When rule-based models need to count
Rule-based modelers dislike direct enumeration of cases when more efficient means of enumeration are available. We present an extension of the Kappa language which attaches to agents a notion of level. We detail two encodings that are more concise than the former practice.
💡 Research Summary
The paper addresses a well‑known scalability problem in rule‑based modeling languages such as Kappa: when a biological entity possesses multiple identical internal states (for example, a protein with several phosphorylation sites), the naïve approach is to enumerate every possible combination of those states as separate rewrite rules. This leads to an exponential blow‑up in the number of rules as the number of levels (or sites) increases, making models cumbersome to write, read, and simulate.
To mitigate this, the authors propose an extension to the Kappa language that introduces an explicit “level” or counter attached to agents. The extension adds syntax for declaring counters with an upper bound, testing counter values (equality, greater‑than, and in one encoding also less‑than), and modifying counters (increment, decrement, or direct assignment). Moreover, the level can be referenced in rule rates, allowing kinetic parameters to depend on the current counter value.
Two concrete encodings of counters are presented.
-
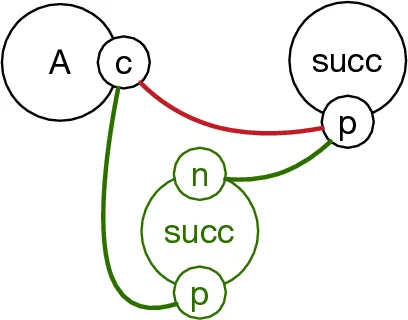
Unary Numbers Encoding – A new agent type
succwith two sites (pandn) is used to build a linear chain ofsuccagents. A counter value k is represented by a chain of length k + 1. An agent that carries a counter has an extra site that binds to the head of this chain. Equality is tested by checking for a chain of exactly k + 1succagents; “greater‑than” is tested by checking that at least k + 1 agents are present, ignoring the state of the lastsucc. Incrementing the counter inserts a newsuccat the front of the chain, decrementing removes the firstsucc. Because the chain length grows linearly with the counter value, the number of generated rules is linear in the declared upper bound, avoiding the exponential explosion of the naïve approach. The authors note a practical issue: when an agent is deleted, its attachedsuccchain becomes orphaned. They propose a “infinite‑speed” cleanup rule that deletes freesuccagents, but this adds a layer of operational complexity. -
Rule Encoding – Here each
succagent has a third siteathat other agents use to bind. An agent’s counter value is determined by whichsuccin the chain it is attached to via sitea. The chain direction (defined by distinctpandnsites) allows the modeler to test “equal”, “greater‑than”, and also “less‑than” by inspecting the length of the chain below or above the attachment point. Increment and decrement are implemented by “sliding” the attachment along the chain. This encoding provides richer comparison operations but increases the state space because each agent must maintain a fixed number ofsuccconnections, leading to higher memory consumption.
Both encodings achieve a linear rule blow‑up compared with the exponential blow‑up of explicit enumeration, and they improve model readability. However, the current Kappa simulator only understands plain Kappa syntax, so a preprocessing step translates the user‑level model with counters into an expanded Kappa model before simulation, and a post‑processing step translates simulation results back into the user’s counter‑based representation. This translation incurs overhead and complicates user feedback (e.g., dumping the current system state).
The authors discuss two main drawbacks of their approach. First, the creation and destruction of succ agents incurs memory management costs, especially for large upper bounds. Second, because the simulator works on the expanded model, static detection of counter overflow is not built‑in; the modeler must declare an upper bound and ensure that no rule can increase a counter beyond it. The paper suggests that static analysis based on interval arithmetic could detect potential overflows, but for now they rely on dynamic watchdog rules that raise alarms if a counter site becomes free or a succ chain grows too long.
In the conclusion, the authors emphasize that while the counter extension is “fairly trivial” to implement, it has already simplified several Kappa models used by the development team. Future work includes implementing native counter support in the KaSim simulator to eliminate the translation layer, and developing static analysis tools to automatically verify that declared counter bounds are respected. They also hint at possible optimizations for managing succ chains more efficiently.
Overall, the paper makes a clear contribution: it formalizes a level/counter mechanism for Kappa, provides two concrete encodings with trade‑offs, demonstrates how they reduce rule explosion, and outlines the practical challenges that remain for robust, high‑performance simulation of rule‑based models with counting semantics.
Comments & Academic Discussion
Loading comments...
Leave a Comment