ShiftCNN: Generalized Low-Precision Architecture for Inference of Convolutional Neural Networks
In this paper we introduce ShiftCNN, a generalized low-precision architecture for inference of multiplierless convolutional neural networks (CNNs). ShiftCNN is based on a power-of-two weight representation and, as a result, performs only shift and addition operations. Furthermore, ShiftCNN substantially reduces computational cost of convolutional layers by precomputing convolution terms. Such an optimization can be applied to any CNN architecture with a relatively small codebook of weights and allows to decrease the number of product operations by at least two orders of magnitude. The proposed architecture targets custom inference accelerators and can be realized on FPGAs or ASICs. Extensive evaluation on ImageNet shows that the state-of-the-art CNNs can be converted without retraining into ShiftCNN with less than 1% drop in accuracy when the proposed quantization algorithm is employed. RTL simulations, targeting modern FPGAs, show that power consumption of convolutional layers is reduced by a factor of 4 compared to conventional 8-bit fixed-point architectures.
💡 Research Summary
ShiftCNN is a novel inference architecture that eliminates multiplications from convolutional neural networks by representing weights as sums of powers‑of‑two. The authors propose a non‑uniform quantization scheme that maps each weight to a combination of N sub‑codebooks, each containing M = 2ᴮ‑1 power‑of‑two values (including zero). An N‑by‑B bit index encodes each weight, allowing the hardware to replace a multiply with a right‑shift and optional sign flip.
The key hardware innovation is the pre‑computation of all possible shifted input values. For every input activation, the Shift Arithmetic Unit (ShiftALU) generates the P = M + 2(N‑1) shifted versions (including sign‑flipped copies) and stores them in a dedicated buffer P. During convolution, the weight indices simply select the appropriate pre‑computed term, and the output is obtained by accumulating these terms with an array of adders. Consequently, the number of product operations drops from (C_out·H_f·W_f·C_in·H·W) in a conventional implementation to (P·C_in·H·W) shift‑only operations, a reduction of two orders of magnitude for typical CNNs where P ≪ C_out·H_f·W_f. The additional N‑fold increase in additions is negligible compared with the saved multiplications.
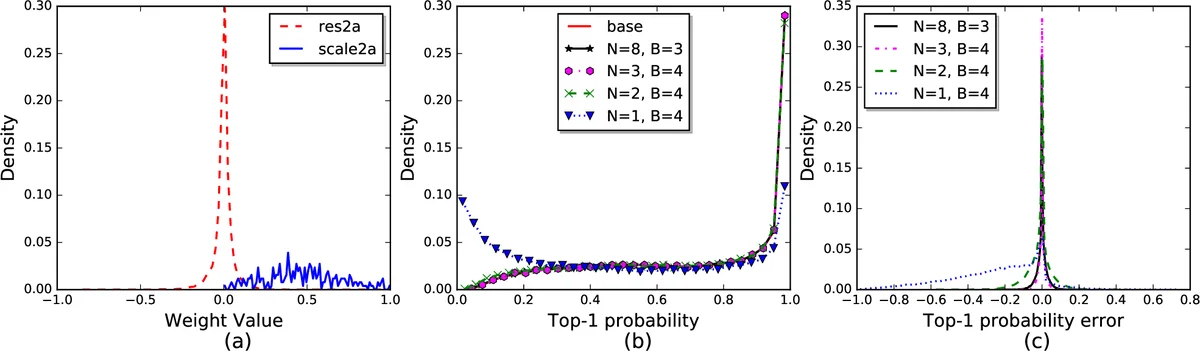
Algorithm 1 details the quantization process: weights are first normalized by the maximum absolute value, then the logarithm base‑2 of the absolute value is taken, rounded to the nearest codebook entry, and finally expressed as a sum of N power‑of‑two components. This approach generalizes binary (N=1, B=1) and ternary (N=1, B=2) quantization, while offering a richer representation for N>1 without requiring any retraining of the original model.
The hardware design consists of the ShiftALU (shifter + sign‑flip logic), a memory buffer for the pre‑computed terms, a multiplexer that selects the appropriate term based on the weight index, and an adder tree that aggregates the selected terms. Parallelism is extracted along the input‑channel dimension; the authors set the parallelization level ¯C = C, which allows the pre‑computed buffer to be organized as (P‑1) shift‑register arrays, each of length C. This organization provides sufficient bandwidth for high‑throughput inference while keeping the memory footprint modest.
Experimental evaluation on ImageNet uses four state‑of‑the‑art models: SqueezeNet v1.1, GoogleNet, ResNet‑18, and ResNet‑50. The authors provide a publicly available conversion script that implements the quantization algorithm without any fine‑tuning. With B=4 bits and N>2, the Top‑1 accuracy drop is less than 0.3 % (e.g., ResNet‑50: 72.87 % → 72.58 %). Even with the more aggressive setting N=2, the accuracy loss stays within 1 %, which the authors argue is an acceptable trade‑off for many embedded applications.
RTL simulations targeting modern FPGAs demonstrate that the ShiftCNN convolution engine consumes roughly one‑quarter of the power of a conventional 8‑bit fixed‑point design while using fewer logic resources. The authors attribute this to the elimination of multipliers and the regular, shift‑centric datapath, which maps efficiently onto FPGA DSP slices and LUTs.
In summary, ShiftCNN contributes three main advances: (1) a power‑of‑two weight quantization that enables multiplier‑free inference; (2) a pre‑computation and indexing scheme that reduces the number of arithmetic operations by up to two orders of magnitude; and (3) a hardware architecture that leverages these algorithmic properties to achieve significant power and area savings on FPGA/ASIC platforms. Limitations include the need for additional on‑chip memory to store the pre‑computed terms and the growth of the codebook size with N and B, which may constrain ultra‑low‑resource edge devices. Future work could explore dynamic codebook compression, integration with sparsity‑inducing techniques, and more flexible scheduling for models with small channel counts or larger batch sizes. Overall, ShiftCNN presents a compelling path toward energy‑efficient, high‑performance CNN inference for both edge and data‑center accelerators.
Comments & Academic Discussion
Loading comments...
Leave a Comment