A statistical inference course based on p-values
Introductory statistical inference texts and courses treat the point estimation, hypothesis testing, and interval estimation problems separately, with primary emphasis on large-sample approximations. Here I present an alternative approach to teaching…
Authors: Ryan Martin
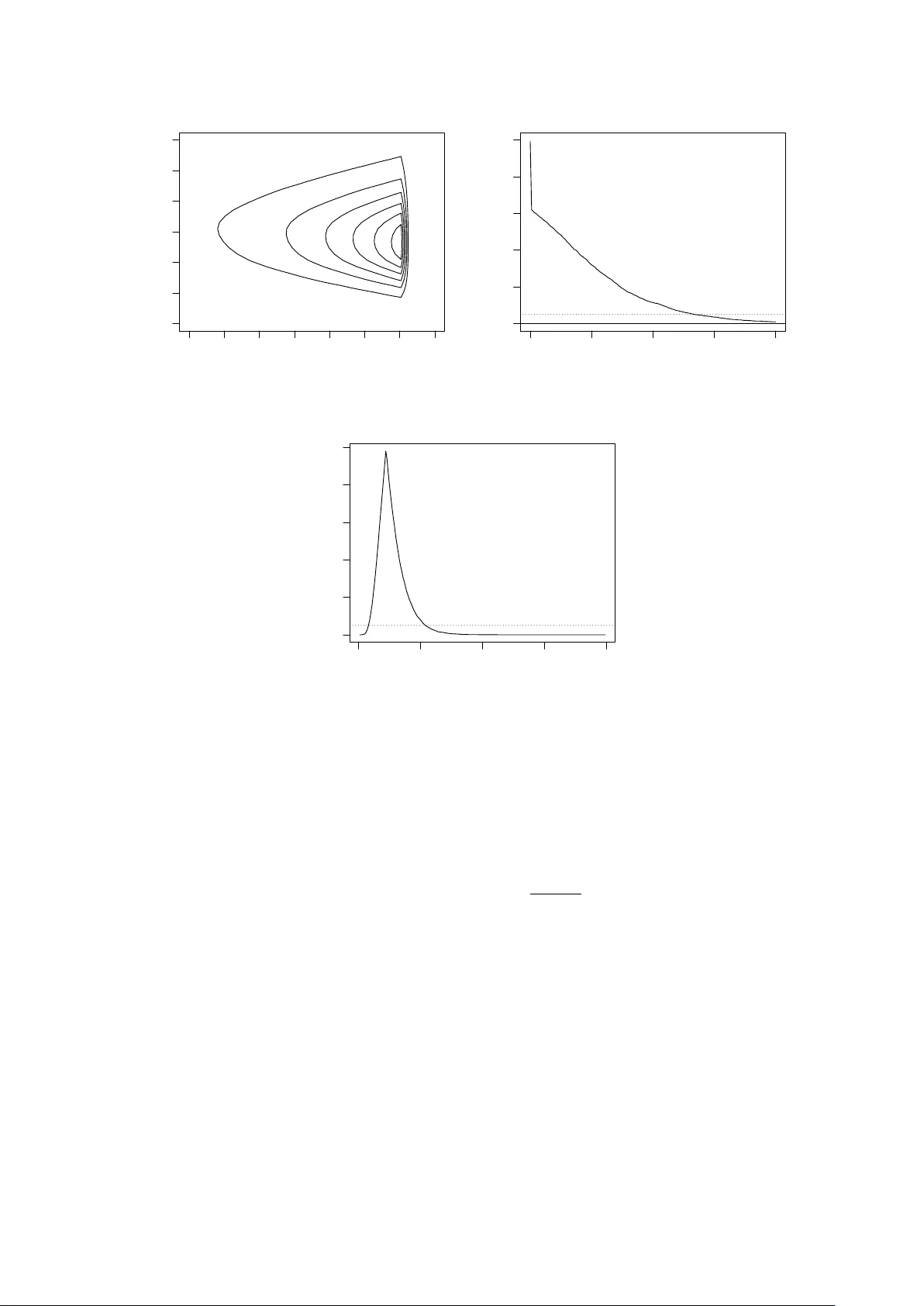
A statistical inference course based on p-v alues Ry an Martin Departmen t of Mathematics, Statistics, and Computer Science Univ ersit y of Illinois at Chicago rgmartin@uic.edu June 9, 2016 Abstract In tro ductory statistical inference texts and courses treat the p oin t estimation, h yp othesis testing, and in terv al estimation problems separately , with primary em- phasis on large-sample approximations. Here I present an alternativ e approach to teac hing this course, built around p-v alues, emphasizing prov ably v alid inference for all sample sizes. Details ab out computation and marginalization are also pro vided, with sev eral illustrativ e examples, along with a course outline. Keywor ds and phr ases: Confidence in terv al; large-sample theory; Mon te Carlo; teac hing statistics; v alid inference. 1 In tro duction Consider a first course in statistical inference, whose target audience is upp er-lev el un- dergraduate and b eginning graduate studen ts in statistics or other quan titative fields suc h as computer science, economics, engineering, and finance. These students t ypi- cally ha v e b een exp osed to some basic statistical metho ds, suc h as t-tests, in a previous course. Moreo v er, the course is question is usually the second course in a “probability + statistics” sequence, so the studen ts are assumed to ha v e bac kground in (calculus- based) probability , which co vers random v ariables and their distributional prop erties; in particular, students will ha v e had at least an introduction to sampling distributions and k ey results lik e the law of large num b ers and central limit theorem. Commonly used textb o oks for this statistics theory course include: Casella and Berger (1990), W ac k erly et al. (2008), and Hogg et al. (2012). A typical course outline for the first statistical theory course starts with a review of sampling distributions and pro ceeds with details ab out point estimation, hypothesis testing, and confidence in terv als, in turn. As a result of this structure, and the amoun t of material to b e co vered, the ma jority of the course is sp en t on p oin t estimation and its prop erties, e.g., unbiasedness, consistency , etc, leaving v ery little time at the end to cov er h yp othesis testing and confidence in terv als. This is unfortunate b ecause it gives students the wrong impression that p oin t estimation is the priorit y , with hypothesis tests and confidence in terv als of only secondary importance. F or statistics students, this skew ed persp ectiv e would ev entually get straigh tened out in their 1 more adv anced courses. F or the non-statistics students, how ev er, the course in question ma y b e their only serious exp osure to statistical theory , so it is essen tial that it b e more efficien t, fo cusing more on the essentials of statistical inference, rather than unnecessary and out-dated technical details. In this pap er, I will describ e a new approac h to present- ing the core concepts of a statistical inference course, built around the familiar p-v alue, and inspired in part by recen t work in Martin and Liu (2015). Despite the con tro versies surrounding hypothesis testing and p-v alues (e.g., Fidler et al. 2004; Schervish 1996), including the recen t ban of p-v alues in Basic and Applie d So cial Psycholo gy (T rafimow a and Marks 2015), statisticians kno w the v alue of these to ols; see the official statement 1 from the American Statistical Asso ciation, along with commen ts. In particular, p-v alues can be used to construct hypothesis tests with desired frequen tist T yp e I error rate con trol, and these p-v alue-based tests can b e inv erted to obtain a corresp onding confidence interv al. It is in this sense that m y prop osed framework is built around the p-v alue so, from a technical p oint of view, there is nothing new or surprising presented here. How ev er, there are a n um b er of imp ortan t consequences of the prop osed approac h. • P-v alues are familiar to students from their basic statistics course(s), so the tran- sition to using p-v alues in a more fundamental wa y in this course ough t to b e relativ ely smo oth. Studen ts understanding what a p-v alue me ans is not essential. • Hyp othesis testing, confidence in terv als, and p oin t estimation (if necessary) can all b e handled via a single p-v alue function which streamlines the presentation. • Core topics in a statistics theory course, suc h as likelihoo d, maxim um lik eliho o d, and sufficiency , fit naturally in the prop osed course through the construction and computation of the p-v alue function. • F or simple examples, the p-v alue function can b e computed analytically , and this allo ws the instructor to co v er the standard distribution theory results, in particu- lar, piv ots. Bey ond the simple examples, n umerical metho ds are needed, and this pro vides an opp ortunit y for statistical soft w are (e.g., R, R Core T eam 2015) and Mon te Carlo metho ds to b e presen ted and applied in a statistics theory course. • All the usual examples can b e solv ed either analytically or numerically , so asymp- totic theory w ould not b e a high priority in the prop osed course. Indeed, the role of asymptotic theory is just to demonstrate a unification of the examples and to pro vide simple p-v alue function approximations. Ov erall, I b eliev e that this p-v alue-cen tric course, which puts primary fo cus on prov ably v alid inference and computation, strik es the righ t balance betw een what is co v ered in a standard statistics theory course and the modern ideas and to ols that students need. Moreo v er, it provides a more accurate picture of what statistical inference is ab out, compared to the traditional message that ov er-emphasizes asymptotic approximations. The remainder of the pap er is organized as follo ws. Section 2 sets the notation, giv es some background on the p-v alue, and presents the basic p-v alue-based approach. The k ey is that it is conceptually straigh tforward to construct tests and confidence regions based on the p-v alue that are pro v ably exact, or at least conserv ative. This p-v alue 1 http://amstat.tandfonline.com/doi/abs/10.1080/00031305.2016.1154108 2 function can be computed analytically in only a few textb o ok examples (see Section 2.2), so more sophisticated to ols are needed. Section 3 presents some details that go b ey ond the basics, including Mon te Carlo metho ds for ev aluating the p-v alue function, tec hniques for handling n uisance parameters, and asymptotic approximations. Some more c hallenging examples are presented in Section 4, and Section 5 provides a sk etc h of a course outline. Some concluding remarks are given in Section 6. R code for the examples is av ailable as Supplemen tary Material. 2 Inference based on p-v alues—the basics 2.1 Key ideas Supp ose w e ha v e observ able data Y with sampling model P θ , kno wn up to the v alue of the parameter θ , which takes v alues in Θ. Both the data and parameter can be v ectors, and it is not necessary to assume indep endence, etc. Arguably the most fundamen tal statistical problem is h yp othesis testing, and the simplest v ersion tak es the n ull hypothesis as H 0 : θ = θ 0 , for fixed θ 0 ∈ Θ; for the alternativ e h ypothesis, here I tak e H 1 : θ 6 = θ 0 , but other c hoices can b e made dep ending on the context. In my experience, students can relate to this problem and the logic behind the solution, i.e., H 0 iden tifies our “expectations,” and if the observ ation differs to o m uch from these exp ectations, then there is doubt ab out the truthfulness of H 0 . More formally , consider a test statistic T θ 0 ( Y ) and, without loss of generality , assume that large v alues of T θ 0 ( Y ) cast doubt on H 0 , suggesting that H 0 b e rejected. As a measure of the amoun t of supp ort in observ ed data Y = y in the truthfulness of H 0 : θ = θ 0 , consider the p-v alue p y ( θ 0 ) = P θ 0 { T θ 0 ( Y ) ≥ T θ 0 ( y ) } . (1) It is w ell-kno wn that the p-v alue is not the probabilit y that H 0 is true, but it do es carry some relev an t information, i.e., if p y ( θ 0 ) is small, then the observ ation y is extreme compared to exp ectations under H 0 , thereb y casting doubt on H 0 . This intuition can be used to dev elop a formal testing rule, that is, one can reject H 0 , based on observ ation Y = y , if and only if p y ( θ 0 ) ≤ α , where α ∈ (0 , 1) is a pre-determined significance lev el. It can easily b e sho wn that this rule has T yp e I error probability ≤ α ; if the n ull distribution of T θ 0 ( Y ) is con tin uous, then equality is attained. I hav e fo cused so far on simple n ull hypotheses, i.e., H 0 : θ = θ 0 , but more general cases can b e handled similarly . Indeed, if the null h yp othesis is H 0 : θ ∈ Θ 0 , for some subset Θ 0 of Θ, then, with a slight abuse of notation, the p-v alue is expressed as p y (Θ 0 ) = sup ϑ ∈ Θ 0 p y ( ϑ ) , (2) the largest of the p-v alues asso ciated with a simple n ull consistent with Θ 0 . The jumping off p oin t here is that the p-v alue do es not need to b e tied to a sp ecific n ull h yp othesis. That is, define T θ ( Y ) as a function of data Y and parameter θ and define the p-value function p y ( θ ) = P θ { T θ ( Y ) ≥ T θ ( y ) } , θ ∈ Θ . (3) In other contexts, the p-v alue function has b een giv en a different name, e.g., pr efer enc e functions (Sp jøtvoll 1983), c onfidenc e curves (Birn baum 1961; Blaker and Sp jøtvoll 2000; 3 Sc h weder and Hjort 2002, 2016; Xie and Singh 2013), signific anc e functions (F raser 1991), and plausibility functions (Martin 2015). I prefer the latter name b ecause it has a nice in terpretation, though here I stick with “p-v alue function” b ecause that name is familiar to students and is commonly used in the literature. Names aside, the key observ ation is that the distributional prop erties of the p-v alue used ab o v e to justify the p erformance of the test extend in a natural wa y b ey ond the h yp othesis testing con text. That is, P θ { p Y ( θ ) ≤ α } ≤ α, α ∈ (0 , 1) , θ ∈ Θ . (4) As a particular application, take a fixed α ∈ (0 , 1) and define the set C α ( y ) = { θ : p y ( θ ) > α } . (5) This can b e in terpreted as the set of all θ v alues which are “sufficiently plausible” giv en the observ ation Y = y . F ormally , it follo ws from (4) that C α ( Y ) is a 100(1 − α )% confidence region for θ in the sense that the cov erage probabilit y is at least 1 − α ; cov erage is exact if T θ ( Y ) has a con tin uous distribution. More abstractly , for any A ⊂ Θ, one can view p y ( A ), defined as in (2), as a measure of ho w plausible is the claim “ θ ∈ A ” based on observ ation Y = y , and the distributional results abov e guaran tee a particular v alidit y or calibration prop ert y: in standard terms, a test which rejects H 0 : θ ∈ A when p y ( A ) ≤ α will control T yp e I error at level α . If desired, one can also construct a p oin t estimator based on the p-v alue function by solving the equation p y ( θ ) = 1 for θ . In terms of the confidence region in (5), this v alue of θ is one that is con tained in al l 100(1 − α )% confidence regions as α ranges ov er (0 , 1). As an example, supp ose that T θ ( y ) is the likelihoo d ratio statistic, defined as T θ ( y ) = L y ( ˆ θ ) L y ( θ ) (6) where L y ( θ ) is the lik eliho o d function based on data y and ˆ θ = ˆ θ ( y ) is the maximum lik eliho o d estimator, a maximizer of the likelihoo d function, i.e., L y ( ˆ θ ) = sup θ L y ( θ ) . I wan t to stick with the conv ention of rejecting H 0 when T θ ( Y ) is large, so I am using the recipro cal of the usual likelihoo d ratio statistic. With this choice of T θ ( y ), setting p y ( ˜ θ ) = 1 implies P ˜ θ { T ˜ θ ( Y ) ≥ T ˜ θ ( y ) } = 1. This means that T ˜ θ ( y ) is at the low er b ound of the range of T ˜ θ ( Y ) when Y ∼ P ˜ θ , in other words, ˜ θ minimizes the function T θ ( y ) with resp ect to θ , for the given y . By the definition of T θ ( y ) in (6), w e hav e T θ ( y ) ≥ 1, and equalit y is obtained if and only if ˜ θ maximizes L y ( θ ). Therefore, the “maximum p-v alue estimator” ˜ θ is just the maxim um likelihoo d estimator ˆ θ . There is nothing new here in terms of theory , at most all that changes is how the information in data is summarized in the p-v alue function (3) for the goal of inference on θ . The k ey p oin t is that the usual tasks asso ciated with statistical inference are conceptually straigh tforw ard once the p-v alue function has b een found, and the resulting inference is valid in the sense that there are prov able guaran tees on the frequen tist error rates. This sort of unification of the common inferen tial tasks should mak e the concepts easier for 4 studen ts. Another point is that the properties of the p-v alue-based procedures discussed ab o v e do not require asymptotic justification. This is interesting from a theoretical p oin t of view, but this also has p edagogical consequences. In particular, even the students who can follo w the technical details of the asymptotic conv ergence theorems ha ve difficulty seeing how it relates to the problem at hand, so removing or at least down-w eigh ting the imp ortance of asymptotics would b e b eneficial. This is not to say that asymptotic considerations are not useful; see Section 3.3. The take-a w a y message is that the p-v alue function (3) is a useful and arguably fun- damen tal ob ject for the purp ose of statistical inference. Studen ts will see that ev aluating the p-v alue function is the biggest challenge and, fortunately , this is a concrete mathe- matical/computational problem with lots of to ols av ailable to solve it. 2.2 First examples Here I will present a few of the standard examples from an in tro ductory statistical in- ference course from the p oin t of view describ ed ab o v e, treating the p-v alue function as the k ey ob ject. No w that it is time to put this prop osal into action, an ob vious question arises: which test statistic T θ ( Y ) to use? F or the sak e of ha ving a consistent presen tation, along with other reasons discussed in Section 5, I will tak e T θ ( Y ) to be the likelihoo d ratio statistic in (6). Of course, other choices of T θ ( Y ) can b e used, e.g., based on well-kno wn piv ots for the particular mo dels, but I will leav e this decision to the instructor. 2.2.1 Normal mo del Let Y = ( Y 1 , . . . , Y n ) b e an independent and iden tically distributed (iid) sample from a normal distribution N ( θ , 1) with known v ariance but unknown mean. The maximum lik eliho o d estimator is ˆ θ = ¯ Y , the sample mean, and the likelihoo d ratio statistic is T θ ( Y ) = L Y ( ˆ θ ) L Y ( θ ) = e n 2 ( ¯ Y − θ ) 2 . It is well kno wn that 2 log T θ ( Y ) = n ( ¯ Y − θ ) 2 has a ChiSq (1) distribution, so the p-v alue function (3) is simply p y ( θ ) = 1 − G 2 log T θ ( y ) , where G is the ChiSq (1) distribution function. A plot of this p-v alue function is sho wn in Figure 1(a) for the case of n = 10 and ¯ y = 7. It is straightforw ard to c heck that the p-v alue interv al (5) is exactly the standard z-interv al found in textb o oks. 2.2.2 Uniform mo del Let Y = ( Y 1 , . . . , Y n ) b e an iid sample from Unif (0 , θ ), a con tinuous uniform distribution on the in terv al (0 , θ ), where θ > 0 is unknown. The maximum lik eliho o d estimator, in this case, is ˆ θ = Y ( n ) , the sample maxim um. Using the lik eliho od ratio statistic, the p-v alue function (3) is easily seen to b e p y ( θ ) = ( F n ( y ( n ) /θ ) if θ ≥ y ( n ) 0 if θ < y ( n ) , 5 6.0 6.5 7.0 7.5 8.0 0.0 0.2 0.4 0.6 0.8 1.0 θ p−value (a) Normal: n = 10, ¯ y = 7 7 8 9 10 11 0.0 0.2 0.4 0.6 0.8 1.0 θ p−value (b) Uniform: n = 10, y ( n ) = 7 4 6 8 10 12 14 16 0.0 0.2 0.4 0.6 0.8 1.0 θ p−value (c) Exp onen tial: n = 10, ¯ y = 7 0.0 0.2 0.4 0.6 0.8 1.0 0.0 0.2 0.4 0.6 0.8 1.0 θ p−value (d) Binomial: n = 20, y = 13 Figure 1: Plots of the p-v alue function for the four examples in Section 2.2. where F n is the Beta ( n, 1) distribution function. A plot of this p-v alue function is sho wn in Figure 1(b), with n = 10 and y ( n ) = 7. Note, also, that the equation p y ( θ ) = α has exactly one solution, i.e., θ = y ( n ) /F − 1 n ( α ). Therefore, the exact 100(1 − α )% p-v alue confidence interv al for θ is [ y ( n ) , y ( n ) /F − 1 n ( α )). 2.2.3 Exp onen tial mo del Let Y = ( Y 1 , . . . , Y n ) b e an iid sample from the exponential distribution with unknown mean θ > 0. The maxim um likelihoo d estimator is ˆ θ = ¯ Y , and the likelihoo d ratio is T θ ( Y ) = L Y ( ˆ θ ) L Y ( θ ) = ¯ Y θ − n e n ( ¯ Y /θ − 1) . The distribution of T θ ( Y ) is not of a standard form, but there are sev eral w a ys to ev aluate the p-v alue function. First, lev el sets of the function z 7→ z − n e n ( z − 1) are interv als, and 6 can b e found numerically using bisection, say; then the fact that n ¯ Y has a Gamma ( n, θ ) distribution can b e used to ev aluate the p-v alue numerically using, e.g., the pgamma function in R. Second, since the distribution of ¯ Y /θ is free of θ , the p-v alue function can b e appro ximated using Monte Carlo, using only a single Mon te Carlo sample; see Section 3.1. A plot of the p-v alue function based on n = 10 and ¯ y = 7 is sho wn in Figure 1(c); observ e the asymmetric shape compared to the normal model. The p-v alue- based confidence interv al in (5) can be found n umerically; in this case, the 95% confidence in terv al is (3 . 98 , 14 . 07). 2.2.4 Binomial mo del Let Y ∼ Bin ( n, θ ) b e a binomial observ ation, with the n um b er of trials n known but success probability θ ∈ (0 , 1) unkno wn. The maxim um lik eliho o d estimator is ˆ θ = Y /n , and the lik eliho o d ratio statistic is T θ ( Y ) = Y nθ Y n − Y n (1 − θ ) n − Y . There is no clean expression for the corresp onding p-v alue but, since the binomial dis- tribution is supp orted on the finite set { 0 , 1 , . . . , n } , it is p ossible to enumerate all the v alues of Y suc h that T θ ( Y ) ≥ T θ ( y ), where y is the observ ed count. Then the p-v alue function (3) can b e computed b y just summing up the probability masses associated with these v alues of Y . A plot of this p-v alue function, based on n = 20 and y = 13 is sho wn in Figure 1(d). The stair-step shap e of the curve is a consequence of the discreteness. Note that this p-v alue-based approac h to confidence in terv al construction is v ery different from the usual W ald in terv al that is t ypically taught, but differen t is arguably b etter in this case given that the latter is known to b e problematic (Bro wn et al. 2001). The n umerical results in this case are similar, how ever: the 95% p-v alue in terv al is (0 . 42 , 0 . 86) and the corresp onding W ald in terv al is (0 . 44 , 0 . 86). 3 Bey ond the basics 3.1 Computation Except for basic problems, lik e those in Section 2.2, the p-v alue function cannot b e written in closed-form. How ev er, it is straigh tforw ard to obtain a Mon te Carlo approximation thereof. That is, if Y (1) , . . . , Y ( M ) are indep enden t samples from the model P θ , where M is large, then the law of large n umbers implies that p y ( θ ) ≈ 1 M M X m =1 I { T θ ( Y ( m ) ) ≥ T θ ( y ) } . (7) This can be rep eated for as many v alues of θ 0 as necessary to, sa y , dra w a graph of the p- v alue fun ction. Dep ending on the task at hand, certain prop erties of the appro ximation to p y ( · ) m ust b e extracted. F or example, in hypothesis testing, based on the general form ula (2), optimization of the right-hand side of (7), with resp ect to θ , is needed. Similarly , to obtain the confidence region (5), solutions to the equation p y ( θ ) = α are needed. 7 There are a v ariety of w a ys to solv e each of these problems. A simple naiv e solution can b e obtained b y taking a sufficiently fine discretization of the parameter space, e.g., appro ximating the suprem um in p y (Θ 0 ) by the maxim um of p y ( ϑ ) for ϑ ranging ov er a finite grid spanning Θ 0 . Alternatively , one can apply standard optimization and ro ot- finding pro cedures to the appro ximation in (7). F or example, in R, the uniroot and optim functions can b e used for ro ot-finding and optimization. F or numerical stabilit y , it is advised that one use the same seed in the random num b er generator when ev aluating b oth p y ( θ ) and p y ( θ 0 ). More details can b e found in the examples in Section 4. An obvious concern is that the prop osed Monte Carlo approximation in (7) might b e terribly expensive, esp ecially if it needs to b e repeated for several v alues of θ . As a first idea to wards sp eeding things up, observ e that T θ ( Y ) often dep ends only on some function of Y , i.e., a sufficient statistic, so it may not b e necessary to simulate copies of the full data Y at each step of the Mon te Carlo approximation. Second, it may b e that the problem under consideration has a sp ecial structure so that the distribution of T θ ( Y ), under Y ∼ P θ , do es not dep end on θ , i.e., that T θ ( Y ) is a pivot . In that case, the same samples Y (1) , . . . , Y ( M ) can b e used for all v alues of θ , which significantly sp eeds up the computation of the p-v alue function at different parameter v alues. Third, in light of the impro v ed sp eed in the pivotal case, it is natural to ask if it is p ossible to use only a single Mon te Carlo sample ev en in the non-pivotal case. A t least in some cases, the answer is YES. In particular, one can emplo y an imp ortanc e sampling technique (e.g., Lange 2010), whereb y a single Monte Carlo sample Y (1) , . . . , Y ( M ) is dra wn from a distribution with (join t) density function f ( y ), and (7) is replaced by p y ( θ ) ≈ 1 M M X m =1 I { T θ ( Y ( m ) ) ≥ T θ ( y ) } p θ ( Y ( m ) ) f ( Y ( m ) ) , where p θ ( y ) is the (join t) density function for Y ∼ P θ . Of course, the qualit y of this imp ortance sampling appro ximation dep ends hea vily on the choice of f , so this needs to b e addressed, but there are some general rules of th um b av ailable. 3.2 Handling n uisance parameters Standard textb ooks do not adequately address the difficulties that arise from the presence of n uisance parameters. Supp ose that the unknown parameter θ can b e partitioned as ( ψ , λ ), where ψ is the interest parameter and λ is the n uisance parameter; b oth ψ and λ can b e v ectors. Except for a bit about profile likelihoo d, as I discuss below, and p erhaps a few normal examples where marginalization is relativ ely easy , textb o oks focus primarily on asymptotics and W ald-st yle metho ds where an estimator ˆ λ is plugged in for λ in the asymptotic v ariance of the estimator ˆ ψ of ψ . The simplicit y of this approach comes at a price: the plug-in estimator of the v ariance can ov er- or under-estimate the actual v ariance, so it ma y not adequately address uncertaint y . Marginalization is one of the most difficult problems in statistical inference, so there is no wa y to give a completely satisfactory solution in a first course on the sub ject. Ho w ever, there are some general and relativ ely simple techniques that can b e presen ted to students whic h, together with a warning ab out the difficulty of marginal inference on ψ , ough t to suffice. Here I will presen t tw o distinct approaches to marginalization, b oth relying on opti- mization. The first is a familiar one, namely , pr ofiling . In particular, the profile lik eliho od 8 ratio statistic is T ψ ( Y ) = sup ψ ,λ L Y ( ψ , λ ) sup λ L Y ( ψ , λ ) . (8) The righ t-hand side do es not explicitly depend on the nuisance parameter λ , but its dis- tribution migh t. There are sp ecial cases where the distribution of the profile lik eliho o d ratio T ψ ( Y ) is free of λ , in which case a “marginal p-v alue function” can b e obtained without knowing λ , even if Monte Carlo metho ds are needed. Checking that the distri- bution of the profile lik eliho o d ratio do es not dep end on the n uisance parameter migh t b e a difficult exercise, but there are cases where it can b e done; see, Section 4. Problem- sp ecific considerations might also lead to a different choice of test statistic, other than profile likelihoo d ratio, that has a λ -free distribution. There are also some reasonable λ -free approximations a v ailable, as discussed in Section 3.3. The second optimization-based approac h to marginalization starts with the formula (2) for the p-v alue under a comp osite null hypothesis. Indeed, the marginal inference problem can be reduced to one that in volv es a comp osite n ull hypothesis, where the n ull sp ecifies no constrain ts on the nuisance parameter. This suggests that a marginal p-v alue function for ψ can b e expressed, with a sligh t abuse of notation, as follows: p y ( ψ ) = sup λ p y ( ψ , λ ) , where the righ t-hand side is the largest of the original p-v alues in (1) corresponding to a fixed v alue of the interest parameter. So, those p oin ts ab out optimization of the p-v alue function discussed in Section 3.1 are relev an t again here for marginal inference. 3.3 Asymptotic appro ximations An in teresting feature of the prop osed approac h is that one could p otentia lly fill a first course on statistical inference without any serious discussion of asymptotic theory . I do not necessarily recommend that asymptotic theory b e left out en tirely , but I think its imp ortance needs to b e do wnpla y ed compared to the traditional first course. Studen ts should b e encouraged to do exact (analytical or n umerical) calculations whenever possible, only appealing to appro ximations when the exact calculations cannot b e done, either b ecause the computations are to o hard or b ecause the mo del assumptions are to o v ague to determine what exact calculations need to b e done. In my opinion, it is in this sense that the relev an t asymptotic theory should be presen ted in a first statistical theory course. T o be concrete, let Y = ( Y 1 , . . . , Y n ) b e an iid sample from a distribution P θ , with θ a scalar, and supp ose that the lik elihoo d ratio statistic (6) is used to determine the p-v alue; the commen ts to b e made here apply almost w ord-for-w ord to the profile lik elihoo d ratio statistic (8) for marginal inference. P erhaps the most imp ortan t asymptotic result in a first statistical theory course is the theorem of Wilks (1938), which giv es a large-sample appro ximation to the distribution of the likelihoo d ratio statistic, i.e., under suitable regularit y conditions, 2 log T θ ( Y ) = 2 log L Y ( ˆ θ ) L Y ( θ ) → ChiSq (1) in distribution . 9 Therefore, if the regularity conditions hold, then the p-v alue can b e approximated b y p y ( θ ) ≈ 1 − G 2 log T θ ( y ) , where G is the ChiSq (1) distribution function. In this case, all the relev an t calculations for h yp othesis testing and/or in terv al estimation are straightforw ard. More refined higher- order approximation results are av ailable (e.g., Brazzale et al. 2007), but these may b e to o adv anced for a first course. My p osition on the role of asymptotic theory might b e contro v ersial, so let me elab- orate a bit here in closing. Studen ts who will choose to get more adv anced training will learn more ab out asymptotic theory whic h, e.g., can b e used to justify a choice of T θ ( Y ). But the main goal of this first statistics theory course should b e that studen ts develop a basic understanding of what statistical inference is and ho w it can be done; to me, making clear that the primary role play ed by asymptotic theory is for simple approximations is a necessary step tow ard this goal. 4 More c hallenging examples 4.1 Shifted exp onen tial mo del Let Y = ( Y 1 , . . . , Y n ) b e an iid sample from a shifted exp onen tial distribution with com- mon density function y 7→ β − 1 e − ( y − µ ) /β , for y ≥ µ , where θ = ( µ, β ) is unkno wn, where µ is a lo cation parameter and β is a scale parameter. This is a sp ecial case of class of non-regular problems considered in Smith (1985), kno wn to b e relativ ely difficult since the usual asymptotic theory for, say , the maxim um lik eliho o d estimator do es not hold. In this case, the profile likelihoo d ratio is T θ ( Y ) = ( 1 β P n i =1 ( Y i − Y (1) ) − n e 1 β P n i =1 ( Y i − µ ) − n , if Y (1) ≥ µ, ∞ , if Y (1) < µ. F rom here, it is relatively easy to see that T θ ( Y ) is a pivot, i.e., if θ is the true v alue of the parameter, the distribution of T θ ( Y ) do es not dep end on θ . This mak es ev aluation of the p-v alue function, via Monte Carlo, straigh tforward. F or simulated data of size n = 25 with true v alues µ = 7 and β = 3, a plot of the (biv ariate) p-v alue function is shown in Figure 2(a). Note the non-elliptical shap e, indicative of a “non-regular” problem. 4.2 Normal random-effects mo del A simple normal random-effects mo del assumes that Y = ( Y 1 , . . . , Y n ) are indep enden tly distributed, with Y i ∼ N ( µ i , σ 2 i ), i = 1 , . . . , n , where the means µ 1 , . . . , µ n are unknown, but the v ariances σ 2 1 , . . . , σ 2 n are taken to b e kno wn. The “random-effects” p ortion of the mo del comes from the assumption that µ 1 , . . . , µ n are iid N ( λ, ψ 2 ) samples, where θ = ( ψ , λ ) is unknown. Here ψ ≥ 0 is the parameter of interest. This mo del can b e recast in a non-hierarchical form; that is, Y 1 , . . . , Y n are indep en- den t, with Y i ∼ N ( λ, σ 2 i + ψ 2 ), i = 1 , . . . , n . Here the maximizer of the lik eliho o d o ver λ , 10 µ β 7.00 7.05 7.10 7.15 7.20 7.25 7.30 7.35 2.0 2.5 3.0 3.5 4.0 4.5 5.0 (a) Shifted exp onen tial, Sec. 4.1 0 5 10 15 20 0.0 0.2 0.4 0.6 0.8 1.0 ψ p−value (b) Normal random-effects, Sec. 4.2 −1.0 −0.5 0.0 0.5 1.0 0.0 0.2 0.4 0.6 0.8 1.0 ψ p−value (c) Biv ariate normal, Sec. 4.3 Figure 2: Plots of the p-v alue function for the three examples in Section 4. for giv en ψ , is ˆ λ ψ = P n i =1 w i ( ψ ) Y i / P n i =1 w i ( ψ ), where w i ( ψ ) = 1 / ( σ 2 i + ψ 2 ), i = 1 , . . . , n . F rom here it is easy to write down the profile likelihoo d, L Y ( ψ , ˆ λ ψ ) = n Y i =1 ( σ 2 i + ψ 2 ) − 1 / 2 e − 1 2( σ 2 i + ψ 2 ) ( Y i − ˆ λ ψ ) 2 , and the profile likelihoo d ratio T ψ ( Y ), as in (8), can b e ev aluated numerically using an optimization routine. Moreo v er, since λ is a lo cation parameter, one can see that the distribution of T ψ ( Y ) do es not depend on λ . Therefore, any c hoice of λ (e.g., λ = 0) will suffice for computing the p-v alue function for ψ based on Mon te Carlo. F or a concrete example, consider the SA T coac hing problem presen ted in Rubin (1981). Here n = 8 coac hing programs are ev aluated, and inference on ψ is required. In particular, the case of ψ = 0 is of inferential imp ortance, as it indicates that there is no difference b et w een the v arious coaching programs. Figure 2(b) shows a plot of the marginal p- v alue function for ψ for the given data, and the corresp onding 95% confidence in terv al 11 is [0 , 13 . 40). Since the interv al con tains zero, one cannot exclude the p ossibility that the coac hing programs ha v e no effect, consisten t with Rubin’s conclusion. Note also that the confidence interv al in this case has guaranteed frequen tist cov erage prop erties, while other approaches, based only on asymptotics might not b e justifiable here, since only n = 8 samples are av ailable. 4.3 Biv ariate normal mo del Consider a sample of indep endent observ ations Y = { ( Y i 1 , Y i 2 ) : i = 1 , . . . , n } from a biv ariate normal distribution where the tw o means, t w o v ariances, and correlation are all unkno wn. That is, the unknown parameter is θ = ( ψ , λ ), where the correlation co efficien t ψ is the parameter of in terest, and λ = ( µ 1 , µ 2 , σ 1 , σ 2 ) is the n uisance parameter. F rom the calculations in Sun and W ong (2007), the profile likelihoo d ratio is T ψ ( Y ) = (1 − ψ ˆ ψ ) / (1 − ψ 2 ) 1 / 2 (1 − ˆ ψ 2 ) 1 / 2 n , where ˆ ψ is the sample correlation co efficien t. A well known prop erty of the correlation co efficien t is that it do es not change if data are sub jected to a linear transformation. In this case, this implies that the distribution of T ψ ( Y ) does not depend on λ . Therefore, the p-v alue function for ψ can b e ev aluated via Mon te Carlo, b y simulating from a biv ariate normal with an y conv enien t choice of λ . F or an illustration, I revisit the example in Sun and W ong (2007). The data, from Levine et al. (1999), measure the increase in energy use y 1 and the fat gain y 2 for n = 16 individuals, and the sample correlation co efficien t is ˆ ψ = − 0 . 77. A plot of the p-v alue function for ψ is shown in Figure 2(c), based on Mon te Carlo. The corresp onding 95% confidence in terv al is ( − 0 . 918 , − 0 . 461), which is very similar in this case to Fisher’s classical interv al based on the distribution of z = 1 2 log { (1 + ˆ ψ ) / (1 − ˆ ψ ) } . 5 On implemen ting the prop osal Here I will describ e ho w I would teac h a course based on this prop osal. First, the usual prerequisite for an in tro ductory statistical inference course is a semester of calculus-based probabilit y , in whic h studen ts w ould ha v e learned v arious things, including the definitions and prop erties of the standard distributions. So, except for p ossibly giving a brief review at the b eginning of the course, I w ould not co ver probabilit y topics sp ecifically . I ha ve advocated here a general approach based on likelihoo d or profile lik eliho o d ratios, and I hav e t w o reasons for doing this. First, having a sort of fixed choice for the test statistic can giv e the presen tation some needed unification, compared to using the “b est” or “most conv enien t” choice for eac h problem. Second, b y putting an emphasis on lik eliho o d, some of the familiar topics from a standard introductory statistical inference course hav e a natural place in this new t yp e of course. In particular: • The interpretation of the likelihoo d function as providing a “ranking” of the pa- rameter v alues in terms of how well the corresp onding mo del fits the given data is imp ortant, motiv ating maximum lik eliho o d estimation and also the comparison of L Y ( θ ) to L Y ( ˆ θ ) in this prop osed approach. These discussions ab out likelihoo d 12 also help to mak e clear to studen ts that a change of p ersp ectiv e is needed to go from thinking ab out sampling mo dels for data to thinking ab out inference based on observed data. • The notion of sufficient statistics is fundamental, and can b e presented here, via the factorization theorem, as the function of data up on which the likelihoo d ratio dep ends. Sufficiency is helpful in the present approach mainly b ecause it can b e used to simplify ev aluation of the p-v alue function. • The quadratic appro ximation of the log-lik eliho o d function is k ey to all the relev ant (lik eliho o d-based) asymptotic results presen ted in a first statistical inference course, so if the new style of course also fo cuses on likelihoo d ratios, these results can b e seamlessly included based on the discussion in Section 3.3. After in tro ducing lik eliho o d ratios and other relev an t background, the course can no w pro ceed to inference based on p-v alues. I w ould begin b y presen ting, in an informal w a y , a v ery basic h yp othesis testing problem to motiv ate the p-v alue. F rom here, I would follow with the formal definition of the p-v alue function and a detailed demonstration of the prop erties it satisfies, as discussed in Section 2.1. Then I w ould proceed to w ork out some relativ ely simple examples, such as those presen ted in Section 2.2. V arious results are used to solv e these examples, e.g., that Y ( n ) /θ in the Unif (0 , θ ) problem of Section 2.2.2 has a b eta distribution, and these could b e assigned as homew ork. The next part of the course, based on the ideas presented in Section 3, is where things start to get more interesting and new. Here students will b e in tro duced to some basic computational tools needed to implemen t the prop osed approach for statistical inference based on the p-v alue. Dep ending on the background of studen ts in the class, the instruc- tor may need to take some time to introduce a statistical softw are pac k age, and I would recommend using R. This is time well- sp en t, I b eliev e, b ecause studen ts will need this bac kground anyw ay and, moreo v er, studen ts need to understand that no serious w ork can b e done without knowledge of b oth theory and computation. In the discussion of the basic Mon te Carlo strategy , I would highligh t the imp ortance of pivots; this concept app ears in standard textbo oks but is not giv en the emphasis it deserv es. In this context, piv ots are sp ecifically helpful for simplifying and accelerating the Mon te Carlo approxi- mations. Marginalization, as discussed in Section 3.2, is a difficult problem that requires care, and both distributional and computational tric ks can be emplo y ed for this purp ose. Then, finally , asymptotic theory can b e presen ted as a means to get a go o d appro xi- mation to the p-v alue function in complicated problems. Of course, the appro ximation theorem, with the required regularity conditions, should b e carefully stated and maybe ev en prov ed. W orking numerical examples can b e discussed along the wa y in class to compare the results of the v arious approaches: exact analytical, Monte Carlo-based, and asymptotically approximate solutions. The course would end with a discussion of several non-trivial examples implemen ting the v arious techniques, p erhaps with a comparison with other metho ds. Dep ending on time, I would also discuss briefly what other things students w ould learn in, sa y , a more adv anced course. This includes the “optimal” choice of T θ ( Y ) and ho w to deal with b oth theory and computations when θ is high-dimensional. Readers may notice that m y prop osed course leav es out some other topics that may o ccasionally b e co vered in this first statistical inference course, such as Neyman–Pearson 13 optimalit y , minim um v ariance un biased estimation (including the Cram ´ er–Rao inequality , completeness, and the Rao–Blackw ell and Lehmann–Sc h´ effe theorems), Bay esian infer- ence, etc. These are, indeed, important topics but I consider them to b e relev ant only to studen ts who will c ho ose to sp ecialize in statistics. So, for a first statistics theory course, whose audience will likely include as man y studen ts who ultimately will not sp ecialize in statistics, it is b est to leav e these more adv anced topics out. As a sp ecific example, con- sider the sort of Ba y esian inference that is typically included in such a course. T extb o oks fo cus primarily on deriving Bay es estimators under conjugate priors, whic h is not repre- sen tativ e of mo dern Ba y esian analysis. Giving a v ery brief and out-dated presen tation of a relativ ely adv anced topic is p oten tially misleading to studen ts and, more imp ortan tly , p oten tially harmful to the sub ject itself. In fact, the p-v alue-cen tered approach prop osed here might actually help studen ts to b etter understand and appreciate a Bay esian ap- proac h. Bay esian metho ds require care in choice of prior and often require Monte Carlo metho ds to compute the posterior. T o many studen ts, this Bay esian approach app ears to b e “harder” than the classical one based on simple asymptotic approximations. If stu- den ts see that a v alid non-Ba y esian approach also requires care in the setup and Mon te Carlo metho ds to compute the p-v alue function, then they can mak e a meaningful and less sup erficial comparison b et w een a Bay esian and non-Bay esian approac h. 6 Discussion In this pap er, I ha v e prop osed an alternative approac h to teaching the first statistical inference course to senior undergraduates or b eginning graduate studen ts with a calculus- based probability background. The basic idea is that the p-v alue function contains rele- v ant information for all tasks related to statistical inference. Besides the uniform presen- tation, the resulting inference is v alid in the sense that there are prov able controls on the frequen tist error rates, compared to the classical pro cedures presented in suc h courses whic h, in many cases, are only asymptotically v alid. The price that is paid for these desirable features is that, outside the standard textb o ok problems, the solutions ma y not b e so simple to write do wn. Sp ecifically , the p-v alue-based solution for most problems will in volv e n umerical metho ds, including Mon te Carlo. T rading simple analytic solutions with only asymptotic v alidit y for less simple numerical solutions with guaran teed v alidity seems b eneficial to me, so it mak es sense to do this in the first statistical inference course. Indeed, inclusion of n umerical metho ds in to a statistical theory course is of broad in terest and v alue, and the prop osed course pro vides an idea for accomplishing this. There are some p otential downsides to c hanging the w a y the first statistical theory course is taught. One in particular, raised by a referee, is that students migh t b e b etter serv ed by exp osing them to the concepts and vocabulary common among practicing statisticians. I think it is safe to sa y that there are serious concerns these da ys ab out ho w statistical metho ds and reasoning are being used in practice, so p erhaps a c hange is needed. This proposed course, I think, is a step in the righ t direction. Finally , I w ant to briefly mention that the proposed approach is not just a simple strategy suitable for teaching in a first statistics theory course—it can be used to solve real problems. The only obstacle in applying the proposed approac h to modern statistical problems is computation; that is, the naiv e Monte Carlo approximation in (7) might b e 14 to o crude for problems inv olving mo derate- to high-dimensional θ . Therefore, w ork is needed to dev elop efficien t Mon te Carlo metho ds for these problems. So, the compu- tational challenges to implement the prop osed approach is not a shortcoming, it is an opp ortunit y for new researc h and dev elopments. I b eliev e that the standards of asymp- totically v alid inference are too lo w, and I w ould encourage others to consider raising b oth their teaching and research abov e and b eyond these norms. Ac kno wledgemen t The author thanks Professor Samad Heda y at as well as the Editor, Asso ciate Editor, and referees for their v aluable commen ts on a previous version of this manuscript. References Birn baum, A. (1961). Confidence curv es: an omnibus tec hnique for estimation and testing statistical hypotheses. J. A mer. Statist. Asso c. , 56:246–249. Blak er, H. and Sp jøtvoll, E. (2000). Parado xes and improv emen ts in in terv al estimation. A mer. Statist. , 54(4):242–247. Brazzale, A. R., Da vison, A. C., and Reid, N. (2007). Applie d Asymptotics: Case Studies in Smal l-Sample Statistics . Cam bridge Univ ersity Press, Cam bridge. Bro wn, L. D., Cai, T. T., and DasGupta, A. (2001). In terv al estimation for a binomial prop ortion (with discussion). Statist. Sci. , 16:101–133. Casella, G. and Berger, R. L. (1990). Statistic al Infer enc e . The W adsw orth & Bro oks/Cole Statistics/Probabilit y Series. W adsworth & Bro oks/Cole Adv anced Bo oks & Softw are, P acific Grov e, CA. Fidler, F., Thomason, N., Cummings, G., Fineh, S., and Leeman, J. (2004). Editors can lead researc hers to confidence in terv als, but can’t mak e them think. Psychol. Sci. , 15:119–126. F raser, D. A. S. (1991). Statistical inference: likel iho o d to significance. J. A mer. Statist. Asso c. , 86(414):258–265. Hogg, R. V., McKean, J., and Craig, A. T. (2012). Intr o duction to Mathematic al Statis- tics . P earson, 7th edition. Lange, K. (2010). Numeric al Analysis for Statisticians . Statistics and Computing. Springer, New Y ork, second edition. Levine, J. A., Eb erhardt, N. L., and Jensen, M. D. (1999). Role of nonexercise activit y thermogenesis in resistance to fat gain in h umans. Scienc e , 283:212–214. Martin, R. (2015). Plausibilit y functions and exact frequen tist inference. J. Amer. Statist. Asso c. , 110:1552–1561. 15 Martin, R. and Liu, C. (2015). Infer ential Mo dels: R e asoning with Unc ertainty . Mono- graphs in Statistics and Applied Probability Series. Chapman & Hall/CR C Press. R Core T eam (2015). R: A L anguage and Envir onment for Statistic al Computing . R F oundation for Statistical Computing, Vienna, Austria. Rubin, D. B. (1981). Estimation in parallel randomized exp eriments. J. Educ ational Statist. , 6(4):377–401. Sc hervish, M. J. (1996). P v alues: what they are and what they are not. Amer. Statist. , 50(3):203–206. Sc h weder, T. and Hjort, N. L. (2002). Confidence and likelihoo d. Sc and. J. Statist. , 29(2):309–332. Sc h weder, T. and Hjort, N. L. (2016). Confidenc e, Likeliho o d, Pr ob ability: Statistic al Infer enc e with Confidenc e Distributions . Cam bridge Univ. Press. Smith, R. L. (1985). Maximum likelihoo d estimation in a class of nonregular cases. Biometrika , 72(1):67–90. Sp jøtv oll, E. (1983). Preference functions. In A Festschrift for Erich L. Lehmann , W adsworth Statist./Probab. Ser., pages 409–432. W adsw orth, Belmont, Calif. Sun, Y. and W ong, A. C. M. (2007). Interv al estimation for the normal correlation co efficien t. Statist. Pr ob ab. L ett. , 77(17):1652–1661. T rafimow a, D. and Marks, M. (2015). Editorial. Basic Appl. So c. Psych. , 37(1):1–2. W ack erly , D., Mendenhall, W., and Scheaffer, R. L. (2008). Mathematic al Statistics with Applic ations . Thomson Bro oks/Cole, 7th edition. Wilks, S. S. (1938). The large-sample distribution of the lik eliho o d ratio for testing comp osite h yp otheses. A nn. Math. Statist , 9:60–62. Xie, M. and Singh, K. (2013). Confidence distribution, the frequentist distribution of a parameter – a review. Int. Statist. R ev. , 81(1):3–39. 16
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment