ChoiceRank: Identifying Preferences from Node Traffic in Networks
Understanding how users navigate in a network is of high interest in many applications. We consider a setting where only aggregate node-level traffic is observed and tackle the task of learning edge transition probabilities. We cast it as a preferenc…
Authors: Lucas Maystre, Matthias Grossglauser
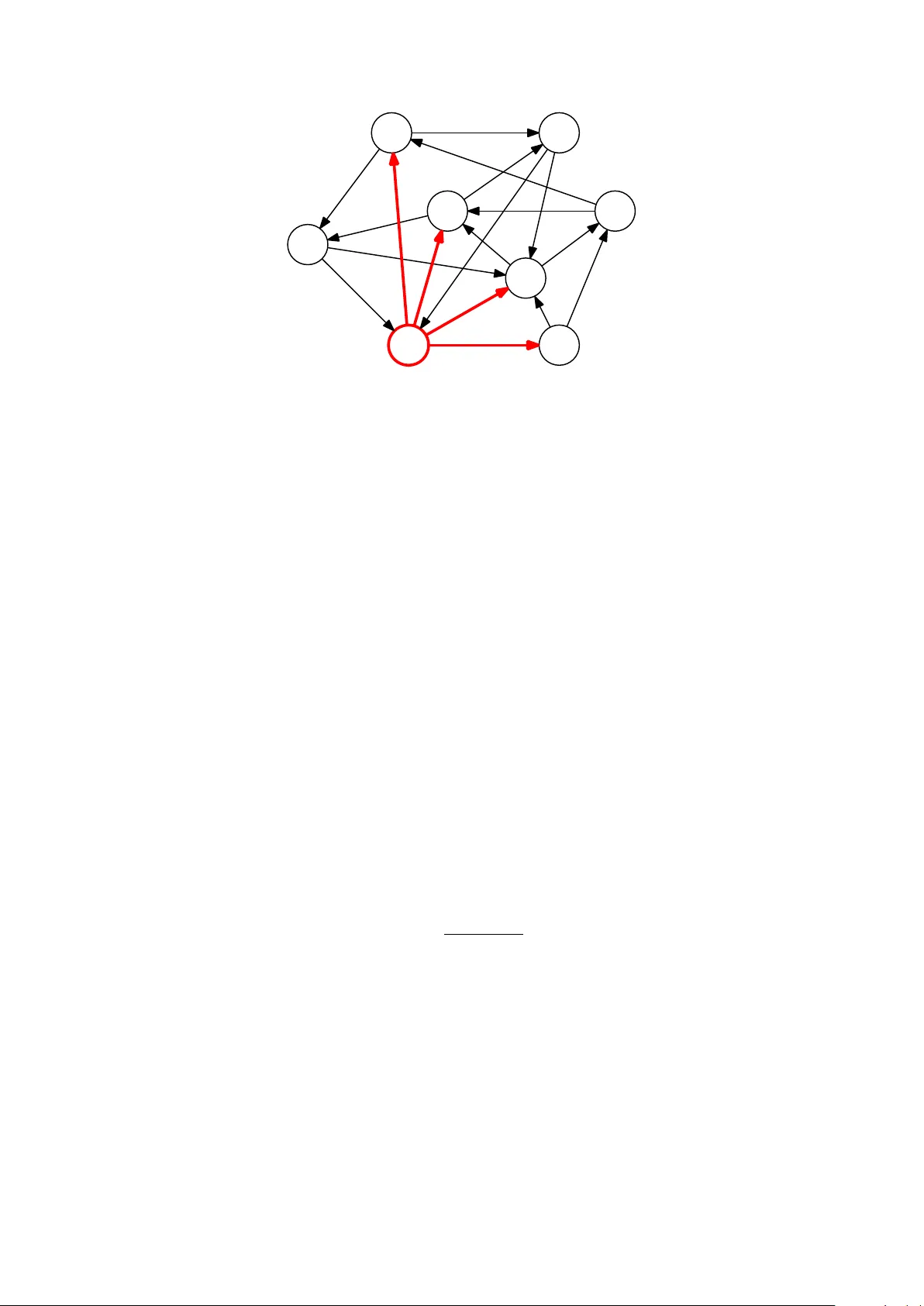
ChoiceRank: Iden tifying Preferences from No de T raffic in Net w orks Lucas Ma ystre ∗ lucas.maystre@epfl.ch Matthias Grossglauser ∗ matthias.grossglauser@epfl.ch June 16, 2017 Abstract Understanding ho w users navigate in a net work is of high interest in man y applications. W e consider a setting where only aggregate no de-lev el traffic is observed and tac kle the task of learning edge transition probabilities. W e cast it as a preference learning problem, and w e study a mo del where c hoices follow Luce’s axiom. In this case, the O ( n ) marginal coun ts of no de visits are a sufficien t statistic for the O ( n 2 ) transition probabilities. W e sho w ho w to make the inference problem w ell-p osed regardless of the netw ork’s structure, and we presen t ChoiceRank, an iterative algorithm that scales to netw orks that con tains billions of no des and edges. W e apply the model to t w o clickstream datasets and sho w that it successfully recov ers the transition probabilities using only the net work structure and marginal (no de-lev el) traffic data. Finally , we also consider an application to mobility netw orks and apply the mo del to one y ear of rides on New Y ork Cit y’s bicycle-sharing system. 1 In tro duction Consider the problem of estimating clic k probabilities for links b etw een pages of a website, giv en a h yp erlink graph and aggregate statistics on the num b er of times each page has b een visited. Naively , one might exp ect that the probability of clicking on a particular link should b e roughly prop ortional to the traffic of the link’s target. Ho wev er, this neglects imp ortant structural effects: a page’s traffic is influenced by a ) the num b er of incoming links, b ) the traffic at the pages that link to it, and c ) the traffic absorb ed by comp eting links. In order to successfully infer clic k probabilities, it is therefore necessary to disen tangle the pr efer enc e for a page (i.e., the in trinsic prop ensity of a user to click on a link p ointing to it) from the page’s visibility (the exp osure it gets from pages linking to it). Building up on recen t w ork b y Kumar et al. [2015], w e presen t a statistical framework that tac kles a general formulation of the problem: given a netw ork (representing p ossible transitions b et ween no des) and the marginal traffic at eac h no de, reco ver the transition probabilities. This problem is relev an t to a num b er of scenarios (in so cial, information ∗ Sc ho ol of Computer and Communication Sciences, EPFL, Switzerland. 1 or transp ortation netw orks) where transition data is not av ailable due to, e.g., priv acy concerns or monitoring costs. W e b egin by p ostulating the follo wing mo del of traffic. Users navigate from no de to no de along the edges of the netw ork by making a choice b etw een adjacen t no des at each step, reminiscent of the random-surfer mo del introduced b y Brin and Page [1998]. Choices are assumed to b e indep endent and generated according to Luce’s mo del [Luce, 1959]: each no de in the netw ork is chararacterized by a laten t str ength parameter, and (sto chastic) c hoice outcomes tend to fav or no des with greater strengths. In this mo del, estimating the transition probabilities amounts to estimating the strength parameters. Unlik e the setting in whic h choice mo dels are traditionally studied [T rain, 2009, Ma ystre and Grossglauser, 2015, V o jno vic and Y un, 2016], we do not observe distinct choices among well-iden tified sets of alternativ es. Instead, w e only hav e access to aggregate, marginal statistics ab out the traffic at eac h no de in the netw ork. In this setting, w e make the following contributions. 1. W e observe that marginal p er-no de traffic is a sufficient statistic for the strength parameters. That is, the parameters can b e inferred from marginal traffic data without an y loss of information. 2. W e sh o w that if the parameters are endo wed with a prior distribution, the inference problem b ecomes well-posed regardless of the net work structure. This is a crucial step in making the framew ork applicable to real-world datasets. 3. W e show that mo del inference can scale to v ery large datasets. W e present an iterative EM-t yp e inference algorithm that enables a remark ably efficien t implementation— eac h iteration requires the computational equiv alen t of tw o iterations of P ageRank. W e ev aluate t w o asp ects of our framew ork using real-w orld net works. W e b egin b y demonstrating that lo cal preferences can indeed b e inferred from global traffic: we in vestigate the accuracy of the transition probabilities reco v ered by our mo del on three datasets for which we hav e ground-truth transition data. First, we consider tw o hyperlink graphs, represen ting the English Wikip edia (ov er tw o million no des) and a Hungarian news p ortal (approximately 40 000 no des), resp ectively . W e mo del clickstream data as a sequence of indep endent choices o ver the links a v ailable at each page. Given only the structure of the graph and the marginal traffic at ev ery no de, we estimate the num b er of transitions b et ween no des, and we find that our estimate matc hes ground-truth edge-level transitions accurately in b oth instances. Second, we consider the net work of New Y ork Cit y’s bicycle-sharing service. F or a giv en ride, giv en a pick-up station, we mo del the drop-off station as a c hoice out of a set of lo cations. Our mo del yields promising results, suggesting that our method can b e useful b eyond clic kstream data. Next, we test the scalabilit y of the inference algorithm. W e show that the algorithm is able to pro cess a snapshot of the WWW hyperlink graph containing o ver a hundred billion edges using a single mac hine. Organization of the pap er. In Section 2, w e formalize the net work choice mo del. In Section 3, w e briefly review related literature. In Section 4, w e present salient statistical prop erties of the mo del and its maxim um-likelihoo d estimator, and w e prop ose a prior distribution that mak es the inference problem well-posed. In Section 5, we describ e an 2 1 3 4 2 5 6 8 7 Figure 1: An illustration of one step of the pro cess. The user is at no de 6 and can reach no des N + 6 = { 1 , 2 , 5 , 7 } . inference algorithm that enables an efficient implementation. W e ev aluate the mo del and the inference algorithm in Section 6, b efore concluding in Section 7. In the app endices, we pro vide a more in-depth discussion of our mo del and algorithm, and we present pro ofs for all the theorems stated in the main text. 2 Net w ork Choice Mo del Let G = ( V , E ) b e a directed graph on n no des (corresp onding to items) and m edges. W e denote the out-neighborho o d of no de i b y N + i and its in-neighborho o d by N − i . W e consider the following choice pro cess on G . A user starts at a no de i and is faced with alternativ es N + i . The user chooses item j and mo ves to the corresp onding no de. At no de j , the user is faced with alternativ es N + j and c ho oses k , and so on. At any time, the user can stop. Figure 1 gives an example of a graph and the alternatives av ailable at a step of the pro cess. T o define the transition probabilities, w e p osit Luce’s well-kno wn choice axiom that states that the odds of c ho osing item j o ver item j 0 do not dep end on the rest of the alternativ es [Luce, 1959]. This axiom leads to a unique probabilistic mo del of c hoice. F or ev ery no de i and ev ery j ∈ N + i , the probabilit y that j is selected among alternativ es N + i can b e written as p ij = λ j P k ∈ N + i λ k (1) for some parameter v ector λ = λ 1 · · · λ n > ∈ R n > 0 . Intuitiv ely , the parameter λ i can b e interpreted as the strength (or utilit y) of item i . Note that p ij dep ends only on the out-neigh b orho o d of no de i . As such, the choice pro cess satisfies the Marko v prop ert y , and we can think of the sequence of c hoices as a tra jectory in a Marko v chain. In the con text of this mo del, we can formulate the inference problem as follo ws. Giv en a directed graph G = ( V , E ) and data on the aggregate traffic at eac h no de, find a parameter vector λ that fits the data. 3 3 Related W ork A v arian t of the netw ork c hoice mo del w as recently introduced by Kumar et al. [2015], in an article that la ys muc h of the groundwork for the present pap er. Their generative mo del of traffic and the parametrization of transition probabilities based on Luce’s axiom form the basis of our w ork. Kumar et al. define the ste ady-state inversion problem as follo ws: Given a graph G and a target stationary distribution, find transition probabilities that lead to the desired stationary distribution. This problem form ulation assumes that G satisfies restrictive structural prop erties (strong-connectedness, ap erio dicity) and is v alid only asymptotically , when the sequences of c hoices made b y users are very long. Our form ulation is, in con trast, more general. In particular, w e eliminate any assumptions ab out the structure of G and cop e with finite data in a principled w a y—in fact, our deriv ations are v alid for choice sequences of any length. One of our contributions is to explain the steady-state in version problem in terms of (asymptotic) maxim um-likelihoo d inference in the net w ork choice mo del. F urthermore, the statistical viewp oint that we dev elop also leads to a ) a robust regularization sc heme, and b ) a s imple and efficient EM-t yp e inference algorithm. These imp ortan t extensions mak e the mo del easier to apply to real-w orld data. Luce’s c hoice axiom. The general problem of estimating parameters of mo dels based on Luce’s axiom has received considerable atten tion. Sev eral decades b efore Luce’s seminal b o ok [Luce, 1959], Zermelo [1928] prop osed a mo del and an algorithm that estimates the strengths of c hess pla yers based on pairwise comparison outcomes (his mo del would later b e redisco vered b y Bradley and T erry [1952]). More recently , Hun ter [2004] explained Zermelo’s algorithm from the p ersp ective of the minorization-maximization (MM) metho d. This metho d is easily generalized to other mo dels that are based on Luce’s axiom, and it yields simple, pro v ably conv ergen t algorithms for maximum-lik eliho o d (ML) or maximum- a-p osteriori p oint estimates. Caron and Doucet [2012] observe that these MM algorithms can b e further recast as exp ectation-maximization (EM) algorithms b y introducing suitable laten t v ariables. They use this observ ation to deriv e Gibbs samplers for a wide family of mo dels. W e take adv an tage of this long line of work in Section 5 when developing an inference algorithm for the net work choice mo del. In recent years, several authors hav e also analyzed the sample complexit y of the ML estimate in Luce’s choice mo del [Ha jek et al., 2014, V o jno vic and Y un, 2016] and inv estigated alternative sp ectral inference metho ds [Negah ban et al., 2012, Azari Soufiani et al., 2013, Maystre and Grossglauser, 2015]. Some of these results could b e applied to our setting, but in general they require observing c hoices among well-iden tified sets of alternativ es. Finally , we note that mo dels based on Luce’s axiom hav e b een successfully applied to problems ranging from ranking play ers based on game outcomes [Zermelo, 1928, Elo, 1978] to understanding consumer b ehavior based on discrete choices [McF adden, 1973], and to discriminating among m ultiple classes based on the output of pairwise classifiers [Hastie and Tibshirani, 1998]. Net work analysis. Understanding the preferences of users in net works is of significant in terest in man y domains. F or brevit y , we fo cus on literature related to h yp erlink graphs. A metho d that has undoubtedly had a tremendous impact in this con text is P ageRank [Brin and Page, 1998]. PageRank computes a set of scores that are prop ortional to the 4 amoun t of time a surfer, who clic ks on links randomly and uniformly , sp ends at eac h no de. These scores are based only on the structure of the graph. The net work c hoice mo del presented in this pap er app ears similar at first, but tac kles a differen t problem. In addition to the structure of the graph, it uses the traffic at each page, and computes a set of scores that reflect the (non-uniform) probabilit y of clicking on each link. Nev ertheless, there are striking similarities in the implementation of the resp ective inference algorithms (see Section 6). The HOT ness metho d prop osed by T omlin [2003] is somewhat related, but tries to tackle a harder problem. It attempts to estimate jointly the traffic and the probabilit y of clic king on eac h link, b y using a maximum-en trop y approach. At the other end of the sp ectrum, BrowseRank [Liu et al., 2008] uses detailed data collected in users’ bro wsers to improv e on Pa geRank. Our metho d uses only marginal traffic data that can b e obtained without trac king users. 4 Statistical Prop erties In this section, w e describ e some imp ortant statistical prop erties of the netw ork c hoice mo del. W e b egin by observing that O ( n ) v alues summarizing the traffic at each no de is a sufficien t statistic for the O ( n 2 ) entries of the Marko v-c hain transition matrix. W e then connect our statistical model to the steady-state in version problem defined b y Kumar et al. [2015]. Guided b y this connection, we study the maximum-lik eliho o d (ML) estimate of mo del parameters, but find that the estimate is lik ely to b e ill-defined in man y scenarios of practical interest. Lastly , we study ho w to ov ercome this issue by introducing a prior distribution on the parameters λ ; the prior guaran tees that the inference problem is w ell-p osed. F or simplicity of exp osition, w e present our results for Luce’s standard choice mo del defined in (1) . Our developmen ts extend to the mo del v arian t prop osed b y Kumar et al. [2015], where c hoice probabilities can b e mo dulated by edge weigh ts. In App endix A, we describ e this v arian t and give the necessary adjustmen ts to our developmen ts. 4.1 Aggregate T raffic Is a Sufficien t Statistic Let c ij denote the n umber of transitions that o ccurred along edge ( i, j ) ∈ E . Starting from the transition probability defined in (1) , w e can write the log-lik eliho o d of λ giv en data D = { c ij | ( i, j ) ∈ E } as ( λ ; D ) = X ( i,j ) ∈ E c ij log λ j − log X k ∈ N + i λ k = n X j =1 X i ∈ N − j c ij log λ j − n X i =1 X j ∈ N + i c ij log X k ∈ N + i λ k = n X i =1 c − i log λ i − c + i log X k ∈ N + i λ k , (2) where c − i = P j ∈ N − i c j i and c + i = P j ∈ N + i c ij is the aggregate n umber of transitions arriving in and originating from i , resp ectively . This formulation of the log-likelihoo d exhibits a k ey 5 feature of the mo del: the set of 2 n coun ts { ( c − i , c + i ) | i ∈ V } is a sufficien t statistic of the O ( n 2 ) coun ts { c ij | ( i, j ) ∈ E } for the parameters λ . (In App endix A, w e show that it is in fact minimally sufficient.) In other words, it is enough to observe marginal information ab out the num b er of arriv als and departures at eac h no de—w e collectiv ely call this data the tr affic at a no de—and no additional information can b e gained b y observing the full c hoice pro cess. This makes the mo del particularly attractive, b ecause it means that it is unnecessary to trac k users across no des. In several applications of practical in terest, trac king users is undesirable, difficult, or outright imp ossible, due to a ) priv acy reasons, b ) monitoring costs, or c ) lac k of data in existing datasets. Note that if w e make the additional assumption that the flo w in the netw ork is conserv ed, then c − i = c + i . If users’ t ypical tra jectories consist of many hops, it is reasonable to appro ximate c − i or c + i using that assumption, should one of the tw o quan tities b e missing. 4.2 Connection to the Steady-State In v ersion Problem In recen t w ork, Kumar et al. [2015] define the problem of ste ady-state inversion as follo ws: Given a strongly-connected directed graph G = ( V , E ) and a target distribution o ver the no des π , find a Mark ov chain on G with stationary distribution π . As there are m = O ( n 2 ) degrees of freedom (the transition probabilities) for n constrain ts (the stationary distribution), the problem is in most cases underdetermined. F ollowing Luce’s ideas, the transition probabilities are constrained to b e prop ortional to a laten t score of the destination no de as p er (1) , thus reducing the n umber of parameters from m to n . Denote by P ( s ) the Marko v-c hain transition matrix parametrized with scores s . The score v ector s is a solution for the steady-state inv ersion problem if and only if π = π P ( s ) , or equiv alen tly π i = X j ∈ N − i s i P k ∈ N + j s k π j ∀ i. (3) In order to formalize the connection b etw een Kumar et al.’s work and ours, w e no w express the steady-state inv ersion problem as that of asymptotic maximum-lik eliho o d estimation in the netw ork c hoice mo del. Supp ose that w e observe no de-level traffic data D = { ( c − i , c + i ) | i ∈ V } ab out a tra jectory of length T starting at an arbitrary no de. W e w ant to obtain an estimate of the parameters λ ? b y maximizing the a verage log-lik eliho o d ˆ ( λ ) = 1 T ( λ ; D ) . F rom standard conv ergence results for Mark ov c hains [Kemeny and Snell, 1976], it follo ws that as G is strongly connected, lim T →∞ c − i /T = lim T →∞ c + i /T = π i . Therefore, ˆ ( λ ) = n X i =1 c − i T log λ i − c + i T log X k ∈ N + i λ k T →∞ − − − → n X i =1 π i log λ i − log X k ∈ N + i λ k . Let λ ? b e a maximizer of the av erage log-likelihoo d. When T → ∞ , the optimality condition ∇ ˆ ( λ ? ) = 0 implies ∂ ˆ ( λ ) ∂ λ i λ = λ ? = π i λ ? i − X j ∈ N − i π j P k ∈ N + j λ ? k = 0 ⇐ ⇒ π i = X j ∈ N − i λ ? i P k ∈ N + j λ ? k π j ∀ i. (4) 6 Comparing (4) to (3) , it is clear that λ ? is a solution of the steady-state inv ersion problem. As suc h, the net work choice mo del presen ted in this pap er can b e viewed as a principled extension of the steady-state in version problem to the finite-data case. 4.3 Maxim um-Lik eliho o d Estimate The log-lik eliho o d (2) is not concav e in λ , but it can b e made concav e using the simple reparametrization λ i = e θ i . Therefore, any lo cal minimum of the lik eliho o d is a global minim um. Unfortunately , it turns out that the conditions guaranteeing that the ML estimate is w ell-defined (i.e., that it exists and is unique) are restrictiv e and impractical. W e illustrate this by providing a necessary condition, and for brevity w e defer the comprehensiv e analysis of the ML estimate to App endix B. W e b egin with a definition that uses the notion of hyp er gr aph , a generalized graph where edges may b e an y non-empty subset of no des. Definition (Comparison h yp ergraph) . Giv en a directed graph G = ( V , E ) , the c omp arison hyp er gr aph is the hypergraph H = ( V , A ) , with A = { N + i | i ∈ V } . In tuitively , H is the hypergraph induced by the sets of alternativ es av ailable at each no de. Figure 2 provides an example of a graph and of its asso ciated comparison hypergraph. Equipp ed with this definition, we can state the follo wing th eorem that is a reformulation of a w ell-known result for Luce’s choice mo del [Hunter, 2004]. Theorem 1. If the c omp arison hyp er gr aph is not c onne cte d, then for any data D ther e ar e λ and µ such that λ 6 = c µ for any c ∈ R > 0 and ( λ ; D ) = ( µ ; D ) . In short, the pro of shows that rescaling all the parameters in one of the connected comp onen ts do es not change the v alue of the lik eliho o d function. The netw ork of Figure 1 illustrates an instance where the condition fails: although the graph G is strongly connected, its asso ciated comparison hypergraph H (depicted in Figure 2) is disconnected, and no matter what the data D is, the ML estimate will never b e uniquely defined. In fact, in App endix B, we demonstrate that Theorem 1 is just the tip of the iceb erg. W e provide an example where the ML estimate do es not exist even though the comparison h yp ergraph is connected, and we explain that verifying a necessary and sufficien t condition for the existence of the ML estimate is computationally mor e exp ensive than solving the inference problem itself. 4.4 W ell-P osed Inference F ollowing the ideas of Caron and Doucet [2012], w e introduce an indep endent Gamma prior on eac h parameter, i.e., i.i.d. λ 1 , . . . , λ n ∼ Gamma ( α, β ) . A dding the log-prior to the log-lik eliho o d, w e can write the log-p osterior as log p ( λ | D ) = n X i =1 ( c − i + α − 1) log λ i − c + i log X k ∈ N + i λ k − β λ i + κ, (5) where κ is a constan t that is indep enden t of λ . The Gamma prior translates in to a form of regularization that makes the inference problem well-posed, as sho wn b y the follo wing theorem. 7 1 2 3 4 5 6 7 8 Figure 2: The comparison h yp ergraph asso ciated to the netw ork of Fig. 1. The h yp eredge asso ciated to N + 6 is highlighted in red. Note that the comp onen t { 3 , 4 } is disconnected from the rest of the h yp ergraph. Theorem 2. If i.i.d. λ 1 , . . . , λ n ∼ Gamma ( α, β ) with α > 1 , then the lo g-p osterior (5) always has a unique maximizer λ ? ∈ R n > 0 . The condition α > 1 ensures that the prior has a nonzero mo de. In short, the pro of of Theorem 2 shows that as a result of the Gamma prior, the log-posterior can b e reparametrized in to a strictly conca ve function with b ounded sup er-lev el sets (if α > 1 ). This guarantees that the log-p osterior will alwa ys hav e exactly one maximizer. Unlike the results that we derive for the ML estimate, Theorem 2 do es not imp ose any condition on the graph G for the estimate to b e w ell-defined. Remark. Note that v arying the rate β in the Gamma prior simply rescales the parame- ters λ . F urthermore, it is clear from (1) that such a rescaling affects neither the likelihoo d of the observed data nor the prediction of future transitions. As a consequence, we may assume that β = 1 without loss of generalit y . 5 Inference Algorithm The maximizer of the log-posterior do es not ha ve a closed-form solution. In the spirit of the algorithms of Hun ter [2004] for v ariants of Luce’s c hoice mo del, we develop a minorization-maximization (MM) algorithm. Simply put, the algorithm iteratively refines an estimate of the maximizer by solving a sequence of surrogates of the log-p osterior. Using the inequality log x ≤ log ˜ x + x/ ˜ x − 1 (with equality if and only if x = ˜ x ), w e can lo wer-bound the log-p osterior (5) by f ( t ) ( λ ) = n X i =1 ( c − i + α − 1) log λ i − c + i log X k ∈ N + i λ ( t ) k + P k ∈ N + i λ k P k ∈ N + i λ ( t ) k − 1 − β λ i + κ, 8 Algorithm 1 ChoiceRank Require: graph G = ( V , E ) , counts { ( c − i , c + i ) } 1: λ ← [1 , . . . , 1] 2: rep eat 3: z ← 0 n Recompute γ 4: for ( i, j ) ∈ E do z i ← z i + λ j 5: for i ∈ V do γ i ← c + i /z i 6: z ← 0 n Recompute λ 7: for ( i, j ) ∈ E do z j ← z j + γ i 8: for i ∈ V do λ i ← ( c − i + α − 1) / ( z i + β ) 9: until λ has conv erged with equality if and only if λ = λ ( t ) . Starting with an arbitrary λ (0) ∈ R n > 0 , we rep eatedly solv e the optimization problem λ ( t +1) = arg max λ f ( t ) ( λ ) . Unlik e the maximization of the log-p osterior, the surrogate optimization problem has a closed-form solution, obtained b y setting ∇ f ( t ) to 0 : λ ( t +1) i = c − i + α − 1 P j ∈ N − i γ ( t ) j + β , γ ( t ) j = c + j P k ∈ N + j λ ( t ) k . (6) The iterates prov ably conv erge to the maximizer of (5) , as shown by the following theorem. Theorem 3. L et λ ? b e the unique maximum a-p osteriori estimate. Then for any initial λ (0) ∈ R n > 0 the se quenc e of iter ates define d by (6) c onver ges to λ ? . Theorem 3 follo ws from a standard result on the conv ergence of MM algorithms and uses the fact that the log-p osterior increases after eac h iteration. F urthermore, it is known that MM algorithms exhibit geometric conv ergence in a neigh b orho o d of the maximizer [Lange et al., 2000]. A thorough inv estigation of the con v ergence prop erties is left for future w ork. The structure of the up dates in (6) leads to an extremely simple and efficient imple- men tation, given in Algorithm 1: we call it ChoiceRank. A graphical representation of an iteration from the p ersp ective of a single no de is given in Figure 3. Eac h iteration consists of tw o phases of message passing, with γ i flo wing tow ards in-neighbors N − i , then λ i flo wing tow ards out-neighbors N + i . The up dates to a no de’s state are a function of the sum of the messages. As the algorithm do es tw o passes ov er the edges and t wo passes o ver the v ertices, an iteration takes O ( m + n ) time. The edges can b e pro cessed in any order, and the algorithm maintains a state ov er only O ( n ) v alues asso ciated with the vertices. F urthermore, the algorithm can b e conv enien tly expressed in the w ell-known vertex-cen tric programming mo del [Malewicz et al., 2010]. This makes it easy to implemen t ChoiceRank inside scalable, optimized graph-pro cessing systems such as Apache Spark [Gonzalez et al., 2014]. 9 1 2 3 4 λ ( t +1) 2 = c − 2 + α − 1 γ ( t ) 3 + γ ( t ) 4 + β γ ( t ) 2 = c + 2 λ ( t ) 1 + λ ( t ) 3 γ 2 γ 3 γ 4 λ 1 λ 3 λ 2 λ 2 γ 2 Figure 3: One iteration of ChoiceRank from the p ersp ective of no de 2 . Messages flow in b oth directions along the edges of the graph G , first in the reverse direction (in dotted) then in the forw ard direction (in solid). EM viewp oin t. The up date (6) can also b e explained from an expectation-maximization (EM) viewp oin t, by introducing suitable latent v ariables [Caron and Doucet, 2012]. This viewp oin t enables a Gibbs sampler that can b e used for Ba yesian inference. W e presen t the EM deriv ation in A pp endix C, but lea ve a study of fully Bay esian inference in the net work choice mo del for future work. 6 Exp erimen tal Ev aluation In this section, we inv estigate a ) the ability of the netw ork choice mo del to accurately reco ver transitions in real-w orld scenarios, and b ) the p otential of ChoiceRank to scale to v ery large netw orks. 6.1 A ccuracy on Real-W orld Data W e ev aluate the netw ork c h oice mo del on three datasets that are representativ e of t wo distinct application domains. Eac h dataset can b e represented as a set of transition coun ts { c ij } on a directed graph G = ( V , E ) . W e aggregate the transition coun ts into marginal traffic data { ( c − i , c + i ) | i ∈ V } and fit a netw ork choice mo del by using ChoiceRank. W e set α = 2 . 0 and β = 1 . 0 (these small v alues simply guarantee the con vergence of the algorithm) and declare con vergence when k λ ( t ) − λ ( t − 1) k 1 /n < 10 − 8 . Giv en λ , w e estimate transition probabilities using p ij ∝ λ j as given b y (1) . T o the b est of our knowledge, there is no other published metho d tac kling the problem of estimating transition probabilities from marginal traffic data. Therefore, w e compare our metho d to three baselines based on simple heuristics. T raffic T ransitions probabilities are prop ortional to the traffic of the target no de: q T ij ∝ c − j . P ageRank T ransition probabilities are prop ortional to the PageRank score of the target no de: q P ij ∝ PR j . 10 Uniform Any transition is equiprobable: q U ij ∝ 1 . The four estimates are compared against ground-truth transition probabilities derived from the edge traffic data: p ? ij ∝ c ij . W e emphasize that although p er-edge transition coun ts { c ij } are needed to evaluate the accuracy of the netw ork choice mo del (and the baselines), these counts are not necessary for le arning the mo del—p er-no de marginal coun ts are sufficient. Giv en a no de i , w e measure the accuracy of a distribution q i o ver outgoing transitions using t wo error metrics, the KL-divergence and the (normalized) rank displacement: D KL ( p ? i , q i ) = X j ∈ N + i p ? ij log p ? ij q ij , D FR ( p ? i , q i ) = 1 | N + i | 2 X j ∈ N + i | σ ? i ( j ) − ˆ σ i ( j ) | , where σ ? i (resp ectiv ely ˆ σ i ) is the ranking of elements in N + i b y decreasing order of p ? ij (resp ectiv ely q ij ). W e rep ort the distribution of errors “ov er c hoices”, i.e., the error at each no de i is w eighted by the num b er of outgoing transitions c + i . 6.1.1 Clic kstream Data Wikip edia The Wikimedia F oundation has a long history of publicly sharing aggregate, page-lev el web traffic data 1 . Recen tly , it also released clic kstream data from the English v ersion of Wikip edia [W ulczyn and T arab orelli, 2016], providing us with essen tial ground- truth transition-lev el data. W e consider a dataset that contains information, extracted from the server logs, ab out the traffic each page of the English Wikip edia received during the mon th of March 2016. Each page’s incoming traffic is group ed by HTTP referrer, i.e., b y the page visited prior to the request. W e ignore the traffic generated by external W eb sites such as searc h engines and keep only the in ternal traffic ( 18 % of the total traffic in the dataset). In summary , we obtain coun ts of transitions on the h yp erlink graph of English Wikip edia articles. The graph contains n = 2 316 032 no des and m = 13 181 698 edges, and we consider slightly ov er 1 . 2 billion transitions ov er the edges. On this dataset, ChoiceRank con verges after 795 iterations. K osarak W e also consider a second clic kstream dataset from a Hungarian online news p ortal 2 . The data consists of 7 029 013 transitions on a graph con taining n = 41001 no des and m = 974 560 edges. ChoiceRank conv erges after 625 iterations. The four leftmost plots of Figure 4 show the error distributions. ChoiceRank signifi- can tly improv es on the baselines, b oth in terms of KL-divergence and rank displacement. These results giv e comp elling evidence that transitions do not o ccur prop ortionally with the target’s page traffic: in terms of KL-div ergence, ChoiceRank improv es on T raffic b y a factor 3 × and 2 × , resp ectively . P ageRank scores, while reflecting some notion of imp ortance of a page, are not designed to estimate transitions, and understandably the corresp onding baseline p erforms p o orly . Uniform (p erhaps the simplest of our baselines) 1 See: https://stats.wikimedia.org/ . 2 The data is publicly av ailable at http://fimi.ua.ac.be/data/ . 11 C-Rank Tra ffic P-Rank Uniform 0 . 0 0 . 5 1 . 0 1 . 5 2 . 0 2 . 5 KL-di vergence W ikiped ia C-Rank Tra ffic P-Rank Uniform 0 . 0 0 . 5 1 . 0 1 . 5 2 . 0 2 . 5 3 . 0 3 . 5 4 . 0 K osar a k C-Rank Tra ffic P-Rank Uniform 0 . 00 0 . 05 0 . 10 0 . 15 0 . 20 0 . 25 0 . 30 0 . 35 Citi Bike C-Rank Tra ffic P-Rank Uniform 0 . 10 0 . 15 0 . 20 0 . 25 0 . 30 0 . 35 0 . 40 0 . 45 Displace m ent C-Rank Tra ffic P-Rank Uniform 0 . 10 0 . 15 0 . 20 0 . 25 0 . 30 0 . 35 0 . 40 C-Rank Tra ffic P-Rank Uniform 0 . 20 0 . 25 0 . 30 0 . 35 0 . 40 0 . 45 Figure 4: Error distributions of the netw ork choice model and three baselines for the Wikip edia (WP) and Citi Bike (CB) datasets. The b o xes sho w the in terquartile range, the whisk ers show the 5 th and 95 th p ercen tiles, the red horizontal bars sho w the median and the red squares sho w the mean. is (b y design) unable to distinguish among transitions, resulting in a large displacemen t error. W e b elieve that its comparativ ely b etter p erformance in terms of KL-divergence (for Wikip edia) is mostly an artifact of the metric, whic h encourages “pruden t” estimates. Finally , in Figure 5 we observe that ChoiceRank seems to p erform comparatively b etter as the n umber of p ossible transition increases. 6.1.2 NYC Bicycle-Sharing Data Next, w e consider trip data from Citi Bike, New Y ork Cit y’s bicycle-sharing system 3 . F or eac h ride on the system made during the y ear 2015, we extract the pick-up and drop-off stations and the duration of the ride. Because we w an t to fo cus on direct trips, we exclude rides that last more than one hour. W e also exclude source-destinations pairs whic h hav e less than 1 ride p er da y on av erage (a ma jority of source-destination pairs app ears at least once in the dataset). The resulting data consists of 3 . 4 million rides on a graph con taining n = 497 no des and m = 5209 edges. ChoiceRank conv erges after 7508 iterations. W e compute the error distribution in the same w ay as for the clickstream datasets. The tw o righ tmost plots of Figure 4 display the results. The observ ations made on the clic kstream datasets carry o ver to this mobilit y dataset, alb eit to a lesser degree. A significan t difference b et w een clicking a link and taking a bicycle trip is that in the latter case, there is a non-uniform “cost” of a transition due to the distance b et ween source and target. In future work, one might consider incorp orating edge weigh ts and using the w eighted netw ork c hoice mo del presented in App endix A. 3 The data is av ailable at https://www.citibikenyc.com/system- data . 12 0 20 40 60 80 100 Node out-de gree 0 . 0 0 . 5 1 . 0 1 . 5 2 . 0 A verage KL-di ver gence ChoiceRank Tr a ffi c PageRank Uniform Figure 5: A verage KL-div ergence as a function of the num b er of p ossible transitions for the Wikip edia dataset. ChoiceRank p erforms comparatively b etter in the case where a no de’s out-degree is large. 6.2 Scaling ChoiceRank to Billions of No des T o demonstrate ChoiceRank’s scalability , we dev elop a simple implementation in the Rust programming language, based on the ideas of COST [McSherry et al., 2015]. Our co de is publicly av ailable online 4 . The implementation rep eatedly streams edges from disk and k eeps four floating-p oint v alues p er no de in memory: the coun ts c − i and c + i , the sum of messages z i , and either γ i or λ i (dep ending on the stage in the iteration). As edges can b e pro cessed in any order, it can b e b eneficial to reorder the edges in a wa y that accelerates the computation. F or this reason, our implementation prepro cesses the list of edges and reorders them in Hilb ert curv e order 5 . This results in b etter cac he lo cality and yields a significan t sp eedup. W e test our implementation on a h yp erlink graph extracted from the 2012 Common Cra wl web corpus 6 that contains o v er 3 . 5 billion no des and 128 billion edges [Meusel et al., 2014]. The edge list alone requires ab out 1 TB of uncompressed storage. There is no publicly av ailable information on the traffic at eac h page, therefore w e generate a v alue c i for every no de i randomly and uniformly b etw een 100 and 500 , and set b oth c − i and c + i to c i . As such, this exp erimen t do es not attempt to measure the v alidit y of the mo del (unlike the exp eriments of Section 6.1). Instead, it fo cuses on testing the algorithm’s p oten tial to scale to to v ery large netw orks. Results. W e run 20 iterations of ChoiceRank on a dual In tel Xeon E5-2680 v3 mac hine, with 256 GB of RAM and 6 HDDs configured in RAID 0. W e arbitrarily set α = 2 . 0 and β = 1 . 0 (but this choice has no impact on the results). Only ab out 65 GB of memory is used, all to store the no des’ state ( 4 × 4 b ytes p er no de). The algorithm takes a little less than 39 min utes p er iteration on a verage. Collectiv ely , these results v alidate the feasibility 4 See: http://lucas.maystre.ch/choicerank . 5 A Hilb ert space-filling curve visits all the entries of the adjacency matrix of the graph, in a wa y that preserv es lo cality of b oth source and destination of the edges. 6 The data is av ailable at http://webdatacommons.org/hyperlinkgraph/ . 13 of mo del inference for v ery large datasets. It is w orth noting that despite tac kling differen t problems, the ChoiceRank algorithm exhibits interesting similarities with a message-passing implementation of PageRank commonly used in scalable graph-parallel systems such as Pregel [Malewicz et al., 2010] and Spark [Gonzalez et al., 2014]. F or comparison, using the COST co de [McSherry et al., 2015] w e run 20 iterations of P ageRank on the same hardware and data. PageRank uses sligh tly less memory (ab out 50 GB, or one less floating-p oint n umber p er no de) and takes ab out half of the time p er iteration (a little ov er 20 min utes). This is consisten t with the fact that ChoiceRank requires t wo passes o ver the edges p er iteration, whereas PageRank requires one. The similarities b etw een the tw o algorithms lead us to b elieve that in general, ChoiceRank can b enefit from an y new system optimizations developed for PageRank. 7 Conclusion In this pap er, w e present a method that tac kles the problem of finding the transition probabilities along the edges of a net work, given only the net work’s structure and aggregate no de-lev el traffic data. This metho d generalizes and extends ideas recently presented by Kumar et al. [2015]. W e demonstrate that in spite of the strong mo del assumptions needed to learn O ( n 2 ) probabilities from O ( n ) observ ations, the metho d still manages to reco v er the transition probabilities to a go o d level of accuracy on t wo clickstream datasets, and sho ws promise for applications b ey ond clickstream data. T o sum up, we b elieve that our metho d will b e useful to pracitioners interested in understanding patterns of na vigation in net works from aggregate traffic data, commonly av ailable, e.g., in public datasets. A ckno wledgmen ts. W e thank Holly Cogliati-Bauereis, Ksenia Kon yushk ov a, Brunella Spinelli and anon ymous reviewers for careful pro ofreading and helpful comments. A Extensions and Pro ofs In this section, we start by generalizing the net work choice mo del to account for edge w eights. Then, w e present formal pro ofs for a ) the (minimal) sufficiency of marginal coun ts and b ) the well-posedness of MAP inference in the generalized w eighted netw ork choice mo del. A.1 Generalization of the Mo del Let G = ( V , E ) b e a weigh ted, directed graph with edge w eights w ij > 0 for all ( i, j ) ∈ E . Kumar et al. [2015] prop ose the following generalization of Luce’s choice mo del. Given a parameter v ector λ ∈ R n > 0 , they define the c hoice probabilities as p ij = w ij λ j P k ∈ N + i w ik λ k , j ∈ N + i . (7) W e refer to this mo del as the weighte d network choic e mo del . Intuitiv ely , the strength of eac h alternative is w eigh ted by the corresp onding edge’s weigh t; Luce’s original choice 14 mo del is obtained by setting w ij = constan t . In this general mo del, the log-lik eliho o d b ecomes ( λ ; D ) = X ( i,j ) ∈ E c ij log w ij λ j − log X k ∈ N + i w ik λ k = X ( i,j ) ∈ E c ij log λ j − log X k ∈ N + i w ik λ k + X ( i,j ) ∈ E c ij log w ij , = n X i =1 c − i log λ i − c + i log X k ∈ N + i w ik λ k + κ 1 , (8) where c − i = P j ∈ N − i c j i and c + i = P j ∈ N + i c ij is the aggregate n umber of transitions arriving in and originating from i , resp ectiv ely . Note that for every i , the weigh ts { w ij | j ∈ N + i } are equiv alen t up to rescaling. This generalization is relev ant in situations where the current context mo dulates the alternativ es’ strength. F or example, this could b e used to take in to accoun t the p osition or prominence of a link on a page in a hyperlink graph, or the distance b etw een tw o lo cations in a mobilit y netw ork. A.2 Minimal Sufficiency of Marginal Coun ts Recall that c ij denotes the num b er of times we observ e a transition from i to j . W e set out to pro ve the following theorem for the weigh ted net work choice mo del. Theorem 4. L et c − i = P j ∈ N − i c j i and c + i = P j ∈ N + i c ij b e the aggr e gate numb er of tr ansitions arriving in and originating fr om i , r esp e ctively. Then, { ( c − i , c + i ) | i ∈ V } is a minimal ly sufficient statistic for the p ar ameter λ in the weighte d network choic e mo del. Pr o of. Let f ( { c ij } | λ ) b e the discrete probability density function of the data under the mo del with parameters λ . Theorem 6 . 2 . 13 in Casella and Berger [2002] states that { ( c − i , c + i ) } is a minimally sufficient statistic for λ if and only if, for any { c ij } and { d ij } in the supp ort of f , f ( { c ij } | λ ) f ( { d ij } | λ ) is indep enden t of λ ⇐ ⇒ ( c − i , c + i ) = ( d − i , d + i ) ∀ i. (9) T aking the log of the ratio on the left-hand side and using (8), w e find that log f ( { c ij } | λ ) f ( { d ij } | λ ) = n X i =1 ( c − i − d − i ) log λ i − ( c + i − d + i ) log X k ∈ N + i w ik λ k + κ 2 . F rom this, it is easy to see that the ratio of densities is indep endent of λ if and only if c − i = d − i and c + i = d + i , whic h verifies (9). 15 A.3 W ell-P osedness of MAP Inference Using a Gamma ( α, β ) prior for each parameter, the log-p osterior of the w eigh ted netw ork c hoice mo del can b e written as log p ( λ | D ) = n X i =1 ( c − i + α − 1) log λ i − c + i log X k ∈ N + i w ik λ k − β λ i + κ 3 . (10) W e prov e a theorem that guarantees that MAP estimation is well-posed in this generalized mo del; the pro of of Theorem 2 follo ws trivially . Theorem 5. If i.i.d. λ 1 , . . . , λ n ∼ Gamma ( α, β ) with α > 1 , then ther e exists a unique maximizer λ ? ∈ R n > 0 of the weighte d network choic e mo del’s lo g-p osterior (10) . Pr o of. The log-p osterior (10) is not conca ve in λ , but it can b e made conca ve using the simple reparametrization λ i = e θ i . Under this reparametrization, the log-prior and the log-lik eliho o d b ecome log p ( θ ) = n X i =1 ( α − 1) θ i − β e θ i + κ 4 , ( θ ; D ) = n X i =1 c − i θ i − c + i log X k ∈ N + i w ik e θ k + κ 5 . It is easy to see that the log-lik eliho o d is concav e and the log-prior strictly conca ve in θ . As a result, the log-p osterior is strictly conca ve in θ , whic h ensures that there exists at most one maximizer. No w consider any transition counts { c ij } that satisfy c − i = P j ∈ N − i c j i and c + i = P j ∈ N + i c ij . The log-p osterior can b e written as log p ( θ | D ) = n X i =1 X j ∈ N + i c ij θ j − log X k ∈ N + i w ik e θ k + n X i =1 ( α − 1) θ i − β e θ i + κ 3 ≤ − n 2 · max i,j log w ij + n X i ( α − 1) θ i − β e θ i + κ 3 . F or α > 1 , it follo ws that lim k θ k→∞ log p ( θ | D ) = −∞ , which ensures that there is at least one maximizer. Note that Theorem 5 can easily b e extended to indep enden t but non-identical Gamma priors, where λ i ∼ Gamma ( α i , β i ) and α i 6 = α j , β i 6 = β j in general. B Maxim um-Lik eliho o d Estimation In this section, we go in to the analysis of the ML estimator in depth. F rom the definition of c hoice probabilities in (7) , it is clear that the likelihoo d is in v arian t to a rescaling of the parameters, i.e., ( λ ; D ) = ( s λ ; D ) for an y s > 0 . W e will therefore identify parameters up to rescaling. 16 B.1 Necessary and Sufficien t Conditions In order to pro vide a data-dep endent, necessary and sufficient condition that guarantees that the ML estimate is well-defined, we extend the definition of comparison hypergraph presen ted in Section 4.3. Definition (Comparison graph) . Let G = ( V , E ) b e a directed graph and { a ij | ( i, j ) ∈ E } b e non-negativ e num b ers. The c omp arison gr aph induced by { a ij } is the directed graph H = ( V , E 0 ) , where ( i, j ) ∈ E 0 if and only if there is a no de k suc h that i, j ∈ N + k and a kj > 0 . The num b ers { a ij } can b e lo osely in terpreted as transition counts (although they do not need to b e integer). Intuitiv ely , there is an edge ( i, j ) in the comparison graph whenev er there is at least one instance in whic h i and j w ere among the alternatives and j w as selected. If a ij > 0 for all edges, then the comparison graph is equiv alen t to its h yp ergraph counterpart, in that every h yp eredge induces a clique in the comparison graph. As sho wn by the next theorem, the notion of (data-dep endent) comparison graph leads to a precise c haracterization of whether the ML estimate is well-defined or not. Theorem 6. L et G = ( V , E ) b e a dir e cte d gr aph and { ( c − i , c + i ) } b e the aggr e gate numb er of tr ansitions arriving in and originating fr om i , r esp e ctively. L et { a ij } b e any set of non-ne gative r e al numb ers that satisfy X j ∈ N − i a j i = c − i , X j ∈ N + i a ij = c + i . Then, the maximizer of the lo g-likeliho o d (8) exists and is unique (up to r esc aling) if and only if the c omp arison gr aph induc e d by { a ij } is str ongly c onne cte d. The proof b orrows from Hun ter [2004], in particular from the proofs of Lemmas 1 and 2 . Pr o of. The log-lik eliho o d (8) is not concav e in λ , but it can b e made concav e using the reparametrization λ i = e θ i . W e can rewrite the reparametrized log-likelihoo d using { a ij } as ( θ ) = n X i =1 X j ∈ N + i a ij θ j − log X k ∈ N + i w ik e θ k , and, without loss of generalit y , we can assume that P i θ i = 0 and min ij w ij = 1 . First, w e shall pro ve that the sup er-level set { θ | ( θ ) ≥ c } is b ounded and compact for an y c , if and only if the comparison graph is strongly connected. The compactness of all sup er-lev el sets ensures that there is at least one maximizer. Pick any unit vector u suc h that P i u i = 0 , and let θ = s u When s → ∞ , then e θ i > 0 and e θ j → 0 for some i and j . As the comparison graph is strongly connected, there is a path from i to j , and along this path there must b e tw o consecutive no des i 0 , j 0 suc h that e θ i 0 > 0 and e θ j 0 → 0 . The existence of the edge ( i 0 , j 0 ) in the comparison graph means that there is a k suc h that i 0 , j 0 ∈ N + k and a kj 0 > 0 . Therefore, the log-lik eliho o d can b e b ounded as ( θ ) ≤ a kj 0 θ j 0 − log X q ∈ N + k w kq e θ q ≤ a kj 0 θ j 0 − log ( e θ j 0 + e θ i 0 ) , 17 and lim s →∞ ( θ ) = −∞ . Conv ersely , supp ose that the comparison graph is not strongly connected and partition the v ertices in to t wo non-empt y subsets S and T suc h that there is no edge from S to T . Let c > 0 b e an y p ositive constant, and tak e ˜ θ i = θ i + c if i ∈ S and ˜ θ i = θ i if i ∈ T (renormalize such that P i ˜ θ i = 0 ). Clearly , ( ˜ θ ) ≥ ( θ ) , and b y rep eating this pro cedure k θ k ma y b e driv en to infinity without decreasing the likelihoo d. Second, we shall prov e that if the comparison graph is strongly connected, the log- lik eliho o d is strictly conca ve (in θ ). In particular, for an y p ∈ (0 , 1) , [ p θ + (1 − p ) η ] ≥ p ( θ ) + (1 − p ) ( η ) , (11) with equality if and only if θ ≡ η up to a constant shift. Strict concavit y ensures that there is at most one maximizer of log-likelihoo d. W e start with Hölder’s inequalit y , which implies that, for p ositiv e { x k } and { y k } , and p ∈ (0 , 1) , log X k x p k y 1 − p k ≤ p log X k x k + (1 − p ) log X k y k . with equalit y if and only x k = cy k for some c > 0 . Letting x k = w ik e θ k and y k = w ik e η k , w e find that for all i log X k ∈ N + i w ik e pθ k +(1 − p ) η k ≤ p log X k ∈ N + i w ik e θ k + (1 − p ) log X k ∈ N + i w ik e η k , (12) with equality if and only if there exists c ∈ R suc h that θ k = η k + c for all k ∈ N + i . Multiplying b y a ij and summing ov er i and j on b oth sides of (12) sho ws that the log- lik eliho o d is concav e in θ . No w, consider any partition of the vertices into tw o non-empty subsets S and T . Because the comparison graph i s strongly connected, there is alwa ys k ∈ V , i ∈ S and j ∈ T suc h that i, j ∈ N + k and a ki > 0 . Therefore, the left and right side of (11) are equal if and only if θ ≡ η up to a constan t shift. Bounded sup er-level sets and strict conca vit y form necessary and sufficient conditions for the existence and uniqueness of the maximizer. W e now give a pro of for Theorem 1, presented in the main b o dy of text. Pr o of of The or em 1. If the comparison h yp ergraph is disconnected, then for any data D , the (data-induced) comparison graph is disconnected to o. F urthermore, the connected comp onen ts of the comparison graph are subsets of those of the hypergraph. Partition the v ertices into tw o non-empt y subsets S and T suc h that there is no hyperedge b etw een S to T in the comparison hypergraph. Let A = { i | N + i ⊂ S } and B = { i | N + i ⊂ T } . By construction of the comparison hypergraph, A ∩ B = ∅ and A ∪ B = V . The log-likelihoo d can b e therefore b e rewritten as ( θ ) = X i ∈ A X j ∈ N + i a ij log λ j − log X k ∈ N + i w ik λ k + X i ∈ B X j ∈ N + i a ij log λ j − log X k ∈ N + i w ik λ k . The sum ov er A in volv es only parameters related to no des in S , while the sum ov er B in volv es only parameters related to no des in T . Because the lik eliho o d is inv ariant to a rescaling of the parameters, it is easy to see that we can arbitrarily rescale the parameters of the v ertices in either S or T without affecting the lik eliho o d. 18 1 2 3 4 c − 2 =2 c + 4 =1 c − 4 =1 c + 2 =1 c − 1 =1 c + 1 =1 c − 3 =1 ,c + 3 =2 (a) net work structure 1 2 3 4 (b) comparison h yp ergraph 1 2 4 3 (c) comparison graph Figure 6: An inno cent-looking example where the ML estimate do es not exist. The netw ork structure, aggregate traffic data and compatible transitions are shown on the left. While the comparison h yp ergraph is connected, the (data-dep endent) comparison graph is not strongly connected. V erifying the condition of Theorem 6. In order to verify the necessary and sufficien t condition giv en { ( c − i , c + i ) } , one has to find a non-negative solution { a ij } to the system of equations X j ∈ N − i a j i = c − i , X j ∈ N + i a ij = c + i . Dines [1926] presen ts a remark ably simple algorithm to find such a non-negative solution. Alternativ ely , Kumar et al. [2015] suggest recasting the problem as one of maximum flow in a net work. How ev er, the computational cost of running Dines’ or max-flow algorithms is significan tly greater than that of running ChoiceRank. B.2 Example T o conclude our discussion, w e pro vide an inno cuous-lo oking example that highlights the difficult y of dealing with the ML estimate. Consider the netw ork structure and traffic data depicted in Figure 6. The netw ork is strongly connected, and its comparison h yp ergraph is connected as well; as such, the netw ork satisfies the necessary condition stated in Theorem 1 in the main text. Nevertheless, the condition is not sufficient for the ML-estimate to b e w ell-defined. In this example, the (data-dep enden t) comparison graph is not strongly connected, and it is easy to see that the likelihoo d can alw ays b e increased b y increasing λ 1 , λ 2 and λ 4 . Hence, the ML estimate do es not exist. In this simple example, we indicate the edge transitions that generated the observed marginal traffic in b old. Giv en this information, the comparison graph is easy to find, and the necessary and sufficient conditions of Theorem 6 are easy to c heck. But in general, finding a set of transitions that is compatible with given marginal p er-no de traffic data is computationally exp ensiv e (see discussion ab o ve). 19 C ChoiceRank Algorithm In this section, we start by generalizing the ChoiceRank algorithm to the weigh ted net work c hoice mo del. W e then prov e the conv ergence of this generalized algorithm. Finally , we sho w ho w the same algorithm can b e obtained from an EM viewp oin t b y in tro ducing suitable laten t v ariables. C.1 Algorithm for the Generalized Mo del Using the same linear upp er-b ound on the logarithm as in Section 5 of the main text, we can lo wer-bound the log-p osterior (10) in the weigh ted mo del by f ( t ) ( λ ) = κ 2 + n X i =1 ( c − i + α − 1) log λ i − β λ i − c + i log X k ∈ N + i w ik λ ( t ) k + P k ∈ N + i w ik λ k P k ∈ N + i w ik λ ( t ) k − 1 , (13) with equality if and only if λ = λ ( t ) . Starting with an arbitrary λ (0) ∈ R n > 0 , we rep eatedly maximize the low er-b ound f ( t ) . This surrogate optimization problem has a closed form solution, obtained b y setting ∇ f ( t ) to 0 : λ ( t +1) i = c − i + α − 1 P j ∈ N − i w j i γ ( t ) j + β , where γ ( t ) j = c + j P k ∈ N + j w j k λ ( t ) k . (14) The iterates prov ably conv erge to the maximizer of (10) , as shown by the following theorem. Theorem 7. L et λ ? b e the unique maximum a-p osteriori estimate. Then for any initial λ (0) ∈ R n > 0 the se quenc e of iter ates define d by (14) c onver ges to λ ? . The pro of follo ws that of Hunter’s Theorem 1 [2004]. Pr o of. Let M : R n > 0 → R n > 0 b e the (contin uous) map implicitly defined by one iteration of the algorithm. F or conciseness, let g ( λ ) . = log p ( λ | D ) . As g has a unique maximizer and is conca ve using the reparametrization λ i = e θ i , it follo ws that g has a single stationary p oint. First, observ e that the minorization-maximization prop erty guarantees that g [ M ( λ )] ≥ g ( λ ) . Com bined with the strict concavit y of g , this ensures that lim t →∞ g ( λ ( t ) ) exists and is unique for any λ (0) . Second, g [ M ( λ )] = g ( λ ) if and only if λ is a stationary p oint of g , b ecause the minorizing function is tangent to g at the current iterate. It follo ws that lim t →∞ λ ( t ) = λ ? . Theorem 3 of the main text follows directly by setting w ij ≡ 1 . F or completeness, the edge-streaming implementation adapted to the weigh ted mo del is given in Algorithm 2. The only c hanges with resp ect to Algorithm 1 (presented in the main text) are in lines 4 and 7: Ev ery message γ i or λ j flo wing through an edge ( i, j ) is m ultiplied b y the edge w eight w ij . 20 Algorithm 2 ChoiceRank for the weigh ted mo del Require: graph G = ( V , E ) , counts { ( c − i , c + i ) } 1: λ ← [1 , . . . , 1] 2: rep eat 3: z ← 0 n Recompute γ 4: for ( i, j ) ∈ E do z i ← z i + w ij λ j 5: for i ∈ V do γ i ← c + i /z i 6: z ← 0 n Recompute λ 7: for ( i, j ) ∈ E do z j ← z j + w ij γ i 8: for i ∈ V do λ i ← ( c − i + α − 1) / ( z i + β ) 9: until λ has conv erged C.2 EM Viewp oin t The MM algorithm can b e seen from an EM viewp oint, following the ideas of Caron and Doucet [2012]. W e in tro duce n indep enden t random v ariables Z = { Z i | i = 1 , . . . , n } , where Z i ∼ Gamma c + i , X j ∈ N + i w ij λ j . With the addition of these laten t random v ariables the complete log-lik eliho o d b ecomes ( λ ; D , Z ) = ( λ , D ) + n X i =1 log p ( z i | D , λ ) = n X i =1 c − i log λ i − c + i log X k ∈ N + i w ik λ k + n X i =1 c + i log X k ∈ N + i w ik λ k − z i X k ∈ N + i w ik λ k + κ 6 = n X i =1 c − i log λ i − z i X k ∈ N + i w ik λ k + κ 6 . Using a Gamma ( α, β ) prior for eac h parameter, the exp ected v alue of the log-p osterior with resp ect to the conditional Z | D under the estimate λ ( t ) is Q ( λ , λ ( t ) ) = E Z |D , λ ( t ) [ ( λ ; D , Z )] + log p ( λ ) = n X i =1 c − i log λ i − c + i P k ∈ N + i w ik λ k P k ∈ N + i w ik λ ( t ) k + n X i =1 ( α − 1) log λ i − β λ i + κ 7 The EM algorithm starts with an initial λ (0) and iteratively refines the estimate by solving the optimization problem λ ( t +1) = arg max λ Q ( λ , λ ( t ) ) . It is not difficult to see that for a given λ ( t ) , maximizing Q ( λ , λ ( t ) ) is equiv alen t to maximizing the minorizing function 21 f ( t ) ( λ ) defined in (13) . Hence, the MM and the EM viewpoint lead to the exact same sequence of iterates. The EM formulation leads to a Gibbs sampler in a relatively straigh tforward w ay [Caron and Doucet, 2012]. W e leav e a systematic treatmen t of Bay esian inference in the net work choice mo del for future work. References H. Azari Soufiani, W. Z. Chen, D. C. Park es, and L. Xia. Generalized Metho d-of-Moments for Rank Aggregation. In NIPS 2013 , Lak e T aho e, CA, 2013. R. A. Bradley and M. E. T erry . Rank Analysis of Incomplete Blo ck Designs: I. The Metho d of P aired Comparisons. Biometrika , 39(3/4):324–345, 1952. S. Brin and L. Page. The Anatom y of a Large-Scale Hyp ertextual W eb Search Engine. In WWW’98 , Brisbane, Australia, 1998. F. Caron and A. Doucet. Efficien t Ba yesian Inference for Generalized Bradley–T erry mo dels. Journal of Computational and Gr aphic al Statistics , 21(1):174–196, 2012. G. Casella and R. L. Berger. Statistic al Infer enc e . Duxbury Press, second edition, 2002. L. L. Dines. On Positiv e Solutions of a System of Linear Equations. A nnals of Mathematics , 28(1/4):386–392, 1926. A. Elo. The R ating Of Chess Players, Past & Pr esent . Arco, 1978. J. E. Gonzalez, R. S. Xin, A. Da v e, D. Crankshaw, M. J. F ranklin, and I. Stoica. Graphx: Graph Pro cessing in a Distributed Dataflow F ramew ork. In OSDI’14 , pages 599–613, 2014. B. Ha jek, S. Oh, and J. Xu. Minimax-optimal Inference from P artial Rankings. In NIPS 2014 , Mon treal, QC, Canada, 2014. T. Hastie and R. Tibshirani. Classification by pairwise coupling. The Annals of Statistics , 26(2):451–471, 1998. D. R. Hun ter. MM algorithms for generalized Bradley–T erry mo dels. The A nnals of Statistics , 32(1):384–406, 2004. J. G. Kemen y and J. L. Snell. Finite Markov Chains . Springer-V erlag, 1976. R. Kumar, A. T omkins, S. V assilvitskii, and E. V ee. Inv erting a Steady-State. In WSDM’15 , pages 359–368. A CM, 2015. K. Lange, D. R. Hunter, and I. Y ang. Optimization T ransfer Using Surrogate Ob jective F unctions. Journal of Computational and Gr aphic al Statistics , 9(1):1–20, 2000. Y. Liu, B. Gao, T.-Y. Liu, Y. Zhang, Z. Ma, S. He, and H. Li. Bro wseRank: Letting W eb Users V ote F or Page Imp ortance. In SIGIR’08 , pages 451–458. ACM, 2008. 22 R. D. Luce. Individual Choic e b ehavior: A The or etic al A nalysis . Wiley , 1959. G. Malewicz, M. H. Austern, A. J. C. Bik, J. C. Dehnert, I. Horn, N. Leiser, and G. Cza jk o wski. Pregel: A System for Large-Scale Graph Pro cessing. In SIGMOD’10 , pages 135–145. A CM, 2010. L. Ma ystre and M. Grossglauser. F ast and Accurate Inference of Plac k ett–Luce Mo dels. In NIPS 2015 , Mon treal, Canada, 2015. D. McF adden. Conditional logit analysis of qualitativ e choice b eha vior. In P . Zarembk a, editor, F r ontiers in Ec onometrics , pages 105–142. Academic Press, 1973. F. McSherry , M. Isard, and D. G. Murray . Scalability! But at what COST? In HotOS XV , 2015. R. Meusel, S. Vigna, O. Lehm b erg, and C. Bizer. Graph Structure in the W eb—Revisited: A T rick of the Heavy T ail. In WWW’14 Comp anion , pages 427–432, 2014. S. Negah ban, S. Oh, and D. Shah. Iterative Ranking from Pair-wise Comparisons. In NIPS 2012 , Lak e T aho e, CA, 2012. J. A. T omlin. A New P aradigm for Ranking Pages on the W orld Wide W eb. In WWW’03 , pages 350–355. A CM, 2003. K. E. T rain. Discr ete Choic e Metho ds with Simulation . Cambridge Univ ersity Press, second edition, 2009. M. V o jnovic and S.-Y. Y un. Parameter Estimation for Generalized Thurstone Choice Mo dels. In ICML 2016 , pages 498–506, 2016. E. W ulczyn and D. T arab orelli. Wikip edia Clickstream. Apr. 2016. URL https://dx. doi.org/10.6084/m9.figshare.1305770.v16 . E. Zermelo. Die Berechn ung der T urnier-Ergebnisse als ein Maximumproblem der W ahrscheinlic hkeitsrec hn ung. Mathematische Zeitschrift , 29(1):436–460, 1928. 23
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment