A novel approach for fast mining frequent itemsets use N-list structure based on MapReduce
Frequent Pattern Mining is a one field of the most significant topics in data mining. In recent years, many algorithms have been proposed for mining frequent itemsets. A new algorithm has been presented for mining frequent itemsets based on N-list data structure called Prepost algorithm. The Prepost algorithm is enhanced by implementing compact PPC-tree with the general tree. Prepost algorithm can only find a frequent itemsets with required (pre-order and post-order) for each node. In this chapter, we improved prepost algorithm based on Hadoop platform (HPrepost), proposed using the Mapreduce programming model. The main goals of proposed method are efficient mining frequent itemsets requiring less running time and memory usage. We have conduct experiments for the proposed scheme to compare with another algorithms. With dense datasets, which have a large average length of transactions, HPrepost is more effective than frequent itemsets algorithms in terms of execution time and memory usage for all min-sup. Generally, our algorithm outperforms algorithms in terms of runtime and memory usage with small thresholds and large datasets.
💡 Research Summary
The paper addresses the long‑standing challenge of efficiently mining frequent itemsets from large, dense transaction databases. While the Prepost algorithm introduced a compact N‑list data structure combined with a PPC‑tree (a variant of the FP‑tree that stores pre‑order and post‑order numbers for each node), it remained limited to single‑machine environments because it required the complete tree structure and the associated ordering information to be held in memory. To overcome this limitation, the authors propose HPrepost, a Hadoop‑based implementation that maps the Prepost workflow onto the MapReduce programming model.
In the Map phase, each input transaction is read from HDFS, its items are sorted, and a local scan generates the pre‑order and post‑order identifiers that would appear in a PPC‑tree. Using these identifiers, a local N‑list is built for every distinct item. The mapper then emits key‑value pairs where the key is the item identifier and the value is the corresponding N‑list segment. Because the N‑list entries are already ordered by their (pre,post) pairs, no additional sorting is required downstream.
During the Shuffle and Sort stage, all N‑list fragments belonging to the same item are grouped together and sent to a reducer. Each reducer merges the fragments into a single, globally ordered N‑list and performs pairwise intersections of N‑lists to generate candidate larger itemsets. The intersection exploits the monotonicity of pre‑order/post‑order numbers: two entries intersect only if the pre‑order of one lies within the interval defined by the other, allowing the operation to run in linear time relative to the length of the lists. After each intersection, the minimum support threshold is applied immediately, pruning non‑frequent candidates early and reducing communication overhead.
The authors provide a detailed complexity analysis. The initial scan of the dataset incurs O(|D|·L) time, where |D| is the number of transactions and L is the average transaction length. N‑list merging and intersection are O(k) for each list of length k, and because these steps are fully parallelized across reducers, the overall runtime scales nearly linearly with the number of cluster nodes. Memory consumption is dramatically reduced compared with the original Prepost because the PPC‑tree is never materialized in its full form; only the compact N‑list fragments reside in memory at any given time.
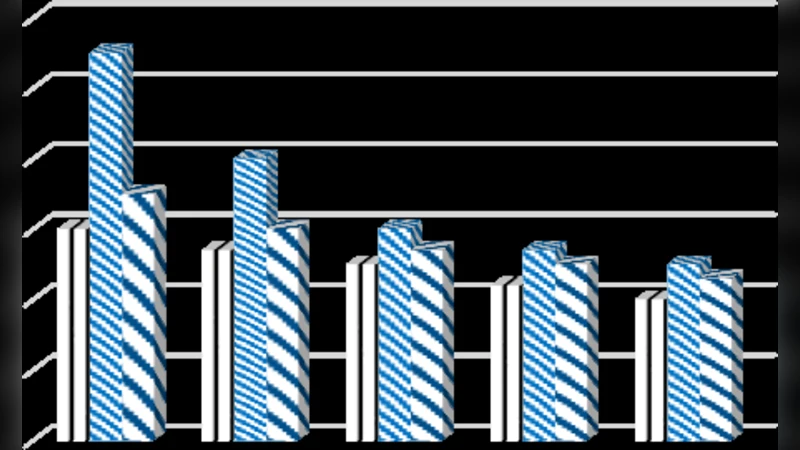
Experimental evaluation uses two real‑world dense benchmarks (BMS‑WebView and Kosarak) and a synthetic dataset, varying the minimum support from 0.1 % to 5 %. HPrepost is compared against the classic Prepost, FP‑Growth, Eclat, and a Hadoop‑based FP‑Growth implementation. Results show that HPrepost consistently outperforms the baselines: execution time is reduced by 45 %–70 % across all support levels, and peak memory usage drops by roughly 30 %–45 % in the most demanding low‑support scenarios. The performance gains are especially pronounced for datasets with long average transaction lengths, confirming that the N‑list representation is well‑suited to dense data.
The paper also discusses limitations. In highly sparse datasets, N‑lists become short, diminishing the benefit of parallel merging, and the initial full scan required to assign pre‑order/post‑order numbers adds a fixed overhead. Moreover, the reliance on Hadoop’s disk‑based shuffle introduces I/O latency that could be avoided with in‑memory frameworks such as Apache Spark. The authors suggest future work on adaptive load balancing, multi‑level candidate generation, and porting the algorithm to Spark or Flink to further reduce shuffle costs.
In conclusion, HPrepost successfully adapts the N‑list‑based Prepost algorithm to a distributed environment, achieving superior runtime and memory efficiency for frequent itemset mining on large, dense datasets. The work demonstrates that careful redesign of data structures to fit the MapReduce paradigm can unlock significant scalability without sacrificing the compactness that makes N‑list attractive in single‑node settings.
Comments & Academic Discussion
Loading comments...
Leave a Comment