POMDPs Make Better Hackers: Accounting for Uncertainty in Penetration Testing
Penetration Testing is a methodology for assessing network security, by generating and executing possible hacking attacks. Doing so automatically allows for regular and systematic testing. A key question is how to generate the attacks. This is naturally formulated as planning under uncertainty, i.e., under incomplete knowledge about the network configuration. Previous work uses classical planning, and requires costly pre-processes reducing this uncertainty by extensive application of scanning methods. By contrast, we herein model the attack planning problem in terms of partially observable Markov decision processes (POMDP). This allows to reason about the knowledge available, and to intelligently employ scanning actions as part of the attack. As one would expect, this accurate solution does not scale. We devise a method that relies on POMDPs to find good attacks on individual machines, which are then composed into an attack on the network as a whole. This decomposition exploits network structure to the extent possible, making targeted approximations (only) where needed. Evaluating this method on a suitably adapted industrial test suite, we demonstrate its effectiveness in both runtime and solution quality.
💡 Research Summary
The paper addresses a fundamental challenge in automated penetration testing: how to generate effective attack plans when the attacker’s knowledge of the target network is incomplete. Traditional approaches either rely on classical planning, which assumes perfect knowledge, or on probabilistic models that assign a static success probability to each exploit. Both strategies require extensive pre‑scanning to reduce uncertainty, incurring high time and network‑traffic costs, and still leave residual uncertainty because scans are imperfect.
The authors propose to model the entire attack planning problem as a Partially Observable Markov Decision Process (POMDP). In this formulation, the hidden state encodes the unknown configuration of each host (operating system, installed services, security mechanisms such as DEP, etc.), while the observable components (network topology, firewall rules) are treated as known constants. Actions consist of two families: scans (port or OS detection) that provide observations without changing the underlying state, and exploits that attempt to gain control of a host; exploits are deterministic in the sense that their outcome (success, failure, or crash) is fully determined by the hidden configuration and firewall constraints. Rewards are designed to capture three aspects: a large positive reward for a successful exploit (reflecting the value of compromising a target), a negative reward proportional to the duration of the action, and a negative reward reflecting the risk of detection. The “terminate” action yields zero reward and ends the episode.
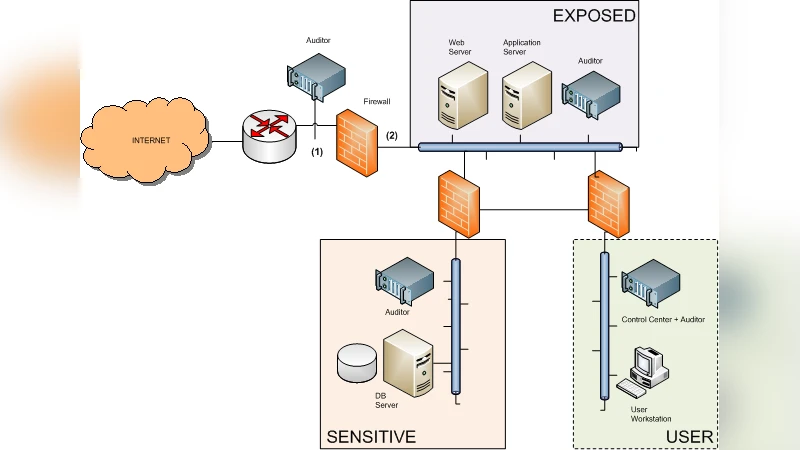
Because a naïve POMDP that includes all hosts simultaneously would have a state space exponential in the number of machines, the authors introduce a hierarchical decomposition that exploits typical network structure. Real networks are modeled as a logical network (LN) where vertices are fully‑connected subnets and edges represent inter‑subnet connections filtered by firewalls. The LN is further decomposed into biconnected components, each of which can be solved independently. Within a component, each subnet is treated as a collection of individual machines; for each machine a separate POMDP is generated, solved using the state‑of‑the‑art point‑based solver SARSOP, and the resulting expected value is propagated upward. The combination of component‑level solutions is performed conservatively, i.e., the aggregated value never overestimates the true optimal value, ensuring that the final policy is safe.
The paper details the construction of the POMDP for a single machine, enumerating possible configurations (e.g., presence of two vulnerable services SA and CAU, and the DEP protection flag) and defining five actions (two exploits, two port scans, and terminate). Transition and observation functions are deterministic: an exploit succeeds only if the required service is present, vulnerable, and DEP is disabled; a scan returns “open” only if the corresponding service is present. The authors also discuss minor optimizations such as merging states that are indistinguishable with respect to future rewards (e.g., when DEP is enabled, the vulnerability status of SA and CAU becomes irrelevant).
Experimental evaluation uses a modified version of the test suite from Core Insight Enterprise, a commercial penetration‑testing platform. Three configurations are compared: (1) a monolithic global POMDP (the theoretical optimum but computationally infeasible for realistic sizes), (2) the proposed hierarchical decomposition, and (3) the existing approach that performs exhaustive pre‑scanning followed by a classical planner (Metric‑FF variant). Results show that the hierarchical method reduces planning time by an order of magnitude relative to the global POMDP while achieving expected rewards within 5–10 % of the global optimum. Compared to the exhaustive‑scan baseline, the hierarchical method cuts scanning traffic dramatically and improves the expected reward by 2–4 %, demonstrating that intelligent, on‑the‑fly scanning guided by belief updates yields better trade‑offs between information gathering and exploitation.
Key contributions of the work are: (i) a formal POMDP model that integrates scanning and exploiting actions, allowing the planner to decide when and where to scan; (ii) a scalable decomposition technique that leverages subnet and biconnected‑component structure to make the approach applicable to real‑world networks; (iii) a conservative value‑combination scheme that guarantees the composed policy never overestimates the true optimal value; and (iv) empirical validation on an industrial‑grade testbed, confirming both runtime efficiency and solution quality.
The authors acknowledge several avenues for future research: extending the logical‑network model to capture privilege escalation and password harvesting, exploring factored POMDP representations to avoid explicit state enumeration, incorporating adaptive detection‑risk models that change during execution, and handling multi‑objective goals such as compromising several high‑value assets simultaneously. Overall, the paper demonstrates that treating penetration testing as a belief‑driven decision problem yields more efficient and realistic attack plans than traditional scan‑first, plan‑later pipelines.
Comments & Academic Discussion
Loading comments...
Leave a Comment