Plausible Deniability in Web Search -- From Detection to Assessment
We ask how to defend user ability to plausibly deny their interest in topics deemed sensitive in the face of search engine learning. We develop a practical and scalable tool called \PDE{} allowing a user to detect and assess threats to plausible deniability. We show that threats to plausible deniability of interest are readily detectable for all topics tested in an extensive testing program. Of particular concern is observation of threats to deniability of interest in topics related to health and sexual preferences. We show this remains the case when attempting to disrupt search engine learning through noise query injection and click obfuscation. We design a defence technique exploiting uninteresting, proxy topics and show that it provides a more effective defence of plausible deniability in our experiments.
💡 Research Summary
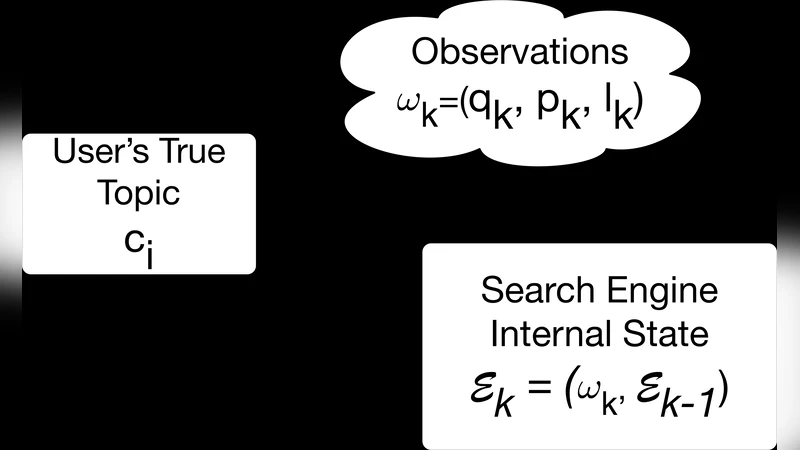
The paper addresses the problem of preserving a user’s ability to plausibly deny interest in sensitive topics when interacting with commercial web search engines that continuously personalize results and advertisements based on inferred user interests. The authors formalize “plausible deniability” as a probabilistic notion: a user can plausibly deny interest in a sensitive category c_i if, after observing the search engine’s personalized output, the posterior probability that the user is interested in c_i is not significantly higher than the probability of interest in any other (non‑sensitive) category.
To operationalize this definition, they introduce the Plausible Deniability Estimator (PDE). PDE works by injecting a set of pre‑defined “probe queries” at regular intervals into a user’s normal query stream. For each probe query, the system records the advertisements (and potentially other personalized elements) displayed on the results page. By mapping each ad to a topic category using a manually curated dictionary, PDE updates a Bayesian posterior over the user’s interest vector X̄ ∈ {0,1}^N after each interaction. The cumulative posterior probability P_i for each sensitive category is then compared against a user‑specified threshold (e.g., 0.5). If P_i exceeds the threshold, PDE flags a loss of plausible deniability.
The threat model treats the search engine as a black‑box observer that selects personalized content it believes will maximize click‑through and revenue. The key assumption is that the engine’s personalization reveals its internal belief about user interests through the ads it serves; the authors verify that an average of 2–3 ads appear per probe query, providing sufficient signal.
Experiments were conducted on Google Search using twelve sensitive topics (cancer, bankruptcy, addiction, sexual orientation, etc.) and five “proxy” topics (consumer electronics, travel, cooking, etc.). Thirty synthetic user profiles were created, each performing sessions that included 3–5 sensitive queries. Results show that without any defense, merely three to five revealing queries enable the engine to infer a sensitive interest with posterior probability ≥ 0.9 in 100 % of cases; health‑related and sexual‑preference topics reach ≈ 0.95.
Two families of defenses were evaluated. The first, traditional noise injection (random queries and misleading click patterns), was tested at noise‑to‑signal ratios from 1:1 up to 10:1. While noise occasionally reduced the posterior for a single query, the engine quickly re‑learned the true topic, and posterior probabilities remained above 0.7 even at the highest noise levels. Thus, short‑term obfuscation does not protect long‑term plausible deniability.
The second, novel “proxy‑topic” defense, deliberately interleaves queries about commercially valuable but personally uninteresting topics. When proxy queries comprised at least 70 % of the session, the posterior for the sensitive category dropped below 0.2, and PDE rarely signaled a deniability breach. The authors argue that because modern search engines learn topics rapidly, steering the learning process toward a benign proxy effectively dilutes the signal from the sensitive queries.
The paper also discusses limitations and future work. Currently PDE only analyses ad content; other personalization signals such as “Top Stories,” related tweets, or Knowledge Graph results could provide additional evidence of learning and should be incorporated in later versions. Moreover, as search engines evolve, they may develop counter‑strategies to proxy‑topic defenses, prompting an ongoing “arms race.”
In the related‑work section, the authors contrast their approach with existing privacy tools like TrackMeNot, GooPIR, and PWS, which rely primarily on random noise. They highlight that PDE offers a measurable, probabilistic assessment of deniability risk, while the proxy‑topic strategy leverages the engine’s own learning dynamics for sustained protection.
In conclusion, the study delivers a practical, scalable framework for users to monitor and preserve plausible deniability during web search. PDE can be built with publicly available APIs and open‑source components, making it accessible to ordinary users and researchers alike. The proxy‑topic defense demonstrates that purposeful, low‑cost query shaping can substantially reduce the risk of sensitive profiling, offering a promising direction for future privacy‑preserving search technologies.
Comments & Academic Discussion
Loading comments...
Leave a Comment