Learning what matters - Sampling interesting patterns
In the field of exploratory data mining, local structure in data can be described by patterns and discovered by mining algorithms. Although many solutions have been proposed to address the redundancy problems in pattern mining, most of them either pr…
Authors: Vladimir Dzyuba, Matthijs van Leeuwen
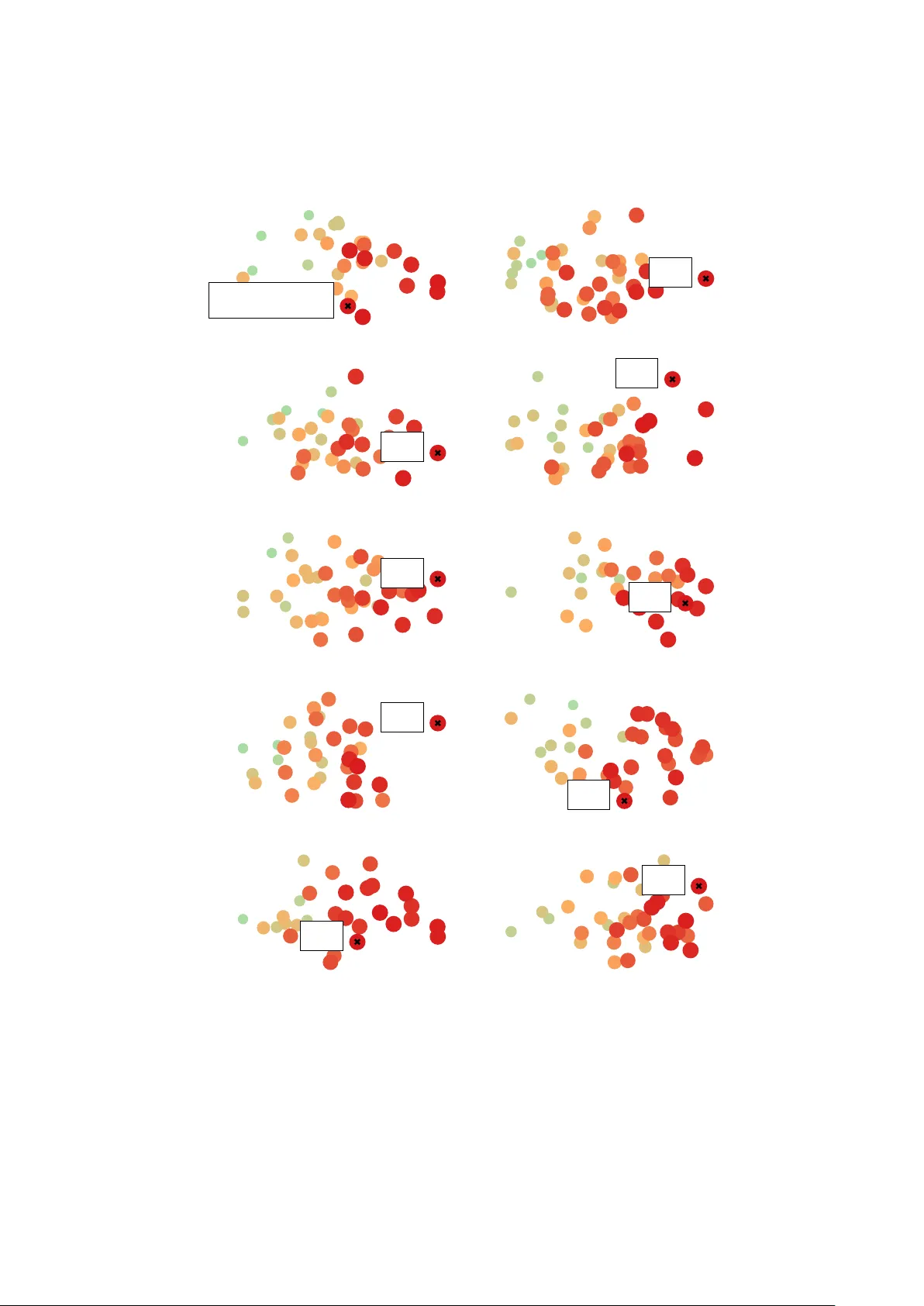
Learning what matters – Sampling in teresting patterns Vladimir Dzyuba 1 and Matthijs v an Leeu wen 2 1 Departmen t of Computer Science, KU Leuven, Belgium 2 LIA CS, Leiden Univ ersity , The Netherlands vladimir.dzyuba@cs.kuleuven.be , m.van.leeuwen@liacs.leidenuniv.nl Abstract. In the field of explor atory data mining , lo cal structure in data can b e described by p atterns and disco vered by mining algorithms. Although many solutions ha ve been prop osed to address the redundancy problems in pattern mining, most of them either provide succinct pat- tern sets or take the interests of the user into accoun t—but not b oth. Consequen tly , the analyst has to inv est substantial effort in iden tifying those patterns that are relev ant to her sp ecific in terests and goals. T o address this problem, w e propose a nov el approach that com bines pat- tern sampling with interactiv e data mining. In particular, we introduce the LetSIP algorithm, whic h builds upon recen t adv ances in 1) weigh ted sampling in SA T and 2) learning to rank in interactiv e pattern mining. Sp ecifically , it exploits user fe e db ack to dir e ctly le arn the p ar ameters of the sampling distribution that r epr esents the user’s inter ests . W e compare the performance of the prop osed algorithm to the state- of-the-art in interactiv e pattern mining by emulating the in terests of a user. The resulting system allows efficien t and interlea v ed learning and sampling, thus user-sp ecific anytime data exploration. Finally , LetSIP demonstrates fav ourable trade-offs concerning both qualit y–div ersity and exploitation–exploration when compared to existing methods. 1 In tro duction Imagine a data analyst who has access to a medical database con taining in- formation ab out patients, diagnoses, and treatmen ts. Her goal is to identify nov el connections b etw een patient characteristics and treatmen t effects. F or example, one treatment may b e more effective than another for patien ts of a certain age and occupation, even though the latter is more effectiv e at large. Here, age and o ccupation are latent factors that explain the difference in treatment effect. In the field of explor atory data mining , suc h h yp otheses are represented b y p atterns [1] and disco vered by mining algorithms. Informally , a pattern is a state- men t in a formal language that concisely describes the structure of a subset of the data. Unfortunately , in an y realistic database the inter esting and/or r elevant patterns tend to get lost among a h umongous num b er of patterns. This do cumen t is an extended version of a conference publication [14]. The solutions that hav e b een prop osed to address this so-called p attern ex- plosion , caused by enumerating al l patterns satisfying given constraints, can b e roughly clustered into four categories: 1) c ondense d r epr esentations [10], 2) p at- tern set mining [9], 3) p attern sampling [5], 4) and—most recen tly— inter active p attern mining [20]. As exp ected, eac h of these categories has its o wn strengths and w eaknesses and there is no ultimate solution as of yet. That is, condensed represen tations, e.g., closed itemsets, can b e lossless but usually still yield large result sets; pattern set mining and pattern sampling can pro vide succinct pattern sets but do not take the analyst into account; and existing interactiv e approaches tak e the user into accoun t but do not adequately address the pattern explosion. Consequen tly , the analyst has to inv est substan tial effort in identifying those patterns that are relev ant to her specific in terests and goals, whic h often requires extensive data mining exp ertise. Aims and con tributions Our o v erarching aim is to enable analysts—such as the one describ ed in the medical scenario ab o ve—to discov er small sets of patterns from data that they consider in teresting. This translates to the following three sp ecific requiremen ts. First, w e require our approac h to yield c oncise and diverse r esult sets , effectiv ely a voiding the pattern explosion. Second, our method should take the user’s inter ests into ac c ount and ensure that the results are relev an t. Third, it should achiev e this with limite d effort on b ehalf of the user . T o satisfy these requirements, w e propose an approac h that com bines pattern sampling with interactiv e data mining tec hniques. In particular, we introduce the LetSIP algorithm, for Le arn t o S ample I n teresting P atterns, which follo ws the Mine, Inter act, L e arn, R ep e at framework [13]. It samples a small set of patterns, receiv es feedback from the user, exploits the feedback to learn new parameters for the sampling distribution, and repeats these steps. As a result, the user may utilize a compact diverse set of interesting patterns at any momen t, blurring the b oundaries b et ween learning and discov ery mo des. W e satisfy the first requirement by using a sampling technique that samples high quality patterns with high probabilit y . While sampling do es not guaran tee div ersity p er se , we demonstrate that it gives concise yet diverse results in prac- tice. Moreov er, sampling has the adv an tage that it is anytime , i.e., the result set can grow by user’s request. LetSIP ’s sampling comp onent is based on recent adv ances in sampling in SA T [12] and their extension to pattern sampling [15]. The second requiremen t is satisfied b y learning what matters to the user, i.e., b y interactiv ely learning the distribution patterns are sampled from. This allows the user to steer the sampler tow ards sub jectively interesting regions. W e build up on recent work [13,7] that uses pr efer enc e le arning to learn to rank patterns. Although user effort can partially b e quantified b y the total amount of input that needs to b e giv en during the analysis, the third requirement also concerns the time that is needed to find the first interesting results. F or this it is of par- ticular in terest to study the tr ade-off b etwe en exploitation and explor ation . As men tioned, one of the b enefits of interactiv e pattern sampling is that the b ound- aries b et w een learning and discov ery are blurred, meaning that the system keeps learning while it con tinuously aims to discov er p oten tially interesting patterns. W e ev aluate the p erformance of the prop osed algorithm and compare it to the state-of-the-art in in teractive pattern mining b y emulating the in terests of a user. The results confirm that the prop osed algorithm has the capacit y to learn what matters based on little feedbac k from the user. More imp ortan tly , the LetSIP algorithm demonstrates fav ourable trade-offs concerning both quality–div ersit y and exploitation–exploration when compared to existing metho ds. 2 In teractiv e pattern mining: Problem definition Recall the medical analyst example. W e assume that after insp ecting patterns, she can judge their interestingness, e.g., by comparing tw o patterns. Then the primary task of interactiv e pattern mining consists in learning a formal mo del of her interests. The second task inv olves using this mo del to mine nov el patterns that are sub jectively interesting to the user (according to the learned mo del). F ormally , let D denote a dataset, L a pattern language, C a (p ossibly empty) set of constraints on patterns, and the unknown sub jective pattern preference relation of the current user o ver L , i.e., p 1 p 2 implies that the user considers pattern p 1 sub jectively more interesting than pattern p 2 : Pr oblem 1 (L e arning). Given D , L , and C , dynamically collect feedback U with resp ect to patterns in L and use U to learn a (sub jective) pattern in terestingness function h : L → R such that h ( p 1 ) > h ( p 1 ) ⇔ p 1 p 2 . The mining task should account for the potential div ersity of user’s in terests. F or example, the analyst ma y (unwittingly) b e interested in several unrelated treatmen ts with disparate laten t factors. An algorithm should be able to iden tify and mine patterns that are represen tative of these diverse hypotheses. Pr oblem 2 (Mining). Given D , L , C , and h , mine a set of patterns P h that maximizes a com bination of interestingness h and diversit y of patterns. The in terestingness of P can be quantified b y the a v erage qualit y of its mem b ers, i.e., P p ∈P h ( p ) | / |P | . Div ersity measures quan tify how different patterns in a set are from each other. Joint entr opy is a common diversit y measure [24] (see Section 4 for the definition). 3 Related w ork In this pap er, w e fo cus on t wo classes of related w ork aimed at alleviating the pattern explosion, namely 1) pattern sampling and 2) in teractive pattern mining. P attern sampling. First pattern samplers are based on Marko v Chain Monte Carlo (MCMC) random w alks o ver the pattern lattice [5,17,4]. Their main ad- v an tage is that they supp ort “black b o x” distributions, i.e., they do not require an y prior knowledge ab out the target distribution, a prop ert y essential for in- teractiv e exploration. How ever, they often conv erge only slowly to the desired target distribution and require the selection of the “right” proposal distributions. Samplers that are based on alternativ e approaches include direct tw o-step samplers and XOR samplers. Two-step samplers [6,8], while pro v ably accurate and efficient, only support a limited n um b er of distributions and th us cannot b e easily extended to interactiv e settings. Flexics [15] is a recen tly prop osed pattern sampler based on the latest adv ances in weigh ted constrained sampling in SA T [12]. It supp orts blac k-box target distributions, pro vides guarantees with resp ect to sampling accuracy and efficiency , and has been shown to b e comp et- itiv e with the state-of-the-art metho ds describ ed ab o ve. In teractive pattern mining. Most recen t approaches to interactiv e pattern mining are based on learning to rank patterns. They first app eared in Xin et al. [25] and Rueping [22] and were indep enden tly extended by Boley et al. [7] and Dzyuba et al. [13]. The cen tral idea b ehind these algorithms is to alternate b e- t ween mining and learning. Pri ime [3] fo cuses on adv anced feature construction for in teractive mining of structured data, e.g., sequences or graphs. T o the b est of our knowledge, IPM [2] is the only existing approach to in teractive items et sampling. It uses binary feedbac k (“likes” and “dislik es”) to up date weigh ts of individual items. Itemsets are sampled proportional to the pro duct of w eigh ts of constituent items. Th us, the mo del of user interests in IPM is fairly restricted; moreov er, it p oten tially suffers from conv ergence issues t ypical for MCMC. W e empirically compare LetSIP with IPM in Section 6. 4 Preliminaries P attern mining and sampling. W e fo cus on itemset mining , i.e., pattern mining for binary data. Let I = { 1 . . . M } denote a set of items. Then, a dataset D is a bag of transactions o ver I , where each transaction t is a subset of I , i.e., t ⊆ I ; T = { 1 . . . N } is a set of transaction indices. The pattern language L also consists of sets of items, i.e., L = 2 I . An itemset p occurs in a transaction t , iff p ⊆ t . The frequency of p is the prop ortion of transactions in whic h it o ccurs, i.e., f req ( p ) = |{ t ∈ D | p ⊆ t }| / N . In lab eled datasets, each transaction t has a lab el from {− , + } ; f req − , + are defined accordingly . Giv en an (arbitrarily ordered) pattern set P of size k , its div ersity can b e mea- sured using joint entr opy H J , which essen tially quantifies the ov erlap of sets of transactions, in whic h the patterns in P o ccur. Let [ · ] denote the Iv erson brac ket, b 0 ∈ { 0 , 1 } k a binary k -tuple, and P ( b 0 ) = 1 |D | P t ∈D Q i ∈ [1 , k ] [ b 0 i = 1 ⇔ P i ⊆ t ] the fraction of transactions in D cov ered only b y patterns in P that corresp ond to non-zero elemen ts of b 0 (e.g., if k = 3 and b 0 = 101, w e only count the transactions co vered b y the 1st and the 3rd pattern and not co vered by the 2nd pattern). Join t en tropy H J is defined as H J ( P ) = − P b ∈{ 0 , 1 } k P ( b ) × log P ( b ). H J is mea- sured in bits and b ounded from ab o ve b y k . The higher the joint en tropy , the more div erse are the patterns in P in terms of their o ccurrences in D . The choice of constraints and a quality measure allows a user to express her analysis requiremen ts. The most common constraint is minimal fr e quency f req ( p ) ≥ θ . In contrast to hard constraints, quality measures are used to describ e soft preferences that allow to rank patterns; see Section 6 for examples. While common mining algorithms return the top- k patterns w.r.t. a measure ϕ : L → R + , pattern sampling is a randomized pro cedure that ‘mines’ a pattern with probability prop ortional to its quality , i.e., P ϕ ( p is sampled ) = ϕ ( p )/ Z ϕ , if p ∈ L satisfies C , and 0 otherwise, where Z ϕ is the (unknown) normalization constan t. This is an instance of weigh ted constrained sampling. W eigh ted constrained sampling. This problem has b een extensively studied in the context of sampling solutions of a SA T problem [21]. WeightGen [12] is a recent algorithm for approximate weigh ted sampling in SA T. The core idea consists of partitioning the solution space in to a n um b er of “cells” and sampling a solution from a random cell. Partitioning with desired prop erties is obtained via augmen ting the SA T problem with uniformly random X OR constraints (X ORs). T o sample a solution, WeightGen dynamically estimates the num b er of X ORs required to obtain a suitable cell, generates random XORs, stores the solutions of the augmented problem (i.e., a random cell), and returns a p er- fect weigh ted sample from the cell. Owing to the prop erties of partitioning with uniformly random XORs, WeightGen pro vides theoretical p erformance guar- an tees regarding quality of samples and efficiency of the sampling pro cedure. F or implementation purposes, WeightGen only requires an efficien t oracle that en umerates solutions. Moreo ver, it treats the target sampling distribution as a black b o x: it requires neither a compact description thereof, nor the knowl- edge of the normalization constan t. Both features are crucial in pattern sampling settings. Flexics [15], a recen tly prop osed pattern sampler based on Weight- Gen , has b een sho wn to be accurate and efficien t. See Appendix A for a more detailed description of these algorithms. Preference learning. The problem of learning ranking functions is known as obje ct r anking [19]. A common solving technique inv olves minimizing pair- wise loss, e.g., the n umber of discordan t pairs. F or example, user feedback U = { p 1 p 3 p 2 , p 4 p 2 } is seen as { ( p 1 p 3 ) , ( p 1 p 2 ) , ( p 3 p 2 ) , ( p 4 p 2 ) } . Giv en feature representations of ob jects p i , ob ject ranking is equiv alen t to p ositiv e-only classification of difference vectors, i.e., a rank ed pair example p i p j corresp onds to a classification example ( p i − p j , +). All pairs comprise a train- ing dataset for a scoring classifier. Then, the predicted ranking of an y set of ob jects can be obtained by sorting these ob jects b y classifier score descending. F or example, this form ulation is adopted by SvmRank [18]. 5 Algorithm Key questions concerning instantiations of the Mine, inter act, le arn, r ep e at frame- w ork include 1) the feedback format, 2) learning qualit y measures from feedbac k, 3) mining with learned measures, and crucially , 4) selecting the patterns to sho w to the user. As pattern sampling has been shown to be effective in mining and learning, w e presen t LetSIP , a sampling-based instantiation of the framework Algorithm 1 LetSIP Input: Dataset D , minimal frequency threshold θ P arameters: Query size k , query retention l , range A , cell sampling strategy ς SCD: regularisation parameter λ , iterations T ; Flexics : error tolerance κ Initialization 1: Ranking function h 0 = Logistic ( 0 , A ) Zero weigh ts lead to uniform sampling 2: F eedback U ← ∅ , Q ∗ 0 ← ∅ Mine , Inter act , L e arn , R ep e at lo op 3: for t = 1 , 2 , . . . do 4: R = T akeFirst ( Q ∗ t − 1 , l ) Retain top patterns from the previous iteration 5: Query Q t ← R ∪ SampleP a tterns ( h t − 1 ) × ( k − | R | ) times 6: Q ∗ t = Order ( Q t ), U ← U ∪ Q ∗ t Ask user to order patterns in Q t 7: h t ← Logistic ( LearnWeights ( U ; λ, T ), A ) 8: function SampleP a tterns (Sampling weigh t function w : L → [ A, 1]) 9: C = FlexicsRandomCell ( D , f r eq ( · ) ≥ θ , w ; κ ) 10: if ς = Top ( m ) then return m highest-weigh ted patterns 11: else if ς = Random then return PerfectSample ( C , w ) whic h employs Flexics . The sequel describes the mining and learning compo- nen ts of LetSIP . Algorithm 1 shows its pseudo code. Mining patterns by sampling. Recall that the main goal is to discov er pat- terns that are sub jectively in teresting to a particular user. W e use parameterised logistic functions to measure the in terestingness/quality of a given pattern p : ϕ logistic ( p ; w, A ) = A + 1 − A 1 + e − w · p where p is the vector of pattern features for p , w are feature weigh ts, and A is a parameter that controls the range of the interestingness measure, i.e. ϕ logistic ∈ ( A, 1). Examples of pattern features include Leng th ( p ) = | p | / |I | , F r eq uency ( p ) = f r eq ( p ) / |D | , I tems ( i, p ) = [ i ∈ p ]; and T r ansactions ( t, p ) = [ p ⊆ t ], where [ · ] denotes the Iverson brac ket. W eigh ts reflect feature contribu- tions to pattern interestingness, e.g., a user might b e interested in combinations of particular items or disin terested in particular transactions. The set of features w ould typically be chosen b y the mining system designer rather than b y the user herself. W e empirically ev aluate several feature combinations in Section 6. Sp ecifying feature weigh ts manually is tedious and opaque, if at all possible. Belo w we present an algorithm that learns the weigh ts based on easy-to-provide feedbac k with resp ect to patterns. This motiv ates our c hoice of logistic functions: they enable efficient learning. F urthermore, their b ounded range [ A, 1] yields distributions that allo w efficient sampling directly prop ortional to ϕ logistic with Flexics . P arameter A essentially controls the tilt of the distribution [15]. User interaction & learning from feedback. F ollowing previous researc h [13], we use or der e d fe e db ack , where a user is ask ed to provide a total order ov er a (small) n umber of patterns according to their sub jective interestingness; see Figure 1 for an example. W e assume that there exists an unknown, user-sp ecific target ranking R ∗ , i.e., a total order ov er L . The inductive bias is that there exists w ∗ suc h that p q ⇒ ϕ logistic ( p, w ∗ ) > ϕ logistic ( q , w ∗ ). W e apply the reduction of ob ject ranking to binary classification of difference v ectors (see Section 4). F ollo wing Boley et al. [7], we use Sto c hastic Co ordinate Descent (SCD) [23] for minimizing L1-regularized logistic loss. How ever, unlike Boley et al., we directly use the learned functions for sampling. SCD is an an ytime conv ex optimization algorithm, which makes it suitable for the in teractive setting. Its runtime scales linearly with the n umber of training pairs and the dimensionalit y of feature v ectors. It has t wo parameters: 1) the n umber of weigh t up dates (per iteration of LetSIP ) T and 2) the regularization parameter λ . How ever, direct learning of ϕ logistic is infeasible, as it results in a non-con vex loss function. W e therefore use SCD to optimize the standard logistic loss, whic h is conv ex, and use the learned weigh ts w in ϕ logistic . Selecting patterns to show to the user. An interactiv e system seeks to ensure faster learning of accurate models by targeted selection of patterns to sho w to the user; this is kno wn as active le arning or query sele ction . Random- ized metho ds hav e b een succe ssfully applied to this task [13]. F urthermore, in large pattern spaces the probability that tw o redundant patterns are sampled in one (small) batch is typically lo w. Therefore, a sampler, whic h pro duces inde- p enden t samples, t ypically ensures diversit y within batches and thus sufficient explor ation . W e directly show k patterns sampled by Flexics prop ortional to ϕ logistic to the user, for whic h she has to provide a total order as feedback. W e prop ose tw o mo difications to Flexics , which aim at emphasising ex- ploitation , i.e., biasing sampling to wards higher-quality patterns. First, we em- plo y alternativ e cell sampling strategies. Normally Flexics draws a perfect w eighted random sample, once it obtains a suitable cell. W e denote this strat- egy as ς = Random . W e prop ose an alternative strategy ς = Top( m ) , which pic ks the m highest-quality patterns from a cell (Line 10 in Algorithm 1). W e h yp othesize that, owing to the prop erties of random XOR constraints, patterns in a cell as w ell as in consecutive cells are exp ected to b e sufficiently diverse and th us the mo dified cell sampling do es not disrupt exploration. Rigorous analysis of (unw eigh ted) uniform sampling by Chakrab ort y et al. sho ws that re-using samples from a cell still ensures broad cov erage of the so- lution space, i.e., diversit y of samples [11]. Although as a downside, consecutive samples are not i.i.d., the effects are b ounded in theory and inconsequential in practice. W e use these results to take license to mo dify the theoretically moti- v ated cell sampling pro cedure. Although we do not present a similar theoretical analysis of our mo difications, we ev aluate them empirically . Second, we prop ose to retain the top l patterns from the previous query and only sample k − l new patterns (Lines 4–5). This should help users to relate the queries to eac h other and p ossibly exploit the structure in the pattern space. Iteration 1 Iteration 2 . . . Iteration 30 p 1 , 1 p 1 , 2 p 1 , 3 p 1 , 3 p 2 , 2 p 2 , 3 p 29 , 1 p 30 , 2 p 30 , 3 f r eq , | p | , . . . 52 , 6 49 , 7 48 , 9 48 , 9 53 , 7 54 , 9 73 , 8 60 , 8 54 , 8 F eedback U p 1 , 3 p 1 , 1 p 1 , 2 p 1 , 3 p 2 , 2 p 2 , 3 p 29 , 1 p 30 , 2 p 30 , 3 ϕ = sur p 0 . 12 0 . 04 0 . 20 0 . 20 0 . 11 0 . 10 0 . 28 0 . 26 0 . 12 (p ct.rank) 0 . 51 0 . 13 0 . 84 0 . 84 0 . 46 0 . 41 0 . 99 0 . 97 0 . 51 Regret: Max. ϕ 1 − 0 . 84 = 0 . 16 0 . 16 0 . 01 T rue qualit y ϕ Learned quality ϕ logistic Fig. 1. W e emulate user feedback U using a hidden quality measure ϕ (here sur p ; the b o xplot shows the distribution of ϕ in the given dataset). The rows ab ov e the bar sho w the prop erties of the sampled patterns that would b e insp ected by a user, e.g., fr e quency or length , and the emulated feedbac k. The scatter plots show the relation b et w een ϕ and the learned mo del of user interests ϕ logistic after 1 and 29 iterations of feedbac k and learning. The performance of the learned model improv es considerably as evidenced by higher v alues of ϕ of the sampled patterns (squares) and low er regret. 6 Exp erimen ts The experimental ev aluation fo cuses on 1) the accuracy of the learned user mod- els and 2) the effectiveness of learning and sampling. Ev aluating interactiv e al- gorithms is challenging, for domain exp erts are scarce and it is hard to gather enough exp erimen tal data to draw reliable conclusions. In order to p erform ex- tensiv e ev aluation, we emulate users using (hidden) in terest mo dels, whic h the algorithm is supp osed to learn from ordered feedback only . W e follo w a proto col also used in previous w ork [13]: w e assume that R ∗ is deriv ed from a quality measure ϕ , i.e., p q ⇔ ϕ ( p ) > ϕ ( q ). Th us, the task is to learn to sample frequent patterns prop ortional to ϕ from (short) sample rankings. As ϕ , w e use frequency f req , surprisingness sur p , and discriminativit y in lab eled data as measured by χ 2 , where sur p ( p ) = max { f r eq ( p ) − Q i ∈ p f req ( { i } ) , 0 } and χ 2 ( p ) = X c ∈{− , + } ( f req ( p ) ( f r eq c ( p ) − |D c | )) 2 f req ( p ) |D c | + ( f req ( p ) ( f r eq c ( p ) − |D c | )) 2 ( |D | − f req ( p )) |D c | T able 1. Dataset properties. |I | |D | θ F requent patterns anneal 93 812 660 149 331 australian 125 653 300 141 551 german 112 1000 300 161 858 heart 95 296 115 153 214 hepatitis 68 137 48 148 289 lymph 68 148 48 146 969 primary 31 336 16 162 296 soybean 50 630 28 143 519 vote 48 435 25 142 095 zoo 36 101 10 151 806 W e inv estigate the p erformance of the algorithm on ten datasets 3 . F or eac h dataset, we set the minimal sup- p ort threshold such that there are appro ximately 140 000 frequent pat- terns. T able 1 shows dataset statis- tics. Eac h exp eriment inv olv es 30 it- erations (queries). W e use the default v alues suggested by the authors of SCD and Flexics for the auxiliary parameters of LetSIP : λ = 0 . 001, T = 1000, and κ = 0 . 9. W e ev aluate performance using cumulative r e gr et , which is the differ- ence b et w een the ideal v alue of a cer- tain measure M and its observed v alue, summed ov er iterations. W e use the maximal and av erage quality ϕ in a query and joint en tropy as performance measures. T o allo w comparison across datasets and measures, we use p ercen tile ranks by ϕ as a non-parametric measure of ranking p erformance. W e also divide join t entrop y b y k : th us, the ideal v alue of eac h measure is 1 (e.g., the highest p ossible ϕ ov er all frequent patterns has the p ercen tile rank of 1), and the re- gret is defined as P 1 − M ( Q ∗ i ), where M ∈ { ϕ av g , ϕ max , H J } . W e rep eat eac h exp erimen t ten times with differen t random seeds and rep ort a verage regret. A c haracteristic exp erimen t in detail. Figure 1 illustrates the w orkings of LetSIP and the experimental setup. It uses the lymph dataset, the target quality measure ϕ = sur p , I tems as features, and the following parameter settings: k = 3, A = 0 . 1, l = 1, ς = Random . LetSIP starts by sampling patterns uniformly . A human user would insp ect the patterns (items not shown) and their properties, e.g., frequency or length, or visualizations thereof, and rank the patterns by their sub jective interestingness; in these exp erimen ts, w e order them according to their v alues of ϕ . The algorithm uses the feedback to up date ϕ logistic . A t the next iteration, the patterns are sampled from an up dated distribution. As l = 1, the top-rank ed pattern from the previous iteration ( p 1 , 3 ) is retained. After a n umber of iterations, the accuracy of the appro ximation increases considerably , while the regret decreases. On av erage, one iteration tak es 0 . 5s on a desktop computer. Ev aluating comp onen ts of LetSIP. W e inv estigate the effects of the c hoice of features and parameter v alues on the p erformance of LetSIP , in partic- ular query size k , query retention l , range A , and cell sampling strategy ς . W e use the following feature combinations ( k denotes concatenation): Items (I); Items k L ength k F r e quency (ILF); and Items k L ength k F r e quency k T r ansactions (ILFT). V alues for other parameters and aggregated results are shown in T able 2. Increasing the query size decreases the maximal quality regret more than t wofold, which indicates that the prop osed learning technique is able to identify 3 Source: https://dtai.cs.kuleuven.be/CP4IM/datasets/ the prop erties of target measures from ordered lists of patterns. How ever, as larger queries also increase the user effort, further we use a more reasonable query size of k = 5. Similarly , additional features pro vide v aluable information to the learner. Changing the range A do es not affect the p erformance. The choice of v alues for query reten tion l and the cell sampling strategy allo ws influencing the exploration-exploitation trade-off. Interestingly , retain- ing one highest-rank ed pattern results in the low est regret with resp ect to the maximal qualit y . F ully random queries ( l = 0) do not enable sufficient exploita- tion, whereas higher retention ( l ≥ 2)—while ensuring higher aver age quality— prev ents exploration necessary for learning accurate weigh ts. The cell sampling strategy is the only parameter that clearly affects joint en tropy , with purely random cell sampling yielding the lo west regret. Ho wev er, it is also results in the highest qualit y regrets, whic h negates the gains in diversit y . T aking the best pattern according to ϕ logistic ensures the lo west qualit y regrets and joint entrop y equiv alen t to other strategies. Based on these findings, w e use the following parameters in the remaining exp eriments: k = 5, features = ILFT, A = 0 . 5, l = 1, ς = Top(1) . The largest proportion of LetSIP ’s run time costs is asso ciated with sampling (costs of weigh t learning are low due to a relatively low n umber of examples). The most important factor is the n umber of items |I | : the a verage run time per iteration ranges from 0.8s for lymph to 5.8s for australian , whic h is suitable for online data exploration. See the Flexics pap er [15] for more information ab out the scalabilit y of the sampling comp onen t. Comparing with alternatives. W e compare LetSIP with APLe [13], another approac h based on active preference learning, and IPM [2], an MCMC-based in teractive sampling framework. F or the former, we use query size k and feature represen tation iden tical to LetSIP , query selector MMR( α = 0 . 3 , λ = 0 . 7 ) , C RankSVM = 0 . 005, and 1000 frequen t patterns sampled uniformly at random and sorted b y f r eq as the sour c e r anking . T o compute regret, w e use the top-5 frequen t patterns according to the learned ranking function. T o emulate binary feedbac k for IPM based on ϕ , we use a tec hnique similar to the one used b y the authors: we designate a num b er of items as “interesting” and “like” an itemset, if more than half of its items are “in teresting”. T o select the items, we sort frequent patterns by ϕ descending and add items from the top-rank ed patterns until 15% of all patterns are considered “liked”. As w e w ere not able to obtain the co de for IPM , w e implemen ted its sampling comp onen t b y materializing all frequen t patterns and generating perfect samples according to the learned multiplicativ e distribution. Note that this approach fa vors IPM , as it eliminates the issues of MCMC conv ergence. W e request 300 samples (the amount of training data roughly equiv alen t to that of LetSIP ), partition them into 30 groups of 10 patterns each, and use the tail 5 patterns in eac h group for regret calculations. F ollowing the authors’ recommendations, we set the learning parameter to b = 1 . 75. F or the sampling-based methods LetSIP and IPM , w e also rep ort the div ersity regret as measured by joint e n trop y . T able 2. Effect of LetSIP ’s parameters on regret w.r.t. three p erformance measures. Results are aggregated ov er datasets, quality measures, and other parameters. Regret: avg. ϕ Regret: max. ϕ Regret: H J Query size k 5 6 . 35 ± 1 . 04 1 . 13 ± 0 . 52 13 . 28 ± 0 . 89 10 5 . 91 ± 0 . 59 0 . 47 ± 0 . 18 17 . 44 ± 0 . 45 All results b elo w are for query size of k = 5 F eatures I 8 . 17 ± 0 . 96 1 . 35 ± 0 . 56 13 . 64 ± 0 . 90 ILF 6 . 30 ± 1 . 36 1 . 16 ± 0 . 59 13 . 15 ± 0 . 96 ILFT 4 . 60 ± 0 . 78 0 . 87 ± 0 . 40 13 . 06 ± 0 . 81 Range A 0.5 6 . 43 ± 1 . 06 1 . 15 ± 0 . 52 13 . 20 ± 0 . 86 0.1 6 . 26 ± 1 . 01 1 . 11 ± 0 . 51 13 . 36 ± 0 . 91 Query retention l 0 8 . 19 ± 1 . 21 2 . 53 ± 0 . 72 13 . 38 ± 0 . 69 1 6 . 78 ± 0 . 99 0 . 53 ± 0 . 34 13 . 06 ± 0 . 72 2 5 . 61 ± 0 . 94 0 . 61 ± 0 . 42 13 . 56 ± 1 . 05 3 4 . 80 ± 1 . 00 0 . 80 ± 0 . 57 13 . 33 ± 1 . 22 Cell sampling ς Random 10 . 60 ± 0 . 71 1 . 89 ± 0 . 64 12 . 15 ± 0 . 59 T op(1) 5 . 14 ± 1 . 13 0 . 81 ± 0 . 45 13 . 70 ± 1 . 00 Top(2) 5 . 45 ± 1 . 06 0 . 87 ± 0 . 47 13 . 60 ± 0 . 98 Top(3) 5 . 95 ± 1 . 20 0 . 95 ± 0 . 50 13 . 57 ± 0 . 96 T able 3 shows the results. Note that the regret of LetSIP is low er than in T able 2, as the sp ecific parameter combination suggested by the previous exp erimen ts is used. F urthermore, it is substan tially low er than that of either of the alternativ es. The adv an tage o ver IPM is due to a more p o werful learning mec hanism and feature representation. IPM ’s multiplicativ e w eights are biased to wards longer itemsets and items seen at early iterations, which ma y preven t sufficien t exploration, as evidenced by higher join t entrop y regret. Non-sampling metho d APLe p erforms the b est for ϕ = f req , which can b e represented as a linear function of the features and learned b y RankSVM with the linear kernel. It p erforms substantially w orse in other settings and has the highest v ariance, whic h reveals the imp ortance of informed source rankings and the cons of p o ol- based activ e learning. These results v alidate the design c hoices made in LetSIP . 7 Conclusion W e presented LetSIP , a sampling-based instantiation of the Mine, inter act, le arn, r ep e at in teractive pattern mining framework. The user is ask ed to rank small sets of patterns according to their (sub jective) interestingness. The learn- ing comp onen t uses this feedback to build a mo del of user interests via active preference learning. The mo del directly defines the sampling distribution, which assigns higher probabilities to more in teresting patterns. The sampling compo- T able 3. LetSIP has considerably low er regrets than alternatives w.r.t. quality and, for samplers, div ersity as quan tified by joint en tropy . (F or ϕ = sur p (mark ed by *), IPM fails for 7 out of 10 datasets due to double o verflo w of multiplicativ e weigh ts.) Regret: avg. ϕ Regret: joint entrop y H J f r eq χ 2 sur p f r eq χ 2 sur p LetSIP 2 . 4 ± 0 . 5 2 . 4 ± 0 . 1 4 . 5 ± 1 . 4 11 . 7 ± 0 . 6 11 . 7 ± 0 . 5 15 . 9 ± 1 . 1 IPM 15 . 5 ± 1 . 8 12 . 8 ± 2 . 3 15 . 5 ± 1 . 8* 15 . 7 ± 1 . 9 15 . 4 ± 1 . 9 19 . 8 ± 2 . 1* APLe 0 . 0 ± 0 . 0 4 . 5 ± 3 . 8 5 . 3 ± 3 . 9 – – – nen t uses the recently prop osed Flexics sampler, whic h w e mo dify to facilitate con trol ov er the exploration-exploitation balance in active learning. W e empirically demonstrate that LetSIP satisfies the key requirements to an in teractive mining system. W e apply it to itemset mining, using a w ell-principled metho d to emulate a user. The results demonstrate that LetSIP learns to sample div erse sets of in teresting patterns. F urthermore, it outp erforms t wo state-of- the-art interactiv e metho ds. This confirms that it has the capacity to tac kle the pattern explosion while taking user in terests into account. Directions for future work include extending LetSIP to other pattern lan- guages, e.g., asso ciation rules, inv estigating the effect of noisy user feedbac k on the performance, and formal analysis, e.g., with m ulti-armed bandits [16]. A user study is necessary to ev aluate the practical asp ects of the prop osed approach. Ac knowledgemen ts : Vladimir Dzyuba is supported by FW O-Vlaanderen. The authors would like to thank the anonymous reviewers for their helpful feedback. References 1. Aggarw al, C.C., Han, J. (eds.): F requent Pattern Mining. Springer (2014) 2. Bh uiyan, M., Hasan, M.A.: Interactiv e knowledge discov ery from hidden data through sampling of frequen t patterns. Statistical Analysis and Data Mining: The ASA Data Science Journal 9(4), 205–229 (aug 2016) 3. Bh uiyan, M., Hasan, M.A.: PRIIME: A generic framew ork for in teractive p ersonal- ized interesting pattern discov ery . In: Pro c. of IEEE Big Data. pp. 606–615 (2016) 4. Boley , M., G¨ artner, T., Grosskreutz, H.: F ormal concept sampling for counting and threshold-free lo cal pattern mining. In: Pro ceedings of SDM. pp. 177–188 (2010) 5. Boley , M., Grosskreutz, H.: Appro ximating the num b er of frequen t sets in dense data. Knowledge and information systems 21(1), 65–89 (2009) 6. Boley , M., Lucchese, C., P aurat, D., G¨ artner, T.: Direct lo cal pattern sampling b y efficien t tw o-step random pro cedures. In: Pro ceedings of KDD. pp. 582–590 (2011) 7. Boley , M., Mampaey , M., Kang, B., T okmak ov, P ., W rob el, S.: One Click Mining – in teractive lo cal pattern disco very through implicit preference and p erformance learning. In: W orkshop Pro ceedings of KDD. pp. 28–36 (2013) 8. Boley , M., Mo ens, S., G¨ artner, T.: Linear space direct pattern sampling using coupling from the past. In: Proceedings of KDD. pp. 69–77 (2012) 9. Bringmann, B., Nijssen, S., T atti, N., V reek en, J., Zimmermann, A.: Mining sets of patterns. T utorial at ECML/PKDD (2010) 10. Calders, T., Rigotti, C., Boulicaut, J.F.: A survey on condensed represen tations for frequent sets. In: Boulicaut, J.F., De Raedt, L., Mannila, H. (eds.) Constraint- Based Mining and Inductive Databases, pp. 64–80. Springer (2006) 11. Chakrab ort y , S., F remont, D., Meel, K., Seshia, S., V ardi, M.: On parallel scalable uniform SA T witness generation. In: Pro ceedings of T A CAS. pp. 304–319 (2015) 12. Chakrab ort y , S., F remon t, D., Meel, K., V ardi, M.: Distribution-aw are sampling and weigh ted mo del counting for SA T. In: Pro c. of AAAI. pp. 1722–1730 (2014) 13. Dzyuba, V., v an Leeu wen, M., Nijssen, S., De Raedt, L.: In teractive learning of pat- tern rankings. International Journal on Artificial Intelligence T o ols 23(06) (2014) 14. Dzyuba, V., v an Leeuw en, M.: Learning what matters – sampling interesting pat- terns. In: Pro ceedings of P AKDD (2017), to app ear 15. Dzyuba, V., v an Leeuw en, M., De Raedt, L.: Flexible constrained sampling with guaran tees for pattern mining. Data Mining and Kno wledge Discov ery (in press), preprin t av ailable at 16. Filippi, S., Capp´ e, O., Garivier, A., Szep esv´ ari, C.: Parametric bandits: The gen- eralized linear case. In: Pro ceedings of NIPS. pp. 586–594 (2010) 17. Hasan, M.A., Zaki, M.: Output space sampling for graph patterns. In: Pro ceedings of VLDB. pp. 730–741 (2009) 18. Joac hims, T.: Optimizing search engines using clickthrough data. In: Pro ceedings of KDD. pp. 133–142 (2002) 19. Kamishima, T., Kazaw a, H., Ak aho, S.: A survey and empirical comparison of ob- ject ranking metho ds. In: F¨ urnkranz, J., H¨ ullermeier, E. (eds.) Preference Learning, c hap. I I I, pp. 181–202. Springer (2011) 20. v an Leeu wen, M.: In teractiv e data exploration using pattern mining. In: Holzinger, A., Jurisica, I. (eds.) In teractive Kno wledge Disco very and Data Mining in Biomed- ical Informatics, pp. 169–182. Springer (2014) 21. Meel, K., V ardi, M., Chakrab ort y , S., F remon t, D., Seshia, S., F ried, D., Ivrii, A., Malik, S.: Constrained sampling and coun ting: Univ ersal hashing meets SA T solving. In: Pro ceedings of Bey ond NP AAAI W orkshop (2016) 22. Rueping, S.: Ranking interesting subgroups. In: Proc. of ICML. pp. 913–920 (2009) 23. Shalev-Sh wartz, S., T ew ari, A.: Sto c hastic metho ds for 1 -regularized loss mini- mization. Journal of Machine Learning Researc h pp. 1865–1892 24. v an Leeu wen, M., Ukkonen, A.: Disco vering skylines of subgroup sets. In: Pro ceed- ings of ECML/PKDD. pp. 273–287 (2013) 25. Xin, D., Shen, X., Mei, Q., Han, J.: Discov ering interesting patterns through users in teractive feedbac k. In: Proceedings of KDD. pp. 773–778 (2006) A Sampling patterns with Flexics Here w e presen t a bird’s ey e view on the WeightGen / Flexics sampling proce- dure in order to pro vide con text for the modifications to it made within LetSIP , whic h are describ ed in Section 5. The reader interested in further technical de- tails should consult the resp ectiv e pap ers [15,12]. WeightGen is an algorithm for weigh ted constrained sampling of solutions to a SA T problem F , where each solution F is assigned a weigh t; w ( F ) ∈ (0 , 1]. The goal is to sample solutions to F randomly , with the probabilit y of sampling ϕ = 0 . 1 = A ϕ = 0 . 4 ϕ = 0 . 7 ϕ = 1 . 0 Fig. 2. The tw o principal comp onen ts obtained from the I tems features of all frequent patterns, i.e., pattern descriptions 5 . The size and the color of a point indicate the v alue of ϕ logistic of the corresp onding pattern. F or clarity , only a 1%-subsample is shown. a solution F prop ortional to its weigh t w ( F ). WeightGen employs the follow- ing high-level sampling procedure: 1) partition the set of solutions to F into a n umber of random subsets (referred to as c el ls ); 2) sample a random cell, and 3) sample a random solution from that cell. The k ey challenges are obtaining a partitioning with desirable prop erties and enumerating the solutions in a ran- dom cell efficiently . WeightGen addresses thes e with partitionings induced by random X OR constraints (XORs). Flexics extends this sampling pro cedure from SA T to pattern mining. V ari- ables in XORs corresp ond to individual items: N i ∈I b i · [ i ∈ p ] = b 0 , where b 0 | i ∈ { 0 , 1 } . The co efficien ts b i determine the items in volv ed in the constrain t, whereas the p arity bit b 0 determines whether an even or an o dd num b er of the in volv ed items must b e set to 1 for a pattern p to satisfy the XOR. T ogether, m XORs identify one cell b elonging to a partitioning of the set of all patterns in to 2 m cells. A required num b er of XORs is estimated once p er batch, based on theoretical considerations. Then for each sample (1) the co efficien ts b are drawn uniformly , obtaining a random cell; (2) Flexics enumerates and stores all pat- terns in that cell, i.e., the patterns that satisfy the original constrain ts C and the sampled X ORs; (3) a p erfect sample is dra wn from the cell and returned as the o verall sample. Theoretical properties of uniformly drawn X ORs allow proving desirable prop erties of the partitioning and b ounding the sampling error. In order to illustrate the concepts describ ed ab ov e, we use the characteristic example from Section 6 with ϕ = ϕ logistic after 30 learning iterations. W e visual- ize patterns by plotting the t wo principal comp onen ts obtained from the I tems feature matrix, i.e., pattern descriptions. Figure 2 sho ws all frequent patterns, 5 The PCA coordinates and ϕ logistic are strongly correlated, b ecause they are com- puted using the same feature represen tation for patterns ( I tems ). while Figure 3 shows examples of random cells, i.e., the output of FlexicsRan- domCell , from whic h patterns are chosen by a cell sampling strategy ς . The cells are different from each other, thus patterns returned from consec- utiv e cells are indep enden t and diverse. In each cell, we highlight the pattern with the highest qualit y ϕ logistic , whic h is returned b y ς = Top(1) , along with P ς = Random , the probabilit y that it is sample d fr om that c el l if ς = Random . These probabilities do not exceed 0 . 05, which demonstrates the motiv ation for alterna- tiv e cell sampling strategies. As exp ected, the patterns returned b y Top(1) are concen trated in the regions in the pattern space that are characterized b y high v alues of ϕ logistic . Nev ertheless, they are different from eac h other, thus the di- v ersity across samples is maintained, regardless of the bias tow ards exploitation. T op-1: { 18 , 20 , 23 , 53 , 56 , 58 , 60 , 64 } ϕ logistic = 0 . 974 P ς = Random = 0 . 044 ϕ logistic = 0 . 974 P ς = Random = 0 . 044 T op-1: { 6 , 14 , 18 , 24 , 26 , 56 , 58 , 60 , 64 } 0 . 990 0 . 034 0 . 990 0 . 034 T op-1: { 10 , 14 , 18 , 24 , 26 , 56 , 58 , 60 , 62 , 64 } 0 . 993 0 . 039 0 . 993 0 . 039 T op-1: { 6 , 8 , 10 , 20 , 24 , 26 , 56 , 60 , 64 , 66 } 0 . 980 0 . 036 0 . 980 0 . 036 T op-1: { 6 , 10 , 14 , 18 , 23 , 24 , 26 , 56 , 58 , 60 , 64 , 66 } 0 . 985 0 . 034 0 . 985 0 . 034 T op-1: { 8 , 20 , 24 , 26 , 56 , 60 , 62 } 0 . 980 0 . 038 0 . 980 0 . 038 T op-1: { 6 , 8 , 10 , 20 , 24 , 26 , 56 , 58 , 60 , 64 } 0 . 993 0 . 041 0 . 993 0 . 041 T op-1: { 14 , 18 , 20 , 23 , 37 , 56 , 60 , 62 , 64 } 0 . 965 0 . 032 0 . 965 0 . 032 T op-1: { 8 , 20 , 23 , 26 , 29 , 56 , 60 , 64 } 0 . 972 0 . 036 0 . 972 0 . 036 T op-1: { 6 , 10 , 14 , 20 , 24 , 56 , 60 , 62 , 64 } 0 . 988 0 . 033 0 . 988 0 . 033 Fig. 3. Individual cells plotted using the same PCA transformation as in Figure 2, i.e., the distances b etw een patterns corresp ond to the distances b et ween their descriptions.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment