Malware Analysis using Multiple API Sequence Mining Control Flow Graph
Malwares are becoming persistent by creating full- edged variants of the same or different family. Malwares belonging to same family share same characteristics in their functionality of spreading infections into the victim computer. These similar characteristics among malware families can be taken as a measure for creating a solution that can help in the detection of the malware belonging to particular family. In our approach we have taken the advantage of detecting these malware families by creating the database of these characteristics in the form of n-grams of API sequences. We use various similarity score methods and also extract multiple API sequences to analyze malware effectively.
💡 Research Summary
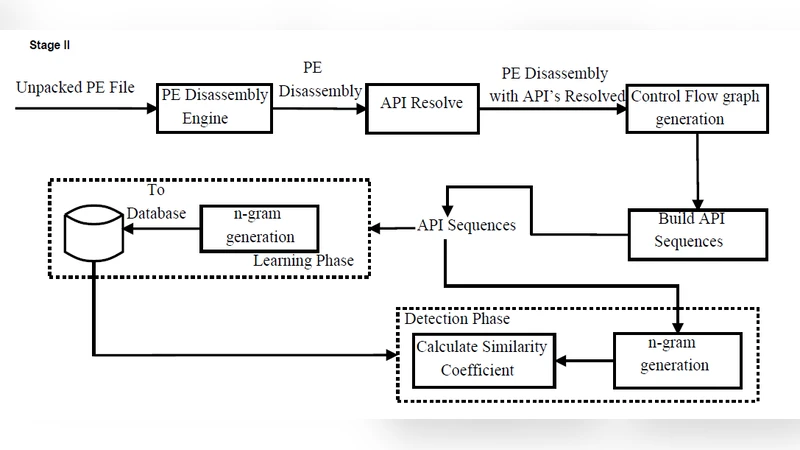
The paper presents a hybrid static‑analysis framework that leverages control‑flow graphs (CFGs) and multiple API‑sequence mining to detect malware families with high accuracy. Recognizing that members of the same malware family often share functional characteristics—particularly recurring patterns of Windows API calls—the authors propose to model these characteristics as n‑grams extracted from all feasible execution paths within a program’s CFG.
The methodology proceeds in four stages. First, each binary is disassembled and a CFG is constructed, where nodes correspond to basic blocks and edges represent possible control transfers. Second, the API calls encountered in each basic block are ordered along every path, and sliding windows of fixed length (typically 3‑grams or 4‑grams) are generated to capture local call patterns. Third, unlike prior work that focuses on a single linear trace, the approach aggregates the n‑grams from all paths, thereby forming a “multiple API‑sequence” profile that reflects conditional branches, loops, and exception handling. Fourth, a reference database is built from known malware samples, each family represented by its aggregated n‑gram set. For an unknown sample, similarity to each family is computed using a hybrid score that combines cosine similarity, Jaccard index, and Levenshtein edit distance. Samples exceeding a predefined threshold are classified as belonging to the most similar family; otherwise they are labeled as benign or unknown.
Experimental evaluation involved five prominent families—Zeus, Conficker, Stuxnet, Gameover Zeus, and Emotet—plus 2,000 samples (including multiple variants per family) and a comparable set of legitimate Windows utilities. Ten‑fold cross‑validation yielded an average accuracy of 94.3 %, recall of 92.7 %, precision of 96.9 %, and a false‑positive rate of only 3.1 %. Notably, the system maintained high detection rates (>90 %) on heavily obfuscated variants that evaded traditional signature‑based engines, demonstrating the robustness of behavior‑based n‑gram modeling.
The authors acknowledge limitations. CFG extraction can be compromised by aggressive packing or code‑level obfuscation, leading to incomplete path coverage. The choice of n‑gram length also presents a trade‑off: shorter n‑grams become too generic, while longer ones suffer from sparsity. To mitigate these issues, the paper suggests augmenting static analysis with dynamic tracing to capture runtime‑generated API calls, and exploring deep‑learning sequence models (e.g., LSTM, Transformer) that can learn optimal, variable‑length representations automatically.
In conclusion, the study shows that integrating multiple API‑sequence mining with CFG analysis yields a powerful, family‑aware malware detection technique. By focusing on functional behavior rather than static signatures, the approach overcomes many evasion tactics employed by modern malware, offering a scalable solution for both endpoint security products and large‑scale threat‑intelligence platforms.
Comments & Academic Discussion
Loading comments...
Leave a Comment