Demonstrating a Service-Enhanced Retrieval System
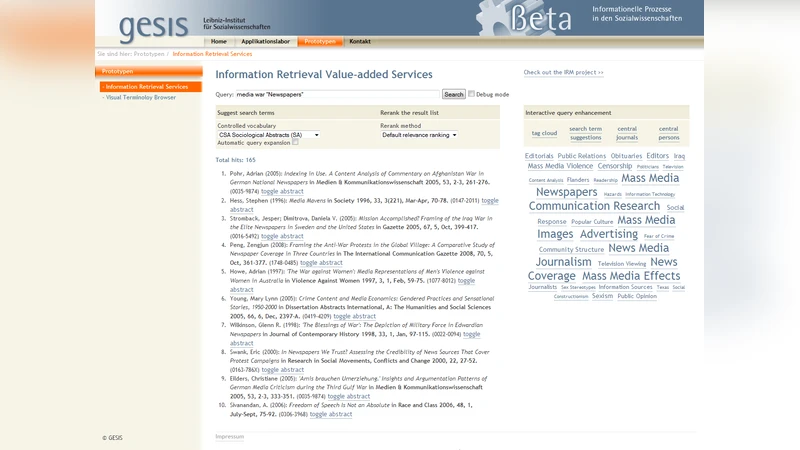
This paper is a short description of an information retrieval system enhanced by three model driven retrieval services: (1) co-word analysis based query expansion, re-ranking via (2) Bradfordizing and (3) author centrality. The different services each favor quite other - but still relevant - documents than pure term-frequency based rankings. Each service can be interactively combined with each other to allow an iterative retrieval refinement.
💡 Research Summary
The paper presents a prototype information‑retrieval (IR) system that augments a conventional keyword‑based search engine with three model‑driven services: (1) query expansion via co‑word analysis (Search Term Recommender, STR), (2) result re‑ranking by Bradfordizing, and (3) result re‑ranking by author centrality. The authors argue that each service offers a distinct “view” of the information space, surfacing relevant documents that would be missed or ranked low by a pure term‑frequency (tf‑idf) approach.
The STR component addresses the classic language problem in IR. Using statistical co‑occurrence analysis between free terms (extracted from titles or abstracts) and controlled vocabulary terms, the system learns associations with a hybrid machine‑learning pipeline that combines Support Vector Machines (SVM) and Probabilistic Latent Semantic Analysis (PLSA). Trained on six heterogeneous scholarly databases (covering social science, sport science, and pedagogy), the STR can suggest controlled descriptors automatically, display them as a term cloud, or expand the user’s query directly. This helps users formulate queries that match the indexing language of the underlying collections without requiring deep domain knowledge.
Bradfordizing is a bibliometric re‑ranking technique that exploits the “core‑journal” phenomenon described by Bradford’s law. After an initial Solr search, the prototype filters results by ISSN, aggregates the number of hits per journal using Solr’s facet functionality, and then boosts the original Solr score of each document by the frequency count of its journal. Consequently, articles from journals that publish most frequently on the query topic rise to the top of the result list. The method requires reliable journal identifiers (ISSN) but is straightforward to implement and effectively reduces oversized result sets.
Author centrality offers a network‑analytic re‑ranking alternative. For a given query, the system builds a co‑authorship graph from the retrieved documents, where nodes represent authors and edges represent joint publications. Betweenness centrality is computed for each author; documents are then sorted according to the highest centrality among their authors. The underlying assumption is that publications by structurally central scholars are more likely to be influential or relevant. This approach diverges from text‑centric ranking and leverages social structure information embedded in the metadata.
Technically, the prototype integrates three open‑source components: Apache Solr as the search engine, Grails as the web application framework, and Recommind Mindserver for the STR’s text categorization. Each service is encapsulated as a Grails plugin, allowing users to combine them interactively via a tabbed interface or to run them automatically in a pipeline. The system ingests bibliographic metadata from six databases (SOLIS, SPOLIT, FIS Bildung, SA, PEI, and FES) amounting to roughly 1.6 million records, with mixed languages (German and English) and varying metadata schemas. The authors address schema heterogeneity through normalization and by providing six specialized controlled vocabularies that match the respective databases.
The demonstration setup is deliberately lightweight: a web‑based prototype that runs on any standard laptop with an active Internet connection and a modern browser (Firefox preferred). No special hardware or client‑side software is required, underscoring the feasibility of deploying such service‑enhanced retrieval in real scholarly portals.
In conclusion, the paper showcases how three complementary, model‑driven services can be combined to support iterative retrieval refinement. Query expansion broadens recall, Bradfordizing improves precision by emphasizing core journals, and author centrality introduces a social‑network perspective. While the authors do not present quantitative evaluation results, they suggest that the system enables users to explore multiple relevance dimensions and to converge on a satisfactory result set through interactive refinement. Future work is indicated to include user studies, performance benchmarking, and automated orchestration of service combinations.
Comments & Academic Discussion
Loading comments...
Leave a Comment