Corral Framework: Trustworthy and Fully Functional Data Intensive Parallel Astronomical Pipelines
Data processing pipelines represent an important slice of the astronomical software library that include chains of processes that transform raw data into valuable information via data reduction and analysis. In this work we present Corral, a Python framework for astronomical pipeline generation. Corral features a Model-View-Controller design pattern on top of an SQL Relational Database capable of handling: custom data models; processing stages; and communication alerts, and also provides automatic quality and structural metrics based on unit testing. The Model-View-Controller provides concept separation between the user logic and the data models, delivering at the same time multi-processing and distributed computing capabilities. Corral represents an improvement over commonly found data processing pipelines in Astronomy since the design pattern eases the programmer from dealing with processing flow and parallelization issues, allowing them to focus on the specific algorithms needed for the successive data transformations and at the same time provides a broad measure of quality over the created pipeline. Corral and working examples of pipelines that use it are available to the community at https://github.com/toros-astro.
💡 Research Summary
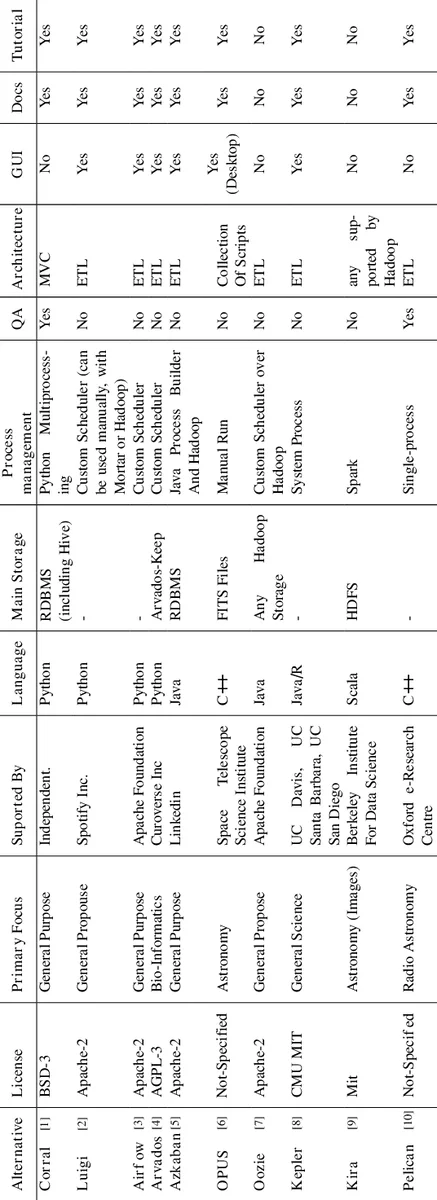
The paper presents Corral, an open‑source Python framework designed to simplify the creation, execution, and quality assurance of astronomical data processing pipelines. Modern astronomical facilities generate petabyte‑scale data streams that must be ingested, transformed, and stored with high reliability and speed. Existing pipeline tools such as Luigi, OPUS, and Kira address distribution or workflow definition, but they often lack a unified architecture that cleanly separates data models from processing logic and provides built‑in quality metrics.
Corral adopts the Model‑View‑Controller (MVC) design pattern and reinterprets its components for pipeline use: Model defines the relational database schema (via SQLAlchemy) that holds raw inputs, intermediate products, and final results; Step (derived from Controllers) implements the actual data transformations, including a single Loader that seeds the pipeline; Alert (derived from Views) records events, warnings, and errors, enabling automated monitoring and recovery. By storing all intermediate state in a relational database, Corral guarantees transactional consistency across parallel processes and makes the pipeline inherently reproducible.
Parallelism is achieved through Python’s multiprocessing module. Each Step class can be instantiated as an independent process; steps that have no data dependencies are automatically executed concurrently, exploiting multi‑core CPUs and, when configured, distributed clusters that share the same database backend (SQLite for single‑node, PostgreSQL or Hive for larger installations). This design eliminates the need for the developer to manage thread pools, locks, or inter‑process communication manually.
A central contribution of Corral is its built‑in quality‑assurance subsystem. The framework encourages the use of the standard unittest library; after test execution it computes code coverage percentages, highlighting untested code paths. It also integrates profiling tools to collect CPU, memory, and I/O statistics, and it runs style‑checkers to count deviations from a prescribed coding standard, providing a quantitative maintainability score. These metrics are automatically gathered for each pipeline run and can be stored alongside processing results for later audit.
The authors describe the implementation details: Python 3 serves as the language base, leveraging the extensive scientific ecosystem (NumPy, SciPy, AstroPy, etc.). SQLAlchemy abstracts the underlying SQL dialect, allowing seamless migration between SQLite, PostgreSQL, or Hadoop‑based solutions. The framework is released under a BSD‑3 license and hosted on GitHub, where documentation, tutorials, and several example pipelines are provided.
A concrete case study is the TOROS (Transient Optical Robotic Observatory of the South) project, which operates a robotic telescope at 4,600 m altitude in a remote location with limited network connectivity. TOROS required an on‑site pipeline capable of ingesting raw images, performing bias/dark/flat correction, source extraction, and transient candidate identification, all while being tolerant to hardware failures. By employing Corral, the team built a fully automated workflow that runs on a modest multi‑core server, stores all intermediate products in a local PostgreSQL instance, and generates alerts for any processing anomalies. The system demonstrated reliable performance during the O1 LIGO observing run and is slated for deployment on the upcoming wide‑field telescope at Cerro Macón.
In a comparative analysis (see Appendix B), Corral is shown to outperform peer frameworks in three key dimensions: (1) a clear MVC‑derived separation of concerns that eases code maintenance; (2) native support for database‑backed state management, enabling reproducibility and easy inspection; (3) integrated quality‑metric collection (unit‑test coverage, profiling, style compliance) without external tooling.
The paper concludes by outlining future work: extending the framework to support more complex directed‑acyclic‑graph (DAG) workflows, adding plug‑in mechanisms for custom resource managers, and exploring cloud‑native deployment options (e.g., Kubernetes). Corral thus positions itself as a robust, extensible foundation for next‑generation astronomical pipelines that demand both high performance and rigorous software quality.
Comments & Academic Discussion
Loading comments...
Leave a Comment