Dimensionality Reduction of Collective Motion by Principal Manifolds
While the existence of low-dimensional embedding manifolds has been shown in patterns of collective motion, the current battery of nonlinear dimensionality reduction methods are not amenable to the analysis of such manifolds. This is mainly due to th…
Authors: Kelum Gajamannage, Sachit Butail, Maurizio Porfiri
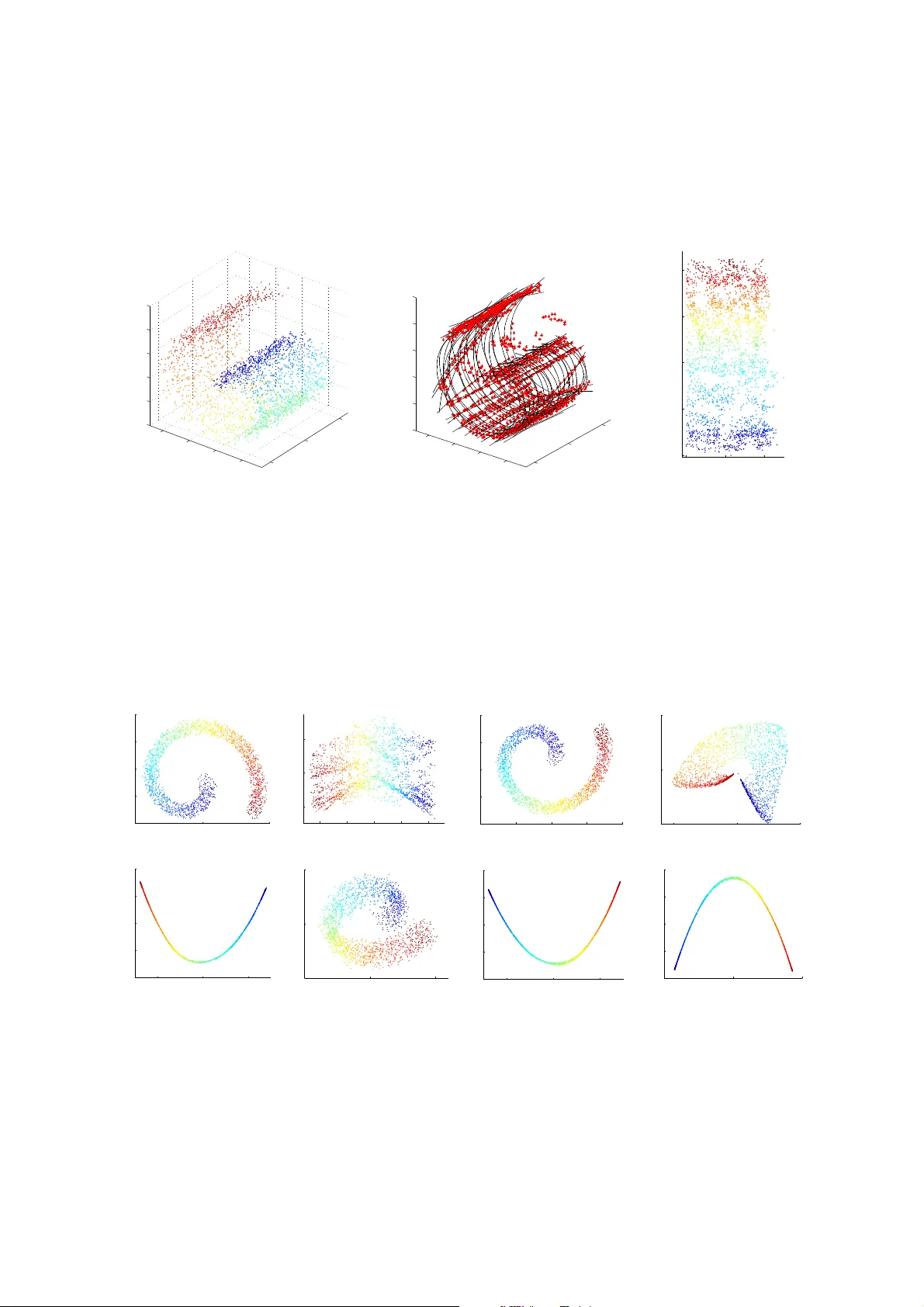
Dimensionality Reduction of Collecti ve Moti on b y Principal Manifolds Kelum Gajamannag e a , Sachit Butail b , Maurizio Porfiri b , Erik M. Bollt a, ∗ a Department of Mathemat ics, Clarkson University , P otsdam, NY -13699, USA . b Department of Mec hanical and Aer ospace Engineering, New Y ork Univer sity P olytec hnic School of Engineerin g, B r ooklyn, NY -11201, USA. Abstract While the existence of lo w-dimensio nal embedd ing manifo lds has been shown in pattern s of collective motion, the current battery of non linear dimen sionality reduction meth ods are not amen able to th e ana lysis of such manif olds. This is ma inly due to the necessary spectral d ecompo sition step, wh ich limits con trol over th e mapping fro m the original high -dimen sional space to the em beddin g spac e. Here, we propo se an alternative approach that demands a two-dimensional embedd ing which topolo gically summariz es the high -dimension al data. In this sense, ou r app roach is closely related to the construction of one-dimension al principal curves that minimize orthogonal erro r to data p oints subject to smo othness constraints. Specifically , we construct a two-d imensional p rincipal manifold directly in the high-d imensional space using cu bic sm oothing splines, and define the emb edding coo rdinates in terms of g eodesic distances. Thu s, the mapping from the high- dimensiona l data to the manifold is defined in terms of local coordinates. Throu gh rep resentative examples, we show that co mpared to existing no nlinear d imensionality redu ction methods, the principal manif old retains the orig inal structure even in noisy an d sparse datasets. T he prin cipal manifold finding algorithm is app lied to co nfigur ations obtaine d fro m a d ynamical system o f multiple agen ts simu lating a co mplex maneuver called p redator mobbin g, and the resulting two-dimension al embed ding is com pared with that of a well- established nonlinear dimensiona lity reductio n method . K eywor ds: Dimensionality reduction, algorithm, collectiv e behavior, dyna mical systems 1. Introduction W ith advancements in data collection and video record ing methods, high-volume datasets of animal groups, such as fish schools [ 1, 2], bird flocks [ 3, 4], and insect and bacterial swarms [5, 6], are now ubiquitous. Howe ver , analy zing these datasets is still a nontrivial task, e ven when ind ividual trajecto ries of all member s are a vailable. A desirable step that may ease th e experimenter’ s task o f locating events of interest is to identify c oarse observables [7, 8, 9] and behavioral measures [10] as the group navigates throug h space. I n this con text, Nonlinear Dimensionality Redu ction (NDR) o ff ers a large set of tools to i nf er proper ties of such complex multi-agent dynamical systems. T raditio nal Dimension ality Reduc tion (DR) meth ods based on linear techn iques, such as Prin cipal Comp onents Analysis ( PCA), have been shown to possess limited accuracy when input d ata is nonlinear and com plex [11]. DR entails fin ding the axes of maximu m variability [12] or retaining the d istances b etween p oints [1 3]. Multi Dimensional Scaling (MDS) with Euclide an metric is another DR method which attains low-dimensiona l representatio n by retain- ing the pairwise distanc e of points in low dimensiona l rep resentations [1 3]. Howe ver , Euclidean distance calcu lates the sho rtest distance b etween two po ints on a man ifold instead o f th e genuine m anifold distance, which may lead to di ffi culty of inferring low-dimensional embeddings. The isometric mapping algorithm (Isomap) resolves the prob lem associated with MD S by pr eserving th e pairwise geodesic d istance between p oints [14]; it has re cently b een used to analyz e grou p proper ties in collective behavior , such as the level o f coor dination and f ragmen tation [15, 16, 17]. ∗ Correspondi ng author Email addr esses: dineshhk@clarks on.edu (Kelum Gajamanna ge), sb4304@nyu.edu (Sachit Butail), mporfiri@p oly.edu (Maurizio Porfiri), bolltem@ clarkson.edu (Erik M. Bollt ) 1 W ithin Iso map, h owe ver , short- circuiting [18] created b y faulty connection s in the neighborhoo d graph, manifold n on- conv exity [19, 20] and holes in the data [21] can degrade the f aithf ulness of the reconstructed embeddin g manifo ld. Di ff usion map s [22] have also b een shown to successfully ide ntify coarse obser vables in co llectiv e pheno mena [23] that would other wise require hit-and -trial gu esswork [24]. Beyond Isomap and di ff usion map s, th e potential of oth er NDR metho ds to study collectiv e beh avior is largely untested. For exam ple, Kernel PCA (KPCA) requires the compu tation o f the eigenv ector s of the kern el matrix instead of the eig env ector s of the covariance matrix o f the data [25] but this is com putation ally expen siv e [11]. Local Linea r Em beddin g ( LLE) em beds hig h-dimen sional data thr ough glob al minimiza tion of local line ar reco nstruction erro rs [11]. Hessian L LE (HLL E) min imizes the curviness of th e high er dimensiona l man ifold by assuming that the low-dimensional em beddin g is lo cally isometr ic [26]. L aplacian Eig enmaps (LE) per form a weigh ted minimization (instead o f glob al minimization as in LLE) of the distance between each point and its giv en nearest neighb ors to embed high dimen sional data [27]. Iterative NDR approach es have also been recen tly d ev elop ed in ord er to b ypass spectral decompo sition which is co mmon in most o f NDR metho ds [28]. Curvilinear Com ponen t Analysis ( CCA) employs a self-o rganized neural network to perform two tasks, namely , vecto r quan tization of subman ifolds in the input s pace and non linear pro jection of q uantized vectors onto a low dimension al space [29]. This method minimizes the distan ce between the inpu t and output spaces. Manif old Sculpting (MS) tran sforms data by balan cing two oppo sing h euristics: first, scaling informa tion out of unwanted dimensions, an d second, preserv ing loca l structure in the data. The MS method, which is robust to sampling issues, iteratively re duces the dim ensionality by u sing a cost fu nction that sim ulates the r elationship among p oints in a local neig hborh oods[2 8 ]. The L ocal Splin e E mbedd ing (LSE) is another NDR meth od which embeds the data points using splines th at map each local coord inate in to a g lobal coordina te of the under lying ma nifold by m inimizing th e r econstruc tion error of th e objectiv e fu nction [3 0]. This method redu ces the dimension ality by solving a n eigen value problem wh ile th e lo cal g eometry is e xp loited by the tangential projection of data. LSE a ssumes that the da ta is not only una ff ected by no ise or ou tliers, but also, samp led fro m a smoo th manifold which ensures the existence of a smooth lo w dimensional embedd ing. Due to the global perspecti ve of all these methods, none of them provide su ffi cient control o ver the mapping from the o riginal h igh-dim ensional d ataset to th e low-dimension al re presentation , limiting the analysis in the embed ding space. In other words, the low-dimensional coor dinates are not immedia tely p erceived as useful, whereby one must correlate th e axes of the embed ding manifo ld with selected fun ctions of kn own observables to deduce their p hysical meaning [24, 14]. In this context, a desirab le feature of DR th at we emp hasize here is the r egularity in the spatial structure and range of points on the embedding space, despite the presence of noise. W ith regard to datasets of collective behavior , nonlinear methods have lim ited use fo r detailed analysis at the lev el of the embed ding space. Th is is p rimarily becau se the majority of th ese meth ods collapse the data onto a lo wer dimensiona l space , whose coord inates a re not guar anteed to be linear functions of known system variables [31]. In an idealized simulation of predator in duced mobbing [32], a form of collecti ve behavior w here a g roup of animals crowd around a moving p redator, tw o degrees of freedom are obvio us, namely , the translation of the grou p and the ro tation about th e predator (cen ter o f th e tran slating c ircle). This two-dimensional manif old is not immediately perceived by Isomap, even for the idealized scenario presented in Figure 1, where a group of twenty indi vid uals ro tate about a predator moving at a constant speed about a line bisecting the first quadran t. Sp ecifically , the algorith m is u nable to locate a distinct elbow in the residual variance vs. dimen sionality curve, notwithstand ing substantial tweak ing of the parameters. Thus, th e infe rred dimension ality is alw ays 1 (Fig. 1b). For a two-dimensional embed ding (Fig. 1c), visual comp arison of the r elativ e scale of the axes ind icates that the horiz ontal axis represents a gr eater translation than the vertical axis. It is likely that the h orizontal axis captures the motio n of the group along the translating circ le. The vertical ax is co uld instead be associate d with (i) motion about the c enter of the circle, or (ii) no ise, which is indepen dent and identically d istributed at each time s tep. The ambiguity in determining the meaning o f such direction indicates a drawback of Isomap i n provide meaningful interpretations of the low-dimensional coordinates. An alternative appro ach to DR, one th at d oes not require heavy matrix co mputation s or orthogonalizatio n, inv olves working directly on raw data in the high -dimensio nal space [33, 34]. W e prop ose here a m ethod f or DR that relies on geodesic rather than Euclidean distance and emphasizes manifo ld regularity . Our approa ch is based on a spline representatio n o f the data that allows u s to control the expected manifold r egularity . T ypically , this enta ils condition ing the data so that the lower dimensions are r ev ealed . For example, in [33], raw data is successively clustered through a series of lumping and s plitting oper ations until a faithful classification of points is obtained. In [34], one-dimension al parameteriz ed curves ar e used to summarize the high-d imensional data by u sing a property ca lled self-consistency , 2 Figure 1: Using I somap to cr eate a two-dimen sional embedding of a simu lation of co llectiv e behavior . (a) Predator mobbin g of twenty agen ts moving on a translating circular tra jectory on a plane ( enclosing a p redator moving at constant spee d at a 45 ◦ angle), axes y 2 i − 1 , y 2 i generally rep resent co ordinates f or the i - th ag ent. (b ) Scaled re sidual variance of can didate low-dimensional em bedding s pro duced by Isomap using di ff eren t n earest neigh bor v alues k (green- circle, brown-square, an d black -triangle) , and (c) two-dimen sional representatio n of the data for five nearest neighbo rs (black- triangle). Green and blue crosses mark the start and end points of the trajectory . in which points on the final cur ve coincide with the average o f raw d ata pr ojected on itself. In a similar vein, we construct a PM of th e high- dimension al data using cubic sm oothing splines. Summa rizing the data u sing splines to construct a PM of the data has two advantages: ( i) it r espects the data regular ity by enab ling access to ev ery p oint of the dataset, and (ii) it giv es direct control ov er the amount of noise rejection in extracting the true embedd ing throug h the smoo thing p arameter . W e illustrate the algorith m using the stand ard swiss roll da taset, typically used in NDR methods. The n we validate the method on three di ff erent datasets, including an instance o f collecti ve beha vior similar to that in Figure 1. This paper is organized as follows. Section 2 d escribes th e thr ee m ain steps of the algo rithm usin g th e swiss roll dataset as an illu strativ e example. In Section 3, we validate and co mpare the algorithm on a parabolo id, a swiss roll with hig h ad ditive noise, and a simulation of collecti ve animal m otion. Section 4 analyzes th e perfor mance o f the algorithm by comp aring topologies in the origin al an d embed ding space as a function of the smoo thing param eter , noise intensity , an d data density . W e conclude in Sectio n 5 with a discussion of the a lgorithm perfor mance and ongoin g w ork. Individual s teps o f the algo rithm are detailed in Ap pendix A. Compu tational complexity is discussed in Appendix B. 2. Dimensionality reduction algorithm to find principal manif old Dimensionality reduction is defined as a transf ormation o f high- dimension al data into a meaningful representation of r educed dimen sionality [11]. In this context, a d -d imensional input dataset is embedd ed onto an e -dimen sional space such that e << d . T he mapping from point x ∈ R e in the embedding space to the correspon ding point y ∈ R d in the original dataset is Φ : R e → R d (1) Di ff erently from o ther approach es, the pr oposed DR algorithm is ba sed on a PM of the raw dataset, obtained by constru cting a series of cub ic smoothin g splines on slices of data that are par titioned using locally orth ogona l hyperp lanes. Th e resulting PM summ arizes the data in the f orm of a two-dimensional embedding , that is, e = 2. The PM finding algorith m p roceeds in three steps: c lustering, smoo thing, and embed ding. The clustering step partitions the d ata using r eference po ints into n on-overlappin g segments called slices. Th is is followed by locating the longest geodesic within each slice. A cubic smoothing spline is then fitted to the longest geodesic. A second set of slices, and correspo nding spline s, are crea ted in a similar way resulting in a two-dimensional PM surface. The PM is co nstructed 3 T able 1: Nomenclatur e Notation Description D Input dataset d Input dimension y A point in the input dataset n Number of points in the input dataset e Output embed ding dimension (equ al to two) x A point in the embedd ing space z An external input poin t for the embedding µ Mean (centro id) of the input dataset p Smoothing parameter k Number of neighb ors i n the n earest neighbor search O Origin of the under lying manifo ld q 1 , 2 Reference points 1 and 2 C 1 , 2 j j -th cluster for referen ce points 1 and 2 n 1 , 2 C Number of clusters for referen ce points 1 and 2 S 1 , 2 j j -th cubic spline for refere nce points 1 and 2 G 1 , 2 j j -th geod esic for reference points 1 and 2 t l , m Intersection point in d -dime nsional space between splines l and m ( u 1 z , u 2 z ) T angents to splines at the point z ( v 1 , σ 1 ) , ( v 2 , σ 2 ) First two Princip al Componen ts (PCs) of the inpu t dataset, whe re v i is the d -dimension al coe ffi cien ts and σ i is the eigen value of the i -th PC in the form of inter section points be tween pairs o f lines, one fro m each refer ence point. Any point in the inpu t space is projected on the PM in terms of the intersection points and their respecti ve distances along the cubic splines. T able 1 lists the notation used in this paper . 2.1. Clustering Consider an input dataset D describ ed by n d -dimen sional points y 1 , . . . , y n . Clusterin g begins by partitionin g the data into no n-overlapping clusters. T he partitioning is p erform ed by cre ating hyper planes or thogon al to the straight line joining an external re ference point q ∈ R d throug h the m ean µ ∈ R d to some point ˜ q ∈ R d . Althoug h any referenc e po int may be selected, we use Principal Componen ts (PCs) to make the clustering p rocedu re e ffi cient in data-repr esentation. In particular, Princ ipal Comp onent A nalysis ( PCA) of the matrix D = h y 1 | y 2 | . . . | y n i is perform ed to obtain two largest principal compon ents ( v 1 , σ 1 ) and ( v 2 , σ 2 ), where v i is the d -d imensional co e ffi cients and σ i is the eig en value of the i -th PC. The first re ference p oint is cho sen su ch that q 1 = µ + v 1 σ 1 . T o cover the full range of the dataset, the line joining the poin ts q 1 and the poin t ˜ q 1 = µ − v 1 σ 1 is divided into n 1 C equal pa rts using the ratio formu la in a d -dimen sional s pace [3 5]. Th e j -th po int a j ∈ R d on this line is a j = µ + v i σ i (2 j − n i C ) n i C ; j = 0 , . . . , n i C (2) where i = 1 for this case of dealing with the first re ference point. All points between hy perplan es throug h points s j − 1 and s j are assigned to the cluster C 1 j , j = 1 , . . . , n 1 C , by using the following inequality for k = 1 , . . . , n with i = 1 cos − 1 y k − a j − 1 T q i − a j − 1 k y k − a j − 1 kk q i − a j − 1 k < π / 2 , cos − 1 y k − a j T q i − a j k y k − a j kk q i − a j k ≥ π/ 2 (3) (Fig. 2a). T he clustering metho d is adapted to detec t gaps or holes in the d ata by setting a th reshold on the minim um distance b etween n eighbo ring points based on a nearest neig hbor sear ch [ 36]. If a set of points d o n ot satisfy the threshold, they are automatically assigned anoth er cluster gi ving rise to sub-clu sters [37] (Fig. 2b). 4 −0.5 0 0.5 −5 0 5 −4 −2 0 2 4 6 y 2 ( b ) y 1 y 3 −2 0 2 −2 0 2 4 −2 0 2 4 y 2 ( a ) y 1 y 3 Figure 2: Clustering the r aw data into slices. (a) Using a single ref erence point (red) located far from the data points, the d ataset can be sliced into no n-overlapping sections which are p erpend icular to th e line join ing the centroid (gray star) and the ref erence point (red star), then sections are used to draw a grid pattern using splines. ( b) A hole in the data will result in multiple sub-clusters (shown in di ff eren t colors red and blue ) within a cluster . The above proced ure is repeate d for the second r eference po int q 2 = µ + v 2 σ 2 to p artition the dataset along the line joining µ ± v 2 σ 2 using the equ ation (2) with i = 2. Th en, e quation (3) is used for k = 1 , . . . , n with i = 2 to make ano ther set of clusters C 2 j ; j = 1 , . . . , n 2 C . The resulting clustering algo rithm inp uts the data D , and th e n umber of clusters n 1 , 2 C with respect to each referen ce point, wh ich can be set on th e basis o f data density in each d irection. The set of clusters for each refer ence point are store d for subsequent operations. The clustering alg orithm is d etailed in Appendix A as algor ithm 1. 2.2. Smoo thing The clustering step is followed by smoothing , where cub ic splines are used to r epresent the the clusters. Th is approa ch of using a splin e to appro ximate the data is similar to form ing a principal c urve on a set of p oints [ 34, 38]. Briefly , the princip al curve runs smoothly throug h the middle of the dataset s uch that any p oint on th e curve coincid es with the a verage of all poin ts th at project orthog onally onto this po int [34]. The algorith m in [3 4] sear ches for a parameteriz ed function th at satisfies this conditio n of self-consistency . In the con text of smoothin g splines on a cluster with m poin ts, y 1 , . . . , y m , the principal curve g ( λ ) par ameterized in λ ∈ [0 , 1] minimizes over all smooth fu nctions g [34] m X i = 1 k y i − g ( λ i ) k 2 + κ Z 1 0 k g ′′ ( λ ) k 2 d λ, (4) where κ weights the smo othing of the spline and λ i ∈ [0 , 1] for i = 1 , . . . , m . Equation (4) yield s d individual expressions, one for each dimen sion in the input space. Since the splin e is create d in a multi-dimension al space, the points are not necessarily arrang ed to follow th e general curvature of the dataset. In order to arrange the points that are input to the eq uation (4), we perform an additional operation to build geodesics within the cluster . The g eodesics are created u sing a range- search 1 with range distan ce set as the cluster width 2 σ 1 / n 1 C or 2 σ 2 / n 2 C depend ing on th e refer ence poin t. The longest geodesic within th e cluster is used to repr esent th e full range and curvature of the cluster . Using n g number of d -dimen sional points n y i = y i , 1 , . . . , y i , d T | i = 1 , . . . , n g o on the long est geodesic, the d -dimen sional cubic sm oothing splin e S ( λ ) = 1 A neighbor search which choses all neighbo rs within a specific distance . 5 [ S 1 ( λ ) | S 2 ( λ ) | . . . | S d ( λ )] p arameterized in λ ∈ [0 , 1] is computed as a piecewise po lynom ial that minimizes the q uantity [34, 39] p n g X i = 1 | y i , j − S j ( λ i ) | 2 + (1 − p ) Z λ n g λ 1 h S ′′ j ( λ ) i 2 d λ, (5) where p ∈ [0 , 1], in each dimension j = 1 , . . . , d . Thus, p weights the sum of square error and (1 − p ) weights the smoothn ess of the spline ; con versely p = 0 gives th e natural cubic smooth ing spline a nd p = 1 gives an exact fit (Fig . 3a). This procedure is rep eated for all clusters for e ach reference p oint (Fig . 3b) resulting in a g rid-like surface o f smoothing splines. W e den ote cu bic smoothin g spline s made with respect to the first refer ence p oint by S 1 j ; j = 1 , . . . , n 1 C , and second reference po int by S 2 j ; j = 1 , . . . , n 2 C . The smoo thing algor ithm is described in Append ix A as algorith m 2. 0 2 4 6 8 10 −5 0 5 10 15 y 1 ( a ) y 2 p = 0 p = 0 . 9 p = 1 −2 0 2 −2 0 2 4 −4 −2 0 2 4 6 y 1 ( b ) y 2 y 3 Figure 3: Appr oximating clu sters with smoo thing splines. (a) A cu bic smoothing spline is fit onto two-dimension al data using di ff erent values of the smo othing par ameter p . (b ) Smoothin g splines fit clu sters of a swiss ro ll dataset from a single reference point. 2.3. Embed ding Once constru cted, intersection points betwe en a ll pairs of splines, one from each refer ence po int are located as landmark s to embed n ew poin ts onto the PM. Since th e splines fr om two refer ence po ints may not actually intersect each othe r unless p = 1 for all sp lines, virtual intersection points be tween two n on-inter secting s plin es are lo cated at the midp oint on th e shortest distance be tween them. The emb edding algorith m loops thr ough all p airs o f splines to locate such points, and once located they are denoted as t l , m ∈ R d where ( l , m ) ∈ S 1 l × S 2 m . In orde r to defin e the embeddin g coo rdinates, an in tersection point is selected ran domly an d assigned as the manifold o rigin O o f the PM. The set of smo othing splines correspon ding to the origin ar e called axis sp lines. The embedd ing coordinates of a po int z ∈ R d are defined in terms of the spline distance of the intersecting splines of that point from the axis splines (Fig. 4c ). For that, first we find the closest intersection ˜ z for z in Eu clidean distance as ˜ z = argmin l , m k t l , m − z k (6) and tangents to splines at this point ar e called the local spline d irections and den oted by ( u 1 z , u 2 z ). Distance from O to ˜ z is computed along the axis splines by [ ˜ x 1 , ˜ x 2 ] T = h d l ( ˜ z − O ) , d m ( ˜ z − O ) i T (7) 6 where d l ( b 1 − b 2 ) is the distance between po ints b 1 and b 2 along the splin e l . W e project the vector ˜ z − z on th e local tangential directions ( u 1 z , u 2 z ) as δ x 1 = ( ˜ z − z ) T u 1 z δ x 2 = ( ˜ z − z ) T u 2 z (8) at the intersection point ˜ z . The final embedding co ordinates are obtained by summin g the quantities in equa tions (7) and (8) as [ x 1 , x 2 ] T = [ ˜ x 1 + δ x 1 , ˜ x 2 + δ x 2 ] T (9) The embedding algorithm is detailed in Appendix A as algorithm 3. t l,m S 1 l S 2 m (a) (b) (c) −3 −2 −1 0 1 2 −2 0 2 4 −4 −2 0 2 4 6 y 1 y 2 y 3 Figure 4: Embe dding the data into two-dimension al coordinates. (a) The intersecting point b etween two splines lies midway on the shortest distance b etween them (b) in tersecting po ints for a swiss roll and (c) the two-dime nsional coordin ate of a po int (triang le) is the geo desic distance along the in tersecting splines (grey) to the axis splines (b lue) from an origin (circle). 2.4. Mappin g between the manifold and raw data The mapping between the manifold and th e raw data is created b y in verting the steps of the embedding algorith m. In p articular, a two-dimension al point x = h x 1 , x 2 i T in the em bedding space is located in terms o f the em beddin g coordin ate x l , m of the closest intersection p oint t l , m ∈ R d . W e then com plete the local coordinate system by finding the two adjacent intersection points. The resulting three points on the PM, the origin and the two adjacent points denoted by { x l , m , x l , m + 1 , x l + 1 , m } , are used to solve for ratios α an d β such that α = x 2 − x l , m 2 x l , m + 1 2 − x l , m 2 β = x 1 − x l , m 1 x l + 1 , m 1 − x l , m 1 . (10) The ratios are then propagated to the hig h-dimen sional space (Fig. 5) by using the same relation o n the correspon ding points in the higher dimension { t l , m , t l , m + 1 , t l + 1 , m } to obtain the high-dime nsional point y = t l , m + ( t l , m + 1 − t l , m ) α + ( t l + 1 , m − t l , m ) β. (11) 7 ‘ t l,m t l +1 ,m t l,m +1 O α β l l + 1 m + 1 m Figure 5: The mapp ing fr om the embedd ing manifold to the origin al high-d imensional space is fou nd by findin g the projection s α, β on the local coor dinate space and pro pagating the same into the hig h dimensions. Lo cal coor dinate space can be created using adjacent splines ( l , l + 1) , and ( m , m + 1). 3. Examples In this section, we ev aluate and c ompare th e PM finding algorithm with oth er DR m ethods on three di ff erent datasets: a three- dimensiona l par aboloid, a swiss roll constru cted with high additive noise (noisy swiss roll), and a simulation of collectiv e behavior . Specifically , we use a standard version of eight di ff erent DR methods implemented in the Ma tlab T oolb ox for DR [4 0] with default p arameters listed in T able 2. Note that we run ea ch method in an unsuper vised manner using the standard default values a vailable in that toolbox . T able 2: Default parameters of DR methods implemen ted in Matlab T oolbox for DR [40] for the paraboloid an d noisy swiss roll examples. Method Parameters MDS none Isomap nearest neighbors = 12 Di ff usion maps variance = 1 and oper ator on the graph = 1 KPCA variance = 1 and Gaussian kernel is used LSE nearest neighbors = 12 LLE nearest neighbors = 12 HLLE nearest neighbors = 12 LE nearest neighbors = 12 and variance = 1 3.1. P araboloid The three-dim ensional parab oloid (Fig. 6a) is gene rated in the form of 2000 points using y 3 = y 2 1 + y 2 2 + ǫ , (12) where y is a point in th e three -dimension al space with y 1 , y 2 ∈ [ − 2 , 2], and ǫ ∼ U ( − 0 . 05 , 0 . 05 ) is a no ise variable sampled from a un iform d istribution rangin g between -0.0 5 and 0.05 . Since the d ata is g enerated along the y 1 , y 2 axes, t he two referenc e points are selected along the same just outside the range for each value. W e ru n the clustering 8 −2 0 2 −2 0 2 0 2 4 6 8 y 1 ( a ) y 2 y 3 −2 0 2 −2 0 2 0 2 4 6 8 y 1 ( b ) y 2 y 3 0 2 4 6 8 10 0 2 4 6 8 10 x 1 ( c ) x 2 Figure 6: Em beddin g data from a three-dimen sional paraboloid with 2000 poin ts (a) of raw data after smooth ing (b) into two dimensio nal embedd ed space with intrin sic coo rdinate of the manifo ld (c). Points a re co lored to hig hlight the relativ e configura tion. −2 0 2 4 −2 −1 0 1 2 x 1 (a) x 2 −5 0 5 −6 −4 −2 0 2 4 x 1 (b) x 2 −3 −2 −1 0 1 2 −2 −1 0 1 2 x 1 (c) x 2 −0.4 −0.2 0 0.2 0.4 0.6 0.8 −0.4 −0.2 0 0.2 0.4 0.6 x 1 (d) x 2 −1 0 1 2 3 −3 −2 −1 0 1 2 3 4 x 1 (e ) x 2 −0.04 0 0.04 0.08 −0.08 −0.06 −0.04 −0.02 0 0.02 0.04 x 1 (f ) x 2 −1 0 1 2 3 −3 −2 −1 0 1 2 3 x 1 (g) x 2 −0.01 0 0.01 0.02 −0.01 −0.005 0 0.005 0.01 0.015 0.02 x 1 (h) x 2 Figure 7 : T wo-dim ensional embeddin gs of th e p arabolo id b y M DS (a) , Isomap (b), Di ff usion ma ps (c ), KPCA (d ), LSE (e), LLE (f), HLLE (g), and LE (h) 9 algorithm with the value of n C = 14 for each reference point to generate correspo nding sets of clusters with algorith m 1. Next, we run the smo othing alg orithm with a smoothing pa rameter p = 0 . 9 to produ ce a set of representative splines for the data (Fig. 6b ). Finally , we embed the manifold by first finding the intersection points and, then, computing the distance of each point from the axis splines (Fig. 6c). The two-d imensional e mbeddin g man ifold gen erated using ou r algorithm pr eserves the topolog y o f the data as shown in Figure 6c. Furthermore, the axes in the embedd ing manifold retain the scale of the orig inal data in terms of the distance between indi vidual points. For a compar ison, we run o ther NDR methods on this data set with parameter s specified in table 2 (Fig.7). Results show that except Isomap and the proposed method , none of the NDR methods are able to preserve the two-dimension al square embed ding after dimensionality reduction . Between Isom ap and the PM approa ch, the PM approac h retains the scale of the manifo ld as well. 3.2. A noisy swiss r o ll In a second example, we run our algorithm on a 2500 point three-dimen sional noisy swiss roll dataset with high additive n oise (Fig. 8a) . Th e dataset is generated using y 1 = θ 0 . 8 cos θ + ǫ y 2 = θ 0 . 8 sin θ + ǫ y 3 = φ + ǫ (13) where θ ∈ [ 0 . 25 π , 2 . 5 π ] , φ ∈ [ − 2 , 2] , and ǫ ∼ U ( − 0 . 4 , 0 . 4) is a n oise variable samp led fro m a unif orm distribution ranging b etween -0 .4 an d 0.4. T wo r eference p oints a re chosen alo ng two major principa l compo nent directions v 1 and v 2 at a distance of σ 1 and σ 2 units away f rom the da ta centr oid µ . W e run th e clu stering algorithm with the value of n C = 15 for each reference p oint, ho wever , d ue to f olds and therefor e g aps in the data, the clusters along v 2 are further split into 42 sub clusters. The v alue of smo othing parameter p = 0 . 7 5. Figure 8b and 8c show the smoothin g splines in a grid pattern tha t are used to embed the m anifold, and th e resulting embedding. For a compa rison, we run other NDR methods on this data set with param eters specified in table 2 (Fig. 9). Compa rison between existing NDR method s show that while only Isomap and KPCA are able to flatten th e swiss roll into two dimensions, Isomap preserves the general rectangula r shape of the flattened swiss roll. A majority of NDR method s suppress one compon ent out of the two princip al compo nents in the ra w data re vealing an embedd ing tha t resembles a o ne-dim esional curve. In contrast, the PM approa ch is able to embed the swiss roll into a rectang le while preserving the scale. W e n ote that by chang ing the value of th e smoothing parameter we control for the le vel of noise-rejection in the original data, a feature that is not av ailable in the existing DR algorithms [11]. Altho ugh the splines form illegal con- nections, our algorithm is still able to preserve the tw o- dimensiona l emb edding ; th is is due to the inherent embedd ing step wh ich is able to overcome such shortcu ts while co mputing the low-dimensional coo rdinates. Furthermo re, we note that our method is able to better exclude noisy data fro m the embedd ing automatically in the form o f o utliers; neighbo rhoo d based algorithm s wou ld be mislead to attempt to include these as valid points [41]. For examp le, the two-dimensional embedding obtained using Isomap sho ws an unfore seen b end demonstratin g that, despite fe wer out- liers, the gener al topolog ical struc ture is com promised more he avily . This glo bal a nomaly is a dire ct conseque nce of the Isomap’ s attempt to include noisy points in the em beddin g; p oints that are other wise igno red by the principal manifold . 3.3. Collective behavio r: simulation of pr edato r mobbing In a third examp le of low-dimen sional embe dding, we genera te a d ataset representing a form o f collective behavior . W e simulate poin t-mass particles rev olving on a translating circle to rep resent a fo rm of behavior called predator induced mobbin g [42]. In p rey an imals, pr edator mobbing , o r c rowding arou nd a predator, is often ascribed to th e purpo se of highlighting the presence of a predator [42]. In our id ealized model, we assum e that N agen ts ( N = 20) are rev olving on the circumference of a half circle whose center marks the predator and translating on a two-dimen sional plane which is orth ogon al to the axis of th e rev olution . T o gen erate a two-dimensional trajectory with ρ rev olu tions around a translating cente r we represen t the two-dimensional position of an agen t i at k , r i [ k ] = h y 2 i − 1 [ k ] , y 2 i [ k ] i T , r i [ k ] ∈ R 2 r i [ k ] = s i [ k ] " cos(2 πρ k / n k + π i / N ) sin(2 πρ k / n k + π i / N ) # + k v p [ k ] + ǫ [ k ] , (14) 10 −2 0 2 −2 0 2 4 −4 −2 0 2 4 6 y 1 y 2 (a) y 3 −2 0 2 −2 0 2 4 −4 −2 0 2 4 6 y 1 y 2 (b) y 3 0 2 4 0 5 10 15 20 x 1 (c) x 2 Figure 8: T wo-dimen sional emb edding of noisy swiss-roll with 2500 points, raw data (a) of th e noisy swiss roll is clustered an d sm oothene d in order to obtain the p rincipal manifold ( b) and then embedded in two dimensions with intrinsic coordin ates denotin g the distance from the center of the manifo ld coordinate (c). −5 0 5 −4 −2 0 2 4 x 1 (a) x 2 −10 −5 0 5 10 −2 0 2 x 1 (b) x 2 −2 −1 0 1 2 −2 −1 0 1 2 x 1 (c) x 2 −0.5 0 0.5 −0.5 0 0.5 x 1 (d) x 2 −1 0 1 −2 −1 0 1 2 x 1 (e) x 2 −0.05 0 0.05 −0.05 0 0.05 x 1 (f ) x 2 −1 0 1 −2 −1 0 1 2 x 1 (g) x 2 −0.01 0 0.01 −0.01 −0.005 0 0.005 0.01 x 1 (h) x 2 Figure 9: T wo-d imensional e mbeddin gs of the noisy swiss-roll by MDS ( a), Isomap (b), Di ff u sion maps (c), KPCA (d), LSE (e), LLE (f), HLLE (g), and LE (h). 11 −40 −20 0 20 ˜ r 1 , 1 Ground truth time 0 50 100 150 200 Principal surface algorithm x 1 time −1000 −500 0 500 1000 Isomap time x 1 0 1000 2000 −2 −1 0 1 2 ˜ r 1 , 2 time (a) 0 1000 2000 0 20 40 60 time (b) x 2 0 1000 2000 −5 0 5 10 15 time (c) x 2 Figure 10: Embedd ing a forty dimensional dataset of an id ealized simulation of pred ator mobbing where twenty par- ticles move around a tr anslating circle. A com parison of individual axes of the embedd ing produced by th e princip al surface alg orithm described in this pa per and those prod uced using Isomap shows that ou r algorithm perfo rms dis- tinctly better in terms of pr eserving the time signatu re as well as range of the axes. The near est neighbor parameter used for Isomap is equal to 10. where v p [ k ] = [1 , 1] T / 80 is the velocity of the predato r s i [ k ] = 3 is the speed of the agent i , n k is the n umber o f total time-steps, and ǫ [ k ] ∼ N ( 0 , 1 / 10 0) is the Gau ssian noise variable with mean 0 ∈ R 2 and standard deviation 1 / 100 ∈ R 2 . The first term of E qn. (14) assigns the relativ e positions of N agents onto eq ually spaced points on th e circumfer ence of a half c ircle o f u nits s i [ k ], an d the second term gives the velocity of the virtual center (p redator) of the tr anslating cir cle. The agent-dep endent phase π i / N creates spatial separation of ind ividual members a round th e virtual cen ter . Figure 1a shows the resulting trajectories for 2000 tim e-steps w ith ρ = 14 in a d -dimen sional space (note that d = 2 N in this c ase, wh ere N is the number of ag ents). The intera ction between the agents is cap tured in the form of noise ǫ . A high value means that the agents interact less with each other . T o cluster the dataset, we use n C = 3. Th e value of the smooth ing parameter p = 0 . 9 . The emb edding manifold is shown in Fig. 1 0b with the start and end poin ts o f the trajecto ry . For com parison, we also run the Isom ap alg orithm on this dataset with a neighb orho od parameter value set to 10. T o ensure that the em beddin g is consistent and robust to o ur choice of neigh borho od p arameter, we run the algor ithm with n eighbor hood parameters 5 and 15 and verify that th e outpu t is similar . Figu re 10c shows the resulting two-dimen sional embedding coo rdinates each as a function of time. Unlike the parabo loid and the noisy swiss ro ll, the predato r mobbin g dataset represen ts a dynamical system with a cha racteristic tem poral evolution. Therefo re, we use cross-correlatio n between the embedd ing of each m ethod a nd a refer ence g round tru th to compar e the perfo rmance of our algo rithm to Isomap (Fig . 1). For grou nd truth, we transform the original data by a clockwise rotation of π/ 4 such that ˜ r i [ k ] = 1 √ 2 " 1 − 1 1 1 # r i [ k ] (15) and use the position of th e first agent ˜ r 1 [ k ] = h ˜ r 1 , 1 [ k ] , ˜ r 1 , 2 [ k ] i T (this value ser ves as a descriptive global observable of the p redator mobbin g ag ents sep arated by a constant phase, than, for exam ple, the gro up c entroid, where the rev olving motion is suppressed due to the instantaneous two-dimensional arrangem ent). W e then cross-correlate each compon ent of the two-dimension al em beddin g sig nal h x 1 , x 2 i T with the corresponding compo nent of the ground-tru th and add the two v alues. W e compute correlatio ns of the embedded data of our algorithm and Isomap with the groun d 12 truth along the oscillating directio ns as 0 . 3987 and 0 . 007 4. Thus, the co rrelation of our algorithm with the g round truth is fifty times higher than t he correlatio n of Isomap with the ground tru th. Corr elation p -values under our method and Isomap with the grou nd truth are 0 . 0000 and 0 . 388 8 respectively , showing that under 95% of confiden ce i nter val, the values fro m our meth od are related to th e o nes available from the g roun d truth. Figu re 1 visually demo nstrates the sam e wh ere x 2 from th e p rincipal su rface follows the same trend as ˜ r 1 , 2 . I n ad dition, the ra nge o f values o f the embedd ing coordin ates is s imilar to th e original values. 4. Perf ormance analysis T o analyze th e perfo rmance of the algo rithm, we use a distance- preservin g metric between the origina l and the embedd ing data in ter ms of ad jacency distance of graph connectivity . For both the origina l and the embeddin g data, we first searc h k -nearest neighbor s throu gh the algorith m given in [43] and then pr oduce two individual weigh ted graphs based on points conn ectivity in the data sets. A gr aph constructe d throu gh nearest neighbor search is a simple graph 2 that d oes not contain self- loops or multiple ed ges. W e compute the adjacency distance matrix A for the original data as A i , j = d ( i , j ) : ∃ an edge i j in the graph of the original data 0 : otherwise (16) and the adjacency matrix ˜ A for the embed ding data as ˜ A i , j = d ( i , j ) : ∃ an edge i j in the graph of the embedding data 0 : otherwise (17) Here, A i j and ˜ A i j are the ( i , j ) − th entries of th e adjacency m atrices A and ˜ A , and d ( i , j ) is the Euclide an distance between n odes i and j . For n poin ts, this metric is compu ted as the n ormalized n umber of pairw ise erro rs between entries of the adjacency distance matrices as ∆ ( ˜ A , A ) = 1 nk X i , j | ˜ A i j − A i j | , (18) Equation (18) is a mo dification o f th e structure preserv ing metr ic in [ 45] where the conn ectivity is replaced by the distance and the denom inator n 2 with the number of edges nk . W e study the dep endenc e of ∆ ( ˜ A , A ) on the smoothing parameter, th e noise in the dataset, and the data density . 4.1. Err or depen dence on smoothin g The prim ary inp ut to the algorith m described in this p aper is the smoothin g parameter that controls th e degree of fitness and no ise-rejection by the cu bic smoothing splin es. Figure 11 shows the de penden ce of th e d istance preser- vation error ∆ in term of adjacency distance on the smoothing parameter p . Using a noise-fr ee swiss roll dataset comprising 3000 points in three dim ensions, we vary the smo othing parameter between 0 and 1 with an inc rement of 0.01 while keeping the location of ref erence p oints and cluster width consistent. The erro r dependen ce shows a linear deca y with R 2 -value 3 of 0.9 728 and becomes nearly co nstant at a p = 0 . 88, beyo nd which the cha nge in e rror for an inc rease in th e value o f p is negligible. A hig her value of p improves th e data- fit but a low value improves smoothne ss. Since the gra ph connectivity is dependen t on the relative p oint configu ration, it is expected th at ∆ will rise with increasing smoothn ess. On the other h and, the error dependence shows tha t a g iv en degree of smoothin g can be a ttained beyond the value of p = 0 . 88 with out an a ccompan ied incre ase err or . Th us, as a design parame ter , the value p = 0 . 9 may be used as a starting point for all datasets to in vestigate the embedding manifold. 2 A simpl e graph is an u ndirected graph t hat does not conta ins loops (e dges connect ed at both end s to the same verte x ) and multiple edges (more than one edge betwe en any two di ff erent vert ices) [44]. 3 In a fit of a data set, R 2 -v alue (coe ffi cient of determinati on) ranges betwee n 0 and 1, and measures the goodness of the fit so that 1 is the best while 0 is the wor st. For a set of points { y i } n i = 1 associat ed with fi tted values { f i } n i = 1 , coe ffi ci ent of determinati on or R 2 -v alue is define d as, 1 − P n i ( y i − f i ) 2 P n i ( y i − ¯ y ) 2 where ¯ y = P n i y i / n . 13 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.18 0.2 0.22 0.24 0.26 0.28 0.3 p ∆ Data Fi t : ∆ = − 0 . 0709 p + 0 . 2673 , R 2 = 0 . 9657 Figure 11: V ariation of ∆ with respect to p and cor respond ing linear fit f or a n oise free swiss-roll. ∆ is com puted using Eq. ( 18) on raw and embedded data. 4.2. Err or with noise T o an alyze the cha nge in pairw ise e rror with inc rease in no ise, we create mu ltiple same -sized swiss-ro ll datasets generated using (13) with n oise value ǫ rang ing between 0 and 1 .035 with a n incr ement of 0 .015. T he nu mber of points in the dataset are 30 00 and the value of smooth ing parameter p = 0 . 9. Figure 12 shows the v ariatio n of ∆ with respect to ǫ . The error ∆ increases quadratically with R 2 -value 0 .998 3 w hen noise increases. This relation s hows that, the error of the embeddin g is a ff ected quadratically by the intense of the associated noise in the data. 0 0.2 0.4 0.6 0.8 1 0 2 4 6 8 10 ǫ ∆ D a ta Fit : ∆ = 7 . 1 4 6 0 ǫ 2 + 0 . 1 5 0 8 ǫ + 0 . 40 22 , R 2 = 0 . 9 9 8 3 Figure 12: V ariation of ∆ with respect to noise ( ǫ ) and correspo nding qu adratic fit ∆ is com puted over a djacency matrices for the raw data and embedded data by Eq. (18). 4.3. Data density T o analy ze the depen dence o f ∆ on data d ensity we sub -sample the swiss roll dataset such th at the nu mber o f points are systematically decreased. Th e amount of noise is set at ǫ = 0 . 2 and a sequence of data sets are gener ated with numb er of po ints between 500 an d 350 0 with increme nt of 40. The value of the smoothin g parameter p is fixed at 0.9. W e see tha t the pairwise error ( ∆ ) decreases expo nentially with R 2 -value 0 . 9 713 from an initial high value ( Fig. 13). 5. Conclusion In this pap er , we intro duce a PM findin g dimension ality reduction alg orithm that works directly on raw da ta by approx imating the data in terms of cub ic smoothing splines. W e co nstruct the splines o n two sets of no n-overlapping 14 500 1000 1500 2000 2500 3000 3500 0.2 0.3 0.4 0.5 0.6 0.7 n ∆ D a ta Fit : ∆ = 0 . 2 0 2 1 + 0 . 56 1 4 e − 0 . 0008 n , R 2 = 0 . 9 7 1 3 Figure 1 3: V ariation of ∆ with r espect to number of points ( n ) an d co rrespon ding exponential fit with p = 0 . 9 and ǫ = 0 . 2 . ∆ is comp uted over ad jacency matrices for the raw data and embedde d data by Eq. (18). slices of the ra w data created using parallel hyperplan es that are known distance apart. The resulting PM is a grid-like structure that is emb edded on a two-dimension al m anifold. Th e smoo thness of the splines can be controlled via a smoothing parameter t ha t selecti vely weighs fi tting err or v ersus the amount of noise rejection. The PM is represente d by the intersection points between all pairs of splines, while the embedding coordinates are represented in the form of distance along these splines. The spline repre sentation imp roves regularity o f an otherwise noisy d ataset. W e demon strate the algorith m o n three separate examp les includin g a p arabolo id, a n oisy swiss ro ll, an d a simula tion of collecti ve behavior . Upo n emb edding these datasets on tw o-d imensional manifolds, we find that in the case of the paraboloid, the algorithm is successful in preserving the to pology and the range of the data. In the case of the noisy swiss roll, we find that the algorithm is able to reject high noise, thereby p reserving the regularity in the original d ataset. Un like Isomap , our algorithm for finding PM is able to maintain a gen eral structure. In other words, the algo rithm fails g racefully giving the user eno ugh indication of the trend of in creasing erro r di ff er ently than Isomap, which fails ab ruptly and dram atically [46]. Th is proper ty has a distinct advantage over o ther methods that are more sensiti ve to input parameters and th erefor e ma ke i t di ffi cult to iden tify when the algorithm is embe dding cor rectly . In contrast, the proposed algo rithm o n th e swiss-roll dataset shows that in its cu rrent form, is ine ffi cient to embed the dataset with holes faithfu lly onto a two-dimen sional space, since it is highly focused on revealing a sm ooth underlyin g manifold. W e used a simulation of twenty p articles moving in a translating circle as a rep resentation of a two-dimen sional data em bedded in a for ty-dimen sional state. In collectiv e behavior , this form of m otion approx imates predator mob- bing. Cross-correlation between the em bedded signals and the g round -truth available in the f orm of a tr ansforme d signal shows that our algorithm is able to rep licate th e time-history on a low-dimen sional space than for example Isomap. Furth ermore, we see that the range of axes in the embeddin g manifo ld av ailable from our algorithm is closer to that in the original data. The analy sis of the distance preservin g ab ility of o ur algorith m with respec t to the smoothing paramete r reveals that an in crease in the smooth ing parameter reduces the err or in the structure. This is expected because a high value of p im plies th at the cubic smoo thing spline weights data fit more than smoothing . Howe ver , we also note that the amount of error satur ates ne ar p = 0 . 8 8, showing that values close to but not eq ual to one may also be u sed to represen t the data. W e o bserve a similar trend with r espect to the amo unt of n oise introd uced in a swiss-roll dataset, wh ere we find that the a mount of error inc reases quadratically with an increase in noise. Finally , we find that the alg orithm is able to work on sparse datasets up to a representation with fi ve hundred points. Operating and represen ting raw data for dimensionality reductio n provides an opp ortunity for extracting true em- bedding s that preserve the structure as well as regularity of the dataset. By dem anding a tw o- dimension al embedd ing we also p rovide a useful visualization tool to an alyze hig h-dimen sional datasets. Finally , we show that this approa ch is amenable to high-dim ensional dynam ical systems such as those av ailable in dataset of collective behavior . 15 6. Acknowledgements Kelum Gajamannage and Erik M. Bollt h av e b een supp orted by the Natio nal Science Foun dation under gran t no. CMMI- 112 9859 . Sach it Butail and Maur izio Porfiri have been supported b y the Nation al Science Found ation under grants nos. CMMI- 1 12982 0. Ap pendix A. Algorithms Here, we state th e algorith ms of dim ensionality reduction b y princ ipal manifold by three comp onents as, c luster- ing, smoothing, and embeddin g. Algorithm 1 Clustering : Data matrix D and number o f clusters with resp ect to th e first ( n 1 C ) and second ( n 2 C ) refer ence points are three inputs in the clusterin g algorithm. As the output, this prod uces tw o sets of clusters C i j ; j = 1 , . . . , n i C for i = 1 , 2 from D such that one for each referenc e point. 1: procedure C lustering ( D , n 1 C , n 2 C ) 2: Compute the mean µ ∈ R d of the input data D . 3: Perform Princip al Compon ent Analysis (PCA) [47, 48] on th e in put data m atrix D = h y 1 | y 2 | . . . | y n i to obtain two largest principal co mpone nts ( v 1 , σ 1 ) and ( v 2 , σ 2 ), where v i is the d -dimensio nal co e ffi cients and σ i is the eigenv alue of the i -th P C fo r i = 1 , 2 4: In order to assure that two ref erence points ar e in the dire ctions of two PCs from the mean, co mpute the first referenc e point q 1 = µ + v 1 σ 1 , and the second q 2 = µ + v 2 σ 2 . 5: for each reference point q i ; i = 1 , 2 do 6: Segment the line joining the referen ce points q i = µ + v i σ i and the point ˜ q i = µ − v i σ i into n i C parts with equal width using th e ra tio form ula given in equation (2) to obtain a set of p oints a j ; j = 0 , . . . , n i C [35], where a 0 = ˜ q i and a n i C = q i 7: For j = 1 , . . . , n i C , choo se data between h yperp lanes, which ar e made th rough poin ts a j − 1 and a j normal to the line joining ˜ q i and q i , into the cluster C i j by satisfying the inequalities in (3). 8: end for 9: end procedure Algorithm 2 Smooth ing : Smoothing algo rithm p roduce s two sets of cubic smo othing splines with resp ect to b oth referenc e po ints to represen ts the d ata in clusters. T his algorith m in puts spline smoo thing p arameter p and two sets of clusters C i j ; j = 1 , . . . , n i C for i = 1 , 2 made in the clustering algorithm, and outputs two sets o f cubic smoothing splines S i j ; j = 1 , . . . , n i C for i = 1 , 2. 1: procedure S moothing ( p ; C i j , j = 1 , . . . , n i C for i = 1 , 2) 2: for each reference point q i ; i = 1 , 2 do 3: for all clusters C i j ; j = 1 , . . . , n i C do 4: Compute the neighborho od graph u sing range-sear ch with the d istance set as the cluster width 2 σ i / n i C . 5: Compute the longest geodesic G i j using Dijkstra’ s algorithm [49, 50]. G i j is a set of points, where each point is in R d . 6: For poin ts in G i j , use ( 5) and the value of the smoothing p arameter p to prod uce a smo othing spline S i j ∈ R d representatio n for data in the cluster C i j . 7: end for 8: end for 9: end procedure 16 Algorithm 3 Embedding : This produ ces a grid structure by ap proxim ating the intersections o f sp lines, followed by doing the embedd ing of a new p oint based on this s tru cture. Embe dding algo rithm in puts a new po int z ∈ R d to embed and two sets of cub ic smoothin g splines S i j ; j = 1 , . . . , n i C for i = 1 , 2 prod uced by smoothin g algorithm , an d this outputs two dimensional embedding coordinates [ x 1 , x 2 ] T of z . 1: procedure E mbedding ( S i j , j = 1 , . . . , n i C for i = 1 , 2 ; a point z ∈ R d for embedding ) 2: for all pairs ( l , m ) of smoothing splines S 1 l × S 2 m belongin g to reference points 1 and 2 do 3: Approx imate the minimu m distance between the two splines after discretizing each spline. 4: Choose the midpoin t between the two closest points of the splines as the intersection point t l , m ∈ R d . 5: end for 6: Pick a random in tersection p oint a s th e origin O ∈ R d , and smoothing splin es correspon ding to the orig in a s axis splines. 7: Find th e closest in tersection p oint ˜ z for z in terms of Eu clidean d istance b y e quation (6) , and the tang ents to the splines at this point are called the local spline directions ( u 1 z , u 2 z ). 8: Compute the distances [ ˜ x 1 , ˜ x 2 ] T from the manifold origin O to ˜ z alo ng axis splines by equation (7). 9: Project the vector ˜ z − z on to the loc al coo rdinate system cre ated using the spline directions as equation ( 8) at the intersection point ˜ z an d find the projec tions [ δ x 1 , δ x 1 ] T . The final em beddin g co ordinates are g iv en as x 1 = ˜ x 1 + δ x 1 , x 2 = ˜ x 2 + δ x 2 . 10: end procedure Ap pendix B. Computational complexity The thr ee steps o f the algorithm, nam ely , clustering , smoothing, and em beddin g hav e di ff ere nt compu tational complexities. In particular, f or n points with dimensiona lity d , the clustering algorithm has a complexity O m 3 ; wh ere m = min( n , d ) , (B.1) which is dominated by the PCA [48, 51] step. The computation al complexity of the sm oothing algorithm is dom inated by the Dijkstra’ s algo rithm [4 9] for cal- culating the longest g eodesics. Her e, we first assume that each cluster with respect t o the fi rst reference point con tains an equal number of points. Thus, partitionin g a data set of n point into n 1 C clusters yields n / n 1 C points in a cluster . The complexity of g enerating the longe st geodesic in each su ch clu ster is O n / n 1 C log n / n 1 C [49, 50], which sum s-up n 1 C times and implies the to tal complexity O n lo g n / n 1 C of making all g eodesics with respect to th e first r eference point. Similarly , fo r th e second reference po int, the sam e pr ocedur e is followed for all n 2 C clusters, each containin g n / n 2 C points, to obtain a complexity of O n lo g n / n 2 C . Altogether, geodesics from both reference poin ts contributes a computation al complexity of O n lo g n 2 n 1 C n 2 C (B.2) for the smoothing algorithm. In the embedding algo rithm, d iscretizing splines and approxima ting the minimu m d istance are dominant in the total cost of that algorith m. Here, we first calculate the mean length of s plin es with respect to the first reference point, denoted as ˜ S 1 ∈ R d , and the on e for the secon d ref erence point, denoted as ˜ S 2 ∈ R d . Then , the compu tational cost associated with ap proxim ating intersection of these two splines are c omputed . For a pair of d -dim ensional sp lines, computatio n of the E uclidean distance between any two p oints, on e from each spline, has co mplexity of 3 d fr om the operation s of subtraction , squaring , and summation along all d dimen sions. Since each spline ˜ S 1 , 2 is discretized at a mesh size h , while ˜ S 1 has ˜ S 1 / h points o n it, ˜ S 2 has ˜ S 2 / h points. The computatio nal cost o f approx imating clo sest distance between any two points on e from each splin e ˜ S 1 , 2 is 3 d ˜ S 1 ˜ S 2 / h 2 . Here, f or simplicity , we assume that the length of each spline with respect to the first and seco nd refere nce p oints have sam e length s as ˜ S 1 and ˜ S 2 consecutively . Thus, the total complexity of the embeddin g algorithm , which has n 1 C and n 2 C number of splines with respect to the 17 first and second reference points, is O 3 d h 2 n 1 C n 2 C ˜ S 1 ˜ S 2 ! (B.3) Clustering, embedd ing algorithms and steps 1 − 6 in the emb edding algorith m are p erform ed o nly o nce for a g iv en data set, thus after they are completed, n ne w points are embedd ed with O ( n ). References [1] B. L. Partrid ge, T he structure and functi on of fish schools, Scienti fic American 246 (6) (1982) 114–123. [2] R. Gerla i, High-throughput beha vioral screens: the first step tow ards finding genes inv olved in vertebrat e brain functi on using zebrafish., Molecul es 15 (4) (2010) 2609–2622. [3] M. Nagy , Z. Ákos, D. Biro, T . V icsek, Hierarchic al group dynamics in pigeon flocks, Nature 464 (7290) (2010) 890–893. [4] M. Balle rini, N. Cabibb o, R. Candeli er , A. Cav agna, E. Cisbani , I. Giardin a, A. Orlandi, G. Parisi, A. Procaccini, M. V iale, Empirica l in vesti gation of starling flocks: a benchmark s tudy in colle ctiv e animal beha viour, Animal behaviour 76 (1) (2008) 201–215. [5] K. Branson, A. A. Robi e, J. Bender , P . Perona, M. H. Di ckinson, High-throughput ethomics in lar ge groups of Drosophila, Nature Met hods 6 (2009) 451–457 . [6] H. P . Zhang, A. Be’Er , R. S. Sm ith, E. Florin, H. L . Swinney , Swarming dynamics in bacte rial colonie s, EPL (Europhysics Letters) 87 (4) (2009) 48011. [7] A. Ko lpas, J. Moehlis, I. G. Ke vrekidis, Coarse-grai ned analysis of s tochast icity-induc ed switching between collec tiv e motion states., Pro- ceedi ngs of the Nati onal Academy of Sciences of the United States of America 104 (14) (2007) 5931–5935. [8] N. Y . Miller , R. G erlai, Oscilla tions in shoal cohesion in zebrafish (Danio rerio)., Behavi oural Brain Research 193 (1) (2008) 148–151. [9] T . A. Frewe n, I. D. Couzin, A. Kolpa s, J. Moehlis, R. Coifman, I. G. Ke vrekidis, Coarse collecti ve dynamics of animal groups, in: Coping with Comple xity: Model Reduc tion and Data Analysis, 2011, pp. 299–309. [10] N. Miller , R. Gerlai, Redefini ng m embership in animal groups., Behav ior research methods 43 (4) (2011) 964–970. [11] L. V and der Maa ten, E. Postma, H. V an den Herik, Dimensionali ty reduction: A comparati ve revi ew , TiCC TR 2009–005, Til burg Un iv ersity , The Netherla nds (2009). [12] M. Kirby , Geometric data analysis: an empirical approach to dimensional ity reductio n and the study of pattern s, John W iley & Sons, Inc., 2000. [13] T . F . Cox, M. A. Cox, Multidi mensional scaling , CRC Press, 2010. [14] J. B. T enenbaum, V . De Silva, J . C. L angford, A glob al geometric framewo rk for nonlinear dimensi onality reductio n, Science 290 (5500) (2000) 2319–23 23. [15] N. Abaid, E. Bollt, M. Porfiri, T opologi cal analysis of complex ity in multia gent s ystems, Physica l Revie w E 85 (4) (2012) 041907. [16] P . DeLellis, G. Polv erino, G. Ustuner , N. Abaid, S. Macrì, E. M. Bollt, M. Porfiri, Colle ctiv e behavi our across animal species, Scienti fic reports 4. [17] M. Arroyo, L. Heltai, D. Millán, A . DeSimone, Rev erse engine ering the euglen oid movement, Proceedings of the Nationa l Academy of Science s 109 (44) (2012) 17874–178 79. [18] O. Samko, A. D. Marshall, P . L. R osin, Selection of the opti mal parameter value for th e isomap algorithm, Patt ern Recognit ion Letters 27 (9) (2006) 968–979 . [19] M. E. Tippi ng, C. C. Nh, Sparse kerne l principal component analysis. [20] P . DeLellis, M. Porfiri, E. M. Bollt, T opologic al analy sis of group fragmentati on in multi-agent systems, Physical Revie w E 87 (2) (2013) 022818. [21] H. Li, L. T eng, W . Chen, I.-F . Shen, Supervised learning on local tangent space, in: Adv ances in Neural Netw orks–ISNN 2005, Springer , 2005, pp. 546–551 . [22] R. R. Coifman, S. Lafon, Di ff usion maps, Applied and computatio nal harmonic analysis 21 (1) (2006) 5–30. [23] M. Aureli, F . Fiori lli, M. Porfiri, Port raits of self-or ganizatio n in fish school s intera cting with robots, Physic a D: Nonlinea r Phenomena 241 (9) (2012) 908–920 . [24] T . A. Frewe n, I. D. Couzin, A. Kol pas, J. Moehlis, R. Coifman, I. G. Ke vrekidis, Coarse collecti ve dynamics of animal groups, in: Coping with Comple xity: Model Reduc tion and Data Analysis, Springer , 2011, pp. 299–309. [25] J. Shawe-T aylor , N. Cristianini, Kernel methods for pattern analysis, Cambridge univ ersity press, 2004. [26] D. L. Donoho, C. Grimes, Hessian eigenmaps: L ocally linear embedding technique s for high- dimensional data, Proceedings of the National Academy of Scienc es 100 (10) (2003) 5591–5596 . [27] M. Belkin, P . Niyogi, L aplaci an eigenmaps and spectral technique s for embeddin g and clusteri ng., in: NIPS, V ol. 14, 2001, pp. 585–591. [28] M. Gashler , D. V entura, T . R. Martinez, Iterati ve non-linear dimensional ity reduction with manifold sculpting., in: NIPS, V ol. 8, 2007, pp. 513–520. [29] P . Demartin es, J. Hérau lt, Curvili near component analysis: A self-orga nizing neural network for nonlinea r m apping of data sets, Neural Networ ks, IEE E T ransactions on 8 (1) (1997) 148–154. [30] S. X iang, F . Nie, C. Zhang, C. Zhang, Nonlinear dimensionali ty reducti on with local spline embedding , Kno wledge and Data Engineering, IEEE Tr ansactions on 21 (9) (2009) 1285–1298. [31] J. A. Lee, A . L endasse, M. V erle ysen, Nonli near projecti on with curvili near dista nces: Isomap versus curvilinear distance analysis, N euro- computing 57 (null) (2004) 49–76. [32] W . J. Dominey , Mobbing in coloniall y nesting fishes, especial ly the blueg ill, Lepomis macrochir us, Copeia 1983 (4) (1983) 1086–1088. [33] G. H. Ball, H. D. J., ISOD A T A, A nov el method of data analysis and pattern clasificati on, T ech. rep., Stanford Research Institute (1965). [34] T . Hastie , W . Stu etzle, Principal curves, Journal of the American Statisti cal Ass ociat ion 84 (406) (1989) 502–516. 18 [35] M. H. Protter , Calculu s with Analyt ic Geometry, 4th Edition, Jones and Bartl ett, 1988, Ch. 01, p. 29. [36] S. A. Nene, S. K. Nayar , A simple algorith m for nearest neig hbor search in high dimensions, IEEE T ransactions on Pattern Analysi s and Machine Intell igence 19 (9) (1997) 989–1003. [37] J. MacQue en, Some metho ds for classification and analysis of multi var iate observ ations, in: Proceedings of the fifth Berke ley symposium on Mathemat ics, Statistics and Probabili ty , 1967, pp. 281–297. [38] G. Biau, A. Fischer , Parameter Selecti on for Principal Curve s, IEEE Transact ions on Information Theory 58 (3) (2012) 1924–1939. [39] E. M. Bollt, Attract or Modelin g and Em pirical Nonlinear Model Reduct ion of Dissipat iv e Dynamica l Systems, Internationa l Journal of Bifurca tion and Chaos 17 (4) (2007) 1199–1219. [40] L. van de r Maaten, E. Postma, H. van den Heri k, Matlab toolbox for dimensionalit y reduction, MICC, Maastricht Univ ersity . [41] J. B. T enenbaum, V . de Silva , J. C. Langford, A global geometric frame work for nonli near dimensional ity reduction., Scienc e 290 (5500) (2000) 2319–23 23. [42] W . J. Dominey , Mobbing in coloniall y nesting fishes, especial ly the blueg ill, Lepomis macrochir us, Copeia 1983 (4) (1983) 1086–1088. [43] J. H. Friedman, J. L. Bentle y , R. A. Finkel , An algorithm for finding best matches in logari thmic expect ed time, AC M Tran sactions on Mathemat ical Softwa re (TOMS) 3 (3) (1977) 209–226. [44] R. Balakri shnan, K. Rangana than, A te xtbook of graph theory , Springer , 2012. [45] B. Sha w , T . Jebara, Structure preserving embeddin g, in: Proceedings of the 26th A nnual International Conference on Machine Learning, 2009, pp. 937–944 . [46] N. Mekuz, J. K. Tsotsos, Paramet erless isomap with adapti ve neighborhood selection , Patte rn Recognition 4174 (2006) (2006) 364–373. [47] G. H. Golub, C. F . V an Loan, Matrix computati ons, V ol. 3, JHU Press, 2012. [48] I. Jolli ff e, Principal component analysis, W iley Online Library , 2005. [49] E. W . Dijkstra, A note on two problems in conne xion with graphs, Numerische mathematik 1 (1) (1959) 269–271. [50] C. E. Leiserson, R. L. Ri vest, C. Stein, T . H. Cormen, Introducti on to algorit hms, MIT press, 2001. [51] J. E. Jackson, A user’ s guide to principal component s, V ol. 587, John W iley & Sons, 2005. 19
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment