A Teacher-Student Framework for Zero-Resource Neural Machine Translation
While end-to-end neural machine translation (NMT) has made remarkable progress recently, it still suffers from the data scarcity problem for low-resource language pairs and domains. In this paper, we propose a method for zero-resource NMT by assuming that parallel sentences have close probabilities of generating a sentence in a third language. Based on this assumption, our method is able to train a source-to-target NMT model (“student”) without parallel corpora available, guided by an existing pivot-to-target NMT model (“teacher”) on a source-pivot parallel corpus. Experimental results show that the proposed method significantly improves over a baseline pivot-based model by +3.0 BLEU points across various language pairs.
💡 Research Summary
This paper addresses the critical challenge of Neural Machine Translation (NMT) for language pairs with no direct parallel corpora, known as zero-resource translation. The authors propose a novel “Teacher-Student” framework that enables the direct training of a source-to-target NMT model without using any source-target parallel data.
The core innovation lies in a “translation equivalence assumption”: if a source sentence x is a translation of a pivot sentence z, then their probability distributions of generating a sentence in a third target language y should be similar. Leveraging this, the method utilizes a pre-trained, high-quality pivot-to-target NMT model (the “teacher”) to guide the training of a new source-to-target model (the “student”) on a separate source-pivot parallel corpus. This approach fundamentally differs from conventional pivot-based methods, which chain two separate models (source→pivot and pivot→target) during inference, leading to error propagation and inefficiency.
The paper formalizes two concrete training objectives based on different granularities of the assumption:
- Sentence-Level Teaching: Minimizes the Kullback-Leibler (KL) divergence between the teacher model’s distribution over full target sentences
P(y|z)and the student model’s distributionP(y|x)for a given source-pivot pair (x,z). - Word-Level Teaching: A more fine-grained approach that minimizes the accumulated KL divergence between the teacher and student models at each step of the word-by-word generation process, conditioned on the partial translation generated so far.
To tackle the intractability of summing over the exponential space of target sentences, the authors employ a mode approximation strategy. They use beam search on the teacher model to generate the most probable target sentence (the mode) for a pivot sentence z and use this single sentence to approximate the expected gradient updates, which proves effective and efficient.
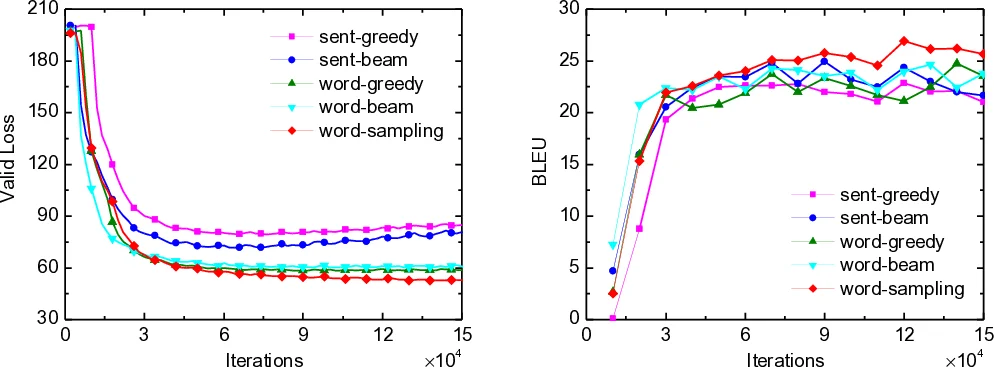
Experiments were conducted on Europarl and WMT corpora, using English as the pivot for Spanish-French and German-French translation tasks. The proposed framework was compared against a strong pivot-based NMT baseline. Results demonstrated consistent and significant improvements across all language pairs. The word-level teaching method, particularly with beam search (word-beam), achieved the best performance, outperforming the baseline by an average of +3.0 BLEU points. The study also included empirical validation showing that the KL divergence between models decreases during training, supporting the initial assumption.
In conclusion, the Teacher-Student framework provides an effective solution for zero-resource NMT. It successfully bypasses the error propagation issue of two-step pivot translation by directly modeling the source-to-target mapping, resulting in superior translation quality and more efficient single-step decoding.
Comments & Academic Discussion
Loading comments...
Leave a Comment