Distant Supervision for Topic Classification of Tweets in Curated Streams
We tackle the challenge of topic classification of tweets in the context of analyzing a large collection of curated streams by news outlets and other organizations to deliver relevant content to users. Our approach is novel in applying distant supervision based on semi-automatically identifying curated streams that are topically focused (for example, on politics, entertainment, or sports). These streams provide a source of labeled data to train topic classifiers that can then be applied to categorize tweets from more topically-diffuse streams. Experiments on both noisy labels and human ground-truth judgments demonstrate that our approach yields good topic classifiers essentially “for free”, and that topic classifiers trained in this manner are able to dynamically adjust for topic drift as news on Twitter evolves.
💡 Research Summary
The paper addresses the problem of classifying tweets by topic in order to deliver relevant push notifications to users. Rather than relying on massive, unfiltered streams of Twitter data, the authors exploit a set of human‑curated news‑media accounts that already focus on specific subjects such as politics, sports, entertainment, or technology. By treating these “focused” accounts as a source of free, albeit noisy, labels, they can automatically generate training data without any manual annotation effort.
A total of 293 Twitter accounts were collected from a list originally published by Facebook for its Trending Topics algorithm. Each account was manually categorized into one of three types: focused (single‑topic), hybrid (covers a few topics), and general (covers many topics). Over a 21‑day period the authors harvested 337,307 tweets, averaging about 16,000 tweets per day. Focused accounts supplied positive examples for a given topic, while negative examples were randomly sampled from other accounts. Features were extracted using the NLTK tweet tokenizer and TF‑IDF weighting. Two classifiers were trained per topic: a binary logistic regression model (scikit‑learn default) and a multinomial Naïve Bayes model for the multi‑class setting.
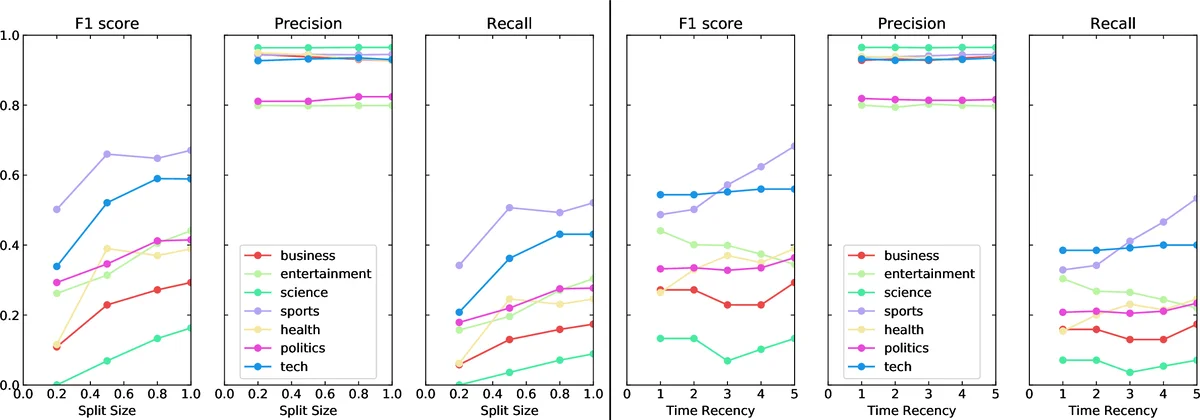
Two evaluation regimes were used. In the “noisy label” setting, the data were split chronologically 80 %/20 % (older tweets for training, newer tweets for testing). In the “gold‑standard” setting, a separate set of >1,000 tweets was manually annotated by the authors, allowing a clean test set. Experiments varied both the quantity of training data (by moving the start of the training window) and the recency of the data (by fixing the training size but sliding the window forward). Results consistently showed that more training data improves F1, precision, and recall, which is unsurprising. More importantly, when the training window was shifted to include more recent tweets, performance improved even with a fixed amount of data, indicating that topic drift is a real issue on Twitter.
To further mitigate drift, the authors introduced a temporal weighting scheme. Each tweet (t_i) in the training sequence was assigned a weight (e^{(\log(p) \cdot i)/n}), where (p) controls the emphasis on recent examples (p = 1 corresponds to uniform weighting). Empirically, setting (p = 10) yielded the best trade‑off: weighted training increased overall F1 by up to 0.07 on noisy labels and by a similar margin on the gold‑standard set. The improvement was especially noticeable for topics with abundant recent activity (politics, business, technology) and less pronounced for low‑frequency topics such as science.
The authors discuss several limitations. First, general accounts do not provide direct supervision, so the method relies on the existence of enough focused accounts for each desired topic. Second, the study is limited to English tweets; extending to multilingual streams would require additional language‑specific preprocessing. Third, topics with sparse data (e.g., science) still suffer from low performance, suggesting a need for data augmentation or transfer learning techniques.
In conclusion, the paper demonstrates that distant supervision via curated, topic‑focused Twitter accounts can produce effective topic classifiers “for free.” By leveraging larger volumes of automatically labeled data and emphasizing recent examples, the classifiers remain robust against the rapid evolution of news topics on Twitter. The authors are building a real‑time notification system based on this approach and plan to conduct field studies with actual users to assess practical impact. Future work includes multilingual expansion, handling of rare topics, and personalization of topic preferences.
Comments & Academic Discussion
Loading comments...
Leave a Comment