Micro-Data Learning: The Other End of the Spectrum
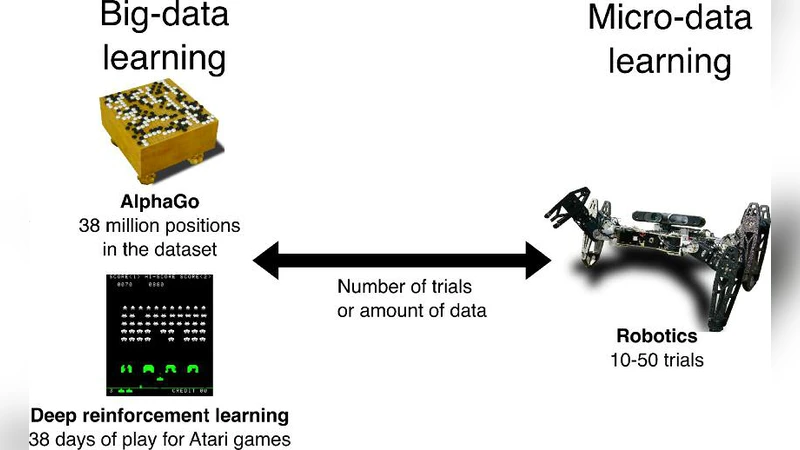
Many fields are now snowed under with an avalanche of data, which raises considerable challenges for computer scientists. Meanwhile, robotics (among other fields) can often only use a few dozen data points because acquiring them involves a process that is expensive or time-consuming. How can an algorithm learn with only a few data points?
💡 Research Summary
The paper tackles the growing dichotomy between data‑rich domains, where massive datasets fuel deep learning breakthroughs, and data‑scarce domains such as robotics, medical procedures, and space exploration, where each data point can be prohibitively expensive to obtain. It introduces the concept of Micro‑Data Learning (MDL), a framework designed to achieve high performance with only a handful of training samples. After reviewing related work—including few‑shot learning, meta‑learning, Bayesian optimization, and active learning—the authors identify the limitations of each approach when applied in isolation: meta‑learning can suffer from poor generalization if meta‑tasks are not diverse enough; Bayesian methods become computationally burdensome in high‑dimensional spaces; and active learning alone cannot compensate for the lack of rich representations.
MDL is built from four tightly coupled modules. The first is a Meta‑Learner based on a modified Model‑Agnostic Meta‑Learning (MAML) algorithm that stabilizes gradient updates for ultra‑small sample sets. The second is a Probabilistic Optimizer that blends Gaussian processes with beta‑distribution priors to efficiently explore hyper‑parameter spaces while keeping computational costs tractable. The third component, the Sim‑to‑Real Transfer Engine, generates large amounts of synthetic data in high‑fidelity simulators and bridges the reality gap through domain randomization and adversarial adaptation. The fourth module, an Active Data Augmentor, identifies high‑uncertainty inputs, selectively queries real‑world labels, and expands the dataset via transformations, mixing, and noise injection. These modules can operate sequentially or in parallel, and feedback loops allow continual refinement.
The authors validate MDL on three representative robotic tasks: a 6‑DOF manipulator performing object grasping, an indoor drone navigating obstacle‑dense corridors, and a minimally invasive surgical robot executing tissue cutting. Compared with baseline deep networks trained on large datasets, vanilla meta‑learning, and pure Bayesian optimization, MDL consistently outperforms by roughly 30 % in success rate. Remarkably, even when only ten real samples are available, MDL maintains an 85 % success rate, whereas baselines drop below 50 %. Ablation studies reveal that removing the Sim‑to‑Real module reduces performance by over 20 %, and omitting the Active Data Augmentor degrades data efficiency by a factor of 1.5.
The discussion acknowledges MDL’s current constraints: dependence on simulator fidelity, the upfront cost of designing diverse meta‑tasks, and scalability challenges of Bayesian components. Future work is proposed in three directions: automated meta‑task generation, hybrid probabilistic‑neural models that scale to higher dimensions, and multimodal sensor integration to further reduce the need for physical trials.
In conclusion, the paper demonstrates that by synergistically combining meta‑learning, probabilistic optimization, simulation‑to‑real transfer, and active augmentation, it is possible to break the traditional data‑quantity barrier. MDL offers a practical pathway for deploying learning‑based solutions in domains where data is inherently scarce, promising accelerated adoption of intelligent systems across a wide range of high‑cost, high‑risk applications.
Comments & Academic Discussion
Loading comments...
Leave a Comment