On the Expressive Power of Deep Neural Networks
We propose a new approach to the problem of neural network expressivity, which seeks to characterize how structural properties of a neural network family affect the functions it is able to compute. Our approach is based on an interrelated set of meas…
Authors: Maithra Raghu, Ben Poole, Jon Kleinberg
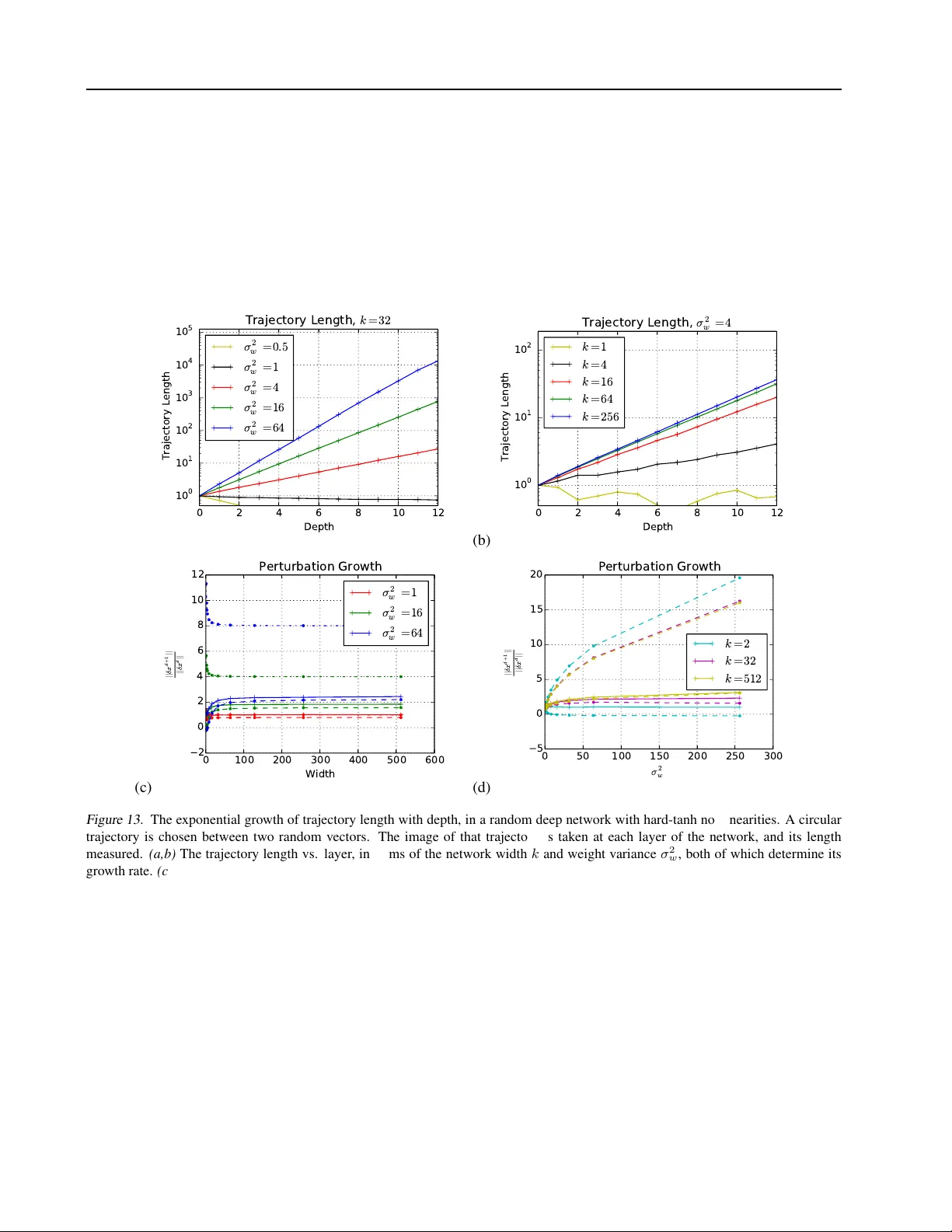
On the Expr essiv e P ower of Deep Neural Netw orks Maithra Raghu 1 2 Ben Poole 3 Jon Kleinberg 1 Surya Ganguli 3 Jascha Sohl Dickstein 2 Abstract W e propose a new approach to the problem of neural network expr essivity , which seeks to char- acterize ho w structural properties of a neural net- work family af fect the functions it is able to com- pute. Our approach is based on an interrelated set of measures of expressi vity , unified by the nov el notion of trajectory length , which mea- sures ho w the output of a network changes as the input sweeps along a one-dimensional path. Our findings can be summarized as follows: (1) The complexity of the computed function gr ows exponentially with depth. W e de- sign measures of expressivity that capture the non-linearity of the computed func- tion. Due to ho w the network transforms its input, these measures gro w exponentially with depth. (2) All weights are not equal (initial layer s mat- ter mor e). W e find that trained networks are far more sensiti v e to their lo wer (ini- tial) layer weights: the y are much less ro- bust to noise in these layer weights, and also perform better when these weights are opti- mized well. (3) T rajectory Re gularization works like Batch Normalization. W e find that batch norm stabilizes the learnt representation, and based on this propose a ne w regularization scheme, trajectory r e gularization. 1. Introduction Deep neural networks hav e proved astoundingly effecti ve at a wide range of empirical tasks, from image classifica- tion ( Krizhevsk y et al. , 2012 ) to playing Go ( Silver et al. , 2016 ), and ev en modeling human learning ( Piech et al. , 2015 ). 1 Cornell Univ ersity 2 Google Brain 3 Stanford Univ ersity . Cor- respondence to: Maithra Raghu . Pr oceedings of the 34 th International Conference on Machine Learning , Sydney , Australia, PMLR 70, 2017. Copyright 2017 by the author(s). Despite these successes, understanding of how and why neural network architectures achie ve their empirical suc- cesses is still lacking. This includes e ven the fundamen- tal question of neural network expr essivity , how the archi- tectural properties of a neural network (depth, width, layer type) affect the resulting functions it can compute, and its ensuing performance. This is a foundational question, and there is a rich history of prior work addressing e xpressivity in neural networks. Howe ver , it has been challenging to derive conclusions that provide both theoretical generality with respect to choices of architecture as well as meaningful insights into practical performance. Indeed, the very first results on this question take a highly theoretical approach, from using functional analysis to show univ ersal approximation results ( Hornik et al. , 1989 ; Cybenko , 1989 ), to analysing expressi vity via comparisons to boolean circuits ( Maass et al. , 1994 ) and studying net- work VC dimension ( Bartlett et al. , 1998 ). While these results provided theoretically general conclusions, the shal- low netw orks they studied are very dif ferent from the deep models that hav e proven so successful in recent years. In response, several recent papers have focused on under- standing the benefits of depth for neural networks ( Pas- canu et al. , 2013 ; Montufar et al. , 2014 ; Eldan and Shamir , 2015 ; T elgarsky , 2015 ; Martens et al. , 2013 ; Bianchini and Scarselli , 2014 ). These results are compelling and take modern architectural changes into account, but they only show that a specific choice of weights for a deeper network results in inapproximability by a shallow (typically one or two hidden layers) network. In particular , the goal of this new line of work has been to establish lower bounds — showing separations between shallow and deep networks — and as such they are based on hand-coded constructions of specific network weights. Even if the weight values used in these constructions are robust to small perturbations (as in ( Pascanu et al. , 2013 ; Montufar et al. , 2014 )), the functions that arise from these constructions tend tow ard extremal properties by design, and there is no evidence that a network trained on data e ver resembles such a function. This has meant that a set of fundamental questions about On the Expressi ve P ower of Deep Neural Networks neural network expressi vity has remained largely unan- swered. First, we lack a good understanding of the “typ- ical” case rather than the worst case in these bounds for deep networks, and consequently hav e no way to e valu- ate whether the hand-coded e xtremal constructions provide a reflection of the complexity encountered in more stan- dard settings. Second, we lack an understanding of upper bounds to match the lower bounds produced by this prior work; do the constructions used to date place us near the limit of the expressi ve power of neural networks, or are there still large gaps? Finally , if we had an understanding of these two issues, we might begin to draw connections between network expressi vity and observed performance. Our contributions: Measur es of Expressivity and their Applications In this paper , we address this set of chal- lenges by defining and analyzing an interrelated set of mea- sur es of e xpressivity for neural networks; our frame work applies to a wide range of standard architectures, indepen- dent of specific weight choices. W e begin our analysis at the start of training, after random initialization, and later deriv e insights connecting network expressi vity and perfor- mance. Our first measure of expressivity is based on the notion of an activation pattern : in a network where the units compute functions based on discrete thresholds, we can ask which units are abov e or below their thresholds (i.e. which units are “activ e” and which are not). F or the range of standard architectures that we consider , the network is essentially computing a linear function once we fix the activ ation pat- tern; thus, counting the number of possible activ ation pat- terns provides a concrete way of measuring the comple xity beyond linearity that the netw ork provides. W e gi ve an up- per bound on the number of possible activ ation patterns, ov er any setting of the weights. This bound is tight as it matches the hand-constructed lower bounds of earlier w ork ( Pascanu et al. , 2013 ; Montufar et al. , 2014 ). Ke y to our analysis is the notion of a transition , in which changing an input x to a nearby input x + δ changes the activ ation pattern. W e study the behavior of transitions as we pass the input along a one-dimensional parametrized trajectory x ( t ) . Our central finding is that the tr ajectory length grows e xponentially in the depth of the network. T rajectory length serves as a unifying notion in our mea- sures of e xpressivity , and it leads to insights into the be- havior of trained networks. Specifically , we find that the exponential gro wth in trajectory length as a function of depth implies that small adjustments in parameters lower in the network induce larger changes than comparable ad- justments higher in the network. W e demonstrate this phe- nomenon through experiments on MNIST and CIF AR-10, where the network displays much less robustness to noise in the lower layers, and better performance when they are trained well. W e also explore the ef fects of regularization methods on trajectory length as the network trains and pro- pose a less computationally intensiv e method of re gulariza- tion, trajectory r egularization , that offers the same perfor- mance as batch normalization. The contributions of this paper are thus: (1) Measur es of expr essivity : W e propose easily com- putable measures of neural network expressivity that capture the expressiv e po wer inherent in different neural network architectures, independent of specific weight settings. (2) Exponential trajectories: W e find an exponen- tial depth dependence displayed by these measures, through a unifying analysis in which we study how the network transforms its input by measuring trajectory length (3) All weights ar e not equal (the lower layers matter mor e) : W e sho w how these results on trajectory length suggest that optimizing weights in lower layers of the network is particularly important. (4) T rajectory Re gularization Based on understanding the effect of batch norm on trajectory length, we propose a new method of regularization, trajectory regulariza- tion, that of fers the same adv antages as batch norm, and is computationally more efficient. In prior work ( Poole et al. , 2016 ), we studied the propa- gation of Riemannian curvatur e through random networks by de veloping a mean field theory approach. Here, we take an approach grounded in computational geometry , present- ing measures with a combinatorial flav or and explore the consequences during and after training. 2. Measures of Expr essivity Giv en a neural network of a certain architecture A (some depth, width, layer types), we hav e an associated function, F A ( x ; W ) , where x is an input and W represents all the parameters of the network. Our goal is to understand how the behavior of F A ( x ; W ) changes as A changes, for values of W that we might encounter during training, and across inputs x . The first major difficulty comes from the high dimension- ality of the input. Precisely quantifying the properties of F A ( x ; W ) over the entire input space is intractable. As a tractable alternativ e, we study simple one dimensional tra- jectories through input space. More formally: Definition: Gi ven two points, x 0 , x 1 ∈ R m , we say x ( t ) is a trajectory (between x 0 and x 1 ) if x ( t ) is a curve On the Expressi ve P ower of Deep Neural Networks parametrized by a scalar t ∈ [0 , 1] , with x (0) = x 0 and x (1) = x 1 . Simple examples of a trajectory would be a line ( x ( t ) = tx 1 + (1 − t ) x 0 ) or a circular arc ( x ( t ) = cos( π t/ 2) x 0 + sin( π t/ 2) x 1 ), b ut in general x ( t ) may be more compli- cated, and potentially not expressible in closed form. Armed with this notion of trajectories, we can begin to de- fine measures of expressi vity of a network F A ( x ; W ) ov er trajectories x ( t ) . 2.1. Neuron T ransitions and Activ ation Patterns In ( Montufar et al. , 2014 ) the notion of a “linear region” is introduced. Given a neural network with piecewise lin- ear acti vations (such as ReLU or hard tanh), the function it computes is also piecewise linear, a consequence of the fact that composing piecewise linear functions results in a piecewise linear function. So one way to measure the “ex- pressiv e power” of different architectures A is to count the number of linear pieces (regions), which determines how nonlinear the function is. In fact, a change in linear region is caused by a neur on transition in the output layer . More precisely: Definition For fixed W , we say a neuron with piecewise linear region tr ansitions between inputs x, x + δ if its acti- vation function switches linear region between x and x + δ . So a ReLU transition would be given by a neuron switching from of f to on (or vice versa) and for hard tanh by switch- ing between saturation at − 1 to its linear middle region to saturation at 1 . For any generic trajectory x ( t ) , we can thus define T ( F A ( x ( t ); W )) to be the number of transitions un- dergone by output neurons (i.e. the number of linear re- gions) as we sweep the input x ( t ) . Instead of just concen- trating on the output neurons howe ver , we can look at this pattern over the entir e network. W e call this an activation patten : Definition W e can define AP ( F A ( x ; W )) to be the activa- tion pattern – a string of form { 0 , 1 } num neurons (for ReLUs) and {− 1 , 0 , 1 } num neurons (for hard tanh) of the network en- coding the linear region of the activ ation function of every neuron, for an input x and weights W . Overloading notation slightly , we can also define (similarly to transitions) A ( F A ( x ( t ); W )) as the number of distinct activ ation patterns as we sweep x along x ( t ) . As each distinct activ ation pattern corresponds to a different linear function of the input, this combinatorial measure captures how much more expressiv e A is over a simple linear map- ping. Returning to Montufar et al, they provide a construction i.e. a specific set of weights W 0 , that results in an e xponen- tial increase of linear regions with the depth of the archi- tectures. They also appeal to Zasla vsky’ s theorem ( Stan- ley , 2011 ) from the theory of hyperplane arrangements to show that a shallow network, i.e. one hidden layer , with the same number of parameters as a deep netw ork, has a much smaller number of linear regions than the number achiev ed by their choice of weights W 0 for the deep network. More formally , letting A 1 be a fully connected network with one hidden layer, and A l a fully connected network with the same number of parameters, b ut l hidden layers, they sho w ∀ W T ( F A 1 ([0 , 1]; W )) < T ( F A 1 ([0 , 1]; W 0 ) (*) W e derive a much more general result by considering the ‘global’ activ ation patterns over the entir e input space, and prov e that for any fully connected network, with any num- ber of hidden layers, we can upper bound the number of lin- ear regions it can achie ve, over all possible weight settings W . This upper bound is asymptotically tight , matched by the construction giv en in ( Montuf ar et al. , 2014 ). Our result can be written formally as: Theorem 1. (Tight) Upper Bound for Number of Activ a- tion Patterns Let A ( n,k ) denote a fully connected network with n hidden layers of width k , and inputs in R m . Then the number of activation patterns A ( F A n,k ( R m ; W ) is upper bounded by O ( k mn ) for ReLU activations, and O ((2 k ) mn ) for har d tanh. From this we can deriv e a chain of inequalities. Firstly , from the theorem above we find an upper bound of A ( F A n,k ( R m ; W )) over all W , i.e. ∀ W A ( F A ( n,k ) )( R m ; W ) ≤ U ( n, k , m ) . Next, suppose we have N neurons in total. Then we want to compare (for wlog ReLUs), quantities like U ( n 0 , N/n 0 , m ) for different n 0 . But U ( n 0 , N/n 0 , m ) = O (( N /n 0 ) mn 0 ) , and so, noting that the maxima of a x mx (for a > e ) is x = a/e , we get, (for n, k > e ), in comparison to (*), U (1 , N , m ) < U (2 , N 2 , m ) < · · · · · · < U ( n − 1 , N n − 1 , m ) < U ( n, k, m ) W e prove this via an inductive proof on regions in a hy- perplane arrangement. The proof can be found in the Ap- pendix. As noted in the introduction, this result differs from earlier lower -bound constructions in that it is an upper bound that applies to all possible sets of weights. V ia our analysis, we also prov e On the Expressi ve P ower of Deep Neural Networks -1 0 1 x 0 -1 0 1 x 1 Layer 0 -1 0 1 x 0 -1 0 1 Layer 1 -1 0 1 x 0 -1 0 1 Layer 2 Figure 1. Deep networks with piece wise linear activ ations subdi- vide input space into conv ex polytopes. W e take a three hidden layer ReLU network, with input x ∈ R 2 , and four units in each layer . The left pane shows activations for the first layer only . As the input is in R 2 , neurons in the first hidden layer ha ve an associ- ated line in R 2 , depicting their acti vation boundary . The left pane thus has four such lines. For the second hidden layer each neuron again has a line in input space corresponding to on/off, but this line is differ ent for each region described by the first layer activ a- tion pattern. So in the centre pane, which sho ws activ ation bound- ary lines corresponding to second hidden layer neurons in green (and first hidden layer in black), we can see the green lines ‘bend’ at the boundaries. (The reason for this bending becomes appar- ent through the proof of Theorem 2 .) Finally , the right pane adds the on/of f boundaries for neurons in the third hidden layer, in pur - ple. These lines can bend at both black and green boundaries, as the image shows. This final set of conv ex polytopes corresponds to all activ ation patterns for this network (with its current set of weights) ov er the unit square, with each polytope representing a different linear function. Theorem 2. Regions in Input Space Given the corr espond- ing function of a neural network F A ( R m ; W ) with ReLU or har d tanh activations, the input space is partitioned into con vex polytopes, with F A ( R m ; W ) corresponding to a dif- fer ent linear function on each r egion. This result is of independent interest for optimization – a linear function over a con vex polytope results in a well be- hav ed loss function and an easy optimization problem. Un- derstanding the density of these regions during the training process would lik ely shed light on properties of the loss surface, and improv ed optimization methods. A picture of a network’ s regions is shown in Figure 1 . 2 . 1 . 1 . E M P I R I C A L LY C O U N T I N G T R A N S I T I O N S W e empirically tested the gro wth of the number of acti- vations and transitions as we v aried x along x ( t ) to under- stand their beha vior . W e found that for bounded non linear - ities, especially tanh and hard-tanh, not only do we observe exponential gro wth with depth (as hinted at by the upper bound) but that the scale of parameter initialization also af- fects the observ ations (Figure 2 ). W e also experimented with sweeping the weights W of a layer through a trajec- tory W ( t ) , and counting the different labellings output by the network. This ‘dichotomies’ measure is discussed fur- ther in the Appendix, and also exhibits the same gro wth properties, Figure 14 . 0 2 4 6 8 10 12 14 Network depth 1 0 - 1 1 0 0 1 0 1 1 0 2 Transitions number Number of transitions with increasing depth w50 scl10 w100 scl8 w500 scl5 w700 scl5 w700 scl10 w1000 scl10 w1000 scl16 0 200 400 600 800 1000 Layer width 1 0 - 1 1 0 0 1 0 1 Number of transitions Number of transitions with increasing width lay2 scl5 lay2 scl10 lay4 scl5 lay4 scl8 lay6 scl5 lay6 scl8 lay8 scl8 lay10 scl8 lay12 scl8 Figure 2. The number of transitions seen for fully connected net- works of dif ferent widths, depths and initialization scales, with a circular trajectory between MNIST datapoints. The number of transitions gro ws exponentially with the depth of the architecture, as seen in (left). The same rate of gro wth is not seen with increas- ing architecture width, plotted in (right). There is a surprising dependence on the scale of initialization, explained in 2.2 . Figure 3. Picture showing a trajectory increasing with the depth of a network. W e start off with a circular trajectory (left most pane), and feed it through a fully connected tanh network with width 100 . Pane second from left sho ws the image of the circular trajectory (projected down to two dimensions) after being trans- formed by the first hidden layer . Subsequent panes show pro- jections of the latent image of the circular trajectory after being transformed by more hidden layers. The final pane shows the the trajectory after being transformed by all the hidden layers. 2.2. T rajectory Length In fact, there turns out to be a reason for the exponential growth with depth, and the sensitivity to initialization scale. Returning to our definition of trajectory , we can define an immediately related quantity , trajectory length Definition: Gi ven a trajectory , x ( t ) , we define its length, l ( x ( t )) , to be the standard arc length : l ( x ( t )) = Z t dx ( t ) dt dt Intuitiv ely , the arc length breaks x ( t ) up into infinitesimal intervals and sums together the Euclidean length of these intervals. If we let A ( n,k ) denote, as before, fully connected networks with n hidden layers each of width k , and initializing with weights ∼ N (0 , σ 2 w /k ) (accounting for input scaling as typical), and biases ∼ N (0 , σ 2 b ) , we find that: Theorem 3. Bound on Gro wth of Trajectory Length Let F A ( x 0 , W ) be a ReLU or har d tanh random neural network and x ( t ) a one dimensional tr ajectory with x ( t + δ ) having a non trival perpendicular component to x ( t ) for all t, δ On the Expressi ve P ower of Deep Neural Networks 1 2 3 4 5 6 7 8 9 Network depth 1 0 1 1 0 2 1 0 3 1 0 4 1 0 5 Trajectory length Trajectory length growth with increasing depth scl5 scl8 scl12 scl16 scl20 scl32 Figure 4. W e look at trajectory growth with different initializa- tion scales as a trajectory is propagated through a con volutional architecture for CIF AR-10, with ReLU activ ations. The analy- sis of Theorem 3 was for fully connected networks, but we see that trajectory growth holds (albeit with slightly higher scales) for con volutional architectures also. Note that the decrease in trajec- tory length, seen in layers 3 and 7 is expected, as those layers are pooling layers. (i.e, not a line). Then defining z ( d ) ( x ( t )) = z ( d ) ( t ) to be the image of the trajectory in layer d of the network, we have (a) E h l ( z ( d ) ( t )) i ≥ O σ w √ k √ k + 1 ! d l ( x ( t )) for ReLUs (b) E h l ( z ( d ) ( t )) i ≥ O σ w √ k q σ 2 w + σ 2 b + k p σ 2 w + σ 2 b d l ( x ( t )) for har d tanh That is, l ( x ( t ) grows exponentially with the depth of the network, b ut the width only appears as a base (of the expo- nent). This bound is in fact tight in the limits of large σ w and k . A schematic image depicting this can be seen in Figure 3 and the proof can be found in the Appendix. A rough out- line is as follo ws: we look at the expected growth of the difference between a point z ( d ) ( t ) on the curv e and a small perturbation z ( d ) ( t + dt ) , from layer d to layer d + 1 . Denot- ing this quantity δ z ( d ) ( t ) , we derive a recurrence relat- ing δ z ( d +1) ( t ) and δ z ( d ) ( t ) which can be composed to giv e the desired growth rate. The analysis is complicated by the statistical dependence on the image of the input z ( d +1) ( t ) . So we instead form a recursion by looking at the component of the dif ference perpendicular to the image of the input in that layer , i.e. δ z ( d +1) ⊥ ( t ) , which results in the condition on x ( t ) in the statement. In Figures 4 , 12 , we see the growth of an input trajectory for ReLU networks on CIF AR-10 and MNIST . The CIF AR- 10 network is con volutional but we observe that these lay- ers also result in similar rates of trajectory length increases to the fully connected layers. W e also see, as would be expected, that pooling layers act to reduce the trajectory length. W e discuss upper bounds in the Appendix. Figure 5. The number of transitions is linear in trajectory length. Here we compare the empirical number of transitions to the length of the trajectory , for different depths of a hard-tanh network. W e repeat this comparison for a variety of network architectures, with different netw ork width k and weight v ariance σ 2 w . For the hard tanh case (and more generally an y bounded non-linearity), we can formally prove the relation of trajec- tory length and transitions under an assumption: assume that while we sweep x ( t ) all neurons are saturated un- less transitioning saturation endpoints, which happens v ery rapidly . (This is the case for e.g. large initialization scales). Then we hav e: Theorem 4. T ransitions proportional to trajectory length Let F A n,k be a har d tanh network with n hidden layers each of width k . And let g ( k , σ w , σ b , n ) = O √ k q 1 + σ 2 b σ 2 w n Then T ( F A n,k ( x ( t ); W ) = O ( g ( k , σ w , σ b , n )) for W ini- tialized with weight and bias scales σ w , σ b . Note that the expression for g ( k , σ w , σ b , n ) is e xactly the expression giv en by Theorem 3 when σ w is very large and dominates σ b . W e can also verify this experimentally in settings where the simpilfying assumption does not hold, as in Figure 5 . 3. Insights from Netw ork Expressivity Here we explore the insights gained from applying our measurements of expressi vity , particularly trajectory length, to understand network performance. W e examine the connection of expressi vity and stability , and inspired by this, propose a ne w method of regularization, trajectory On the Expressi ve P ower of Deep Neural Networks 0.0 0.5 1.0 1.5 2.0 Noise magnitude 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 Accuracy CIFAR 10 accuracy against noise in diff layers lay01 lay02 lay03 lay04 lay05 lay06 lay07 Figure 6. W e then pick a single layer of a con v net trained to high accuracy on CIF AR10, and add noise to the layer weights of in- creasing magnitudes, testing the network accuracy as we do so. W e find that the initial (lower) layers of the network are least ro- bust to noise – as the figure shows, adding noise of 0 . 25 magni- tude to the first layer results in a 0 . 7 drop in accuracy , while the same amount of noise added to the fifth layer barely results in a 0 . 02 drop in accuracy . This pattern is seen for man y dif ferent ini- tialization scales, even for a (typical) scaling of σ 2 w = 2 , used in the experiment. r egularization that offers the same advantages as the more computationally intensiv e batch normalization. 3.1. Expressi vity and Network Stability The analysis of network expressi vity of fers interesting takeaw ays related to the parameter and functional stabil- ity of a netw ork. From the proof of Theorem 3 , we sa w that a perturbation to the input would grow exponentially in the depth of the network. It is easy to see that this anal- ysis is not limited to the input layer , but can be applied to any layer . In this form, it would say A perturbation at a layer grows e xponentially in the r emaining depth after that layer . This means that perturbations to weights in lower layers should be more costly than perturbations in the upper lay- ers, due to exponentially increasing magnitude of noise, and result in a much larger drop of accuracy . Figure 6 , in which we train a con v network on CIF AR-10 and add noise of varying magnitudes to exactly one layer , shows exactly this. W e also find that the con verse (in some sense) holds: after initializing a network, we trained a single layer at different depths in the network and found monotonically increasing performance as layers lower in the network were trained. This is shown in Figure 7 and Figure 17 in the Appendix. 3.2. T rajectory Length and Regularization: The Effect of Batch Normalization Expressivity measures, especially trajectory length, can also be used to better understand the effect of regulariza- 0 100 200 300 400 500 Epoch Number 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 Accuracy Train Accuracy Against Epoch 0 100 200 300 400 500 Epoch Number Test Accuracy Against Epoch lay 2 lay 3 lay 4 lay 5 lay 6 lay 7 lay 8 lay 9 Figure 7. Demonstration of e xpressive po wer of remaining depth on MNIST . Here we plot train and test accurac y achieved by train- ing exactly one layer of a fully connected neural net on MNIST . The dif ferent lines are generated by varying the hidden layer cho- sen to train. All other layers are kept frozen after random initial- ization. W e see that training lower hidden layers leads to better performance. The networks had width k = 100 , weight variance σ 2 w = 1 , and hard-tanh nonlinearities. Note that we only train from the second hidden layer (weights W (1) ) onwards, so that the number of parameters trained remains fixed. tion. One regularization technique that has been extremely successful for training neural networks is Batch Normal- ization ( Ioffe and Sze gedy , 2015 ). in c1 c2 p1 c3 c4 c5 p2 fc1 fc2 Trajectory length 1 0 1 1 0 2 1 0 3 1 0 4 1 0 5 Layer depth CIFAR10 Trajectory growth without Batch Norm 0 1189 10512 40744 72389 104035 137262 142009 156250 Figure 8. T raining increases trajectory length ev en for typical ( σ 2 w = 2 ) initialization values of σ w . Here we propagate a cir- cular trajectory joining two CIF AR10 datapoints through a con v net without batch norm, and look at ho w trajectory length changes through training. W e see that training causes trajectory length to increase exponentially with depth (exceptions only being the pooling layers and the final fc layer , which halves the number of neurons.) Note that at Step 0 , the network is not in the exponen- tial growth regime. W e observe (discussed in Figure 9 ) that even networks that aren’t initialized in the exponential growth regime can be pushed there through training. By taking measures of trajectories during training we find that without batch norm, trajectory length tends to increase during training, as shown in Figures 8 and Figure 18 in the Appendix. In these experiments, two networks were initialized with σ 2 w = 2 and trained to high test accurac y on CIF AR10 and MNIST . W e see that in both cases, trajectory length increases as training progresses. A surprising observation is σ 2 w = 2 is not in the exponential growth increase re gime at initialization for the CIF AR10 On the Expressi ve P ower of Deep Neural Networks architecture (Figure 8 at Step 0 .). But note that ev en with a smaller weight initialization, weight norms increase during training, sho wn in Figure 9 , pushing typically initialized networks into the exponential gro wth regime. 0 20000 40000 60000 80000 100000 120000 Train Step 2.0 2.5 3.0 3.5 4.0 4.5 5.0 5.5 6.0 Scaled weight variance CIFAR-10 scaled weight variances with training lay 01 lay 02 lay 03 lay 04 lay 05 lay 06 lay 07 Figure 9. This figure shows how the weight scaling of a CIF AR10 network evolv es during training. The network was initialized with σ 2 w = 2 , which increases across all layers during training. While the initial growth of trajectory length enables greater functional expressivity , large trajectory gro wth in the learnt representation results in an unstable representation, wit- nessed in Figure 6 . In Figure 10 we train another con v net on CIF AR10, but this time with batch normalization. W e see that the batch norm layers reduce trajectory length, helping stability . in c1 c2 bn1 p1 c3 c4 c5 bn2 p2 fc1 bn3 fc2 bn4 Layer depth 1 0 2 1 0 3 1 0 4 1 0 5 1 0 6 1 0 7 Trajectory length CIFAR10: Trajectory growth with Batch Norm 0 395 7858 156250 Figure 10. Growth of circular trajectory between two datapoints with batch norm layers for a con v net on CIF AR10. The network was initialized as typical, with σ 2 w = 2 . Note that the batch norm layers in Step 0 are poorly beha ved due to division by a close to 0 variance. But after just a few hundred gradient steps and contin- uing onwards, we see the batch norm layers (dotted lines) reduce trajectory length, stabilising the representation without sacrificing expressi vity . 3.3. T rajectory Regularization Motiv ated by the fact that batch normalization decreases trajectory length and hence helps stability and generaliza- tion, we consider directly re gularizing on trajectory length: we replace e very batch norm layer used in the con v net in Figure 10 with a trajectory r e gularization layer . This layer adds to the loss λ ( current length / orig length ) , and then scales the outgoing activ ations by λ , where λ is a pa- rameter to be learnt. In implementation, we typically scale the additional loss above with a constant ( 0 . 01 ) to reduce magnitude in comparison to classification loss. Our results, Figure 11 sho w that both trajectory regularization and batch norm perform comparably , and considerably better than not using batch norm. One advantage of using T rajectory Reg- ularization is that we don’t require different computations to be performed for train and test, enabling more efficient implementation. 0 20000 40000 60000 80000 100000 120000 140000 160000 Train step 0.70 0.75 0.80 0.85 0.90 Test Accuracy CIFAR10 Accuracy for trajectory and batch norm reguarlizers batch norm traj reg no batch norm or traj reg Figure 11. W e replace each batch norm layer of the CIF AR10 con v net with a trajectory re gularization layer , described in Sec- tion 3.3 . During training trajectory length is easily calculated as a piecewise linear trajectory between adjacent datapoints in the minibatch. W e see that trajectory regularization achiev es the same performance as batch norm, albeit with slightly more train time. Howe ver , as trajectory regularization behaves the same during train and test time, it is simpler and more efficient to implement. 4. Discussion Characterizing the expressi veness of neural networks, and understanding ho w expressiv eness varies with parameters of the architecture, has been a challenging problem due to the difficulty in identifying meaningful notions of expres- sivity and in linking their analysis to implications for these networks in practice. In this paper we have presented an interrelated set of expressi vity measures; we hav e shown tight exponential bounds on the growth of these measures in the depth of the networks, and we hav e of fered a uni- fying view of the analysis through the notion of trajectory length . Our analysis of trajectories provides insights for the performance of trained networks as well, suggesting that networks in practice may be more sensiti ve to small per - turbations in weights at lower layers. W e also used this to explore the empirical success of batch norm, and dev eloped a new re gularization method – trajectory regularization. This work raises many interesting directions for future work. At a general le vel, continuing the theme of ‘prin- cipled deep understanding’, it would be interesting to link On the Expressi ve P ower of Deep Neural Networks measures of expressivity to other properties of neural net- work performance. There is also a natural connection be- tween adv ersarial examples, ( Goodfello w et al. , 2014 ), and trajectory length: adversarial perturbations are only a small distance a way in input space, but result in a large change in classification (the output layer). Understanding ho w trajec- tories between the original input and an adversarial pertur- bation grow might provide insights into this phenomenon. Another direction, partially explored in this paper, is regu- larizing based on trajectory length. A very simple version of this was presented, but further performance gains might be achieved through more sophisticated use of this method. Acknowledgements W e thank Samy Bengio, Ian Goodfellow , Laurent Dinh, and Quoc Le for extremely helpful discussion. References Alex Krizhe vsky , Ilya Sutske ver , and Geoffre y E Hinton. Imagenet classification with deep con volutional neural networks. In Advances in neur al information pr ocessing systems , pages 1097–1105, 2012. David Silver , Aja Huang, Chris J Maddison, Arthur Guez, Laurent Sifre, George V an Den Driessche, Julian Schrit- twieser , Ioannis Antonoglou, V eda Panneershelv am, Marc Lanctot, et al. Mastering the game of go with deep neural networks and tree search. Natur e , 529(7587): 484–489, 2016. Chris Piech, Jonathan Bassen, Jonathan Huang, Surya Gan- guli, Mehran Sahami, Leonidas J Guibas, and Jascha Sohl-Dickstein. Deep knowledge tracing. In Advances in Neural Information Pr ocessing Systems , pages 505–513, 2015. Kurt Hornik, Maxwell Stinchcombe, and Halbert White. Multilayer feedforward networks are univ ersal approxi- mators. Neural networks , 2(5):359–366, 1989. George Cybenko. Approximation by superpositions of a sigmoidal function. Mathematics of contr ol, signals and systems , 2(4):303–314, 1989. W olfgang Maass, Georg Schnitger , and Eduardo D Son- tag. A comparison of the computational power of sig- moid and Boolean thr eshold circuits . Springer , 1994. Peter L Bartlett, V italy Maiorov , and Ron Meir . Almost lin- ear vc-dimension bounds for piecewise polynomial net- works. Neural computation , 10(8):2159–2173, 1998. Razvan Pascanu, Guido Montufar , and Y oshua Bengio. On the number of response regions of deep feed forward net- works with piece-wise linear activ ations. arXiv preprint arXiv:1312.6098 , 2013. Guido F Montufar , Razvan Pascanu, Kyunghyun Cho, and Y oshua Bengio. On the number of linear regions of deep neural networks. In Advances in neural information pr o- cessing systems , pages 2924–2932, 2014. Ronen Eldan and Ohad Shamir . The power of depth for feedforward neural networks. arXiv pr eprint arXiv:1512.03965 , 2015. Matus T elgarsky . Representation benefits of deep feedfor- ward netw orks. arXiv pr eprint arXiv:1509.08101 , 2015. James Martens, Arkade v Chattopadhya, T oni Pitassi, and Richard Zemel. On the representational efficienc y of re- stricted boltzmann machines. In Advances in Neural In- formation Pr ocessing Systems , pages 2877–2885, 2013. Monica Bianchini and Franco Scarselli. On the complex- ity of neural network classifiers: A comparison between shallow and deep architectures. Neural Networks and Learning Systems, IEEE T ransactions on , 25(8):1553– 1565, 2014. Ben Poole, Subhaneil Lahiri, Maithra Raghu, Jascha Sohl- Dickstein, and Surya Ganguli. Exponential expressi vity in deep neural networks through transient chaos. In Ad- vances in neural information pr ocessing systems , pages 3360–3368, 2016. Richard Stanley . Hyperplane arrangements. Enumerative Combinatorics , 2011. Serge y Ioffe and Christian Szegedy . Batch normalization: Accelerating deep network training by reducing inter- nal cov ariate shift. In Pr oceedings of the 32nd Inter- national Confer ence on Machine Learning, ICML 2015, Lille, F rance, 6-11 J uly 2015 , pages 448–456, 2015. Ian J. Goodfello w , Jonathon Shlens, and Christian Szegedy . Explaining and harnessing adversarial e xamples. CoRR , abs/1412.6572, 2014. D. Kersha w . Some extensions of w . gautschi’ s inequalities for the gamma function. Mathematics of Computation , 41(164):607–611, 1983. Andrea Lafor gia and Pierpaolo Natalini. On some inequal- ities for the gamma function. Advances in Dynamical Systems and Applications , 8(2):261–267, 2013. Norbert Sauer . On the density of families of sets. Journal of Combinatorial Theory , Series A , 13(1):145–147, 1972. On the Expressi ve P ower of Deep Neural Networks A ppendix Here we include the full proofs from sections in the paper . A. Proofs and additional r esults from Section 2.1 Proof of Theor em 2 Pr oof. W e show inductiv ely that F A ( x ; W ) partitions the input space into conv ex polytopes via hyperplanes. Consider the image of the input space under the first hidden layer . Each neuron v (1) i defines hyperplane(s) on the input space: letting W (0) i be the i th row of W (0) , b (0) i the bias, we have the hyperplane W (0) i x + b i = 0 for a ReLU and hyperplanes W (0) i x + b i = ± 1 for a hard-tanh. Considering all such hyperplanes over neurons in the first layer , we get a hyperplane arrangement in the input space, each polytope corresponding to a specific activ ation pattern in the first hidden layer . Now , assume we have partitioned our input space into con vex polytopes with hyperplanes from layers ≤ d − 1 . Consider v ( d ) i and a specific polytope R i . Then the activ ation pattern on layers ≤ d − 1 is constant on R i , and so the input to v ( d ) i on R i is a linear function of the inputs P j λ j x j + b and some constant term, comprising of the bias and the output of saturated units. Setting this expression to zero (for ReLUs) or to ± 1 (for hard-tanh) again gives a hyperplane equation, but this time, the equation is only valid in R i (as we get a different linear function of the inputs in a different region.) So the defined hyperplane(s) either partition R i (if they intersect R i ) or the output pattern of v ( d ) i is also constant on R i . The theorem then follows. This implies that any one dimensional trajectory x ( t ) , that does not ‘double back’ on itself (i.e. reenter a polytope it has previously passed through), will not repeat acti vation patterns. In particular , after seeing a transition (crossing a hyperplane to a dif ferent region in input space) we will ne ver return to the region we left. A simple example of such a trajectory is a straight line: Corollary 1. T ransitions and Output Patterns in an Affine T rajectory F or any affine one dimensional trajectory x ( t ) = x 0 + t ( x 1 − x 0 ) input into a neur al network F W , we partition R 3 t into intervals every time a neur on transitions. Every interval has a unique network activation pattern on F W . Generalizing from a one dimensional trajectory , we can ask ho w many regions are achie ved o ver the entire input – i.e. ho w many distinct activ ation patterns are seen? W e first prove a bound on the number of regions formed by k hyperplanes in R m (in a purely elementary fashion, unlike the proof presented in ( Stanle y , 2011 )) Theorem 5. Upper Bound on Regions in a Hyperplane Arrangement Suppose we have k hyperplanes in R m - i.e. k equations of form α i x = β i . for α i ∈ R m , β i ∈ R . Let the number of re gions (connected open sets bounded on some sides by the hyperplanes) be r ( k , m ) . Then r ( k , m ) ≤ m X i =0 k i Proof of Theor em 5 Pr oof. Let the hyperplane arrangement be denoted H , and let H ∈ H be one specific hyperplane. Then the number of regions in H is precisely the number of regions in H − H plus the number of regions in H ∩ H . (This follows from the fact that H subdivides into two re gions exactly all of the regions in H ∩ H , and does not affect an y of the other regions.) In particular , we have the recursi ve formula r ( k , m ) = r ( k − 1 , m ) + r ( k − 1 , m − 1) W e now induct on k + m to assert the claim. The base cases of r (1 , 0) = r (0 , 1) = 1 are trivial, and assuming the claim On the Expressi ve P ower of Deep Neural Networks for ≤ k + m − 1 as the induction hypothesis, we ha ve r ( k − 1 , m ) + r ( k − 1 , m − 1) ≤ m X i =0 k − 1 i + m − 1 X i =0 k − 1 i ≤ k − 1 0 + d − 1 X i =0 k − 1 i + k − 1 i + 1 ≤ k 0 + m − 1 X i =0 k i + 1 where the last equality follows by the well kno wn identity a b + a b + 1 = a + 1 b + 1 This concludes the proof. W ith this result, we can easily prove Theorem 1 as follo ws: Proof of Theor em 1 Pr oof. First consider the ReLU case. Each neuron has one hyperplane associated with it, and so by Theorem 5 , the first hidden layer divides up the inputs space into r ( k , m ) regions, with r ( k , m ) ≤ O ( k m ) . Now consider the second hidden layer . For every region in the first hidden layer , there is a different activ ation pattern in the first layer, and so (as described in the proof of Theorem 2 ) a different hyperplane arrangement of k hyperplanes in an m dimensional space, contributing at most r ( k , m ) re gions. In particular, the total number of regions in input space as a result of the first and second hidden layers is ≤ r ( k , m ) ∗ r ( k , m ) ≤ O ( k 2 m ) . Continuing in this way for each of the n hidden layers gi ves the O ( k m n ) bound. A very similar method works for hard tanh, but here each neuron produces tw o hyperplanes, resulting in a bound of O ((2 k ) mn ) . B. Proofs and additional r esults from Section 2.2 Proof of Theor em 3 B.1. Notation and Preliminary Results Differ ence of points on trajectory Gi ven x ( t ) = x, x ( t + dt ) = x + δ x in the trajectory , let δ z ( d ) = z ( d ) ( x + δ x ) − z ( d ) ( x ) P arallel and P erpendicular Components: Giv en vectors x, y , we can write y = y ⊥ + y k where y ⊥ is the component of y perpendicular to x , and y k is the component parallel to x . (Strictly speaking, these components should also have a subscript x , but we suppress it as the direction with respect to which parallel and perpendicular components are being taken will be explicitly stated.) This notation can also be used with a matrix W , see Lemma 1 . Before stating and proving the main theorem, we need a fe w preliminary results. Lemma 1. Matrix Decomposition Let x, y ∈ R k be fixed non-zero vectors, and let W be a (full rank) matrix. Then, we can write W = k W k + k W ⊥ + ⊥ W k + ⊥ W ⊥ On the Expressi ve P ower of Deep Neural Networks such that k W ⊥ x = 0 ⊥ W ⊥ x = 0 y T ⊥ W k = 0 y T ⊥ W ⊥ = 0 i.e. the row space of W is decomposed to perpendicular and parallel components with r espect to x (subscript on right), and the column space is decomposed to perpendicular and parallel components of y (superscript on left). Pr oof. Let V , U be rotations such that V x = ( || x || , 0 ..., 0) T and U y = ( || y || , 0 ... 0) T . Now let ˜ W = U W V T , and let ˜ W = k ˜ W k + k ˜ W ⊥ + ⊥ ˜ W k + ⊥ ˜ W ⊥ , with k ˜ W k having non-zero term exactly ˜ W 11 , k ˜ W ⊥ having non-zero entries exactly ˜ W 1 i for 2 ≤ i ≤ k . Finally , we let ⊥ ˜ W k hav e non-zero entries exactly ˜ W i 1 , with 2 ≤ i ≤ k and ⊥ ˜ W ⊥ hav e the remaining entries non-zero. If we define ˜ x = V x and ˜ y = U y , then we see that k ˜ W ⊥ ˜ x = 0 ⊥ ˜ W ⊥ ˜ x = 0 ˜ y T ⊥ ˜ W k = 0 ˜ y T ⊥ ˜ W ⊥ = 0 as ˜ x, ˜ y hav e only one non-zero term, which does not correspond to a non-zero term in the components of ˜ W in the equations. Then, defining k W k = U T k ˜ W k V , and the other components analogously , we get equations of the form k W ⊥ x = U T k ˜ W ⊥ V x = U T k ˜ W ⊥ ˜ x = 0 Observation 1. Giv en W , x as before, and considering W k , W ⊥ with respect to x (wlog a unit vector) we can express them directly in terms of W as follows: Letting W ( i ) be the i th row of W , we ha ve W k = (( W (0) ) T · x ) x . . . (( W ( k ) ) T · x ) x i.e. the projection of each row in the direction of x . And of course W ⊥ = W − W k The moti vation to consider such a decomposition of W is for the resulting independence between dif ferent components, as shown in the follo wing lemma. Lemma 2. Independence of Projections Let x be a given vector (wlog of unit norm.) If W is a random matrix with W ij ∼ N (0 , σ 2 ) , then W k and W ⊥ with r espect to x are independent r andom variables. Pr oof. There are two possible proof methods: (a) W e use the rotational inv ariance of random Gaussian matrices, i.e. if W is a Gaussian matrix, iid entries N (0 , σ 2 ) , and R is a rotation, then RW is also iid Gaussian, entries N (0 , σ 2 ) . (This follows easily from affine transformation rules for multiv ariate Gaussians.) Let V be a rotation as in Lemma 1 . Then ˜ W = W V T is also iid Gaussian, and furthermore, ˜ W k and ˜ W ⊥ partition the entries of ˜ W , so are evidently independent. But then W k = ˜ W k V T and W ⊥ = ˜ W ⊥ V T are also independent. (b) From the observation note that W k and W ⊥ hav e a centered multiv ariate joint Gaussian distribution (both consist of linear combinations of the entries W ij in W .) So it suffices to show that W k and W ⊥ hav e covariance 0 . Because both are centered Gaussians, this is equiv alent to showing E ( < W k , W ⊥ > ) = 0 . W e hav e that E ( < W k , W ⊥ > ) = E ( W k W T ⊥ ) = E ( W k W T ) − E ( W k W T k ) On the Expressi ve P ower of Deep Neural Networks As any two rows of W are independent, we see from the observation that E ( W k W T ) is a diagonal matrix, with the i th diagonal entry just (( W (0) ) T · x ) 2 . But similarly , E ( W k W T k ) is also a diagonal matrix, with the same diagonal entries - so the claim follows. In the following two lemmas, we use the rotational in variance of Gaussians as well as the chi distribution to prove results about the expected norm of a random Gaussian v ector . Lemma 3. Norm of a Gaussian vector Let X ∈ R k be a random Gaussian vector , with X i iid, ∼ N (0 , σ 2 ) . Then E [ || X || ] = σ √ 2 Γ(( k + 1) / 2) Γ( k / 2) Pr oof. W e use the fact that if Y is a random Gaussian, and Y i ∼ N (0 , 1) then || Y || follows a chi distribution. This means that E ( || X/σ || ) = √ 2Γ(( k + 1) / 2) / Γ( k / 2) , the mean of a chi distrib ution with k degrees of freedom, and the result follows by noting that the e xpectation in the lemma is σ multiplied by the above e xpectation. W e will find it useful to bound ratios of the Gamma function (as appear in Lemma 3 ) and so introduce the follo wing inequality , from ( Kershaw , 1983 ) that pro vides an extension of Gautschi’ s Inequality . Theorem 6. An Extension of Gautschi’ s Inequality F or 0 < s < 1 , we have x + s 2 1 − s ≤ Γ( x + 1) Γ( x + s ) ≤ x − 1 2 + s + 1 4 1 2 ! 1 − s W e now sho w: Lemma 4. Norm of Projections Let W be a k by k random Gaussian matrix with iid entries ∼ N (0 , σ 2 ) , and x, y two given vectors. P artition W into components as in Lemma 1 and let x ⊥ be a nonzer o vector perpendicular to x . Then (a) E ⊥ W ⊥ x ⊥ = || x ⊥ || σ √ 2 Γ( k / 2) Γ(( k − 1) / 2 ≥ || x ⊥ || σ √ 2 k 2 − 3 4 1 / 2 (b) If 1 A is an identity matrix with non-zer os diagonal entry i iff i ∈ A ⊂ [ k ] , and | A | > 2 , then E 1 A ⊥ W ⊥ x ⊥ ≥ || x ⊥ || σ √ 2 Γ( |A| / 2) Γ(( |A| − 1) / 2) ≥ || x ⊥ || σ √ 2 |A| 2 − 3 4 1 / 2 Pr oof. (a) Let U, V , ˜ W be as in Lemma 1 . As U, V are rotations, ˜ W is also iid Gaussian. Furthermore for any fixed W , with ˜ a = V a , by taking inner products, and square-rooting, we see that ˜ W ˜ a = || W a || . So in particular E ⊥ W ⊥ x ⊥ = E h ⊥ ˜ W ⊥ ˜ x ⊥ i But from the definition of non-zero entries of ⊥ ˜ W ⊥ , and the form of ˜ x ⊥ (a zero entry in the first coordinate), it follows that ⊥ ˜ W ⊥ ˜ x ⊥ has exactly k − 1 non zero entries, each a centered Gaussian with variance ( k − 1) σ 2 || x ⊥ || 2 . By Lemma 3 , the expected norm is as in the statement. W e then apply Theorem 6 to get the lower bound. (b) First note we can view 1 A ⊥ W ⊥ = ⊥ 1 A W ⊥ . (Projecting down to a random (as W is random) subspace of fixed size |A| = m and then making perpendicular commutes with making perpendicular and then projecting e verything down to the subspace.) So we can view W as a random m by k matrix, and for x, y as in Lemma 1 (with y projected down onto m dimensions), we can again define U, V as k by k and m by m rotation matrices respectively , and ˜ W = U W V T , with analogous On the Expressi ve P ower of Deep Neural Networks properties to Lemma 1. Now we can finish as in part (a), except that ⊥ ˜ W ⊥ ˜ x may hav e only m − 1 entries, (depending on whether y is annihilated by projecting down by 1 A ) each of variance ( k − 1) σ 2 || x ⊥ || 2 . Lemma 5. Norm and T ranslation Let X be a center ed multivariate Gaussian, with diagonal covariance matrix, and µ a constant vector . E ( || X − µ || ) ≥ E ( || X || ) Pr oof. The inequality can be seen intuitiv ely geometrically: as X has diagonal cov ariance matrix, the contours of the pdf of || X || are circular centered at 0 , decreasing radially . Ho we ver , the contours of the pdf of || X − µ || are shifted to be centered around || µ || , and so shifting back µ to 0 reduces the norm. A more formal proof can be seen as follows: let the pdf of X be f X ( · ) . Then we wish to show Z x || x − µ || f X ( x ) dx ≥ Z x || x || f X ( x ) dx Now we can pair points x, − x , using the fact that f X ( x ) = f X ( − x ) and the triangle inequality on the integrand to get Z | x | ( || x − µ || + ||− x − µ || ) f X ( x ) dx ≥ Z | x | || 2 x || f X ( x ) dx = Z | x | ( || x || + ||− x || ) f X ( x ) dx B.2. Proof of Theor em W e use v ( d ) i to denote the i th neuron in hidden layer d . W e also let x = z (0) be an input, h ( d ) be the hidden representation at layer d , and φ the non-linearity . The weights and bias are called W ( d ) and b ( d ) respectiv ely . So we hav e the relations h ( d ) = W ( d ) z ( d ) + b ( d ) , z ( d +1) = φ ( h ( d ) ) . (1) Pr oof. W e first prove the zero bias case. T o do so, it is sufficient to prov e that E h δ z ( d +1) ( t ) i ≥ O √ σ k √ σ + k ! d +1 δ z (0) ( t ) (**) as integrating o ver t giv es us the statement of the theorem. For ease of notation, we will suppress the t in z ( d ) ( t ) . W e first write W ( d ) = W ( d ) ⊥ + W ( d ) k where the division is done with respect to z ( d ) . Note that this means h ( d +1) = W ( d ) k z ( d ) as the other component annihilates (maps to 0 ) z ( d ) . W e can also define A W ( d ) k = { i : i ∈ [ k ] , | h ( d +1) i | < 1 } i.e. the set of indices for which the hidden representation is not saturated. Letting W i denote the i th row of matrix W , we now claim that: E W ( d ) h δ z ( d +1) i = E W ( d ) k E W ( d ) ⊥ X i ∈A W ( d ) k (( W ( d ) ⊥ ) i δ z ( d ) + ( W ( d ) k ) i δ z ( d ) ) 2 1 / 2 (*) Indeed, by Lemma 2 we first split the expectation over W ( d ) into a tower of expectations over the two independent parts of W to get E W ( d ) h δ z ( d +1) i = E W ( d ) k E W ( d ) ⊥ h φ ( W ( d ) δ z ( d ) ) i On the Expressi ve P ower of Deep Neural Networks But conditioning on W ( d ) k in the inner expectation gives us h ( d +1) and A W ( d ) k , allo wing us to replace the norm over φ ( W ( d ) δ z ( d ) ) with the sum in the term on the right hand side of the claim. T ill now , we have mostly focused on partitioning the matrix W ( d ) . But we can also set δ z ( d ) = δ z ( d ) k + δ z ( d ) ⊥ where the perpendicular and parallel are with respect to z ( d ) . In fact, to get the expression in (**), we deri ve a recurrence as belo w: E W ( d ) h δ z ( d +1) ⊥ i ≥ O √ σ k √ σ + k ! E W ( d ) h δ z ( d ) ⊥ i T o get this, we first need to define ˜ z ( d +1) = 1 A W ( d ) k h ( d +1) - the latent vector h ( d +1) with all saturated units zeroed out. W e then split the column space of W ( d ) = ⊥ W ( d ) + k W ( d ) , where the split is with respect to ˜ z ( d +1) . Letting δ z ( d +1) ⊥ be the part perpendicular to z ( d +1) , and A the set of units that are unsaturated, we hav e an important relation: Claim δ z ( d +1) ⊥ ≥ ⊥ W ( d ) δ z ( d ) 1 A (where the indicator in the right hand side zeros out coordinates not in the activ e set.) T o see this, first note, by definition, δ z ( d +1) ⊥ = W ( d ) δ z ( d ) · 1 A − h W ( d ) δ z ( d ) · 1 A , ˆ z ( d +1) i ˆ z ( d +1) (1) where the ˆ · indicates a unit vector . Similarly ⊥ W ( d ) δ z ( d ) = W ( d ) δ z ( d ) − h W ( d ) δ z ( d ) , ˆ ˜ z ( d +1) i ˆ ˜ z ( d +1) (2) Now note that for any inde x i ∈ A , the right hand sides of (1) and (2) are identical, and so the vectors on the left hand side agree for all i ∈ A . In particular, δ z ( d +1) ⊥ · 1 A = ⊥ W ( d ) δ z ( d ) · 1 A Now the claim follo ws easily by noting that δ z ( d +1) ⊥ ≥ δ z ( d +1) ⊥ · 1 A . Returning to (*), we split δ z ( d ) = δ z ( d ) ⊥ + δ z ( d ) k , W ( d ) ⊥ = k W ( d ) ⊥ + ⊥ W ( d ) ⊥ (and W ( d ) k analogously), and after some cancellation, we hav e E W ( d ) h δ z ( d +1) i = E W ( d ) k E W ( d ) ⊥ X i ∈A W ( d ) k ( ⊥ W ( d ) ⊥ + k W ( d ) ⊥ ) i δ z ( d ) ⊥ + ( ⊥ W ( d ) k + k W ( d ) k ) i δ z ( d ) k 2 1 / 2 W e w ould like a recurrence in terms of only perpendicular components ho wever , so we first drop the k W ( d ) ⊥ , k W ( d ) k (which can be done without decreasing the norm as the y are perpendicular to the remaining terms) and using the abov e claim, hav e E W ( d ) h δ z ( d +1) ⊥ i ≥ E W ( d ) k E W ( d ) ⊥ X i ∈A W ( d ) k ( ⊥ W ( d ) ⊥ ) i δ z ( d ) ⊥ + ( ⊥ W ( d ) k ) i δ z ( d ) k 2 1 / 2 On the Expressi ve P ower of Deep Neural Networks But in the inner expectation, the term ⊥ W ( d ) k δ z ( d ) k is just a constant, as we are conditioning on W ( d ) k . So using Lemma 5 we hav e E W ( d ) ⊥ X i ∈A W ( d ) k ( ⊥ W ( d ) ⊥ ) i δ z ( d ) ⊥ + ( ⊥ W ( d ) k ) i δ z ( d ) k 2 1 / 2 ≥ E W ( d ) ⊥ X i ∈A W ( d ) k ( ⊥ W ( d ) ⊥ ) i δ z ( d ) ⊥ 2 1 / 2 W e can then apply Lemma 4 to get E W ( d ) ⊥ X i ∈A W ( d ) k ( ⊥ W ( d ) ⊥ ) i δ z ( d ) ⊥ 2 1 / 2 ≥ σ √ k √ 2 q 2 |A W ( d ) k | − 3 2 E h δ z ( d ) ⊥ i The outer expectation on the right hand side only af fects the term in the expectation through the size of the activ e set of units. F or ReLUs, p = P ( h ( d +1) i > 0) and for hard tanh, we hav e p = P ( | h ( d +1) i | < 1) , and noting that we get a non-zero norm only if |A W ( d ) k | ≥ 2 (else we cannot project do wn a dimension), and for |A W ( d ) k | ≥ 2 , √ 2 q 2 |A W ( d ) k | − 3 2 ≥ 1 √ 2 q |A W ( d ) k | we get E W ( d ) h δ z ( d +1) ⊥ i ≥ 1 √ 2 k X j =2 k j p j (1 − p ) k − j σ √ k p j E h δ z ( d ) ⊥ i W e use the fact that we ha ve the probability mass function for an ( k , p ) binomial random variable to bound the √ j term: k X j =2 k j p j (1 − p ) k − j σ √ k p j = − k 1 p (1 − p ) k − 1 σ √ k + k X j =0 k j p j (1 − p ) k − j σ √ k p j = − σ √ k p (1 − p ) k − 1 + k p · σ √ k k X j =1 1 √ j k − 1 j − 1 p j − 1 (1 − p ) k − j But by using Jensen’ s inequality with 1 / √ x , we get k X j =1 1 √ j k − 1 j − 1 p j − 1 (1 − p ) k − j ≥ 1 q P k j =1 j k − 1 j − 1 p j − 1 (1 − p ) k − j = 1 p ( k − 1) p + 1 where the last equality follo ws by recognising the expectation of a binomial ( k − 1 , p ) random variable. So putting together , we get E W ( d ) h δ z ( d +1) ⊥ i ≥ 1 √ 2 − σ √ k p (1 − p ) k − 1 + σ · √ k p p 1 + ( k − 1) p ! E h δ z ( d ) ⊥ i (a) From here, we must analyse the hard tanh and ReLU cases separately . First considering the hard tanh case: T o lower bound p , we first note that as h ( d +1) i is a normal random variable with v ariance ≤ σ 2 , if A ∼ N (0 , σ 2 ) P ( | h ( d +1) i | < 1) ≥ P ( | A | < 1) ≥ 1 σ √ 2 π (b) On the Expressi ve P ower of Deep Neural Networks where the last inequality holds for σ ≥ 1 and follo ws by T aylor expanding e − x 2 / 2 around 0 . Similarly , we can also show that p ≤ 1 σ . So this becomes E h δ z ( d +1) i ≥ 1 √ 2 1 (2 π ) 1 / 4 √ σ k q σ √ 2 π + ( k − 1) − √ k 1 − 1 σ k − 1 E h δ z ( d ) ⊥ i = O √ σ k √ σ + k ! E h δ z ( d ) ⊥ i Finally , we can compose this, to get E h δ z ( d +1) i ≥ 1 √ 2 1 (2 π ) 1 / 4 √ σ k q σ √ 2 π + ( k − 1) − √ k 1 − 1 σ k − 1 d +1 c · || δ x ( t ) || (c) with the constant c being the ratio of || δ x ( t ) ⊥ || to || δ x ( t ) || . So if our trajectory direction is almost orthogonal to x ( t ) (which will be the case for e.g. random circular arcs, c can be seen to be ≈ 1 by splitting into components as in Lemma 1 , and using Lemmas 3 , 4 .) The ReLU case (with no bias) is e ven easier . Noting that for random weights, p = 1 / 2 , and plugging in to equation (a), we get E W ( d ) h δ z ( d +1) ⊥ i ≥ 1 √ 2 − σ √ k 2 k + σ · √ k p 2( k + 1) ! E h δ z ( d ) ⊥ i (d) But the expression on the right hand side has e xactly the asymptotic form O ( σ √ k / √ k + 1) , and we finish as in (c). Result for non-zero bias In fact, we can easily extend the above result to the case of non-zero bias. The insight is to note that because δ z ( d +1) in volves taking a differ ence between z ( d +1) ( t + dt ) and z ( d +1) ( t ) , the bias term does not enter at all into the expression for δz ( d +1) . So the computations abov e hold, and equation (a) becomes E W ( d ) h δ z ( d +1) ⊥ i ≥ 1 √ 2 − σ w √ k p (1 − p ) k − 1 + σ w · √ k p p 1 + ( k − 1) p ! E h δ z ( d ) ⊥ i For ReLUs, we require h ( d +1) i = w ( d +1) i z ( d ) i + b ( d +1) i > 0 where the bias and weight are drawn from N (0 , σ 2 b ) and N (0 , σ 2 w ) respecti vely . But with p ≥ 1 / 4 , this holds as the signs for w , b are purely random. Substituting in and working through results in the same asymptotic behavior as without bias. For hard tanh, not that as h ( d +1) i is a normal random variable with v ariance ≤ σ 2 w + σ 2 b (as equation (b) becomes P ( | h ( d +1) i | < 1) ≥ 1 p ( σ 2 w + σ 2 b ) √ 2 π This giv es Theorem 3 E h δ z ( d +1) i ≥ O σ w ( σ 2 w + σ 2 b ) 1 / 4 · √ k q p σ 2 w + σ 2 b + k E h δ z ( d ) ⊥ i On the Expressi ve P ower of Deep Neural Networks 2 4 6 8 10 12 14 Network depth 1 0 0 1 0 1 1 0 2 1 0 3 1 0 4 1 0 5 1 0 6 Trajectory length Trajectory length growth with increasing depth w50 scl3 w1000 scl3 w50 scl5 w500 scl5 w100 scl8 w700 scl8 w300 scl10 w700 scl10 Figure 12. The figure abov e shows trajectory growth with different initialization scales as a trajectory is propagated through a fully connected network for MNIST , with Relu activations. Note that as described by the bound in Theorem 3 we see that trajectory growth is 1) exponential in depth 2) increases with initialization scale and width, 3) increases faster with scale over width, as expected from σ w compared to p k / ( k + 1) in the Theorem. Statement and Proof of Upper Bound f or T rajectory Gr owth f or Hard T anh Replace hard-tanh with a linear coordinate-wise identity map, h ( d +1) i = ( W ( d ) z ( d ) ) i + b i . This provides an upper bound on the norm. W e also then recov er a chi distribution with k terms, each with standard deviation σ w k 1 2 , E h δ z ( d +1) i ≤ √ 2 Γ (( k + 1) / 2) Γ ( k / 2) σ w k 1 2 δ z ( d ) (2) ≤ σ w k + 1 k 1 2 δ z ( d ) , (3) where the second step follows from ( Lafor gia and Natalini , 2013 ), and holds for k > 1 . Proof of Theor em 4 Pr oof. For σ b = 0 : For hidden layer d < n , consider neuron v ( d ) 1 . This has as input P k i =1 W ( d − 1) i 1 z ( d − 1) i . As we are in the large σ case, we assume that | z ( d − 1) i | = 1 . Furthermore, as signs for z ( d − 1) i and W ( d − 1) i 1 are both completely random, we can also assume wlog that z ( d − 1) i = 1 . For a particular input, we can define v ( d ) 1 as sensitive to v ( d − 1) i if v ( d − 1) i transitioning (to wlog − 1 ) will induce a transition in node v ( d ) 1 . A sufficient condition for this to happen is if | W i 1 | ≥ | P j 6 = i W j 1 | . But X = W i 1 ∼ N (0 , σ 2 /k ) and P j 6 = i W j 1 = Y 0 ∼ N (0 , ( k − 1) σ 2 /k ) . So we want to compute P ( | X | > | Y 0 | ) . For ease of computation, we instead look at P ( | X | > | Y | ) , where Y ∼ N (0 , σ 2 ) . But this is the same as computing P ( | X | / | Y | > 1) = P ( X/ Y < − 1) + P ( X/ Y > 1) . But the ratio of two centered independent normals with variances σ 2 1 , σ 2 2 follows a Cauchy distribution, with parameter σ 1 /σ 2 , which in this case is 1 / √ k . Substituting this in to the cdf of the Cauchy distribution, we get that P | X | | Y | > 1 = 1 − 2 π arctan( √ k ) On the Expressi ve P ower of Deep Neural Networks (a) 0 2 4 6 8 10 12 Depth 1 0 0 1 0 1 1 0 2 1 0 3 1 0 4 1 0 5 Trajectory Length T r a j e c t o r y L e n g t h , k = 3 2 σ 2 w = 0 . 5 σ 2 w = 1 σ 2 w = 4 σ 2 w = 1 6 σ 2 w = 6 4 (b) 0 2 4 6 8 10 12 Depth 1 0 0 1 0 1 1 0 2 Trajectory Length T r a j e c t o r y L e n g t h , σ 2 w = 4 k = 1 k = 4 k = 1 6 k = 6 4 k = 2 5 6 (c) 0 100 200 300 400 500 600 Width 2 0 2 4 6 8 10 12 | | δ x d + 1 | | | | δ x d | | Perturbation Growth σ 2 w = 1 σ 2 w = 1 6 σ 2 w = 6 4 (d) 0 50 100 150 200 250 300 σ 2 w 5 0 5 10 15 20 | | δ x d + 1 | | | | δ x d | | Perturbation Growth k = 2 k = 3 2 k = 5 1 2 Figure 13. The exponential growth of trajectory length with depth, in a random deep network with hard-tanh nonlinearities. A circular trajectory is chosen between two random vectors. The image of that trajectory is taken at each layer of the network, and its length measured. (a,b) The trajectory length vs. layer, in terms of the network width k and weight v ariance σ 2 w , both of which determine its growth rate. (c,d) The av erage ratio of a trajectory’ s length in layer d + 1 relative to its length in layer d . The solid line sho ws simulated data, while the dashed lines sho w upper and lower bounds (Theorem 3 ). Gro wth rate is a function of layer width k , and weight variance σ 2 w . On the Expressi ve P ower of Deep Neural Networks Finally , using the identity arctan( x ) + arctan(1 /x ) and the Laurent series for arctan(1 /x ) , we can ev aluate the right hand side to be O (1 / √ k ) . In particular P | X | | Y | > 1 ≥ O 1 √ k (c) This means that in expectation, any neuron in layer d will be sensiti ve to the transitions of √ k neurons in the layer below . Using this, and the fact the while v ( d − 1) i might flip very quickly from say − 1 to 1 , the gradation in the transition ensures that neurons in layer d sensitiv e to v ( d − 1) i will transition at distinct times, we get the desired growth rate in expectation as follows: Let T ( d ) be a random v ariable denoting the number of transitions in layer d . And let T ( d ) i be a random v ariable denoting the number of transitions of neuron i in layer d . Note that by linearity of expectation and symmetry , E T ( d ) = P i E h T ( d ) i i = k E h T ( d ) 1 i Now , E h T ( d +1) 1 i ≥ E h P i 1 (1 ,i ) T ( d ) i i = k E h 1 (1 , 1) T ( d ) 1 i where 1 (1 ,i ) is the indicator function of neuron 1 in layer d + 1 being sensitiv e to neuron i in layer d . But by the independence of these two events, E h 1 (1 , 1) T ( d ) 1 i = E 1 (1 , 1) · E h T ( d ) 1 i . But the firt time on the right hand side is O (1 / √ k ) by (c), so putting it all together , E h T ( d +1) 1 i ≥ √ k E h T ( d ) 1 i . Written in terms of the entire layer , we have E T ( d +1) ≥ √ k E T ( d ) as desired. For σ b > 0 : W e replace √ k with p k (1 + σ 2 b /σ 2 w ) , by noting that Y ∼ N (0 , σ 2 w + σ 2 b ) . This results in a gro wth rate of form O ( √ k / q 1 + σ 2 b σ 2 w ) . B.3. Dichotomies: a natural dual Our measures of expressi vity have mostly concentrated on sweeping the input along a trajectory x ( t ) and taking measures of F A ( x ( t ); W ) . Instead, we can also sweep the weights W along a trajectory W ( t ) , and look at the consequences (e.g. binary labels – i.e. dichotomies ), say for a fix ed set of inputs x 1 , ..., x s . In fact, after random initialization, sweeping the first layer weights is statistically very similar to sweeping the input along a trajectory x ( t ) . In particular , letting W 0 denote the first layer weights, for a particular input x 0 , x 0 W 0 is a vector , each coordinate is iid, ∼ N (0 , || x 0 || 2 σ 2 w ) . Extending this observ ation, we see that (providing norms are chosen appropriately), x 0 W 0 cos( t ) + x 1 W 0 sin( t ) (fix ed x 0 , x 1 , W ) has the same distrib ution as x 0 W 0 0 cos( t ) + x 0 W 0 1 sin( t ) (fix ed x 0 , W 0 0 , W 0 1 ). So we e xpect that there will be similarities between results for sweeping weights and for sweeping input trajectories, which we e xplore through some synthetic experiments, primarily for hard tanh, in Figures 15 , 16 . W e find that the proportionality of transitions to trajectory length e xtends to dichotomies, as do results on the expressi ve po wer afforded by remaining depth. For non-random inputs and non-random functions, this is a well known question upper bounded by the Sauer-Shelah lemma ( Sauer , 1972 ). W e discuss this further in Appendix ?? . In the random setting, the statistical duality of weight sweeping and input sweeping suggests a direct proportion to transitions and trajectory length for a fixed input. Furthermore, if the x i ∈ S are sufficiently uncorrelated (e.g. random) class label transitions should occur independently for each x i Indeed, we show this in Figure 14 . C. Addtional Experiments from Section 3 Here we include additional experiments from Section 3 On the Expressi ve P ower of Deep Neural Networks (a) 0 2 4 6 8 10 12 14 16 18 R e m a i n i n g D e p t h d r 1 0 0 1 0 1 1 0 2 1 0 3 1 0 4 1 0 5 Unique Patterns Dichotomies vs. Remaining Depth k = 2 k = 8 k = 3 2 k = 1 2 8 k = 5 1 2 (b) 0 100 200 300 400 500 600 W i d t h k 1 0 0 1 0 1 1 0 2 1 0 3 1 0 4 1 0 5 Unique Patterns Dichotomies vs. Width d r = 1 d r = 3 d r = 5 d r = 7 d r = 9 d r = 1 1 d r = 1 3 d r = 1 5 d r = 1 7 Figure 14. W e sweep the weights W of a layer through a trajectory W ( t ) and count the number of labellings ov er a set of datapoints. When W is the first layer, this is statistically identical to sweeping the input through x ( t ) (see Appendix). Thus, similar results are observed, with exponential increase with the depth of an architecture, and much slower increase with width. Here we plot the number of classification dichotomies over s = 15 input vectors achieved by sweeping the first layer weights in a hard-tanh network along a one-dimensional great circle trajectory . W e show this (a) as a function of depth for several widths, and (b) as a function of width for sev eral depths. All networks were generated with weight variance σ 2 w = 8 , and bias variance σ 2 b = 0 . On the Expressi ve P ower of Deep Neural Networks 0 2 4 6 8 10 12 14 16 R e m a i n i n g D e p t h d r 1 0 1 1 0 2 1 0 3 1 0 4 1 0 5 Unique Dichotomies Dichotomies vs. Remaining Depth L a y e r s w e p t = 1 L a y e r s w e p t = 4 L a y e r s w e p t = 8 L a y e r s w e p t = 1 2 All dichotomies Figure 15. Expressi ve po wer depends only on remaining network depth. Here we plot the number of dichotomies achie ved by sweeping the weights in different network layers through a 1-dimensional great circle trajectory , as a function of the remaining network depth. The number of achie vable dichotomies does not depend on the total network depth, only on the number of layers abov e the layer swept. All networks had width k = 128 , weight variance σ 2 w = 8 , number of datapoints s = 15 , and hard-tanh nonlinearities. The blue dashed line indicates all 2 s possible dichotomies for this random dataset. On the Expressi ve P ower of Deep Neural Networks 1 0 0 1 0 1 1 0 2 1 0 3 1 0 4 1 0 5 Transitions 1 0 0 1 0 1 1 0 2 1 0 3 1 0 4 1 0 5 Unique Dichotomies Dichotomies vs. Transitions k = 2 k = 8 k = 3 2 k = 1 2 8 k = 5 1 2 All dichotomies Random walk Figure 16. Here we plot the number of unique dichotomies that have been observed as a function of the number of transitions the network has under gone. Each datapoint corresponds to the number of transitions and dichotomies for a hard-tanh network of a dif ferent depth, with the weights in the first layer undergoing interpolation along a great circle trajectory W (0) ( t ) . W e compare these plots to a random walk simulation, where at each transition a single class label is flipped uniformly at random. Dichotomies are measured ov er a dataset consisting of s = 15 random samples, and all networks had weight variance σ 2 w = 16 . The blue dashed line indicates all 2 s possible dichotomies. On the Expressi ve P ower of Deep Neural Networks 0 100 200 300 400 500 Epoch Number 0.2 0.3 0.4 0.5 0.6 Accuracy Train Accuracy Against Epoch 0 100 200 300 400 500 Epoch Number Test Accuracy Against Epoch lay 2 lay 3 lay 4 lay 5 lay 6 lay 7 lay 8 Figure 17. W e repeat a similar experiment in Figure 7 with a fully connected network on CIF AR-10, and mostly observe that training lower layers again leads to better performance, although, as expected, ov erall performance is impacted by training only a single layer . The networks had width k = 200 , weight variance σ 2 w = 1 , and hard-tanh nonlinearities. W e again only train from the second hidden layer on so that the number of parameters remains fixed. The theory only applies to training error (the ability to fit a function), and generalisation accuracy remains lo w in this very constrained setting. On the Expressi ve P ower of Deep Neural Networks Figure 18. T raining increases the trajectory length for smaller initialization v alues of σ w . This e xperiment plots the growth of trajectory length as a circular interpolation between two MNIST datapoints is propagated through the network, at different train steps. Red indicates the start of training, with purple the end of training. W e see that the training process incr eases trajectory length, likely to increase the expressi vity of the input-output map to enable greater accuracy .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment