Unsupervised Learning of Disentangled and Interpretable Representations from Sequential Data
We present a factorized hierarchical variational autoencoder, which learns disentangled and interpretable representations from sequential data without supervision. Specifically, we exploit the multi-scale nature of information in sequential data by formulating it explicitly within a factorized hierarchical graphical model that imposes sequence-dependent priors and sequence-independent priors to different sets of latent variables. The model is evaluated on two speech corpora to demonstrate, qualitatively, its ability to transform speakers or linguistic content by manipulating different sets of latent variables; and quantitatively, its ability to outperform an i-vector baseline for speaker verification and reduce the word error rate by as much as 35% in mismatched train/test scenarios for automatic speech recognition tasks.
💡 Research Summary
The paper introduces a novel unsupervised learning framework called the Factorized Hierarchical Variational Autoencoder (FHVAE) designed specifically for sequential data such as speech. The core idea is to exploit the inherent multi‑scale nature of such data by explicitly separating information that varies slowly across an entire sequence (e.g., speaker identity, channel conditions, background noise) from information that changes rapidly within short segments (e.g., phonetic content, prosody). To achieve this, the model defines two distinct sets of latent variables: a segment‑level latent vector z₁ and a sequence‑level latent vector z₂. In addition, each sequence is associated with a global “s‑vector” μ₂ that serves as the mean of a sequence‑dependent prior distribution over z₂. The prior over z₁ is a standard isotropic Gaussian shared across all sequences, while the prior over z₂ is a Gaussian centered at μ₂, and μ₂ itself follows a zero‑mean Gaussian prior. This hierarchical prior structure forces the z₂ variables of a given sequence to cluster around a common point (μ₂), thereby encouraging them to capture attributes that are relatively constant within the sequence but vary across sequences. Conversely, z₁ is free to capture residual, rapidly varying attributes.
Because exact posterior inference is intractable, the authors adopt the variational autoencoder (VAE) framework. They propose an inference network that operates at the segment level, which dramatically improves scalability for long sequences. The inference proceeds as follows: an LSTM processes the entire segment to produce a hidden state from which the mean and variance of z₂ are predicted; a second LSTM, conditioned on the sampled z₂, processes the same segment to predict the distribution of z₁. The decoder is another LSTM that, conditioned on both z₁ and z₂, reconstructs the original acoustic frames step by step. All stochastic nodes are re‑parameterized to allow back‑propagation.
A key challenge in hierarchical VAEs is the “collapse” of the sequence‑level prior: if μ₂ were forced to zero for all sequences, the KL term would be minimized trivially and z₂ would carry no useful information. To prevent this, the authors add a discriminative objective that encourages z₂ to be predictive of the sequence index. Specifically, they maximize log p(i | z₂) where i is the sequence identifier, using a weighting factor α. The final training objective is the sum of the segment‑wise variational lower bound and the discriminative term.
The architecture is fully sequence‑to‑sequence: both encoders and the decoder are single‑layer LSTMs, with separate multilayer perceptrons (MLPs) to predict means and log‑variances. The model is trained with the Adam optimizer; hyper‑parameters and detailed architectural choices are provided in the supplementary material.
Experiments are conducted on two speech corpora. TIMIT provides clean, speaker‑balanced data (630 speakers, ~5.4 h), while Aurora‑4 offers a challenging noisy environment with multiple microphones and additive noises (clean, channel‑distorted, noisy, and channel + noise conditions). Acoustic features are 80‑dimensional Mel‑filterbank vectors (or 200‑dimensional log‑magnitude spectra for reconstruction), extracted every 10 ms. Each training sample is a 200 ms segment (20 frames), roughly the length of a syllable.
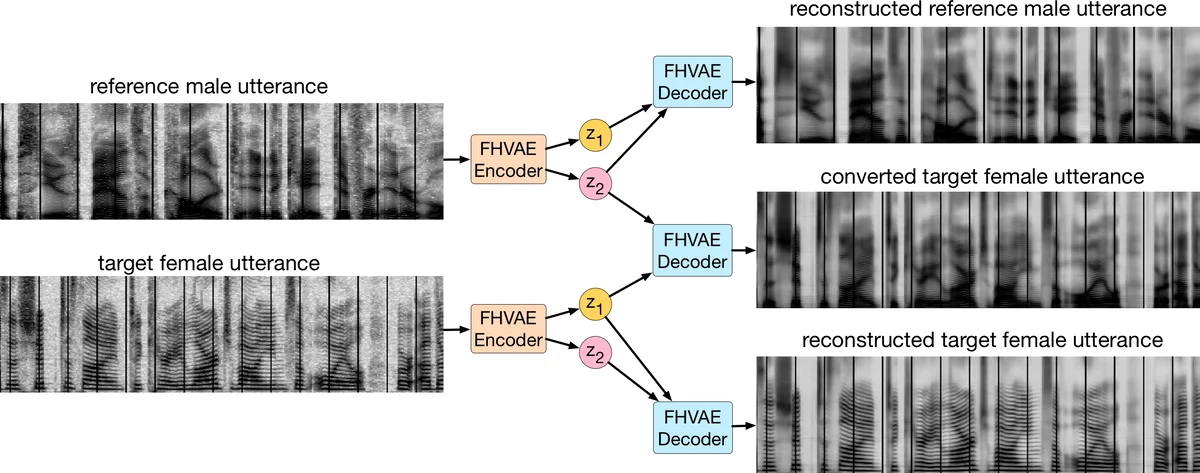
Qualitative results demonstrate that swapping z₂ between two utterances changes global attributes (speaker identity or noise level) while preserving linguistic content encoded in z₁. For example, replacing the z₂ of a noisy utterance with the z₂ of a clean utterance yields a denoised reconstruction that retains the same words. Similarly, exchanging z₂ across speakers produces convincing voice conversion.
Quantitatively, the model achieves substantial improvements over traditional i‑vector baselines. In unsupervised speaker verification, the equal error rate (EER) drops to 2.38 %; with supervised fine‑tuning it reaches 1.34 %, both better than i‑vector systems. For automatic speech recognition on Aurora‑4, incorporating the learned sequence‑level representations reduces word error rate (WER) by up to 35 % in mismatched train‑test conditions (e.g., training on clean data, testing on noisy data). These gains illustrate that the disentangled representations are useful for downstream tasks.
The authors discuss several strengths: (1) explicit multi‑scale modeling yields interpretable latent spaces; (2) the discriminative term prevents trivial solutions; (3) segment‑level training scales to long sequences; (4) the approach delivers real performance gains in speaker verification and robust ASR. They also acknowledge limitations: the current hierarchy includes only two levels (extending to session‑level or dataset‑level would increase complexity); Gaussian assumptions may limit modeling of highly non‑linear phenomena; the discriminative weight α must be tuned carefully; and experiments are confined to speech, leaving validation on video or text sequences for future work.
In conclusion, the paper presents a compelling unsupervised method for learning disentangled, interpretable representations from sequential data. By marrying hierarchical priors with a discriminative objective and a scalable sequence‑to‑sequence VAE, the authors achieve both qualitative interpretability and quantitative performance improvements, opening avenues for broader applications in multimodal time‑series analysis.
Comments & Academic Discussion
Loading comments...
Leave a Comment