Adaptive Training of Random Mapping for Data Quantization
Data quantization learns encoding results of data with certain requirements, and provides a broad perspective of many real-world applications to data handling. Nevertheless, the results of encoder is usually limited to multivariate inputs with the random mapping, and side information of binary codes are hardly to mostly depict the original data patterns as possible. In the literature, cosine based random quantization has attracted much attentions due to its intrinsic bounded results. Nevertheless, it usually suffers from the uncertain outputs, and information of original data fails to be fully preserved in the reduced codes. In this work, a novel binary embedding method, termed adaptive training quantization (ATQ), is proposed to learn the ideal transform of random encoder, where the limitation of cosine random mapping is tackled. As an adaptive learning idea, the reduced mapping is adaptively calculated with idea of data group, while the bias of random transform is to be improved to hold most matching information. Experimental results show that the proposed method is able to obtain outstanding performance compared with other random quantization methods.
💡 Research Summary
The paper addresses a fundamental limitation of existing random‑mapping based binary embedding methods, particularly cosine‑based quantization (CQ). While CQ enjoys the natural bounded output of the cosine function (‑1 to 1), its performance suffers because the random projection vectors w and the bias b are chosen without regard to the data distribution. Consequently, the resulting binary codes often fail to preserve the underlying structure of the data, leading to sub‑optimal retrieval accuracy.
To overcome this, the authors propose Adaptive Training Quantization (ATQ), a two‑stage learning framework that adaptively refines both the linear projection matrix W and the bias term b so that the cosine mapping aligns with the intrinsic two‑way (binary) clustering of the data.
Stage 1 – Adaptive training of the linear mapping.
Given a data matrix X ∈ ℝ^{d×n}, ATQ seeks a projection W ∈ ℝ^{d×r} that minimizes the objective
J(W) = ‖Cos(WᵀX) Π Cos(WᵀX)ᵀ‖_F,
where Π = I − (1/n) eeᵀ is the centered Laplacian matrix. This objective encourages the cosine‑transformed features to be well aligned within each of the two clusters (positive and negative sides) while being separated across clusters. Because a closed‑form eigen‑solution is unavailable, the authors employ the Conjugate Gradient (CG) method. CG requires only first‑order gradients, which are derived analytically, and uses the Fletcher‑Reeves update for the conjugate direction together with an Armijo line‑search to guarantee sufficient decrease. Convergence is monitored by a simple objective‑value‑difference stopping rule (ε‑criterion), avoiding costly gradient‑norm checks.
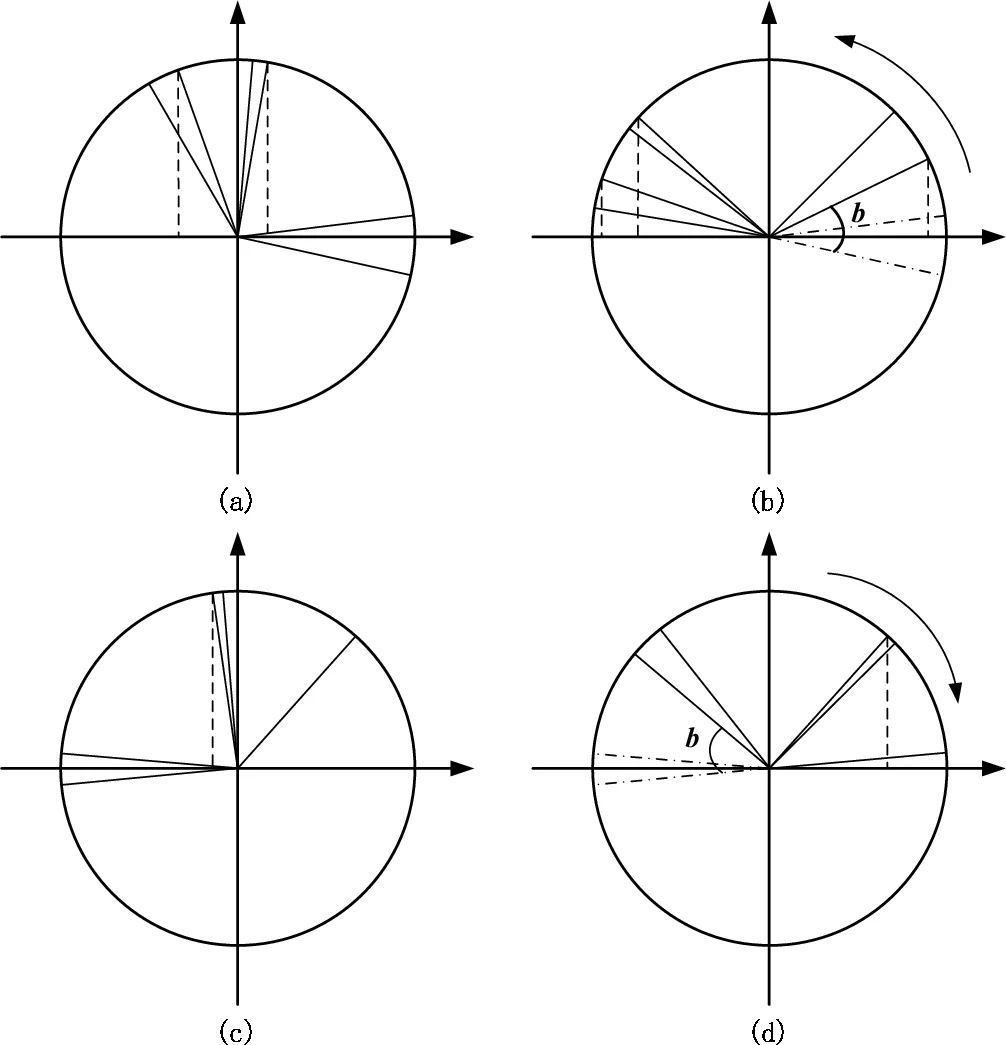
Stage 2 – Adaptive training of the bias.
In standard CQ the bias b is drawn uniformly at random, which often places the decision hyper‑plane in an unbalanced region, causing many bits to be biased toward one side. ATQ formulates bias optimization as
J(b) = Σ_i cos²(wᵀx_i + b)
and, after trigonometric manipulation, reduces it to
J(b) = max_b cos(2b + arctan μ),
with μ = Σ_i sin(2wᵀx_i) / Σ_i cos(2wᵀx_i). The optimal bias is therefore obtained analytically as
b* = –½ arctan μ (mod π/2).
This closed‑form solution directly maximizes the variance of each bit, ensuring that the cosine outputs fully exploit the
Comments & Academic Discussion
Loading comments...
Leave a Comment