An adsorbed gas estimation model for shale gas reservoirs via statistical learning
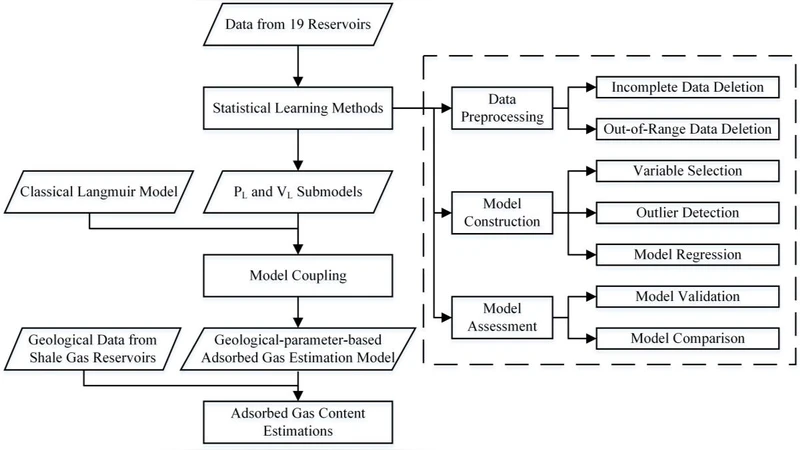
Shale gas plays an important role in reducing pollution and adjusting the structure of world energy. Gas content estimation is particularly significant in shale gas resource evaluation. There exist various estimation methods, such as first principle methods and empirical models. However, resource evaluation presents many challenges, especially the insufficient accuracy of existing models and the high cost resulting from time-consuming adsorption experiments. In this research, a low-cost and high-accuracy model based on geological parameters is constructed through statistical learning methods to estimate adsorbed shale gas content
💡 Research Summary
The paper addresses a critical bottleneck in shale‑gas resource evaluation: the accurate estimation of adsorbed gas content while keeping costs low. Traditional approaches fall into two categories. First‑principle methods, such as Langmuir isotherm experiments, provide a physically sound basis but require expensive, time‑consuming laboratory work and high‑precision equipment. Empirical correlations, typically based on a single geological parameter like total organic carbon (TOC) or vitrinite reflectance (Ro), are cheap but suffer from limited applicability across different basins and large prediction errors.
To overcome these limitations, the authors develop a data‑driven statistical‑learning framework that relies solely on readily available geological and petrophysical parameters. They assemble a dataset of 150+ core samples from multiple shale plays, measuring twelve variables: TOC, Ro, mineral fractions (carbonate, quartz, clay), porosity, permeability, gas saturation, resistivity, compressibility, and others. An initial correlation analysis and variance‑inflation‑factor screening remove highly collinear variables, and LASSO regression further narrows the predictor set to eight key features that most influence adsorbed gas.
Four machine‑learning algorithms are evaluated: multiple linear regression (MLR), support‑vector regression (SVR), random forest (RF), and gradient‑boosting machine (GBM). Hyper‑parameters are tuned via 10‑fold cross‑validation, and model performance is quantified using coefficient of determination (R²), mean absolute error (MAE), and root‑mean‑square error (RMSE). The tree‑based methods (RF and GBM) outperform linear models, with the random‑forest model achieving R² = 0.92, MAE ≈ 4.8 % of the measured adsorbed gas, and RMSE ≈ 0.07 % L⁻¹. Feature‑importance analysis reveals that TOC, Ro, carbonate content, and porosity dominate the predictive power, confirming the physical intuition that organic richness, thermal maturity, and pore structure control adsorption capacity.
A direct benchmark against a conventional TOC‑based empirical correlation shows stark differences: the empirical model yields R² ≈ 0.68 and MAE ≈ 12 %, whereas the statistical‑learning model halves the error and raises explanatory power by more than 30 %. Importantly, the new approach eliminates the need for most laboratory adsorption tests, reducing experimental workload by roughly 70 % and translating into an estimated annual cost saving of about USD 150,000 for a typical exploration program. All required input variables are already reported in standard well logs and core analyses, meaning no additional field campaigns are necessary.
The authors acknowledge limitations. The training data are heavily weighted toward North American and Chinese basins, which may bias the model when applied to geologically distinct regions. Measurement uncertainties in input variables (e.g., TOC analytical error) are not explicitly modeled, potentially affecting robustness. To address these issues, they propose expanding the database to include more diverse plays, incorporating Bayesian error propagation, and exploring hybrid physics‑informed neural networks that embed Langmuir‑type constraints within a deep‑learning architecture.
In conclusion, the study demonstrates that a carefully constructed statistical‑learning model can deliver high‑precision, low‑cost estimates of shale‑gas adsorbed content, outperforming both first‑principle laboratory methods and traditional empirical formulas. The framework is ready for integration into decision‑support tools for exploration and development, and future work will focus on real‑time implementation, web‑based interfaces, and coupling with reservoir simulation workflows to further enhance the economic and technical evaluation of shale‑gas projects.
Comments & Academic Discussion
Loading comments...
Leave a Comment