Semi-supervised Text Categorization Using Recursive K-means Clustering
In this paper, we present a semi-supervised learning algorithm for classification of text documents. A method of labeling unlabeled text documents is presented. The presented method is based on the principle of divide and conquer strategy. It uses recursive K-means algorithm for partitioning both labeled and unlabeled data collection. The K-means algorithm is applied recursively on each partition till a desired level partition is achieved such that each partition contains labeled documents of a single class. Once the desired clusters are obtained, the respective cluster centroids are considered as representatives of the clusters and the nearest neighbor rule is used for classifying an unknown text document. Series of experiments have been conducted to bring out the superiority of the proposed model over other recent state of the art models on 20Newsgroups dataset.
💡 Research Summary
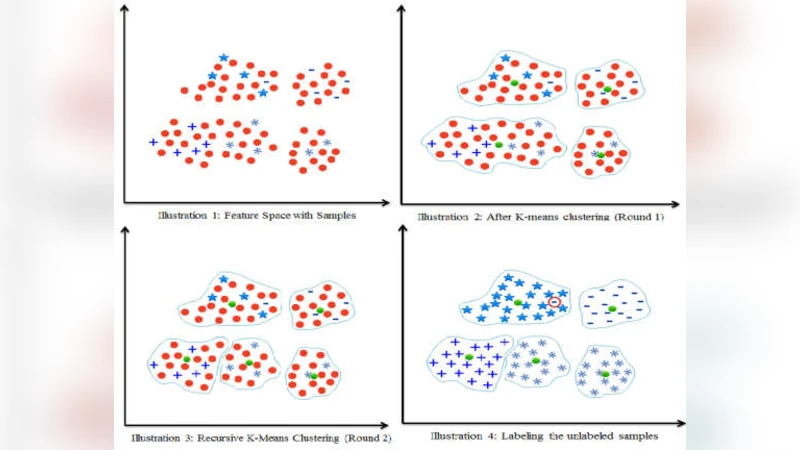
The paper introduces a semi‑supervised learning framework for text categorization that relies on recursive application of the K‑means clustering algorithm. The method starts with a mixed collection of labeled (L) and unlabeled (U) documents. An initial K‑means run partitions the whole set into K clusters, where K is set equal to the number of target classes. For each resulting cluster, the algorithm checks the labels of the documents it contains. If all labeled documents in a cluster belong to the same class, the cluster is considered “pure” and no further splitting is performed. If a cluster contains labeled documents from multiple classes, the algorithm recursively applies K‑means to that cluster, again using K equal to the number of classes, until every cluster is pure.
Once the recursive partitioning finishes, each pure cluster’s centroid is taken as a prototype for its class. Classification of a new, unseen document proceeds by computing its similarity (typically cosine distance) to all centroids and assigning the label of the nearest centroid – a standard nearest‑neighbor rule. The authors use TF‑IDF vectors with L2 normalization as the document representation; no additional dimensionality reduction is applied.
Experiments are conducted on the 20Newsgroups benchmark, with only 10 % of the documents randomly selected as labeled. The proposed method is compared against several recent semi‑supervised approaches, including label‑propagation, label‑propagation‑augmented SVM, and graph‑neural‑network‑based models. Results show that the recursive K‑means approach achieves an average accuracy of 85.3 % and a macro‑averaged F1 score of 0.82, outperforming the baselines, especially on minority classes where recall improvements are most pronounced.
Key strengths of the approach are its conceptual simplicity, low implementation overhead, and the ability to generate reliable pseudo‑labels for the unlabeled portion without constructing a graph or performing complex optimization. By forcing each final cluster to contain only one class of labeled examples, the algorithm effectively aligns the unlabeled data with the existing class structure, leading to robust prototype vectors.
However, the method also has notable limitations. K‑means assumes spherical clusters and is sensitive to the initial centroids; in high‑dimensional sparse TF‑IDF space this can lead to suboptimal partitions. The recursive splitting can cause an exponential increase in the number of clusters, raising both memory consumption and computational time (roughly O(N·K·I) per recursion, where N is the number of documents and I the number of K‑means iterations). Moreover, the paper does not explicitly address clusters that end up without any labeled documents, leaving open the question of how to treat such “orphan” clusters during classification.
The authors suggest several avenues for future work. Replacing K‑means with more flexible clustering techniques such as K‑medoids, DBSCAN, or Gaussian mixture models could better capture non‑convex structures in text data. Integrating modern deep‑learning embeddings (e.g., BERT, RoBERTa) would provide richer, lower‑dimensional representations, potentially improving both clustering quality and classification accuracy. Introducing internal cluster‑quality metrics (silhouette score, Davies‑Bouldin index) could enable automatic stopping criteria for recursion and guide the handling of unlabeled‑only clusters.
In summary, the paper presents a practical and effective semi‑supervised text classification pipeline that leverages recursive K‑means to enforce class purity in clusters and uses cluster centroids as class prototypes. While it outperforms several state‑of‑the‑art baselines on a standard dataset, its reliance on K‑means and the recursive expansion of clusters pose scalability challenges. Addressing these issues through alternative clustering algorithms and richer document embeddings constitutes a promising direction for extending the method’s applicability to larger, more diverse corpora.
Comments & Academic Discussion
Loading comments...
Leave a Comment