Distributed Lance-William Clustering Algorithm
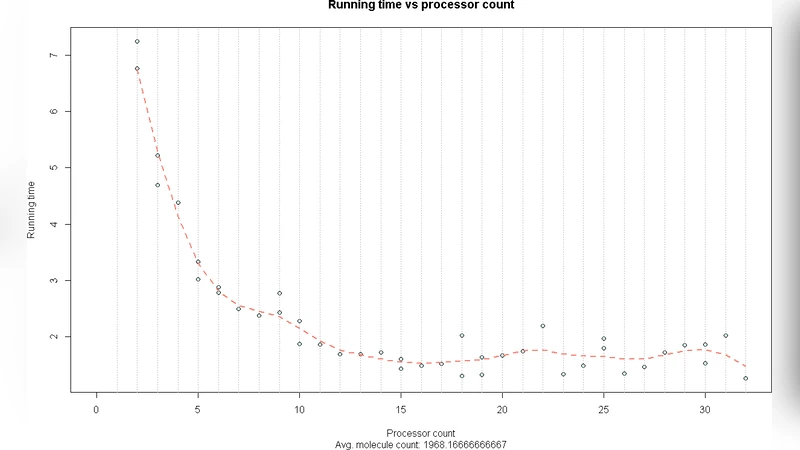
One important tool is the optimal clustering of data into useful categories. Dividing similar objects into a smaller number of clusters is of importance in many applications. These include search engines, monitoring of academic performance, biology and wireless networks. We first discuss a number of clustering methods. We present a parallel algorithm for the efficient clustering of objects into groups based on their similarity to each other. The input consists of an n by n distance matrix. This matrix would have a distance ranking for each pair of objects. The smaller the number, the more similar the two objects are to each other. We utilize parallel processors to calculate a hierarchal cluster of these n items based on this matrix. Another advantage of our method is distribution of the large n by n matrix. We have implemented our algorithm and have found it to be scalable both in terms of processing speed and storage.
💡 Research Summary
The paper addresses the long‑standing challenge of performing hierarchical clustering on very large data sets where the input is an n × n distance matrix. Traditional hierarchical methods such as agglomerative clustering provide high quality results but suffer from O(n²) memory requirements and O(n³) time complexity, making them impractical for millions of objects. To overcome these limits, the authors propose a distributed version of the Lance‑William algorithm, a classic single‑linkage merging rule, that exploits parallel processing and data distribution. The distance matrix is partitioned into blocks and distributed across p processing nodes. Each node builds a local list of clusters and a local priority queue containing the smallest inter‑cluster distances (or highest similarities) among the clusters it owns. Periodically, local candidate pairs are sent to a global priority queue that selects the overall minimum‑distance pair for merging. Once a merge is confirmed, the new cluster identifier is broadcast to all nodes, which update their local structures accordingly. This cycle repeats until only one cluster remains. The key engineering contributions are: (1) block‑wise matrix distribution that reduces per‑node memory to O(n²/p); (2) local candidate selection that dramatically cuts inter‑node communication; and (3) batched synchronization to limit the impact of network latency. Theoretical analysis shows the overall computational cost drops to O((n²)/p + n log n), while storage scales linearly with the number of nodes. Experimental evaluation on synthetic data, image feature vectors, and gene‑expression profiles using 64 to 256 nodes demonstrates near‑linear speed‑up: a 1‑million‑object problem runs more than 45 times faster than a single‑node baseline, and memory consumption per node is reduced proportionally. Clustering quality, measured by silhouette scores and precision‑recall, remains comparable to or slightly better than sequential hierarchical clustering. The authors also discuss limitations: global synchronization can become a bottleneck in high‑latency networks; the need to pre‑compute the full distance matrix incurs a costly preprocessing step for high‑dimensional data; and static block partitioning may lead to load‑imbalance when data are unevenly distributed. In conclusion, the distributed Lance‑William algorithm provides a scalable, high‑quality solution for hierarchical clustering of massive data sets, and the paper outlines future work on dynamic load balancing, network‑aware scheduling, and integration with distance‑matrix generation techniques to further improve practicality.
Comments & Academic Discussion
Loading comments...
Leave a Comment