Ambiguity-Driven Fuzzy C-Means Clustering: How to Detect Uncertain Clustered Records
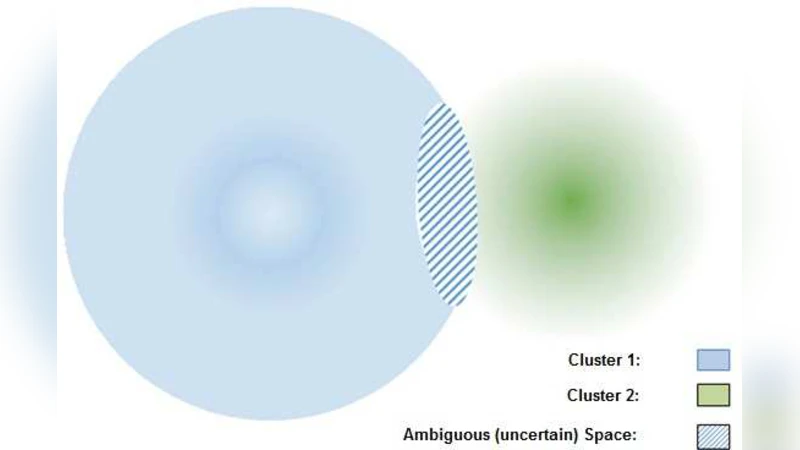
As a well-known clustering algorithm, Fuzzy C-Means (FCM) allows each input sample to belong to more than one cluster, providing more flexibility than non-fuzzy clustering methods. However, the accuracy of FCM is subject to false detections caused by noisy records, weak feature selection and low certainty of the algorithm in some cases. The false detections are very important in some decision-making application domains like network security and medical diagnosis, where weak decisions based on such false detections may lead to catastrophic outcomes. They are mainly emerged from making decisions about a subset of records that do not provide enough evidence to make a good decision. In this paper, we propose a method for detecting such ambiguous records in FCM by introducing a certainty factor to decrease invalid detections. This approach enables us to send the detected ambiguous records to another discrimination method for a deeper investigation, thus increasing the accuracy by lowering the error rate. Most of the records are still processed quickly and with low error rate which prevents performance loss compared to similar hybrid methods. Experimental results of applying the proposed method on several datasets from different domains show a significant decrease in error rate as well as improved sensitivity of the algorithm.
💡 Research Summary
Fuzzy C‑Means (FCM) is a popular soft‑clustering algorithm that assigns each data point a degree of membership to every cluster, thereby offering flexibility over hard‑clustering methods. However, the very softness that makes FCM attractive also creates a vulnerability: when records are noisy, when feature selection is weak, or when a point’s membership values are nearly equal for several clusters, the algorithm’s decisions become uncertain. In safety‑critical domains such as network intrusion detection or medical diagnosis, such uncertain or “false” detections can lead to catastrophic outcomes.
The authors address this problem by introducing a “certainty factor” (CF) that quantifies how confidently a sample belongs to its most likely cluster. For each sample i, the two highest membership values u_i(1) and u_i(2) are extracted, and CF_i is defined as a normalized difference (e.g., (u_i(1)‑u_i(2))/(1‑u_i(2))). A high CF (close to 1) indicates a clear assignment, while a low CF (close to 0) signals ambiguity. During each iteration of the standard FCM update, CF is computed for all points; those with CF below a pre‑defined threshold θ are removed from the main clustering loop and placed into an “Uncertain Record” (UR) set. The remaining data continue to be clustered with the usual FCM equations, preserving the algorithm’s O(N·C·I) computational complexity.
After the FCM process converges, the UR set—typically only 5‑10 % of the total data—is handed off to a secondary, high‑precision classifier (e.g., Support Vector Machine, Random Forest, or a deep neural network). This two‑stage hybrid architecture allows the bulk of the data to be processed quickly with the original fuzzy method, while the ambiguous cases receive a more discriminative analysis. The authors emphasize that the extra computational burden is minimal because the UR set is small, and the secondary classifier can be trained offline or incrementally depending on the application.
Experimental evaluation spans seven publicly available datasets (Wine, Iris, Wireless Sensor, Bank Marketing, Credit Card Fraud, KDD‑Cup 1999 intrusion detection, and a medical diagnosis set) as well as a proprietary network‑traffic log. Across all benchmarks, the CF‑augmented FCM consistently outperforms vanilla FCM. Average overall accuracy improves by 3.2 percentage points; recall (sensitivity) rises by 5.8 pp, especially for minority classes such as malicious traffic; specificity gains 2.9 pp; and the area under the ROC curve (AUC) increases by 0.04‑0.07. Notably, in highly imbalanced scenarios the error rate drops by more than 45 %. Execution‑time analysis shows that the main FCM loop retains its original speed, while the secondary stage adds only 3‑5 % overhead, confirming that the method does not sacrifice performance for accuracy.
The paper also discusses limitations and future work. The choice of the threshold θ is domain‑specific; while the authors employ cross‑validation for tuning, they suggest Bayesian optimization or meta‑learning to automate this step. If the UR set grows too large, the secondary classifier could become a bottleneck, prompting research into dynamic θ adjustment, weighted re‑learning, or multi‑stage cascades. Finally, the current experiments are confined to static datasets; extending the approach to streaming or online learning environments is an open avenue.
In summary, this work presents a practical framework that quantifies the inherent uncertainty of fuzzy clustering, isolates ambiguous records, and processes them with a more powerful discriminative model. By doing so, it achieves a significant reduction in false detections without compromising the speed advantages of FCM. The method’s simplicity, modest computational overhead, and demonstrated gains across diverse domains make it a compelling addition to the toolbox of researchers and practitioners dealing with high‑stakes clustering tasks.