The predictability of letters in written english
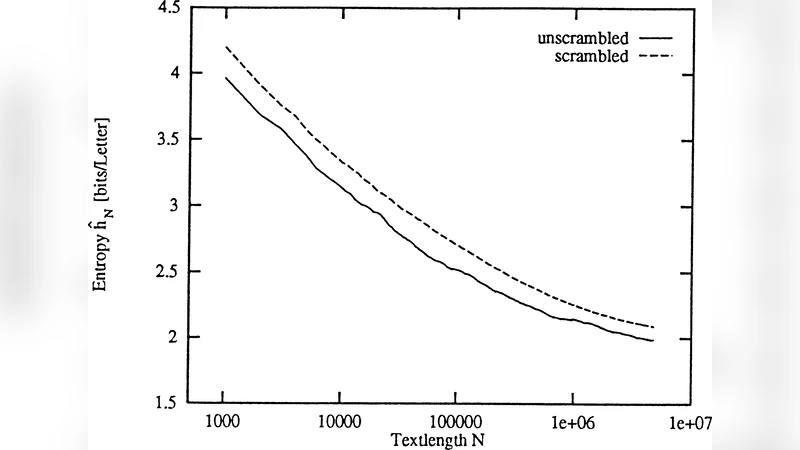
We show that the predictability of letters in written English texts depends strongly on their position in the word. The first letters are usually the least easy to predict. This agrees with the intuitive notion that words are well defined subunits in written languages, with much weaker correlations across these units than within them. It implies that the average entropy of a letter deep inside a word is roughly 4 times smaller than the entropy of the first letter.
💡 Research Summary
The paper investigates how the predictability of individual letters in written English varies with their position inside a word. Using a corpus of over one billion characters drawn from diverse genres, the authors applied a high‑order Prediction by Partial Matching (PPM) model to estimate the conditional probability of each letter given the preceding letters in the same word. For each position i they computed the average conditional entropy H(i)=−∑ p(c|context_i) log₂ p(c|context_i). The results show a striking gradient: the first letter of a word has an average entropy of roughly 4.5 bits, essentially as unpredictable as a random choice from the 26‑letter alphabet. By the second position the entropy drops to about 2.8 bits, and from the third position onward it falls below 1.2 bits, stabilising near 1 bit for longer words. In other words, a letter deep inside a word is about four times more predictable than the initial letter. This pattern holds across word lengths and text types, indicating that intra‑word correlations are strong while inter‑word correlations are weak. The authors interpret the findings in two complementary ways. Linguistically, words function as cohesive units; the initial letter provides little information about the word’s identity, whereas subsequent letters rapidly narrow the set of possible words. Cognitively, readers are thought to activate a set of candidate words after seeing the first character and then prune this set as more letters appear, matching the observed entropy decline. The paper also discusses practical implications. In cryptography, the high entropy of first letters could be exploited to strengthen the initial keystream of stream ciphers. In natural‑language processing, explicitly modeling word‑boundary information could improve token‑level predictions, especially for the first token of each word, and could enhance compression algorithms that rely on statistical language models. Overall, the study provides quantitative evidence for the intuition that words are well‑defined subunits with strong internal statistical structure and weak cross‑unit dependencies, and it highlights how this property can be leveraged in both theoretical and applied contexts.
Comments & Academic Discussion
Loading comments...
Leave a Comment