Human Uncertainty and Ranking Error -- The Secret of Successful Evaluation in Predictive Data Mining
One of the most crucial issues in data mining is to model human behaviour in order to provide personalisation, adaptation and recommendation. This usually involves implicit or explicit knowledge, either by observing user interactions, or by asking users directly. But these sources of information are always subject to the volatility of human decisions, making utilised data uncertain to a particular extent. In this contribution, we elaborate on the impact of this human uncertainty when it comes to comparative assessments of different data mining approaches. In particular, we reveal two problems: (1) biasing effects on various metrics of model-based prediction and (2) the propagation of uncertainty and its thus induced error probabilities for algorithm rankings. For this purpose, we introduce a probabilistic view and prove the existence of those problems mathematically, as well as provide possible solution strategies. We exemplify our theory mainly in the context of recommender systems along with the metric RMSE as a prominent example of precision quality measures.
💡 Research Summary
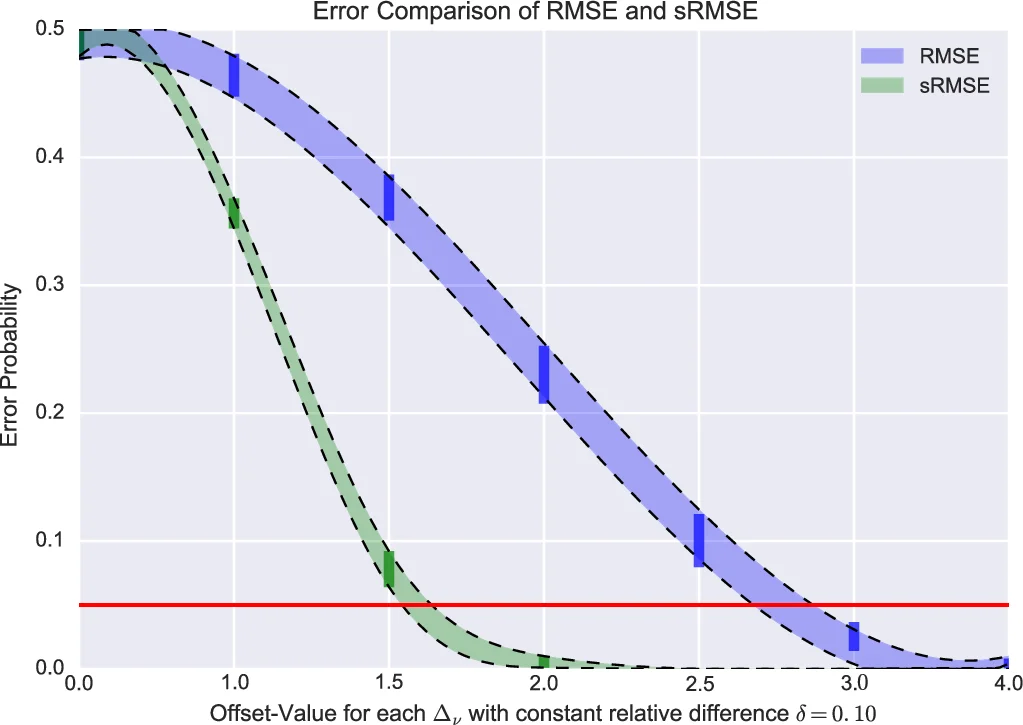
The paper addresses a fundamental yet often overlooked source of error in predictive data‑mining evaluation: the inherent volatility of human decisions, which the authors term “human uncertainty.” By treating each user‑item rating as a random variable drawn from an individual probability distribution (typically modeled as a Gaussian with mean μ and variance σ²), the authors demonstrate that common performance metrics such as RMSE, MAE, or MAP are themselves random quantities rather than fixed point estimates.
First, the authors review empirical evidence that users frequently give inconsistent ratings when asked to evaluate the same item at different times. In a user study involving repeated ratings of theatrical trailers, only 35 % of participants provided identical scores across repetitions; the remainder used two or more rating categories. This variability motivates the shift from a “point‑paradigm” (single deterministic score) to a “distribution‑paradigm” (full probability distribution) for any human‑derived measurement.
The core technical contribution is a probabilistic framework for propagating this uncertainty through evaluation metrics. For a recommender system, the RMSE can be expressed as
\
Comments & Academic Discussion
Loading comments...
Leave a Comment