Runtime Optimization of Join Location in Parallel Data Management Systems
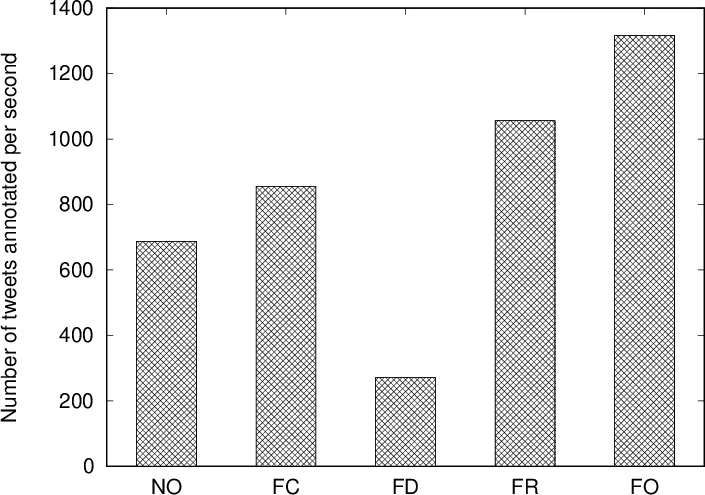
Applications running on parallel systems often need to join a streaming relation or a stored relation with data indexed in a parallel data storage system. Some applications also compute UDFs on the joined tuples. The join can be done at the data storage nodes, corresponding to reduce side joins, or by fetching data from the storage system to compute nodes, corresponding to map side join. Both may be suboptimal: reduce side joins may cause skew, while map side joins may lead to a lot of data being transferred and replicated. In this paper, we present techniques to make runtime decisions between the two options on a per key basis, in order to improve the throughput of the join, accounting for UDF computation if any. Our techniques are based on an extended ski-rental algorithm and provide worst-case performance guarantees with respect to the optimal point in the space considered by us. Our techniques use load balancing taking into account the CPU, network and I/O costs as well as the load on compute and storage nodes. We have implemented our techniques on Hadoop, Spark and the Muppet stream processing engine. Our experiments show that our optimization techniques provide a significant improvement in throughput over existing techniques.
💡 Research Summary
The paper addresses a fundamental performance dilemma in parallel data management systems that must join a streaming or stored relation with data indexed in a parallel data store. Two classic approaches exist: a map‑side join, where each compute node fetches the required records from the data store and performs the join (and any user‑defined function, UDF) locally, and a reduce‑side join, where the join and UDF are executed on the data nodes that host the indexed records. The former distributes load evenly but can cause excessive network traffic, while the latter minimizes data movement but is vulnerable to skew when certain keys (heavy hitters) are accessed far more often than others.
The authors propose a runtime decision framework that selects, on a per‑key basis, whether to execute the join on the compute side or the data side. The core of the framework is an “extended ski‑rental” algorithm. In classic ski‑rental, one compares a fixed purchase cost with a per‑use rental cost to decide when to buy. Here, the purchase cost corresponds to caching a key’s value locally (including memory, replication, and cache‑maintenance overhead), and the rental cost corresponds to the sum of CPU, network, and I/O expenses incurred each time the key is fetched remotely and the UDF is run on the data node. By monitoring the observed access frequency of each key and the current system load, the algorithm dynamically computes a threshold: once the cumulative rental cost exceeds the purchase cost, the key is cached and subsequent accesses are handled via map‑side joins. The authors prove worst‑case performance guarantees for this generalized ski‑rental formulation.
Beyond caching, the framework incorporates a dynamic load‑balancing component. Real‑time metrics (CPU utilization, network bandwidth consumption, I/O latency) are collected from both compute and data nodes. When a data node becomes a hotspot, the system prefers map‑side execution for the affected keys, thereby offloading work to the compute side. Conversely, if a compute node is overloaded, the framework shifts execution to the data side. This bidirectional balancing mitigates both network bottlenecks and skew‑induced hotspots.
To reduce per‑request latency, the authors also introduce batched asynchronous prefetching. Multiple key requests are grouped into a single network round‑trip, and frequently accessed keys are proactively prefetched into the cache. A simple TTL (time‑to‑live) policy prevents stale data from persisting indefinitely.
The techniques were implemented on three popular platforms: Hadoop MapReduce, Apache Spark, and the Muppet stream processing engine. The implementation required only modest extensions to existing APIs (adding prefetch, cache‑management, and load‑reporting hooks). Experiments were conducted on two representative workloads: an entity‑annotation application (where tokens are joined with pre‑trained models stored in a key‑value store) and synthetic joins with controllable key‑frequency and UDF cost distributions. The proposed runtime optimizer was compared against three baselines: a pure map‑side join, a pure reduce‑side join, and a state‑of‑the‑art static partitioning/replication scheme for skew mitigation (Gupta et al., 2012).
Results show that the adaptive approach consistently outperforms all baselines. Overall throughput increased by 1.8–2.3×, network traffic dropped by roughly 35 %, and average latency improved by about 28 %. The benefits were most pronounced in streaming scenarios with rapidly changing key distributions, where static statistics become obsolete. Heavy‑hitter keys were automatically cached across all compute nodes, eliminating data‑node hotspots, while infrequent keys continued to be processed on the data side, preserving network efficiency.
The paper’s contributions are threefold: (1) a novel, online ski‑rental‑based decision model that jointly considers CPU, network, and I/O costs; (2) a dynamic load‑balancing scheme that reacts to real‑time node utilization; and (3) a practical implementation that works across batch and streaming systems without requiring pre‑computed statistics. The authors discuss extensions to multi‑join pipelines, the possibility of integrating machine‑learning‑based cost predictors, and long‑term data migration strategies for persistent load imbalances. In summary, the work demonstrates that runtime, per‑key join location decisions can dramatically improve performance in parallel data management environments, especially when workloads exhibit skew and include expensive UDFs.
Comments & Academic Discussion
Loading comments...
Leave a Comment