DICE Fault Injection Tool
In this paper, we describe the motivation, innovation, design, running example and future development of a Fault Inject Tool (FIT). This tool enables controlled causing of cloud platform issues such as resource stress and service or VM outages, the purpose being to observe the subsequent effect on deployed applications. It is being designed for use in a DevOps workflow for tighter correlation between application design and cloud operation, although not limited to this usage, and helps improve resiliency for data intensive applications by bringing together fault tolerance, stress testing and benchmarking in a single tool.
💡 Research Summary
The paper presents the DICE Fault Injection Tool (FIT), a lightweight, cloud‑agnostic utility designed to deliberately introduce failures at both the virtual‑machine (VM) and cloud‑infrastructure levels in order to evaluate the resilience of data‑intensive applications. The authors begin by motivating the need for systematic fault injection: modern big‑data and IoT workloads run on complex, multi‑tenant cloud platforms where hardware, network, and software failures are inevitable. Traditional tools such as Netflix’s Chaos Monkey are limited to specific providers (e.g., AWS) and focus mainly on VM termination, while other research prototypes suffer from high resource consumption, complex configuration, or lack of extensibility.
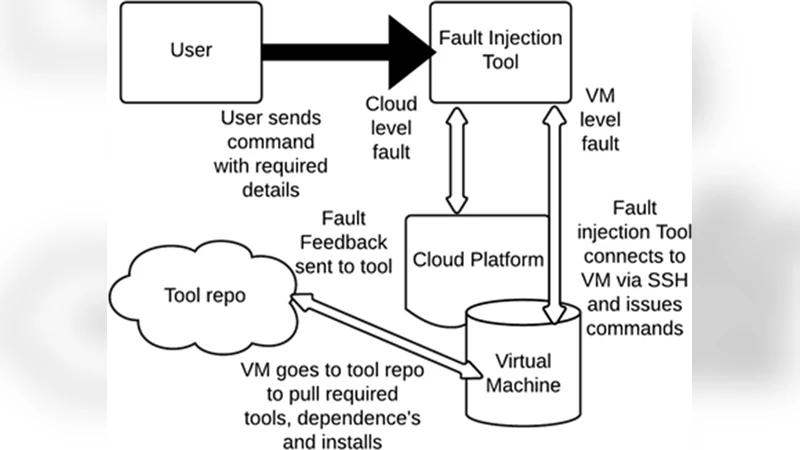
FIT addresses these gaps by offering a command‑line interface (CLI) that can be invoked from any CI/CD pipeline, using SSH (via the Java JSCH library) to connect to target VMs. Once connected, the tool automatically detects the operating system (supported Ubuntu 14.04, 15.10 and CentOS 7) and installs the minimal set of stress utilities required (e.g., memtester, stress‑ng). It then executes a range of fault scenarios: CPU saturation, memory exhaustion, high‑disk‑I/O, bandwidth throttling, service shutdown, and full VM or node termination. The tool distinguishes two privilege levels—Cloud Admin and VM Admin—allowing operators to inject faults either across an entire node cluster or on individual VMs, respectively. This role‑based model helps maintain security in multi‑tenant environments while providing fine‑grained control over test scope.
The design emphasizes extensibility: FIT is released under the permissive Apache 2.0 license, and its architecture separates the CLI, SSH handling, OS detection, tool installation, and fault‑execution modules. This modularity enables future developers to add new fault types, support additional operating systems, or integrate with other cloud APIs without rewriting the core. Table 1 in the paper enumerates the supported operations for each access level, illustrating the breadth of possible experiments.
A concrete running example demonstrates memory‑stress injection. The user issues a single CLI command specifying SSH credentials and a 2 GB memory load. FIT connects to the target VM, installs memtester if absent, and runs it to saturate the allocated memory. Monitoring tools capture the resulting near‑100 % RAM utilization, confirming that the fault was successfully induced and observable in real time. This experiment validates FIT’s ability to reproduce realistic resource‑contention scenarios with minimal manual setup.
In the conclusion, the authors outline future work: extending FIT to containerized environments (e.g., Docker, Kubernetes) to assess microservice‑level impacts, integrating with the CACTOS project to trigger application‑level faults that invoke optimization algorithms, and adding support for additional cloud providers’ APIs. They also plan to evaluate the performance overhead of fault injection, explore more complex topologies, and investigate security implications of exposing fault‑injection capabilities in production‑grade clouds.
Overall, the DICE Fault Injection Tool fills a notable gap in the DevOps toolbox by providing a simple, open‑source, and provider‑agnostic means to stress‑test cloud infrastructures and the applications that depend on them. Its design facilitates seamless incorporation into continuous integration and deployment pipelines, enabling developers and operators to discover resilience weaknesses early, quantify the effect of specific failures, and ultimately deliver more robust, fault‑tolerant services.
Comments & Academic Discussion
Loading comments...
Leave a Comment