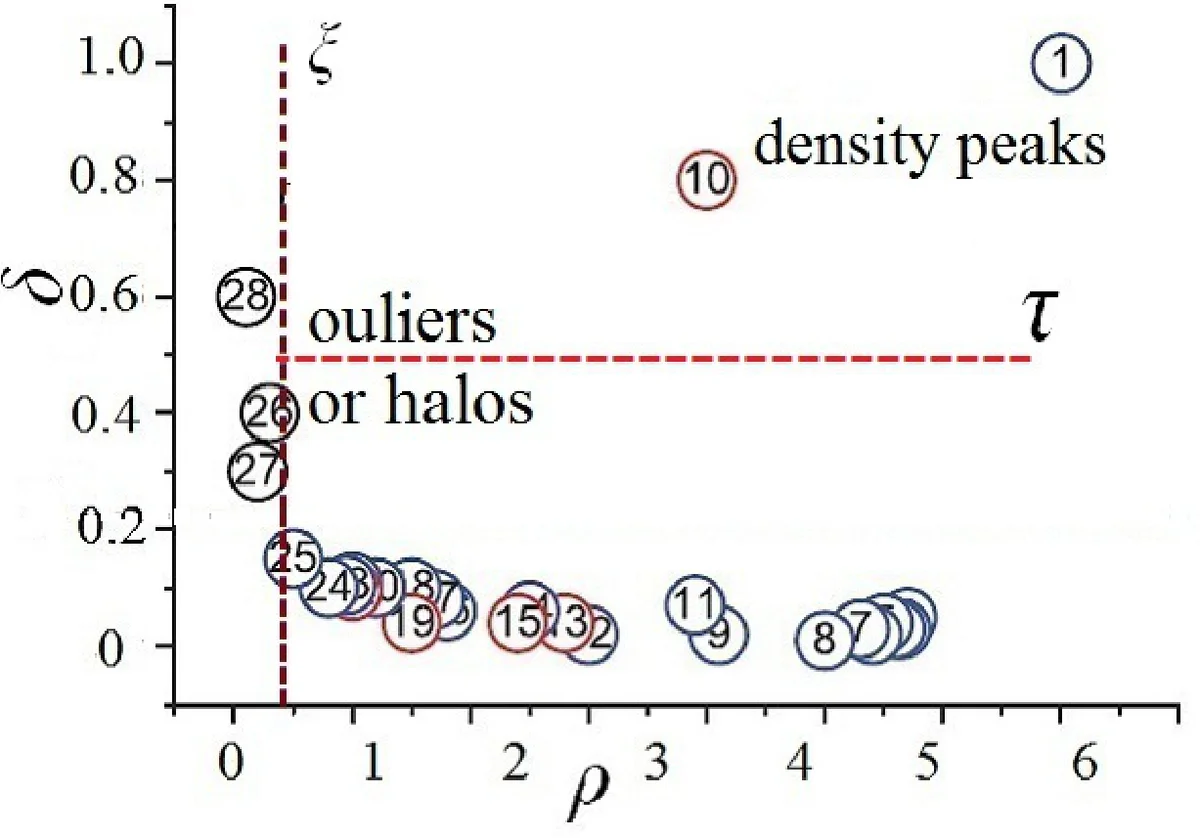
The paper introduces EDMStream, a novel stream clustering algorithm that simultaneously addresses two fundamental challenges in data‑stream mining: (i) the need for real‑time incremental updates of clustering results, and (ii) the ability to monitor and capture cluster evolution events such as splits, merges, births, and deaths. The authors build upon the Density Peaks (DP) clustering paradigm, which characterizes each data point by its local density ρ (the number of points within a cutoff distance) and its dependent distance δ (the distance to the nearest point with higher density). By visualizing the (ρ, δ) pairs as a “density mountain,” cluster centers appear as peaks with both high density and large dependent distance, while points on the slopes have smaller δ values.
To make DP clustering suitable for high‑velocity streams, the authors propose a tree‑like data structure called the Dependency‑Tree (DP‑Tree). Each node in the DP‑Tree represents a cluster‑cell—a compact group of points with similar density characteristics. A node points to its nearest higher‑density neighbor (its parent), establishing a directed dependency chain that ends at a density peak (the root). Strong dependencies (δ ≤ τ) and weak dependencies (δ > τ) are distinguished; subtrees composed solely of strong dependencies are identified as Maximal Strongly Dependent Subtrees (MSDSubTrees), each of which corresponds to a cluster.
When a new data point arrives, the algorithm immediately determines its nearest higher‑density cell, updates the cell’s ρ and δ, and inserts a new node into the DP‑Tree. Because each point depends on only one higher‑density point, the impact of an insertion is localized: only the affected node and possibly a few of its ancestors need pointer updates. Two filtering mechanisms—(1) a density‑threshold filter that discards low‑density outliers, and (2) a dependent‑distance filter that avoids unnecessary re‑linking—greatly reduce the number of tree modifications, enabling updates in microseconds.
EDMStream also incorporates a self‑adaptive component. During an initial user‑interaction phase, the system learns user preferences for clustering granularity, which are encoded as initial values for ρ and τ. As the stream evolves, the algorithm automatically adjusts these parameters based on observed changes in density distribution, allowing it to remain robust to concept drift without manual retuning.
The authors evaluate EDMStream on synthetic datasets (multi‑modal Gaussian streams with controlled drift) and real‑world streams (news articles and network traffic). Compared against four state‑of‑the‑art stream clustering methods—D‑Stream, DenStream, DBSTREAM, and MR‑Stream—EDMStream achieves 7‑15× faster cluster‑update latency (average 7–23 µs per update) while delivering comparable or slightly better clustering quality (F‑measure 0.85–0.92). Moreover, the DP‑Tree’s explicit representation of dependency chains allows precise detection of evolution events; the experiments demonstrate accurate tracking of splits, merges, and the emergence of new clusters, which the baseline methods miss or detect only after a batch re‑clustering step.
A theoretical discussion contrasts DP‑Clustering with DBSCAN. While DBSCAN relies on symmetric density‑connected graphs, DP‑Clustering uses asymmetric dependency links, yielding a hierarchical tree that is naturally amenable to incremental updates. This structural difference underlies EDMStream’s efficiency.
The paper acknowledges limitations: reliance on Euclidean distance may hinder performance in high‑dimensional or sparse streams; memory consumption grows with the number of cluster‑cells; and the quality of results still depends on the initial choice of ρ and τ, despite the adaptive scheme. Future work is suggested on extending the method to non‑Euclidean metrics, improving memory efficiency, and providing theoretical guarantees for the adaptive parameter tuning.
In summary, EDMStream offers a compelling solution for real‑time stream clustering with built‑in evolution tracking, combining the intuitive density‑mountain model with an efficient DP‑Tree structure and adaptive parameter control, and demonstrates substantial speed gains over existing approaches without sacrificing clustering accuracy.
Comments & Academic Discussion
Loading comments...
Leave a Comment