Fixed-Rank Approximation of a Positive-Semidefinite Matrix from Streaming Data
Several important applications, such as streaming PCA and semidefinite programming, involve a large-scale positive-semidefinite (psd) matrix that is presented as a sequence of linear updates. Because of storage limitations, it may only be possible to retain a sketch of the psd matrix. This paper develops a new algorithm for fixed-rank psd approximation from a sketch. The approach combines the Nystrom approximation with a novel mechanism for rank truncation. Theoretical analysis establishes that the proposed method can achieve any prescribed relative error in the Schatten 1-norm and that it exploits the spectral decay of the input matrix. Computer experiments show that the proposed method dominates alternative techniques for fixed-rank psd matrix approximation across a wide range of examples.
💡 Research Summary
This paper addresses the problem of maintaining a high‑quality fixed‑rank approximation of a large positive‑semidefinite (PSD) matrix that evolves through a stream of linear updates, while using only a limited memory budget. Such scenarios arise in streaming principal component analysis (PCA) and in low‑rank semidefinite programming (SDP) where the matrix variable can be enormous. The authors propose a sketch‑based method combined with a Nyström approximation and a novel rank‑truncation strategy that outperforms existing techniques.
Streaming model and sketch.
The target matrix (A\in\mathbb{F}^{n\times n}) (real or complex) starts from a known PSD initial point and is updated repeatedly as (A\leftarrow\theta_{1}A+\theta_{2}H), where (H) is symmetric (often low‑rank or sparse). A random test matrix (\Omega\in\mathbb{F}^{n\times k}) with (k\ge r) is drawn once at the beginning. The sketch is defined as (Y=A\Omega). Because the update is linear, the sketch can be updated cheaply: (Y\leftarrow\theta_{1}Y+\theta_{2}H\Omega).
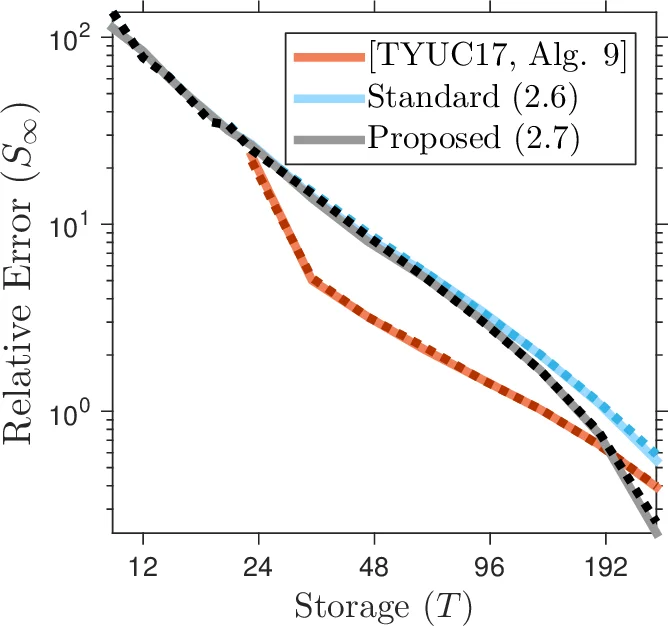
Nyström approximation and its limitations.
The classical Nyström construction yields a rank‑(k) PSD approximation (\widehat A_{\text{nys}} = Y(\Omega^{}Y)^{\dagger}Y^{}). Prior work obtains a fixed‑rank estimator by truncating the middle matrix: (\widehat A_{\text{nys}}^{(r)} = Y\bigl(J_{\Omega^{}Y}^{(r)}\bigr)^{\dagger}Y^{}). Empirical evidence in the streaming setting shows that this truncation discards essential information and leads to poor accuracy.
Proposed fixed‑rank estimator.
Instead of truncating the inner matrix, the authors compute the best rank‑(r) approximation of the full Nyström matrix:
\
Comments & Academic Discussion
Loading comments...
Leave a Comment