Emotion Detection on TV Show Transcripts with Sequence-based Convolutional Neural Networks
While there have been significant advances in detecting emotions from speech and image recognition, emotion detection on text is still under-explored and remained as an active research field. This paper introduces a corpus for text-based emotion detection on multiparty dialogue as well as deep neural models that outperform the existing approaches for document classification. We first present a new corpus that provides annotation of seven emotions on consecutive utterances in dialogues extracted from the show, Friends. We then suggest four types of sequence-based convolutional neural network models with attention that leverage the sequence information encapsulated in dialogue. Our best model shows the accuracies of 37.9% and 54% for fine- and coarse-grained emotions, respectively. Given the difficulty of this task, this is promising.
💡 Research Summary
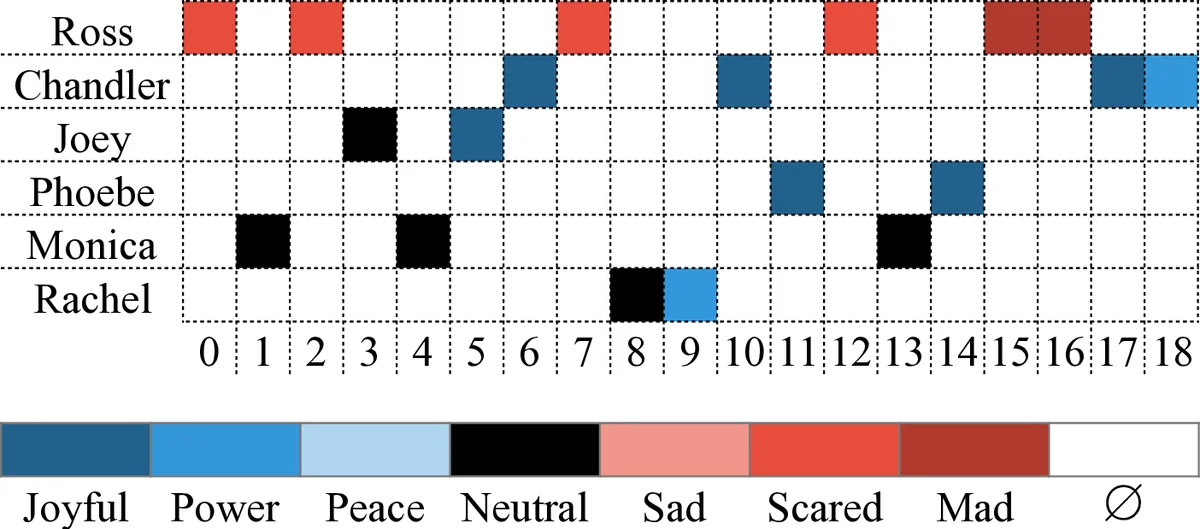
The paper addresses the under‑explored problem of detecting emotions from textual dialogue, particularly in multiparty settings. To fill the gap of annotated resources, the authors construct a new corpus from the first four seasons of the popular TV sitcom “Friends.” The corpus contains 12,606 utterances drawn from 97 episodes and 897 scenes, each labeled with one of seven emotions (sad, mad, scared, powerful, peaceful, joyful, neutral). Annotation was performed via Amazon Mechanical Turk, with four crowd workers labeling each utterance. Because emotion perception is highly subjective, inter‑annotator agreement measured by Cohen’s and Fleiss’ kappa was low (≈14 %). However, partial agreement (any pair of annotators agreeing) reached 85 %, prompting the authors to adopt a voting‑and‑ranking scheme that assigns gold labels to 75.5 % of the data deterministically and resolves the remainder by selecting the annotator with the lowest least‑absolute‑error (LAE).
Statistical analysis shows a skewed distribution: neutral and joyful together account for over half of the utterances, reflecting the comedic nature of the show. When emotions are collapsed into three coarse categories (positive, negative, neutral), the distribution becomes more balanced (≈40 % positive, 30 % negative, 30 % neutral). A confusion matrix reveals that the dominant classes cause most misclassifications, while minority emotions such as sad, powerful, and peaceful exhibit higher diagonal agreement.
The core technical contribution is a set of four sequence‑based convolutional neural network (SCNN) architectures that explicitly incorporate the temporal order of utterances. Traditional CNNs excel at extracting n‑gram features but ignore sequential dependencies. To overcome this, the authors propose two primary ways of “sequence unification.”
-
SCNN‑c (concatenation) – After a standard 2‑D convolution and max‑pooling on the current utterance, the resulting dense vector is concatenated with the vectors of the previous k‑1 utterances (column‑wise). A subsequent 1‑D convolution fuses these stacked features, allowing the model to learn how past emotional context influences the current prediction.
-
SCNN‑v (convolution) – This variant runs two parallel 2‑D convolutions: Conv1 processes the current utterance as in a normal CNN, while Conv2 receives a matrix formed by stacking the dense vectors of the current and previous utterances. Conv2’s filters operate across the temporal dimension, capturing patterns in the emotion sequence. The outputs of Conv1 and Conv2 are concatenated and fed into another 1‑D convolution, producing a fused representation.
Both architectures are extended with attention mechanisms that weight static word embeddings against dynamically generated convolutional features. This attention learns how much the current utterance should rely on its own lexical cues versus the contextual cues from preceding utterances.
Experiments employ 5‑fold cross‑validation and compare the proposed SCNN models against a baseline CNN that treats each utterance independently. Results show consistent improvements: SCNN‑c and SCNN‑v raise fine‑grained (7‑class) accuracy by 3–5 percentage points and coarse‑grained (positive/negative/neutral) accuracy by 4–6 percentage points. The best performing model, SCNN‑v with attention, achieves 37.9 % accuracy on the seven‑class task and 54 % on the three‑class task. These figures, while modest, are notable given the difficulty of inferring emotion from text alone and the limited size of the dataset.
The authors discuss several limitations. The low kappa scores reflect the inherent subjectivity of emotion annotation, and the class imbalance (dominance of neutral and joyful) may bias learning. Moreover, the transcripts contain slang, humor, and metaphor, which challenge standard word‑embedding representations. The paper suggests future work incorporating multimodal cues (audio, visual) to improve annotation reliability, expanding the emotion label set (e.g., 37 fine‑grained emotions), and exploring more sophisticated sequence models such as Transformers.
In summary, this work makes three key contributions: (1) releasing a sizable, publicly available dialogue‑level emotion corpus; (2) introducing sequence‑aware CNN architectures that effectively leverage conversational context; and (3) demonstrating that attention‑augmented SCNNs outperform traditional CNN baselines on both fine‑ and coarse‑grained emotion classification tasks. The study provides a valuable benchmark for future research on text‑only emotion detection in conversational settings.
Comments & Academic Discussion
Loading comments...
Leave a Comment