Unsure When to Stop? Ask Your Semantic Neighbors
In iterative supervised learning algorithms it is common to reach a point in the search where no further induction seems to be possible with the available data. If the search is continued beyond this point, the risk of overfitting increases significantly. Following the recent developments in inductive semantic stochastic methods, this paper studies the feasibility of using information gathered from the semantic neighborhood to decide when to stop the search. Two semantic stopping criteria are proposed and experimentally assessed in Geometric Semantic Genetic Programming (GSGP) and in the Semantic Learning Machine (SLM) algorithm (the equivalent algorithm for neural networks). The experiments are performed on real-world high-dimensional regression datasets. The results show that the proposed semantic stopping criteria are able to detect stopping points that result in a competitive generalization for both GSGP and SLM. This approach also yields computationally efficient algorithms as it allows the evolution of neural networks in less than 3 seconds on average, and of GP trees in at most 10 seconds. The usage of the proposed semantic stopping criteria in conjunction with the computation of optimal mutation/learning steps also results in small trees and neural networks.
💡 Research Summary
The paper addresses a fundamental problem in iterative supervised learning—determining when to stop the search to avoid over‑fitting—by exploiting the information available in the semantic neighbourhood of the current best model. The authors focus on two semantic‑based algorithms: Geometric Semantic Genetic Programming (GSGP) and the Semantic Learning Machine (SLM), a neural‑network counterpart that uses a geometric semantic mutation operator (GSM‑NN). Both algorithms follow a hill‑climbing strategy (Semantic Stochastic Hill Climber, SSHC) that at each generation samples a set of neighbours generated by applying the semantic mutation to the current best individual.
Two stopping criteria are introduced.
-
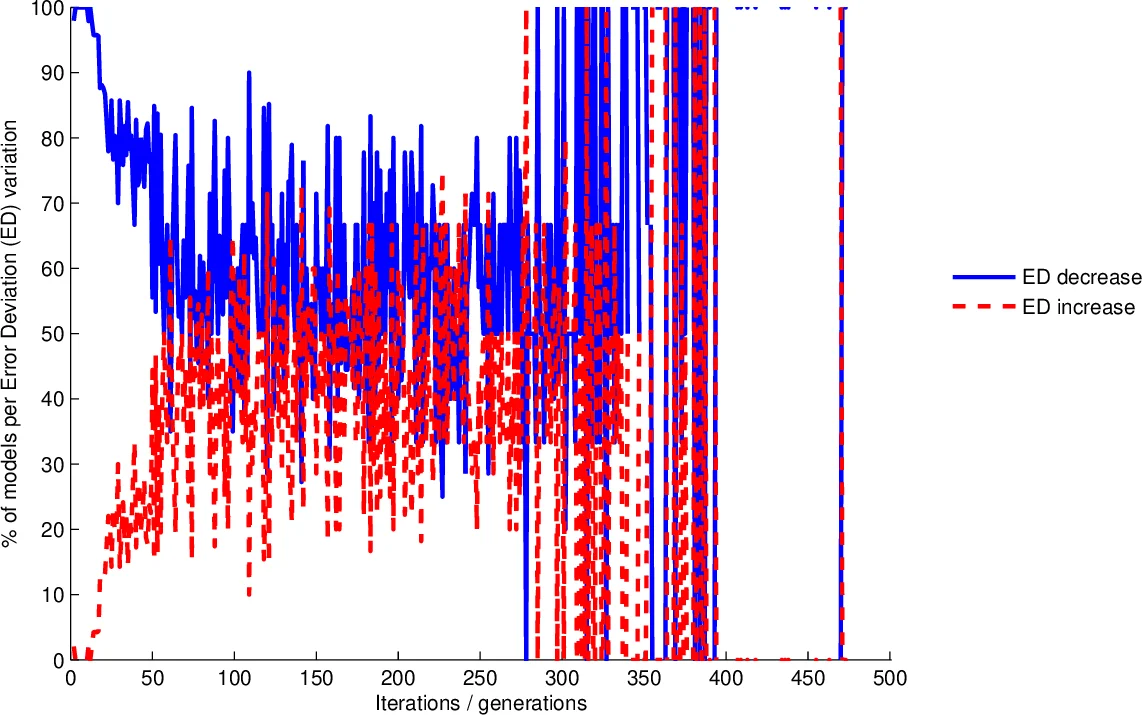
Error Deviation Variation (EDV) – For all neighbours that improve the training error relative to the current best, the proportion that also reduce the standard deviation of absolute errors (error deviation) is computed. If this proportion falls below a predefined threshold, the algorithm stops, interpreting the drop as a sign that error reduction is becoming uneven across training instances, i.e., over‑fitting is beginning.
-
Training Improvement Effectiveness (TIE) – This measures the percentage of neighbours that are strictly better than the current best (i.e., the effectiveness of the mutation operator). When this effectiveness drops below a threshold, the search is halted, under the hypothesis that further improvements are increasingly forced and likely to harm generalization.
Both criteria require no extra sampling because the neighbourhood is already generated each generation for the hill‑climber.
The experimental protocol follows Gonçalves et al. (2017) and uses three high‑dimensional pharmaceutical regression datasets: Bioavailability (359 instances, 241 features), Plasma Protein Binding (131 instances, 626 features), and Median Lethal Dose (LD50, 234 instances, 626 features). For each dataset, 30 independent runs are performed with a 70/30 train‑test split. At each generation 100 neighbours are sampled. Two step‑size strategies are examined:
- Fixed Step (FS) – a constant mutation/learning step (ms or ls) throughout the run.
- Optimal Step (OS) – the step is recomputed at each mutation using the Moore‑Penrose pseudo‑inverse, yielding the step that minimizes training error for that particular mutation.
Key findings:
- Both EDV and TIE successfully detect the onset of over‑fitting. When applied, the average runtime is reduced dramatically—SLM finishes in under 3 seconds on average, and GSGP in at most 10 seconds—while preserving competitive generalization performance.
- The OS variants consistently achieve slightly lower test RMSE (≈2–5 % improvement) compared with FS, without inflating model size. This demonstrates that optimal step computation synergises with the semantic stopping criteria to balance error reduction and model complexity.
- Models produced under the proposed stopping rules are compact: GP trees remain shallow and neural networks contain few hidden neurons, confirming that early stopping also curtails unnecessary growth.
- The bounded mutation (where random sub‑trees are constrained by a logistic function) is used throughout, as it is known to improve generalization compared with unbounded mutation.
The authors conclude that semantic neighbourhood information provides a reliable, low‑overhead signal for early stopping in semantic‑based evolutionary learning. By integrating EDV or TIE with optimal step computation, practitioners can obtain fast, accurate models even on high‑dimensional regression problems. Future work is suggested on extending the approach to deeper neural architectures, alternative semantic operators, and broader application domains.
Comments & Academic Discussion
Loading comments...
Leave a Comment