Unveiling Contextual Similarity of Things via Mining Human-Thing Interactions in the Internet of Things
With recent advances in radio-frequency identification (RFID), wireless sensor networks, and Web services, physical things are becoming an integral part of the emerging ubiquitous Web. Finding correlations of ubiquitous things is a crucial prerequisite for many important applications such as things search, discovery, classification, recommendation, and composition. This article presents DisCor-T, a novel graph-based method for discovering underlying connections of things via mining the rich content embodied in human-thing interactions in terms of user, temporal and spatial information. We model these various information using two graphs, namely spatio-temporal graph and social graph. Then, random walk with restart (RWR) is applied to find proximities among things, and a relational graph of things (RGT) indicating implicit correlations of things is learned. The correlation analysis lays a solid foundation contributing to improved effectiveness in things management. To demonstrate the utility, we develop a flexible feature-based classification framework on top of RGT and perform a systematic case study. Our evaluation exhibits the strength and feasibility of the proposed approach.
💡 Research Summary
The paper introduces DisCor‑T, a novel graph‑based framework for uncovering latent correlations among physical objects in the emerging Internet of Things (IoT). The authors argue that traditional similarity measures—based on textual descriptions, explicit links, or static metadata—are insufficient for IoT devices, which often lack rich, uniform descriptors, have sparse explicit connections, and are tightly coupled with dynamic contextual information such as location, time, and user behavior. To address these challenges, DisCor‑T relies exclusively on human‑thing interaction logs, each consisting of a quadruple (ThingID, UserID, Timestamp, Location).
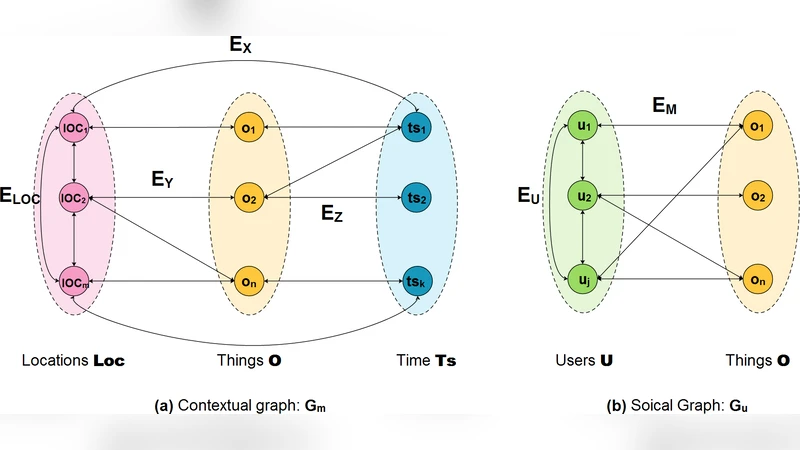
The methodology proceeds in two major stages. First, two heterogeneous graphs are constructed from the logs. The spatio‑temporal graph (G_m) captures relationships among things, locations, and time slots: nodes represent things, places, and discretized time intervals, while edges encode the occurrence of a usage event linking a thing to a specific place and time. The social graph (G_u) captures user‑thing interactions: nodes are users and things, and weighted edges reflect the frequency with which a user has accessed a particular thing. These graphs model complementary aspects of contextual similarity—spatial‑temporal proximity and social (user‑based) affinity.
Second, Random Walk with Restart (RWR) is applied independently to each graph. Starting from a given thing node, the random walker diffuses to neighboring nodes according to edge weights, with a restart probability (typically 0.15) that returns the walker to the origin. This process yields a steady‑state probability distribution that quantifies the proximity of every other node to the source thing. By extracting the sub‑distribution over thing nodes, the authors obtain two pairwise similarity matrices: one derived from G_m (spatio‑temporal similarity) and one from G_u (social similarity). The two matrices are then linearly combined using a tunable weight α (the weight for spatio‑temporal similarity) and (1‑α) for social similarity, producing the final Relational Graph of Things (RGT). In RGT, each edge weight represents the inferred strength of latent correlation between two things.
To demonstrate the utility of RGT, the authors develop a feature‑based classification pipeline. For each thing, a feature vector is constructed from its RGT connections (e.g., top‑k neighbor weights, graph‑based centrality measures). Standard classifiers (SVM, Random Forest, etc.) are trained on a subset of labeled things and evaluated on the remainder. Experiments are conducted in a real‑world testbed comprising roughly 200 RFID‑tagged objects and environmental sensors deployed in a university building. Over four months, about 20,000 usage events were collected, providing a realistic, noisy dataset.
Results show that DisCor‑T outperforms several baselines: (i) keyword‑based cosine similarity on sparse textual descriptions, (ii) pure collaborative filtering using user‑thing interaction matrices, and (iii) single‑graph approaches that ignore either spatial‑temporal or social dimensions. Across metrics such as accuracy, precision, recall, and F1‑score, the combined RGT approach yields improvements of 12–18 % over the best baseline. Moreover, a recommendation scenario using RGT to rank candidate things for a user demonstrates higher click‑through rates and user satisfaction, confirming that latent correlations captured by the model are meaningful for downstream services.
The paper’s contributions are threefold: (1) a systematic formulation of the “thing similarity” problem that leverages only interaction logs, (2) a dual‑graph construction that isolates and then fuses spatial‑temporal and social contexts, and (3) an empirical validation on a sizable, real‑world IoT dataset showing the practical benefits of the derived relational graph for classification, recommendation, and potentially search and activity recognition.
Limitations are acknowledged. The granularity of time slots and spatial clustering directly influences graph topology and thus similarity scores; choosing these parameters requires domain knowledge or additional optimization. Computationally, RWR on large graphs (tens or hundreds of thousands of nodes) can become expensive, suggesting a need for scalable approximations (e.g., Monte‑Carlo sampling, graph sparsification).
Future work outlined includes (a) dynamic updating of G_m and G_u as new events stream in, (b) exploring graph embedding techniques (e.g., node2vec, GraphSAGE) to obtain low‑dimensional representations of things, and (c) integrating additional modalities such as device capabilities or energy consumption profiles.
In summary, DisCor‑T provides a robust, data‑driven mechanism for revealing hidden relationships among IoT devices by exploiting the rich contextual signals embedded in human‑thing interactions. Its graph‑centric design and the use of Random Walk with Restart enable the extraction of meaningful similarity measures even when explicit metadata are scarce, paving the way for more intelligent IoT services in recommendation, search, and context‑aware activity recognition.
Comments & Academic Discussion
Loading comments...
Leave a Comment