Supervised and Unsupervised Speech Enhancement Using Nonnegative Matrix Factorization
Reducing the interference noise in a monaural noisy speech signal has been a challenging task for many years. Compared to traditional unsupervised speech enhancement methods, e.g., Wiener filtering, supervised approaches, such as algorithms based on hidden Markov models (HMM), lead to higher-quality enhanced speech signals. However, the main practical difficulty of these approaches is that for each noise type a model is required to be trained a priori. In this paper, we investigate a new class of supervised speech denoising algorithms using nonnegative matrix factorization (NMF). We propose a novel speech enhancement method that is based on a Bayesian formulation of NMF (BNMF). To circumvent the mismatch problem between the training and testing stages, we propose two solutions. First, we use an HMM in combination with BNMF (BNMF-HMM) to derive a minimum mean square error (MMSE) estimator for the speech signal with no information about the underlying noise type. Second, we suggest a scheme to learn the required noise BNMF model online, which is then used to develop an unsupervised speech enhancement system. Extensive experiments are carried out to investigate the performance of the proposed methods under different conditions. Moreover, we compare the performance of the developed algorithms with state-of-the-art speech enhancement schemes using various objective measures. Our simulations show that the proposed BNMF-based methods outperform the competing algorithms substantially.
💡 Research Summary
This paper addresses the long‑standing problem of single‑channel speech enhancement in noisy environments by introducing two novel approaches built on a Bayesian formulation of non‑negative matrix factorization (BNMF). The first approach, termed BNMF‑HMM, integrates BNMF with a hidden Markov model (HMM) to simultaneously classify the type of environmental noise and compute a minimum‑mean‑square‑error (MMSE) estimator for the clean speech signal. By treating the speech and each possible noise class as separate BNMF models and using the HMM state‑dependent output densities, the system can infer the most probable noise class directly from the noisy observation, eliminating the need for a pre‑trained noise model or a separate voice‑activity detector. The second approach, called Online‑BNMF, extends BNMF to a causal, online learning framework where the noise dictionary is updated frame‑by‑frame from the noisy mixture itself. Starting with a fixed speech dictionary, the algorithm iteratively refines the noise basis vectors using the posterior estimates of the noise activation coefficients, thereby adapting to non‑stationary or previously unseen noise types in real time.
Both methods employ the Itakura‑Saito divergence as the data‑fitting term and adopt conjugate gamma priors for the basis and activation matrices, which yields analytically tractable EM update rules. An SNR‑dependent prior is also introduced to improve robustness across a wide range of signal‑to‑noise ratios.
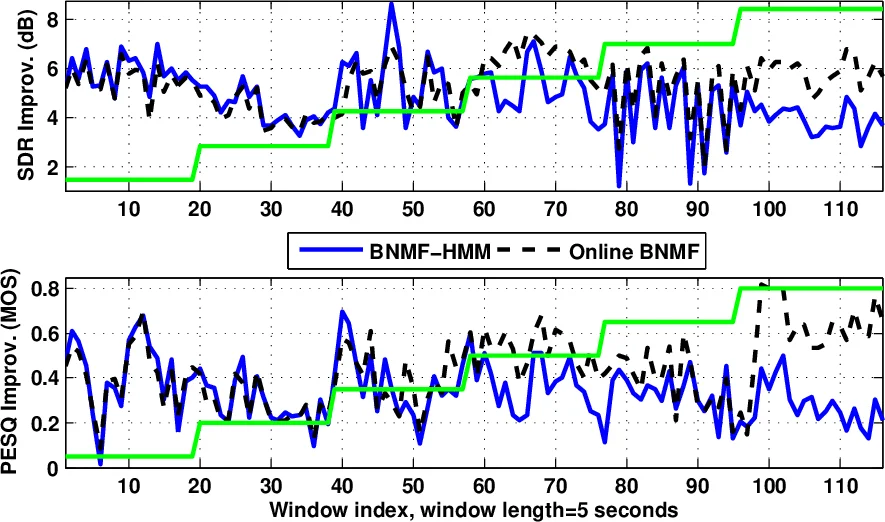
Experimental evaluation uses TIMIT speech mixed with several noise types (white, engine, babble) over SNRs from –5 dB to 20 dB. Objective metrics—PESQ, STOI, and SDR—show that BNMF‑HMM consistently outperforms conventional Wiener filtering, standard HMM‑based enhancement, and earlier NMF‑based schemes, achieving average SDR gains of 0.3–0.5 dB and noticeable improvements in perceived quality. The online variant matches the performance of batch NMF while offering real‑time operation and lower memory requirements. Notably, in challenging conditions where speech and noise spectra overlap (e.g., babble noise), the Bayesian priors effectively separate the two sources, leading to substantial quality gains.
The paper’s contributions are fourfold: (1) a comprehensive review of state‑of‑the‑art NMF‑based speech enhancement; (2) a BNMF framework that embeds temporal dynamics via hierarchical priors; (3) the BNMF‑HMM architecture that removes the need for prior noise classification; and (4) a causal online dictionary learning scheme that adapts to unknown noise on the fly. The authors conclude that the Bayesian perspective not only mitigates the mismatch between training and testing conditions but also provides a principled way to incorporate temporal dependencies and online adaptation, making the proposed methods highly suitable for practical applications such as hearing aids, mobile communications, and real‑time speech‑recognition front‑ends. Future work is suggested to explore extensions to multi‑channel recordings, integration with deep neural network priors, and low‑power hardware implementations.
Comments & Academic Discussion
Loading comments...
Leave a Comment