An Entity Resolution approach to isolate instances of Human Trafficking online
Human trafficking is a challenging law enforcement problem, and a large amount of such activity manifests itself on various online forums. Given the large, heterogeneous and noisy structure of this data, building models to predict instances of trafficking is an even more convolved a task. In this paper we propose and entity resolution pipeline using a notion of proxy labels, in order to extract clusters from this data with prior history of human trafficking activity. We apply this pipeline to 5M records from backpage.com and report on the performance of this approach, challenges in terms of scalability, and some significant domain specific characteristics of our resolved entities.
💡 Research Summary
The paper presents a comprehensive entity‑resolution (ER) pipeline designed to uncover sources of human trafficking hidden within online escort advertisements, specifically those harvested from backpage.com. The authors processed roughly five million ads, each containing noisy, unstructured text, images, hyperlinks, timestamps, and location metadata.
Feature Extraction:
A regular‑expression‑based extractor (AnonymousExtractor) was built to pull fifteen domain‑specific fields (age, cost, email, ethnicity, eye/hair color, name, phone number, restrictions, skin color, URL, height, measurements, weight) as well as image hash codes, posting dates, and geolocation. Evaluation on 1,000 manually annotated ads showed high precision and recall (F1 scores ranging from 0.84 to 0.99), with phone numbers and URLs achieving near‑perfect extraction (F1 ≈ 0.997).
Proxy Label Generation:
Phone numbers, deemed “strong features,” serve as proxy ground‑truth. Any pair of ads sharing a phone number is labeled positive (same source), while pairs without any shared strong feature are labeled negative. To avoid over‑representing near‑duplicate text, the authors introduced a sampling bias: positive pairs are selected such that their strong‑feature sets do not intersect, ensuring diverse training examples. Jaccard similarity of unigrams is used to illustrate the distribution of text similarity in the sampled pairs, confirming a mix of near‑duplicates and dissimilar pairs.
Match Function Learning:
Several classifiers (Logistic Regression, Naïve Bayes, Random Forest) were trained on the generated pairs using Scikit‑learn. Random Forest consistently outperformed the others, achieving an ROC curve with true‑positive rates above 90 % at false‑positive rates of 1 % or lower. Feature importance analysis revealed that spatial (state), textual (number of special characters, longest common substring, unique token count), and temporal (time difference, same‑day posting) attributes were most predictive, confirming that human‑trafficking networks exhibit strong spatio‑temporal and linguistic cohesion.
Scalability via Blocking:
Given the O(N²) cost of exhaustive pairwise comparison, the authors introduced a blocking scheme based on rare unigrams, rare bigrams, and rare image hashes. Blocking rules were selected using support and lift metrics (e.g., “Xminchars ≤ 250 ∧ 120 000 < Xmaximgfrq ∧ 3 < Xmnweeks ≤ 3.4 ∧ 4 < Xmnmonths ≤ 6.5” achieved a lift of 2.67). This reduced the number of comparisons dramatically while preserving the ability to discover cross‑block links later in the pipeline.
Connected‑Component Analysis:
After applying the learned match function, the ads form a graph where edges indicate likely common source. Connected components (clusters) with more than 300 ads were extracted for downstream analysis. A second Random Forest classifier, trained on component‑level features (size, posting month/week variance, image‑frequency standard deviation, normalized counts of names and unique images), achieved a true‑positive rate of 90.38 % at a 1 % false‑positive rate. Rule learning on the same feature set produced high‑lift rules that mirrored the Random Forest’s top features, providing interpretable patterns such as “posting months ≤ 0.03 ∧ 1.95 < std‑weeks ≤ 2.2 ∧ 3.2 < std‑months.”
Empirical Findings:
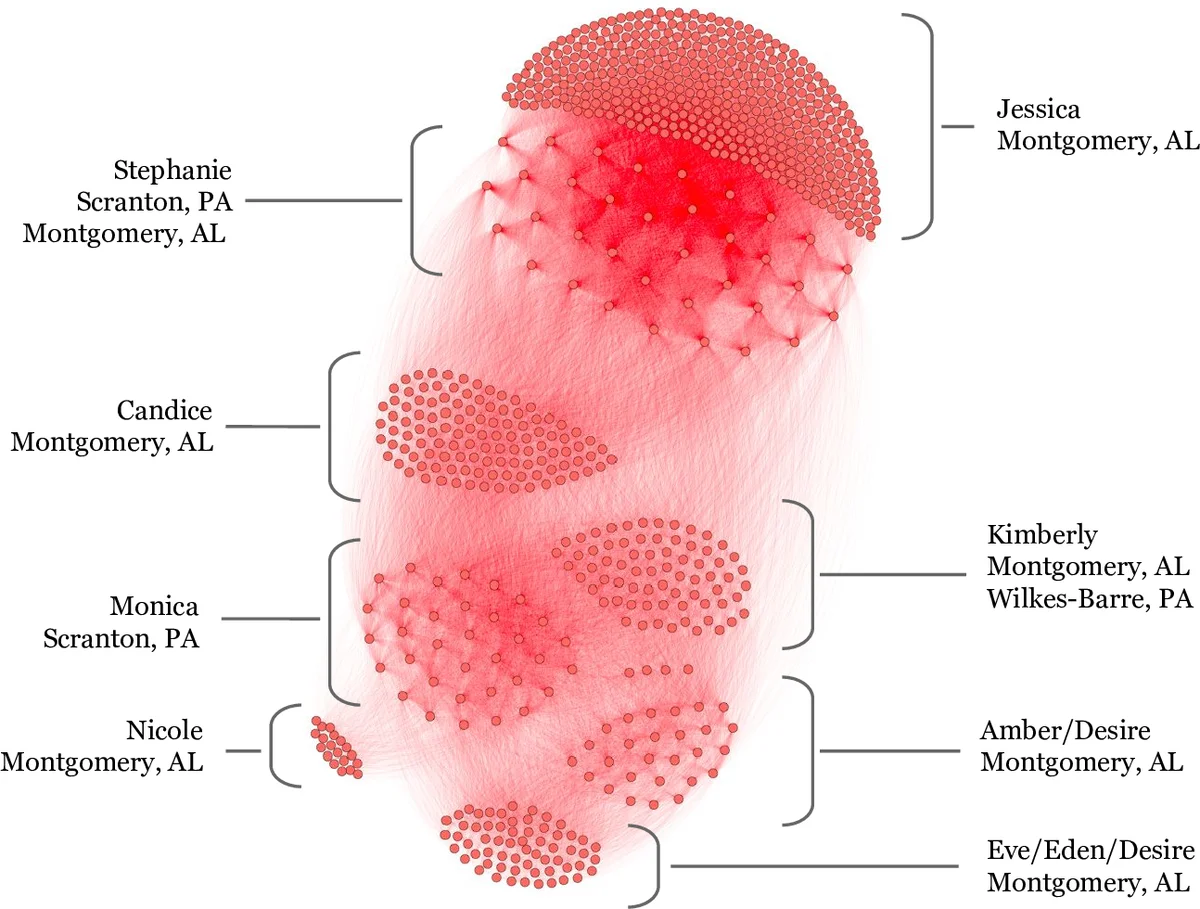
The pipeline successfully identified large, multi‑state clusters. One highlighted entity comprised 802 ads and 39,383 edges, spanning several states and employing multiple phone numbers and aliases, illustrating the organized and distributed nature of trafficking operations. Visualizations generated with Gephi demonstrated dense interconnections even when no phone number was present, confirming the match function’s ability to capture subtle, non‑obvious links.
Conclusions and Future Work:
The study demonstrates that proxy labeling via strong features enables supervised learning for ER in a domain where true labels are scarce. The resulting system attains low false‑positive rates, essential for law‑enforcement applicability, and scales to millions of records through effective blocking. Limitations include reliance on phone numbers (which traffickers can rotate or omit), the brittleness of regex‑based extraction to evolving slang, and limited exploitation of image content beyond hash codes. Future directions suggested are incorporating deep‑learning text embeddings, multimodal image‑text models, and dynamic crowdsourced validation to further improve robustness and adaptability.
Comments & Academic Discussion
Loading comments...
Leave a Comment