Named Entity Recognition with stack residual LSTM and trainable bias decoding
Recurrent Neural Network models are the state-of-the-art for Named Entity Recognition (NER). We present two innovations to improve the performance of these models. The first innovation is the introduction of residual connections between the Stacked Recurrent Neural Network model to address the degradation problem of deep neural networks. The second innovation is a bias decoding mechanism that allows the trained system to adapt to non-differentiable and externally computed objectives, such as the entity-based F-measure. Our work improves the state-of-the-art results for both Spanish and English languages on the standard train/development/test split of the CoNLL 2003 Shared Task NER dataset.
💡 Research Summary
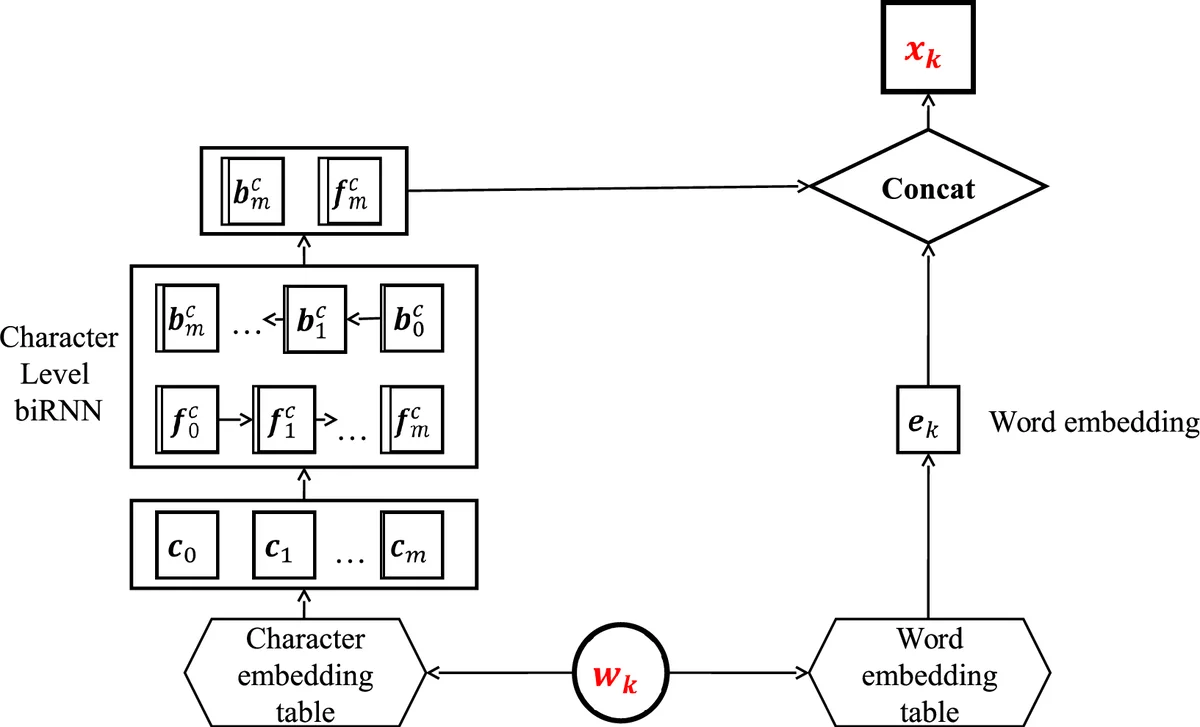
This paper introduces two complementary techniques to improve neural network–based Named Entity Recognition (NER) systems: a stacked residual recurrent architecture and a trainable bias decoding layer. The authors build upon the widely used RNN‑CRF model, which encodes each token using a character‑level bidirectional RNN, concatenates the resulting character representation with a pretrained word embedding, and then feeds the combined vector into a bidirectional LSTM. The LSTM outputs are transformed into per‑token label scores, which together with transition scores form a linear‑chain Conditional Random Field (CRF). Training maximizes the log‑likelihood of the correct label sequence, while decoding uses the Viterbi algorithm.
Stacked Residual RNN
Deep stacking of recurrent layers often suffers from the “degradation problem”: as more layers are added, training becomes harder and performance may plateau or drop. Inspired by residual connections in convolutional networks, the authors propose a modified residual connection for stacked RNNs. Instead of adding the input vector to the output (which imposes dimensionality constraints), they concatenate the original input with the output of each lower layer before feeding it to the next layer. Formally, for each layer ℓ they compute h⁰ = ρ(x), then ˆh⁰ = concat(x, h⁰), and repeat the process M times. This design lets higher layers directly access the raw input, allowing a mixture of shallow and deep feature learners without requiring dimension matching or clipping. Experiments with 2, 3, and 4 stacked layers show that three layers give the best F1 scores on both English and Spanish CoNLL‑2003 data, with statistically significant improvements over a baseline single‑layer model (p < 0.05).
Trainable Bias Decoding
NER evaluation uses entity‑level F1, whereas most neural models are trained with token‑level log‑likelihood. Directly optimizing F1 is difficult because it is non‑differentiable and depends on whole‑entity spans. The authors therefore keep the standard log‑likelihood training but introduce a simple, learnable “percentage bias” that is added to the Viterbi score table during decoding: ξ_j(y_i) = max_k
Comments & Academic Discussion
Loading comments...
Leave a Comment