THUMT: An Open Source Toolkit for Neural Machine Translation
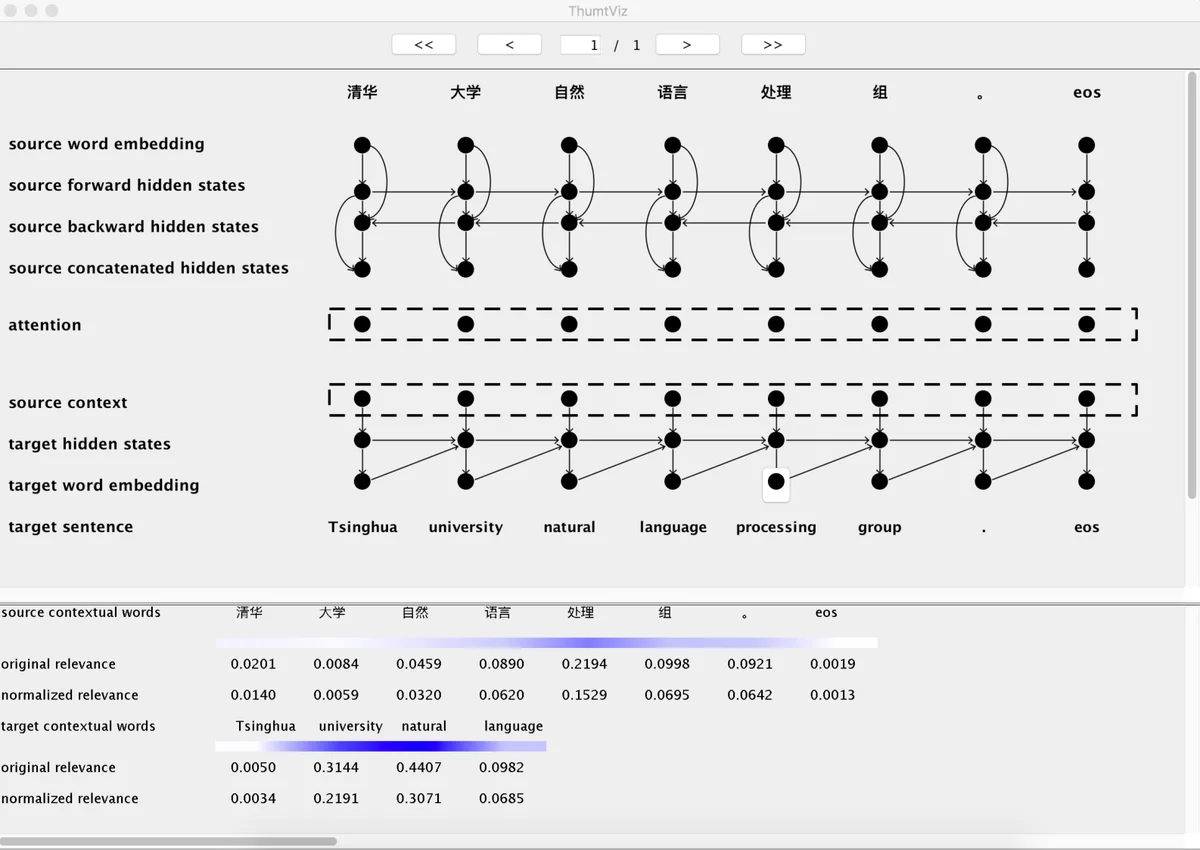
This paper introduces THUMT, an open-source toolkit for neural machine translation (NMT) developed by the Natural Language Processing Group at Tsinghua University. THUMT implements the standard attention-based encoder-decoder framework on top of Theano and supports three training criteria: maximum likelihood estimation, minimum risk training, and semi-supervised training. It features a visualization tool for displaying the relevance between hidden states in neural networks and contextual words, which helps to analyze the internal workings of NMT. Experiments on Chinese-English datasets show that THUMT using minimum risk training significantly outperforms GroundHog, a state-of-the-art toolkit for NMT.
💡 Research Summary
The paper presents THUMT, an open‑source neural machine translation (NMT) toolkit developed by the Natural Language Processing Group at Tsinghua University. Built on Theano, THUMT implements the standard attention‑based encoder‑decoder architecture originally described by Bahdanau et al. (2015). Its main contributions are threefold: (1) support for three distinct training criteria—Maximum Likelihood Estimation (MLE), Minimum Risk Training (MRT), and Semi‑Supervised Training (SST); (2) integration of three optimizers—SGD, Adadelta, and a modified Adam that mitigates NaN issues; and (3) a visualization module that applies Layer‑wise Relevance Propagation (LRP) to expose the relevance of hidden states to source and target words.
MLE serves as the baseline objective, minimizing cross‑entropy loss and providing a fast, stable convergence. MRT extends this by directly minimizing the expected loss measured with evaluation metrics such as BLEU; the authors initialize MRT with an MLE‑trained model and report consistent BLEU improvements of 3–5 points over the baseline. SST leverages large monolingual corpora to jointly train source‑to‑target and target‑to‑source models, which is particularly beneficial for low‑resource language pairs, yielding additional gains of 2–4 BLEU points.
Optimization experiments show that Adam outperforms both SGD and Adadelta in terms of convergence speed and final translation quality. The modified Adam uses a smaller epsilon and carefully tuned learning‑rate schedules (0.0005 for MLE, 0.00001 for MRT, 0.00005 for SST) to avoid numerical instability. Training time comparisons reveal that MLE with Adam converges in roughly 10 hours (36 K iterations), whereas MRT requires substantially more computation (≈72 hours, 118 K iterations), reflecting the cost of sampling and evaluating multiple candidate translations per batch.
The visualization tool addresses the “black‑box” nature of NMT models. By propagating relevance scores from a selected output token back through the network, users can see which source and target words contributed most to that token, facilitating qualitative analysis and debugging.
To handle unknown tokens, THUMT adopts the approach of Luong et al. (2015), generating bilingual dictionaries with FastAlign and replacing UNK symbols with the most probable aligned word. This simple post‑processing step yields consistent BLEU gains of 0.5–1.0 across all training criteria and optimizers.
Experimental evaluation focuses on Chinese‑English translation. The authors use a 1.25 M sentence parallel corpus (≈28 M Chinese tokens, ≈35 M English tokens) and large monolingual corpora (≈19 M Chinese sentences, ≈22 M English sentences). Vocabulary size is limited to 30 K, embeddings are 620‑dimensional, hidden layers have 1 000 units, batch size is 80, and beam size is 10. Validation is performed on NIST 2002, while test sets span NIST 2003‑2008.
Results (Table 1) show that THUMT matches GroundHog under MLE, but surpasses it when MRT is applied, achieving BLEU improvements of up to 5 points. SST further boosts performance, especially in the low‑resource direction (English→Chinese). Table 3 confirms that UNK replacement consistently improves scores across all configurations. The authors also note that Adam reduces training iterations dramatically compared to Adadelta, confirming its efficiency.
In conclusion, THUMT offers a flexible, research‑oriented platform that integrates advanced training objectives, robust optimization, and interpretability tools. While current implementation supports only a single GPU and MRT remains computationally intensive, the authors plan to release a multi‑GPU version to alleviate these constraints. The toolkit is freely available at http://thumt.thunlp.org, encouraging broader adoption and further experimentation in the NMT community.
Comments & Academic Discussion
Loading comments...
Leave a Comment