With the use of ontologies in several domains such as semantic web, information retrieval, artificial intelligence, the concept of similarity measuring has become a very important domain of research. Therefore, in the current paper, we propose our method of similarity measuring which uses the Dijkstra algorithm to define and compute the shortest path. Then, we use this one to compute the semantic distance between two concepts defined in the same hierarchy of ontology. Afterward, we base on this result to compute the semantic similarity. Finally, we present an experimental comparison between our method and other methods of similarity measuring.
Deep Dive into An enhanced method to compute the similarity between concepts of ontology.
With the use of ontologies in several domains such as semantic web, information retrieval, artificial intelligence, the concept of similarity measuring has become a very important domain of research. Therefore, in the current paper, we propose our method of similarity measuring which uses the Dijkstra algorithm to define and compute the shortest path. Then, we use this one to compute the semantic distance between two concepts defined in the same hierarchy of ontology. Afterward, we base on this result to compute the semantic similarity. Finally, we present an experimental comparison between our method and other methods of similarity measuring.
Springer International Publishing 2017
Advances in Intelligent Systems and Computing 640,
DOI 10.1007/978-3-319-64719-7
Series Volume 640, Series ISSN 2194-5357 pp. 95–107, 2017.
An enhanced method to compute the similarity between
concepts of ontology
Abdelhadi Daoui 1, Noreddine Gherabi 2 and Abderrahim Marzouk 3
13 Hassan 1st University, FSTS, IR2M Laboratory, Settat, Morocco
2 Hassan 1st University, ENSAK, LIPOSI Laboratory, Khouribga, Morocco
{abdo.daoui, gherabi}@gmail.com
amarzouk2004@yahoo.fr
Abstract. With the use of ontologies in several domains such as semantic web,
information retrieval, artificial intelligence, the concept of similarity measuring
has become a very important domain of research. Therefore, in the current pa-
per, we propose our method of similarity measuring which uses the Dijkstra’s
algorithm to define and compute the shortest path. Then, we use this one to
compute the semantic distance between two concepts defined in the same hier-
archy of ontology. Afterward, we base on this result to compute the semantic
similarity. Finally, we present an experimental comparison between our method
and other methods of similarity measuring.
Keywords: semantic web, ontologies, similarity measuring, Dijkstra’s algo-
rithm.
1
Introduction
Today, ontologies play an important role in many domains related to the semantic
Web [1], information retrieval [2], knowledge engineering [3] and knowledge man-
agement [4]. Therefore, several researches and studies have been developed or are
being done to cover this fertile area. These researches can be used in different ap-
proaches such as concepts creation, ontology design [5], classification [6], or segmen-
tation [7]. The latter is useful for the processing of large ontologies, which is difficult
to maintain, namely the addition, modification or deletion of large ontology parts.
Our work will focus on the measuring of the semantic similarity between concepts
of ontology. This one is an important concept used in different areas of research. Jef-
frey Hau, William Lee and John Darlington [8] use the semantic similarity to define
compatibility between semantic web services [9] [10] annotated by OWL ontologies
[11]. In [12] the authors present a method based on multiple information resources
(lexical taxonomy, corpus…) to measure the semantic similarity between words. The
similarity is also used in the correspondence between the shapes for example, the
authors in [13] compute the similarity between outlines of 2D shapes by using a tech-
nique based on the extracting of the shapes contours which are represented by a set of
points, then the authors describe each segment of this contours by a local and global
features, these ones will be coded in string of symbols and stored into XML files On
which the similarity calculation will be executed.
2
Series Volume 640, Series ISSN 2194-5357pp. 95–107, 2017.
Also, several techniques are proposed to compute the semantic similarity between
ontologies [14] [15]. Where, the authors, in [15] propose a new method to compute
the semantic similarity which is based on three steps. In the first the authors compute
the semantic similarity of nodes, and then they compute the semantic similarity of
relations between these nodes, at last they combine these two results to form a unified
value of semantic similarity.
There are two families of approaches to compute the semantic similarity between con-
cepts:
1. A family based on computing the geometric distance between concepts to de-
fine their semantic similarity, where the less distance gives the more similarity
[16].
2. A family based on degree of information sharing, more common information
between two concepts means more similarity [8].
The principal idea of our method is defining the shortest path between any node of
a graph (in the current paper the term graph is used to describe ontology) and the root
node. Then, we base on these shortest paths and our formula for computing the rate of
semantic similarity between the concepts of this graph.
This paper is organized as follows: in Section 2 we describe our method. The next
section presents an experimental comparison with some other methods of similarity
measuring, followed by a discussion of the changes made to the methodology. Final-
ly, the section 4 presents our conclusion.
2
Proposed method
Our method is designed to compute the semantic similarity between two concepts that
exist in the same hierarchy of ontology, where all their nodes are connected by “is-a”
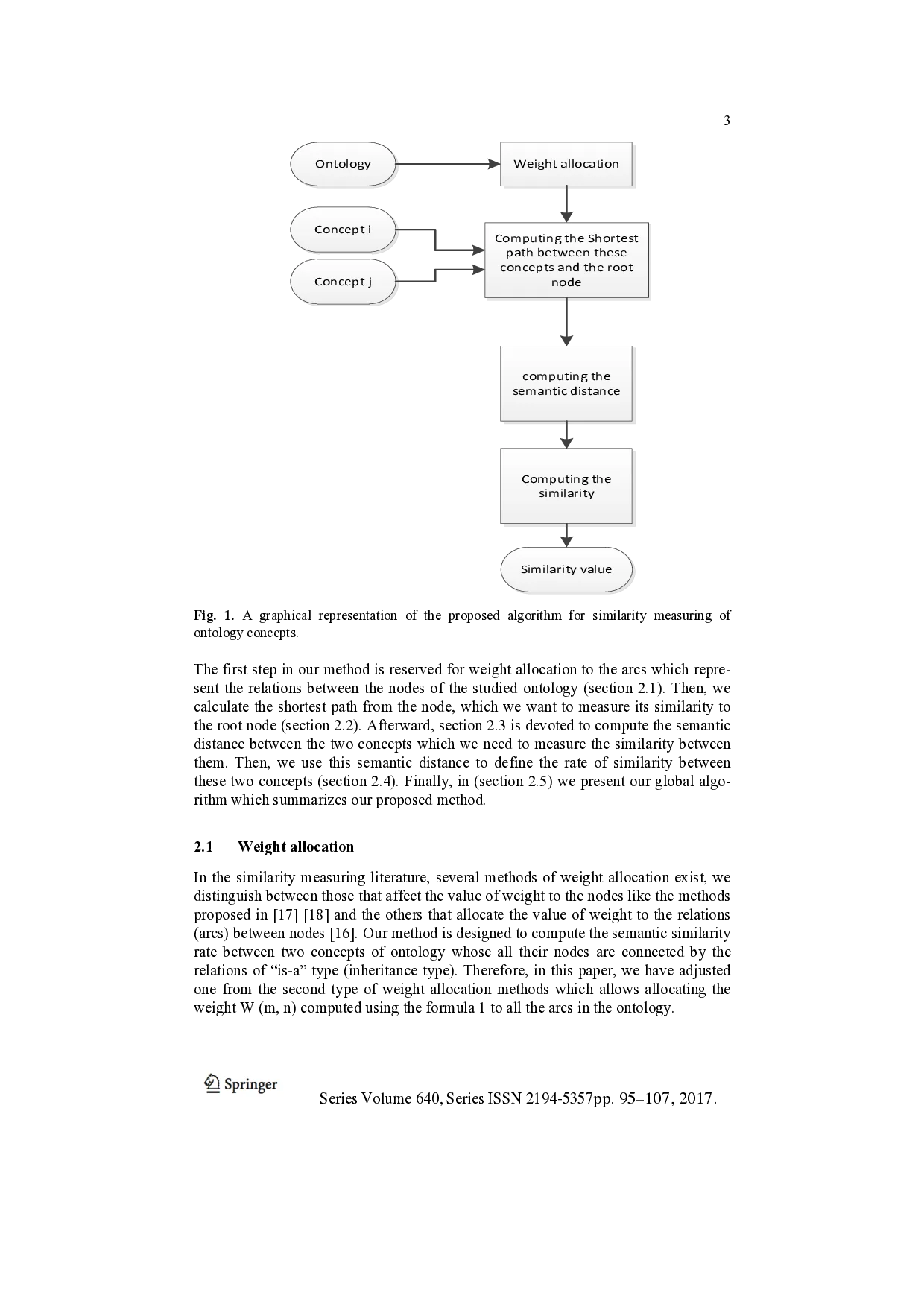
relations type. This method is summarized in the algorithm shown below in figure 1.
3
Series Volume 640, Series ISSN 2194-5357pp. 95–107, 2017.
Ontology
Concept
i
Concept
j
Weight
allocation
Computing
the
Shortest
path
between
these
concepts
and
the
root
node
computing
the
semantic
distance
Computing
the
similarity
…(Full text truncated)…
This content is AI-processed based on ArXiv data.