A Supervised Approach to Extractive Summarisation of Scientific Papers
Automatic summarisation is a popular approach to reduce a document to its main arguments. Recent research in the area has focused on neural approaches to summarisation, which can be very data-hungry. However, few large datasets exist and none for the traditionally popular domain of scientific publications, which opens up challenging research avenues centered on encoding large, complex documents. In this paper, we introduce a new dataset for summarisation of computer science publications by exploiting a large resource of author provided summaries and show straightforward ways of extending it further. We develop models on the dataset making use of both neural sentence encoding and traditionally used summarisation features and show that models which encode sentences as well as their local and global context perform best, significantly outperforming well-established baseline methods.
💡 Research Summary
The paper tackles the problem of extractive summarisation for scientific publications, a domain that has historically suffered from a lack of large‑scale training data. By exploiting the “highlights” that many journals require authors to provide on ScienceDirect, the authors construct a new dataset comprising 10,148 computer‑science papers. Each paper comes with a title, abstract, author‑written highlight statements, and author‑defined keywords. The highlights are treated as gold‑standard summary sentences because they are concise, self‑contained statements of the paper’s main contributions, a practice validated in prior news‑summarisation work (Nallapati et al., 2016a).
Two datasets are released: CSPubSum and CSPubSumExt. CSPubSum contains the original highlights as positive examples and an equal number of negative examples sampled from the bottom 10 % of sentences (according to ROUGE‑L similarity to the highlights). This yields about 85 k training instances. To overcome the limited size and the fact that CSPubSum only labels the highlights themselves, the authors introduce HighlightROUGE, an oracle‑style automatic labelling method. For each paper, HighlightROUGE selects the 20 sentences in the main body that achieve the highest ROUGE‑L score against the highlights; these become additional positive instances, while an equal number of low‑scoring sentences become negatives. This process expands the training set to roughly 263 k instances in CSPubSumExt. A test split of 150 full papers (CSPubSum Test) is used for end‑to‑end summarisation evaluation, while CSPubSumExt Test (≈132 k sentence‑level instances) measures classification accuracy.
The authors propose two novel metrics/features. AbstractROUGE computes the ROUGE‑L similarity between any sentence and the paper’s abstract, based on the intuition that sentences that well‑summarise the abstract are also likely to be good summary candidates. HighlightROUGE, as described, serves both as a data‑augmentation technique and as a way to generate additional training signals. Both metrics are inexpensive to compute and exploit the inherent structure of scientific articles.
For modelling, each sentence is encoded in two ways: (1) a simple mean of pre‑trained 100‑dim Word2Vec embeddings, and (2) a bidirectional LSTM (128 hidden units per direction) that processes the sequence of word embeddings. In addition to these neural encodings, eight handcrafted features are supplied for every sentence: AbstractROUGE, Section Location (seven possible zones: Highlight, Abstract, Introduction, Methods, Results/Discussion, Conclusion, Other), Numeric Count (number of numerals), Title Score (overlap with paper title), Keyphrase Score (overlap with author‑provided keywords), TF‑IDF (average TF‑IDF of words in the sentence), Document TF‑IDF (TF‑IDF computed against the rest of the paper), and Sentence Length. These features aim to capture both local (sentence‑level) and global (document‑level) context without requiring complex feature engineering.
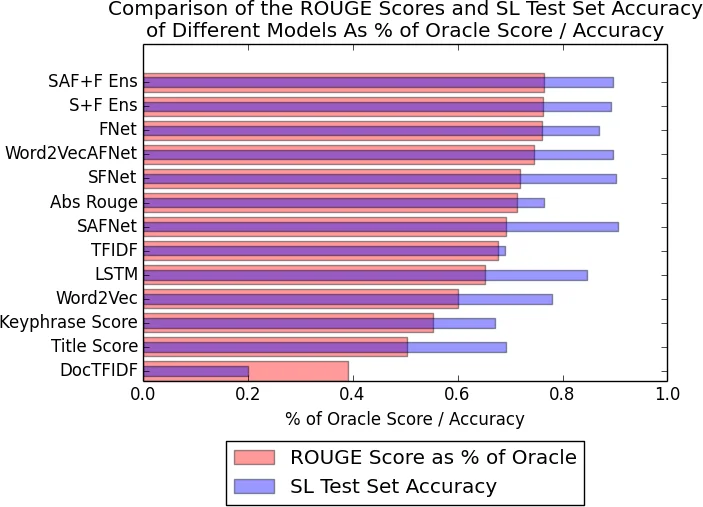
A suite of models is evaluated, ranging from simple feature‑only classifiers (FNet: a single‑layer feed‑forward network over the eight features) to hybrid architectures that concatenate neural sentence embeddings with the handcrafted features (e.g., Word2VecAF, S+F Net). Models ending in “Ens” denote ensembles of several base learners. All neural components use ReLU activations and are trained with Adam optimisation.
Experimental results, measured with ROUGE‑L on the CSPubSum Test set, show a clear hierarchy. Traditional extractive baselines (LexRank, TextRank, SumBasic) achieve scores around 0.28–0.31. Feature‑only models improve modestly to ≈0.33. Adding neural sentence embeddings raises performance to 0.36–0.38. The best system, an ensemble of S+F Net models trained on the expanded CSPubSumExt data, reaches 0.44 ROUGE‑L, outperforming the strongest baseline by roughly 10–15 percentage points. Ablation studies reveal that AbstractROUGE and Section Location are the most predictive features, confirming that sentences from certain sections (especially Results/Discussion and Conclusions) and those similar to the abstract are prime summary candidates.
The paper’s contributions are threefold: (1) a publicly released, scalable dataset for scientific‑paper extractive summarisation; (2) two lightweight, effective automatic labelling techniques (HighlightROUGE for data augmentation and AbstractROUGE as a feature); and (3) a set of baseline models that demonstrate how modest neural encodings combined with a small set of intuitive features can substantially surpass classic graph‑based summarisation methods. The authors suggest future work such as incorporating Transformer‑based encoders for longer contexts, extending the dataset to the remaining 26 domains available on ScienceDirect, and exploring multi‑task learning that jointly predicts highlights, abstracts, and keyphrases. Overall, the study provides both the resources and the methodological foundation needed to advance automatic understanding of scientific literature.
Comments & Academic Discussion
Loading comments...
Leave a Comment