A Deep Learning Approach for Joint Video Frame and Reward Prediction in Atari Games
Reinforcement learning is concerned with identifying reward-maximizing behaviour policies in environments that are initially unknown. State-of-the-art reinforcement learning approaches, such as deep Q-networks, are model-free and learn to act effectively across a wide range of environments such as Atari games, but require huge amounts of data. Model-based techniques are more data-efficient, but need to acquire explicit knowledge about the environment. In this paper, we take a step towards using model-based techniques in environments with a high-dimensional visual state space by demonstrating that it is possible to learn system dynamics and the reward structure jointly. Our contribution is to extend a recently developed deep neural network for video frame prediction in Atari games to enable reward prediction as well. To this end, we phrase a joint optimization problem for minimizing both video frame and reward reconstruction loss, and adapt network parameters accordingly. Empirical evaluations on five Atari games demonstrate accurate cumulative reward prediction of up to 200 frames. We consider these results as opening up important directions for model-based reinforcement learning in complex, initially unknown environments.
💡 Research Summary
The paper tackles a central challenge in model‑based reinforcement learning (RL): learning both the dynamics of a high‑dimensional visual environment and its reward function from raw pixel data. While model‑free approaches such as Deep Q‑Networks (DQNs) achieve impressive performance on Atari games, they require massive amounts of interaction data and cannot exploit an explicit model for planning or efficient exploration. Conversely, model‑based methods are data‑efficient but traditionally assume that the transition and reward models are either known or can be learned from low‑dimensional state representations.
To bridge this gap, the authors extend the video‑frame‑prediction network introduced by Oh et al. (2015) so that it simultaneously predicts the next game screen and the immediate reward. The original architecture consists of three stages: (1) an encoder that compresses the last four grayscale frames (84 × 84) into a latent vector, (2) a transformation that incorporates the current action (one‑hot encoded) via element‑wise multiplication with the latent vector, and (3) a decoder that deconvolves the action‑conditioned latent representation back into a full‑resolution frame.
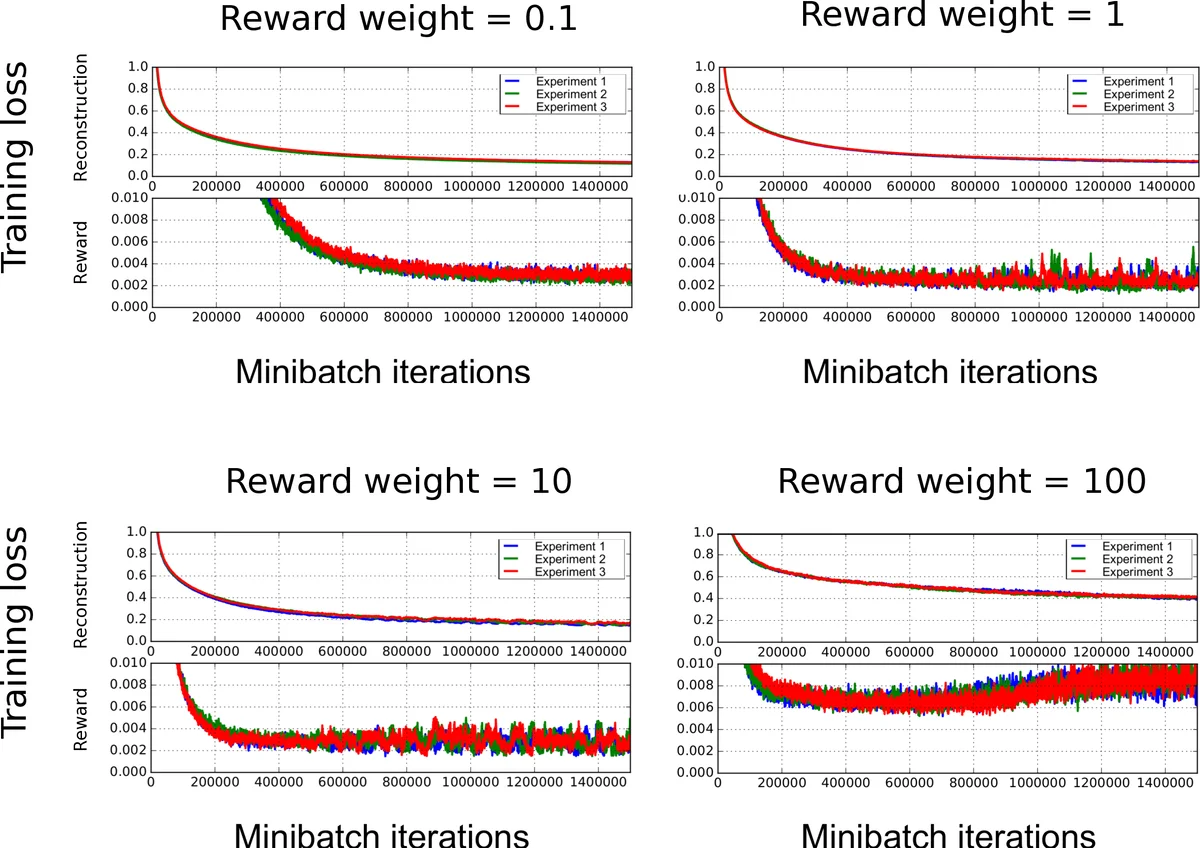
The extension adds a soft‑max output branch on top of the action‑conditioned latent vector to predict the clipped reward (‑1, 0, +1) as a three‑class one‑hot vector. Training now minimizes a joint loss: an L2 reconstruction term for the predicted frame and a cross‑entropy term for the reward prediction, weighted by a hyper‑parameter λ. The loss is summed over K‑step unrolled predictions, enabling the network to be trained for multi‑step ahead forecasting. A curriculum learning schedule gradually increases K, allowing the model to first master short‑term predictions before tackling longer horizons.
The authors collect trajectories from DQN agents that have already been trained on five Atari games (Q*bert, Seaquest, Freeway, Ms. Pac‑Man, Space Invaders). Each trajectory provides sequences of frames, actions, and clipped rewards. During training, the network receives the four‑frame history and the current action, and it is asked to predict both the next frame and the reward. The evaluation focuses on cumulative reward prediction: for each test trajectory the model rolls out its own predictions up to 100 steps (and up to 200 steps in some analyses) and compares the summed predicted rewards to the true cumulative reward. A baseline that samples rewards from the marginal distribution observed in the test set is used for comparison.
Results show that the joint model dramatically outperforms the baseline across all games. The median cumulative‑reward error remains low for at least 20 steps and stays competitive even at 100–200 steps, indicating that the latent representation captures reward‑relevant dynamics. Qualitative visualizations (e.g., in Seaquest) demonstrate that predicted frames remain faithful to the true game screen, and the reward branch correctly signals events such as enemy kills or life loss.
Key contributions are:
- Unified architecture that predicts both visual dynamics and immediate reward from the same latent state, eliminating the need for separate models.
- Joint optimization that forces the latent space to retain reward‑relevant features that would otherwise be ignored by a pure frame‑reconstruction loss.
- Empirical evidence that accurate long‑horizon cumulative reward prediction (up to ~200 frames) is feasible, opening the door to model‑based RL techniques such as Dyna‑style planning or Monte‑Carlo Tree Search in high‑dimensional visual domains.
The paper also discusses limitations. The current pipeline still reconstructs full frames before using them for planning, which can be computationally expensive; a future “shortcut” model that predicts the next latent state directly would be more efficient. Moreover, the approach relies on reward clipping to a ternary signal; extending it to environments with continuous or more complex reward structures will require additional research.
Overall, the work demonstrates that a single deep convolutional network can learn a compact, reward‑aware representation of Atari game dynamics, providing a practical stepping stone toward data‑efficient, model‑based reinforcement learning in visually rich, initially unknown environments.
Comments & Academic Discussion
Loading comments...
Leave a Comment