Parallel solver for shifted systems in a hybrid CPU-GPU framework
This paper proposes a combination of a hybrid CPU–GPU and a pure GPU software implementation of a direct algorithm for solving shifted linear systems $(A - \sigma I)X = B$ with large number of complex shifts $\sigma$ and multiple right-hand sides. Such problems often appear e.g. in control theory when evaluating the transfer function, or as a part of an algorithm performing interpolatory model reduction, as well as when computing pseudospectra and structured pseudospectra, or solving large linear systems of ordinary differential equations. The proposed algorithm first jointly reduces the general full $n\times n$ matrix $A$ and the $n\times m$ full right-hand side matrix $B$ to the controller Hessenberg canonical form that facilitates efficient solution: $A$ is transformed to a so-called $m$-Hessenberg form and $B$ is made upper-triangular. This is implemented as blocked highly parallel CPU–GPU hybrid algorithm; individual blocks are reduced by the CPU, and the necessary updates of the rest of the matrix are split among the cores of the CPU and the GPU. To enhance parallelization, the reduction and the updates are overlapped. In the next phase, the reduced $m$-Hessenberg–triangular systems are solved entirely on the GPU, with shifts divided into batches. The benefits of such load distribution are demonstrated by numerical experiments. In particular, we show that our proposed implementation provides an excellent basis for efficient implementations of computational methods in systems and control theory, from evaluation of transfer function to the interpolatory model reduction.
💡 Research Summary
The paper addresses the computational bottleneck that arises when solving a large number of shifted linear systems of the form ((A-\sigma I)X = B) with many complex shifts (\sigma) and multiple right‑hand sides. Such systems appear in control‑theoretic tasks such as transfer‑function evaluation, interpolatory model reduction (e.g., IRKA), and the computation of (structured) pseudospectra. The authors propose a two‑phase direct algorithm that exploits a hybrid CPU–GPU architecture.
In the first phase the matrix pair ((A,B)) is reduced to a controller‑Hessenberg form: (A) becomes an (m)-Hessenberg matrix (zero entries below the (m)-th sub‑diagonal) and (B) becomes upper‑triangular. This reduction proceeds in a blocked fashion. The matrix is divided into column panels; each panel is further split into mini‑panels of width (m). Householder reflectors are generated on the CPU for each panel, while the trailing‑matrix updates are performed concurrently on the GPU using high‑performance BLAS‑3 kernels (cuBLAS). The reduction and update steps are overlapped, minimizing idle time on both devices. The QR factorization of (B) and the final orthogonal similarity transformations involving the small matrices (Q_B) and (Q_A) are kept on the CPU to avoid unnecessary data movement.
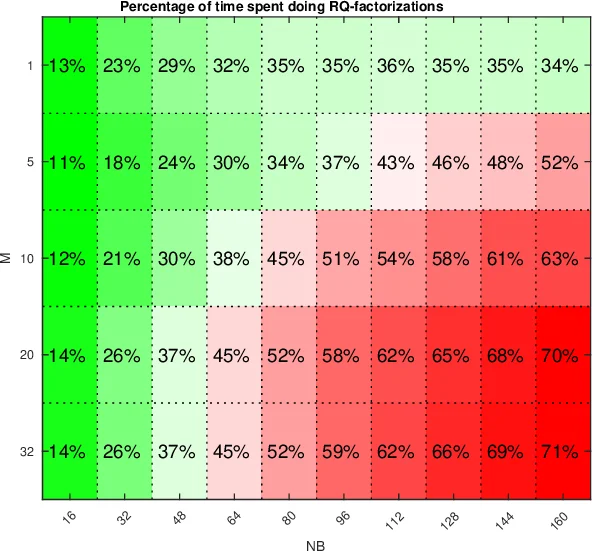
The second phase solves the shifted systems that are now of the form ((\tilde A - \sigma I)^{-1}\tilde B), where (\tilde A) is (m)-Hessenberg and (\tilde B) is triangular. Shifts are processed in batches that fit into GPU memory. For each batch the algorithm annihilates the (m) sub‑diagonals of all shifted matrices simultaneously. This requires many small RQ factorizations; each is carried out by a distinct thread block, while the bulk of the matrix updates again relies on cuBLAS. Consequently, thousands of shifts can be solved in parallel, with the computational cost dominated by highly optimized matrix‑multiply operations.
The authors integrate the solver into the IRKA algorithm, where each iteration demands the solution of (2r) shifted systems. Numerical experiments on matrices of size up to (n=10^4) with (m) up to a few hundred and several thousand shifts demonstrate speed‑ups of 5–10× over the best CPU‑only implementation and up to 30× when the GPU performance approaches that of a dense DGEMM. The paper also reports favorable scaling when the number of shifts grows, confirming that the batch‑processing strategy effectively utilizes GPU resources.
Implementation details include a two‑level blocking scheme, careful layout of data in column‑major order for cuBLAS compatibility, and the use of asynchronous streams to overlap data transfers with computation. The authors note that the orthogonal matrices (Q_B) and (Q_A) cancel out in the final solution, so they need not be stored, further reducing memory pressure.
In conclusion, the work delivers a practical, high‑performance direct solver for large families of shifted linear systems. By combining a CPU‑driven reduction to a controller‑Hessenberg form with a GPU‑centric batch solver, the method achieves near‑DGEMM performance on modern heterogeneous platforms. The authors suggest that extensions to multi‑GPU systems and further kernel‑level optimizations for complex arithmetic could broaden the applicability to even larger problems in scientific computing and control engineering.
Comments & Academic Discussion
Loading comments...
Leave a Comment