PersonaBank: A Corpus of Personal Narratives and Their Story Intention Graphs
We present a new corpus, PersonaBank, consisting of 108 personal stories from weblogs that have been annotated with their Story Intention Graphs, a deep representation of the fabula of a story. We describe the topics of the stories and the basis of the Story Intention Graph representation, as well as the process of annotating the stories to produce the Story Intention Graphs and the challenges of adapting the tool to this new personal narrative domain We also discuss how the corpus can be used in applications that retell the story using different styles of tellings, co-tellings, or as a content planner.
💡 Research Summary
The paper introduces PersonaBank, a newly compiled corpus of 108 personal narratives harvested from weblogs and annotated with Story Intention Graphs (SIGs), a deep, multi‑layer representation of a story’s fabula. The authors first describe the motivation: personal blogs publish hundreds of thousands of everyday stories that reveal people’s activities, goals, emotions, and social interactions, yet there is a lack of structured resources for computational analysis of such informal narratives. To fill this gap, they adapt the SIG formalism—originally used for classic fables in the DramaBank project—to the domain of personal narratives.
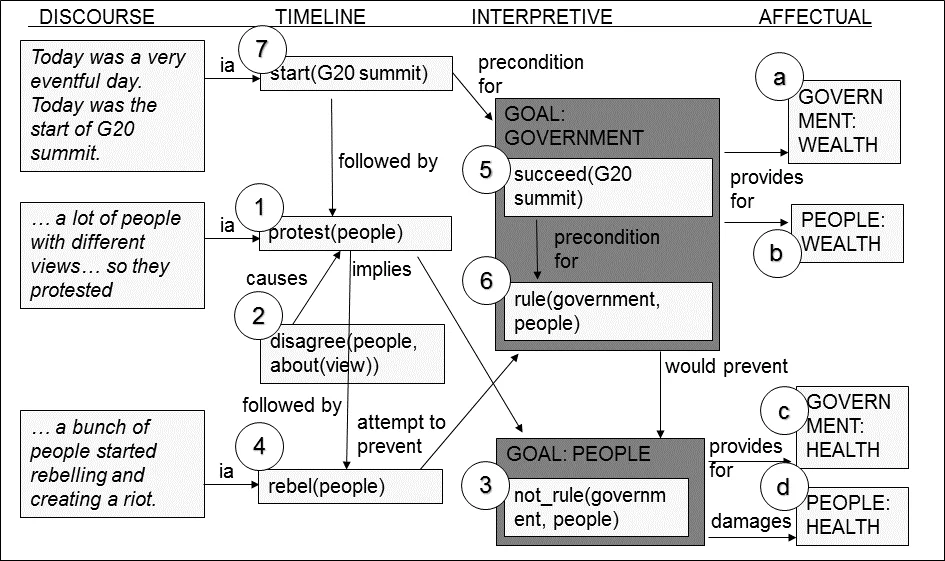
SIG consists of four layers: (1) the surface text, (2) the timeline layer that encodes events as predicate‑argument propositions ordered temporally, (3) the interpretive layer that captures agents’ goals, plans, attempts, outcomes, and causal relations (e.g., “attempt”, “goal”, “precondition”, “prevent”), and (4) the affectual layer that marks the emotional impact of events on characters. By separating these dimensions, SIG can represent not only what happens but also why it happens and how it feels, enabling content‑based comparison across stories irrespective of stylistic variation.
The corpus construction pipeline begins with the Spinn3r dataset. Using a set of seed lexical items for each target topic (e.g., “tree”, “garden”, “snow”), the authors retrieve candidate stories, then manually filter them for relevance, coherence, clear temporal ordering, non‑offensive content, and a single identifiable narrator (the first‑person voice). They balance the collection with 55 positive‑tone and 53 negative‑tone stories. The final set spans a wide thematic range: health, weather, wildlife, activities, sports, holidays/family, romance, everyday events, technology, pets, and work. Story lengths average 269 words (range 104–959). Twenty‑one stories have a fully annotated interpretive layer; the rest contain only timeline and affectual information.
Annotation is performed with Scheherazade, a freely available graphical tool originally built for DramaBank. Scheherazade leverages VerbNet and WordNet to present annotators with sense inventories and semantic role slots. Annotators first define characters (including the narrator) and props, then highlight text spans and map them to predicate‑argument structures, thereby constructing the timeline layer. The tool follows a “what‑you‑see‑is‑what‑you‑mean” (WYSIWYM) paradigm: as each proposition is entered, the system generates a natural‑language realization, allowing annotators to verify correctness instantly. For example, the sentence “20 of the leaders of the world come together to talk about how to run their governments” is encoded as two nested propositions: meet(group of leaders) and in‑order‑to(talk about running(the group of countries)). The generated sentence “The group of leaders meet in order to talk about running the group of countries” is displayed for confirmation.
Adapting Scheherazade to personal narratives presented several challenges. Personal stories often contain rich descriptive language, metaphor, and implicit causal links that are not directly expressed. To mitigate this, annotators are instructed to read the entire narrative first, identify core events, goals, and outcomes, and ignore peripheral details. The authors also refined the set of interpretive relations (e.g., adding “prevent” to capture interruptions like a startled squirrel) and clarified guidelines for handling ambiguous or missing causal information.
The paper discusses multiple downstream applications. Because SIG abstracts away surface style, the same graph can be fed to the built‑in generator to produce retellings in different registers (formal, informal, narrative, expository) or to support co‑telling scenarios where multiple agents contribute to a shared story. SIG can also serve as a content planner for story generation systems, enabling controlled manipulation of plot elements while preserving logical coherence. Moreover, the corpus can be used for computational narrative analysis, such as clustering stories by underlying goal structures, studying affective trajectories, or training models that map raw text to deep semantic representations.
In conclusion, PersonaBank provides the first large‑scale, publicly available resource that bridges informal personal narratives and a formal, computable story representation. By coupling the robust SIG formalism with an accessible annotation interface, the authors demonstrate that non‑expert annotators can reliably encode complex narrative information. This resource opens avenues for research at the intersection of narrative theory, natural language understanding, and generation, and sets a foundation for extending deep story representations to diverse languages and cultural contexts.
Comments & Academic Discussion
Loading comments...
Leave a Comment