AllConcur: Leaderless Concurrent Atomic Broadcast (Extended Version)
Many distributed systems require coordination between the components involved. With the steady growth of such systems, the probability of failures increases, which necessitates scalable fault-tolerant agreement protocols. The most common practical agreement protocol, for such scenarios, is leader-based atomic broadcast. In this work, we propose AllConcur, a distributed system that provides agreement through a leaderless concurrent atomic broadcast algorithm, thus, not suffering from the bottleneck of a central coordinator. In AllConcur, all components exchange messages concurrently through a logical overlay network that employs early termination to minimize the agreement latency. Our implementation of AllConcur supports standard sockets-based TCP as well as high-performance InfiniBand Verbs communications. AllConcur can handle up to 135 million requests per second and achieves 17x higher throughput than today’s standard leader-based protocols, such as Libpaxos. Thus, AllConcur is highly competitive with regard to existing solutions and, due to its decentralized approach, enables hitherto unattainable system designs in a variety of fields.
💡 Research Summary
AllConcur addresses the scalability bottleneck inherent in leader‑based atomic broadcast protocols such as Paxos and Raft. The paper introduces a leaderless concurrent atomic broadcast algorithm that relies on a logical overlay network modeled as a directed regular graph G with n vertices, degree d, diameter D, and vertex‑connectivity k. By ensuring that k ≥ f (where f is the maximum number of tolerated crash‑stop failures), the system can tolerate up to f failures while each server maintains at most 2·d connections, thus keeping network overhead sub‑quadratic (O(n·d)).
The core contribution is an early‑termination mechanism that dramatically reduces the number of communication steps required for consensus. Traditional lower bounds dictate that an f‑resilient consensus algorithm using G needs at least f + Df(G,f) rounds in the worst case, where Df is the fault‑diameter. AllConcur observes that a server can safely deliver a message as soon as it knows that every non‑faulty server possesses exactly the same set of broadcast messages. To achieve this, each server tracks received failure notifications and the set of messages that have been A‑broadcast. When all servers have broadcast, no waiting for non‑existent messages is necessary, allowing termination after only a few rounds (typically 2–3 in practice). The paper provides a formal correctness proof (Section 3.1) and discusses the role of failure detectors, assuming a perfect detector (P) for analysis while acknowledging practical use of eventually‑perfect detectors (♦P).
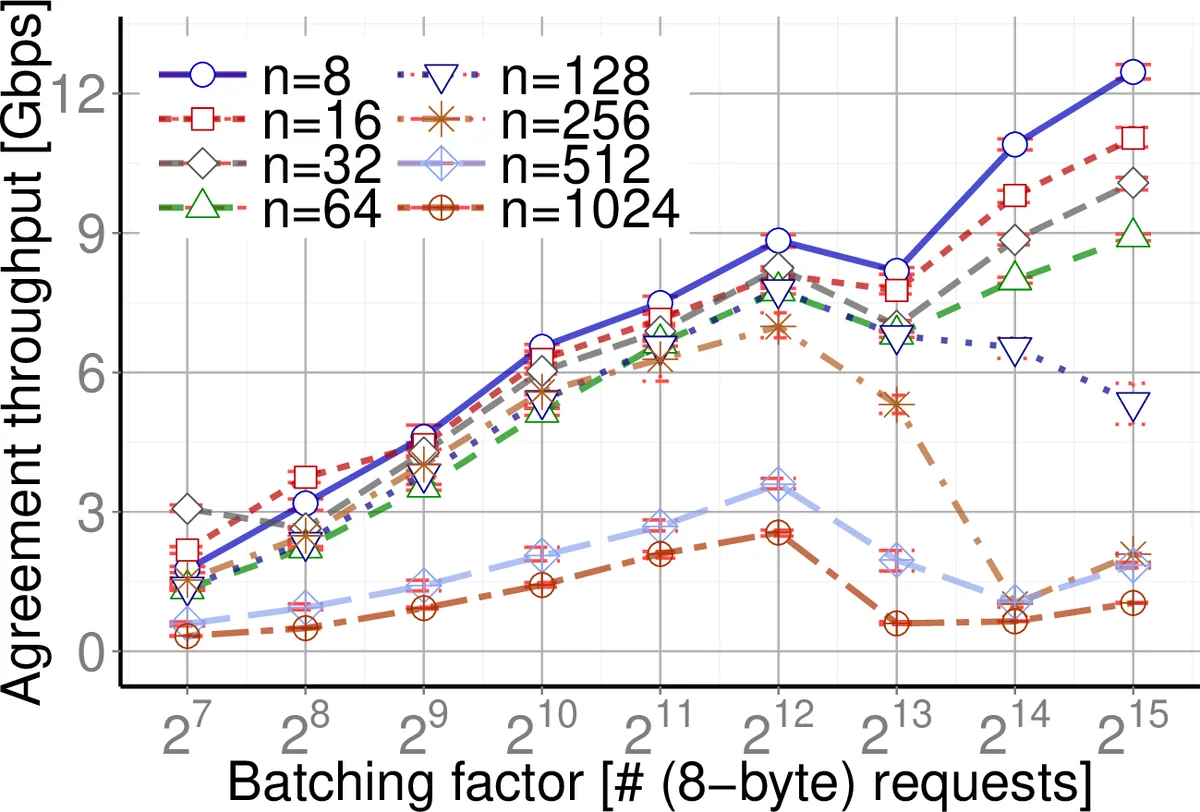
Implementation details cover two communication stacks: standard TCP sockets and high‑performance InfiniBand Verbs. Experiments on a cluster demonstrate that AllConcur can process up to 135 million 8‑byte requests per second, achieving a 17× throughput improvement over Libpaxos, a state‑of‑the‑art leader‑based implementation. Latency measurements show 35 µs for 8 servers each generating 100 M updates/s, and sub‑millisecond latency for 64‑server deployments under realistic loads. The system’s overhead for fault tolerance is reported as 58 % of the baseline, indicating efficient use of resources.
Three representative applications are evaluated: (1) travel reservation systems, where strong consistency is required despite heavy read‑heavy workloads; AllConcur distributes queries across servers while maintaining a single round of state lag, enabling 100 M updates/s across 8 servers with 35 µs agreement latency. (2) Multiplayer online games, which demand low latency and large shared state; the system supports 512 concurrent players with 40‑byte updates at 38 ms latency, enabling “epic battles” without sacrificing consistency. (3) Distributed exchanges, where fairness and equal latency across geographically dispersed clients are essential; an 8‑server deployment processes 100 M requests/s with median latency under 90 µs, while preserving strong consistency.
Performance analysis (Section 4) details the algorithmic complexity: sub‑quadratic work O(n·d), adjustable depth governed by the graph’s diameter and fault‑diameter, and bounded per‑server connections. The paper also compares AllConcur’s server‑transitivity (all servers are peers) against the asymmetry of leader‑based designs, highlighting fairness and avoidance of a single point of congestion.
In summary, AllConcur delivers a theoretically sound, practically validated leaderless atomic broadcast protocol that combines graph‑based overlay networks with an early‑termination scheme to achieve high throughput, low latency, and configurable fault tolerance. Its ability to outperform established leader‑based solutions by an order of magnitude makes it a compelling foundation for next‑generation distributed services requiring strong consistency at scale.
Comments & Academic Discussion
Loading comments...
Leave a Comment